 PyTorch核心華人開發者透徹解讀PyTorch內部機制
PyTorch核心華人開發者透徹解讀PyTorch內部機制
本文以內部PyTorch核心開發者視角,非常詳細透徹的分析了PyTorch的內部結構,為開發者提供一張地圖,告訴您“支持自動區分的張量庫”的基本概念結構,并提供一些工具和技巧,以便找到適合代碼庫。對學習PyTorch、尤其是致力于參與PyTorch貢獻有非常大的意義。
PyTorch是一個開源的Python機器學習庫,基于Torch,已成為最受歡迎的機器學習框架之一。
相比Tensorflow,PyTorch的社區由更多專業機器學習開發人員、軟件架構師和公司內部程序員組成。
PyTorch也更多地用于數據分析和業務環境中的特殊模型中。
在PyTorch社區中,有更多的Python開發人員從事Web應用程序。此外,這種Python向框架的多功能性,使得研究人員能夠以幾乎無痛的方式測試想法,使得它成為最先進的尖端解決方案的首選框架。
對于準備、正在學習PyTorch的讀者來說,了解其內部機制能夠極大的提升學習效率、增進對PyTorch設計原理和目的的了解,從而能夠更好的在工作學習中使用該工具。如果你立志參與到PyTorch后續的改進中,那么更應該深入的了解其內部機制。
好消息是,Facebook Research Engineer、斯坦福博士生、PyTorch核心開發人員Edward Z. Yang為大家帶來一份PyTorch內部機制的詳解slides,新智元在此強力推薦給廣大讀者。正文約3500字,閱讀可能需要10分鐘。
由于微信的限制無法展示高清圖像,我們特意為大家在文末找來了可下載的高清完整版,預祝大家學習愉快!
這份內部機制詳解是為誰準備的?
主要針對使用過PyTorch的人,尤其是希望成為PyTorch貢獻者、但卻被PyTorch的龐大復雜的C++代碼庫嚇到的人。
最終目的是能夠為大家提供一個通關寶典,讓大家了解“支持自動區分的Tensor庫”的基本概念結構,并提供一些工具和技巧,用來更容易的找到適合代碼庫。
讀者只需要對PyTorch有一個初步的了解,并且有過一定的動手經驗即可。門檻還是非常低的。
全部內容分為兩部分。首先介紹Tensor庫的概念。作者將從Tensor數據類型開始,更詳細地討論這種數據類型提供的內容,以便讓讀者更好地了解它是如何實際實現的。布局、設備和dtype的三位一體,探討如何考慮對Tensor類的擴展。
第二部分將討論PyTorch實戰。例如使用autograd來降低工作量,哪些代碼關鍵、為什么?以及各種用來編寫內核的超酷的工具。
理解Tensor庫的概念
Tensor
Tensor是PyTorch中的中心數據結構。我們可以將Tensor視為由一些數據組成,然后是一些描述Tensor大小的元數據,包含元素的類型(dtype),Tensor所依賴的設備(CPU內存?CUDA內存?)。以及Strides(步幅)。Strides實際上是PyTorch的一個顯著特征。
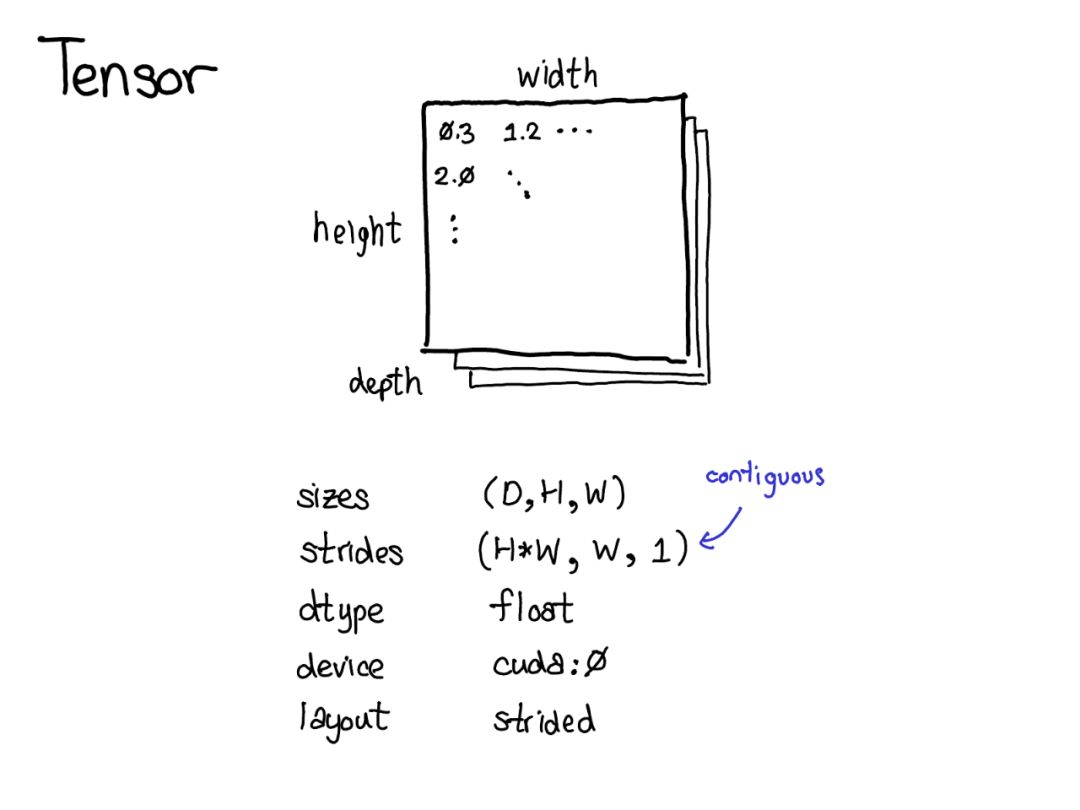
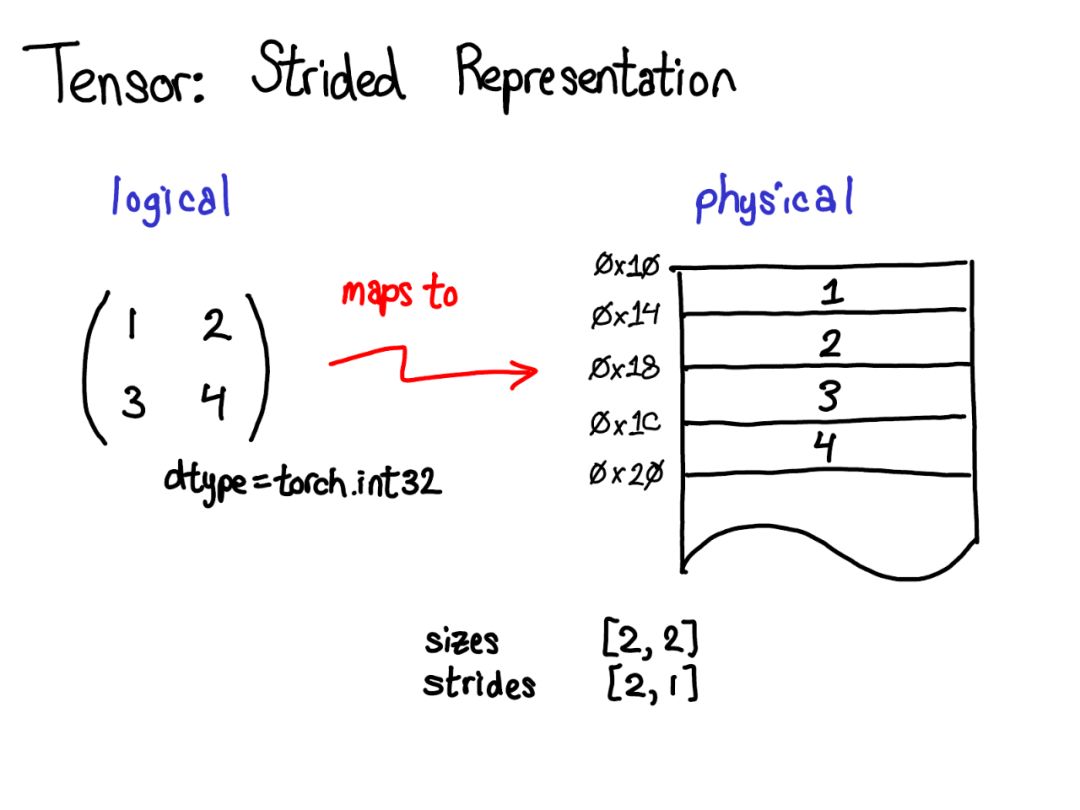
Tensor是一個數學概念。在計算機上最常見的表示是將Tensor中的每個元素連續地存儲在內存中,將每一行寫入內存,如上所示。
在上面的例子中,指定Tensor包含32位整數,每個整數位于物理地址中,相互偏移四個字節。要記住Tensor的實際尺寸,還必須記錄哪些尺寸是多余的元數據。
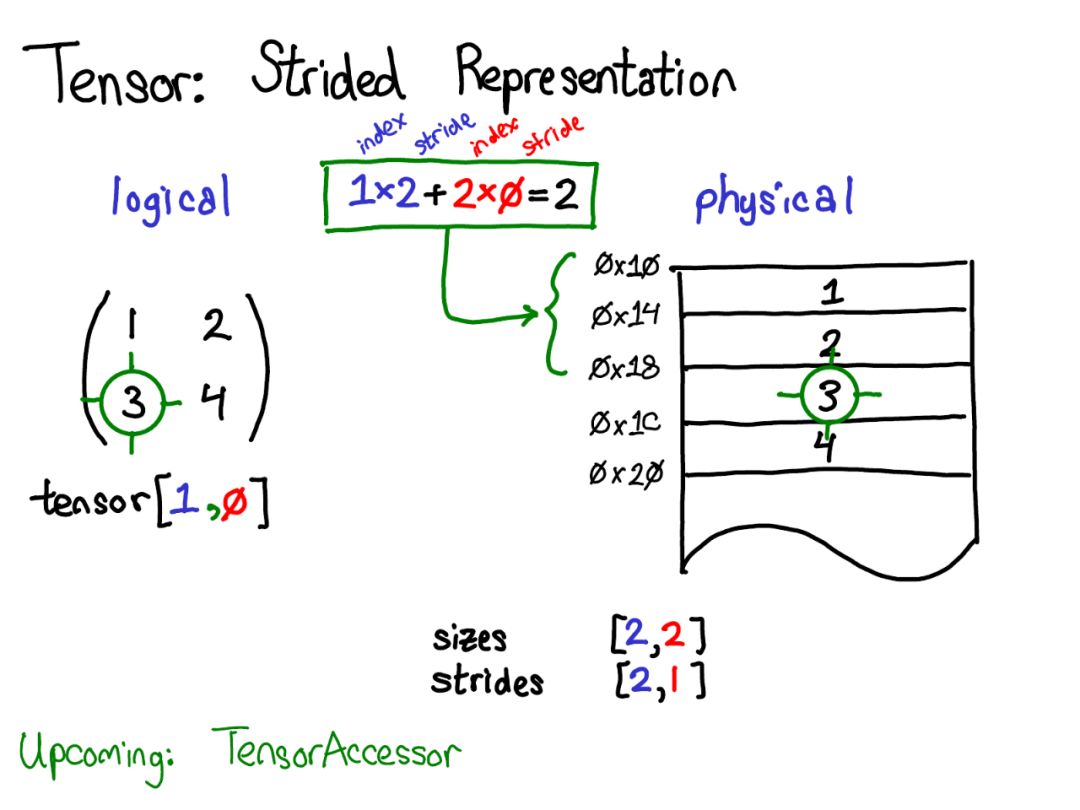
假設我想在邏輯表示中訪問位置Tensor[0,1]處的元素。通過Stride我們應該這樣做:
找出Tensor的任何元素存在的位置,將每個索引乘以該維度的相應Stride,并將它們加在一起。
上圖中將第一維藍色和第二維紅色進行了顏色編碼,以便在Stride計算中跟蹤索引和步幅。
以上是Stride的一個例子。Stride表示實際上可以讓你代表Tensor的各種有趣的方法; 如果你想玩弄各種可能性,請查看Stride Visualizer。
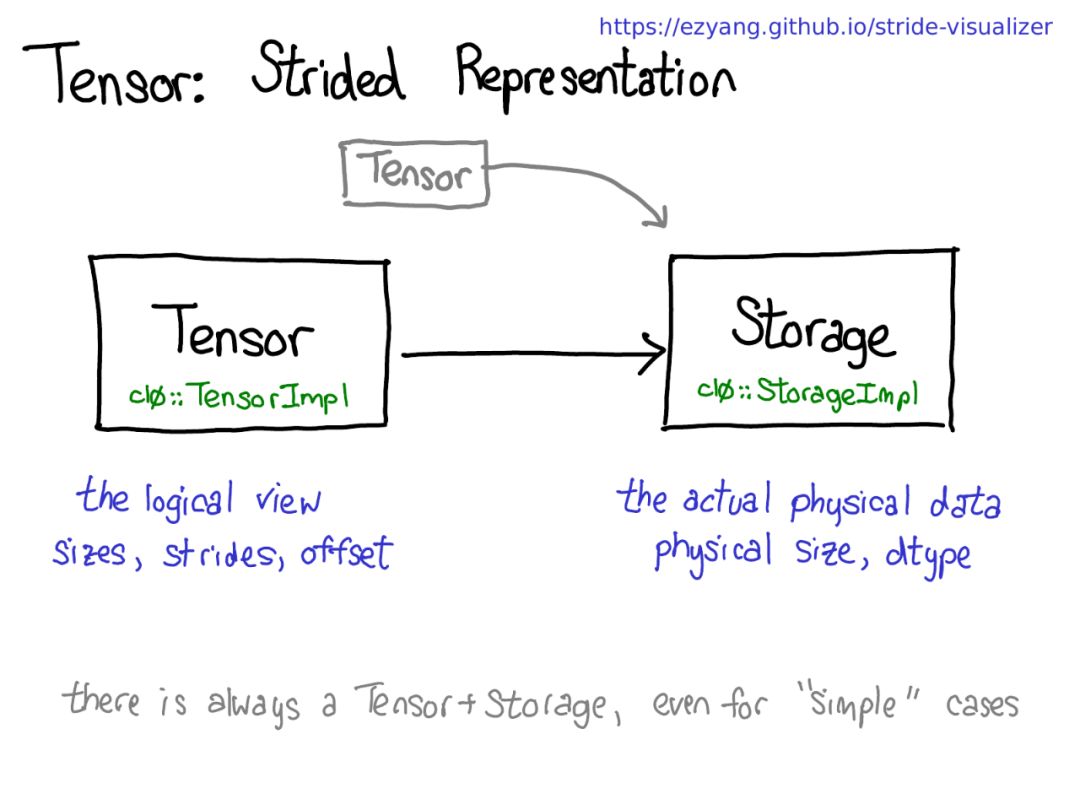
可能存在共享相同存儲的多個Tensor,但請記住一點:有Tensor的地方,就有存儲。
存儲定義Tensor的dtype和物理大小,而每個Tensor記錄大小,步幅和偏移,定義物理內存的邏輯解釋。
Tensor擴展
有很多有趣的擴展,如XLA張量,量化張量,或MKL-DNN張量,作為張量庫,我們必須考慮是如何適應這些擴展。
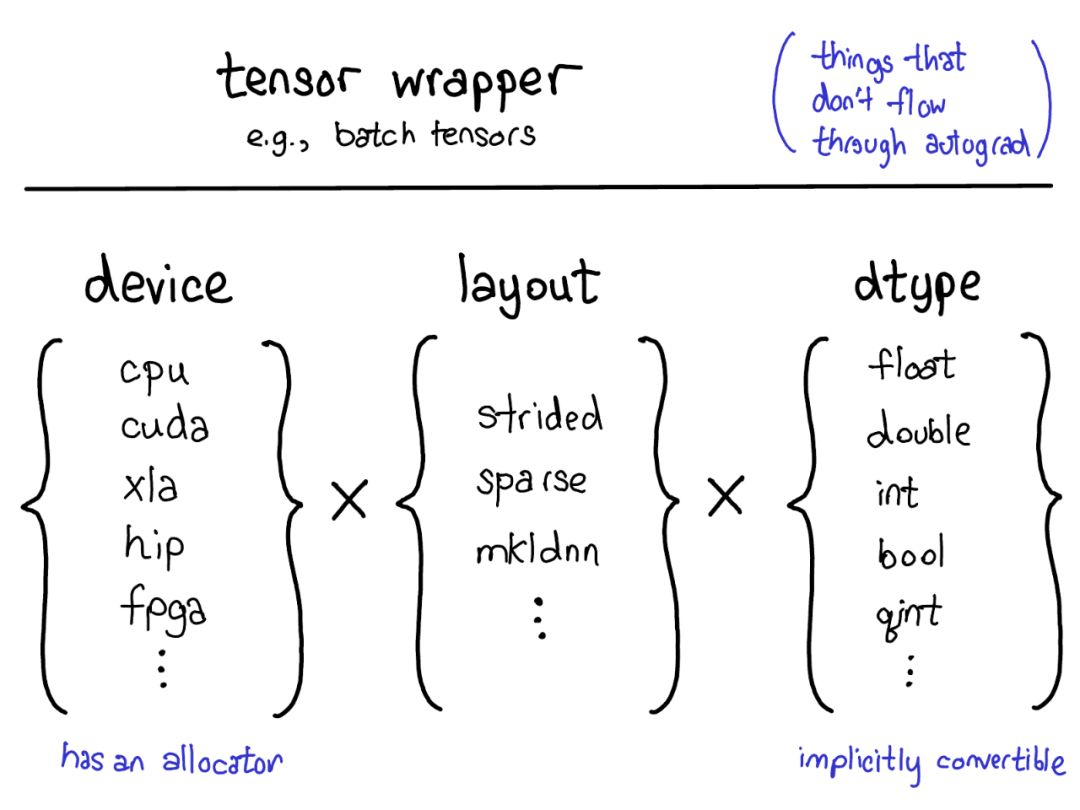
當前的擴展模型在張量上提供了四個擴展點。首先,用三個參數用來確定張量是什么:
設備
張量的物理存儲器實際存儲在何處,例如在CPU上,NVIDIA GPU(cuda)上,或者可能在AMD GPU(hip)或TPU(xla)上的描述。設備的顯著特征是它有自己的分配器,不能與任何其他設備一起使用。
布局
布局用來描述我們如何邏輯地解釋這個物理內存。最常見的布局是跨步張量,但稀疏張量具有不同的布局,涉及2個張量:一個用于索引、一個用于數據。
MKL-DNN張量可能具有更奇特的布局,例如阻擋布局,這不能僅使用步幅來表示。
dtype
描述了它實際存儲在張量的每個元素中的含義。這可以是浮點數或整數,或者它可以是例如量化的整數。
順便說一下,如果你想為PyTorch張量添加一個擴展名,請聯系PyTorch官方。
實戰技巧
了解你手里的武器
PyTorch有很多文件夾,CONTRIBUTING文檔有非常詳細的描述。但實際上,你真正需要了解的只有四個:
torch/:包含導入和使用的實際Python模塊。Python代碼,很容易上手調試。
torch/csrc/:它實現了在Python和C++之間進行轉換的綁定代碼,以及一些非常重要的PyTorch功能,如autograd引擎和JIT編譯器。它還包含C++前臺代碼。
aten/:“A Tensor Library”的縮寫(由Zachary DeVito創造),是一個實現Tensors操作的C++庫。存放一些內核代碼存在的地方,盡量不要在那里花太多時間。
c10/:這是一個雙關語。C代表Caffe,10既是二級制的2,也是十進制的10(英文Ten,同時也是Tensor的前半部分)。包含PyTorch的核心抽象,包括Tensor和Storage數據結構的實際實現。
讓我們看看這種代碼分離在實踐中是如何分解的:

調用一個函數的時候,會經歷以下步驟:
將Python翻譯成C
處理變量調度
處理設備類型/布局調度
我們有實際的內核,它既可以是現代本機函數,也可以是傳統的TH函數

值得一提的是,所有代碼都是自動生成的,所以不會出現在GitHub的repo里,必須自己構建PyTorch后才能看到。不過你也不必非常深刻地理解這段代碼在做什么,自動生成的嘛。
從武器庫中挑選寫內核的趁手兵刃
PyTorch為內核編寫者提供了許多有用的工具。在本節中,我們將介紹其中比較趁手的工具。
要利用PyTorch帶來的所有代碼生成,需要為運算符編寫schema。詳細介紹參見GitHub的README。

錯誤檢查可以通過低階API(TORCH_CHECK)和高階API實現。高階API可以基于TensorArg元數據提供用戶友好的錯誤消息。
要執行dtype調度,應該使用AT_DISPATCH_ALL_TYPES宏,用來獲取張量的dtype,并用于可從宏調度的每個dtype的lambda。通常,這個lambda只調用一個模板化的輔助函數。

如何提高工作效率

別編輯header!
編輯header會導致很長的重構時間,盡量去編輯.cpp文件。
別直接用CI去測試
CI是一個直接可用的測試代碼的變動是否有效的非常棒的工具,但如果你真的一點不都改設置恐怕要浪費很長時間在測試過程中。
強烈建議設置ccache
它有可能讓你避免在編輯header時進行大量重新編譯。而當我們在不需要重新編譯文件時進行了重新編譯,它還有助于掩蓋構建系統中的錯誤。
用一臺高性能的工作站
-
存儲器
+關注
關注
38文章
7453瀏覽量
163608 -
機器學習
+關注
關注
66文章
8378瀏覽量
132415 -
pytorch
+關注
關注
2文章
803瀏覽量
13149
原文標題:揭秘PyTorch內核!核心開發者親自全景解讀(47頁PPT)
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Pytorch模型訓練實用PDF教程【中文】
Facebook致力AI開源PyTorch 1.0 AI框架
Facebook致力AI 開源PyTorch1.0 AI框架
Facebook宣布發布深度學習框架 PyTorch 1.0開發者預覽版
一文解構PyTorch:深入了解PyTorch內部機制

一篇非常新的介紹PyTorch內部機制的文章

PyTorch 的 Autograd 機制和使用
TensorFlow的衰落與PyTorch的崛起

沒有“中間商賺差價”, OpenVINO? 直接支持 PyTorch 模型對象

15-PyTorch-Edge-在邊緣設備上部署AI模型的開發者之旅





 工商網監
工商網監
評論