") 斯坦福大學(xué)研究人員就試圖通過大型視頻集來識別、表示和生成人與物體間的真實交互
斯坦福大學(xué)研究人員就試圖通過大型視頻集來識別、表示和生成人與物體間的真實交互
現(xiàn)代機(jī)器人技術(shù)在運動類任務(wù)上的表現(xiàn)已經(jīng)很驚艷,比如搬運重物、雪地行走等,但對于人和目標(biāo)的交互式任務(wù),比如餐桌擺盤、裝飾房間等多半還無能為力。近日,斯坦福大學(xué)研究人員就試圖通過大型視頻集來識別、表示和生成人與物體間的真實交互。
近幾年來,虛擬現(xiàn)實(VR)和機(jī)器人平臺技術(shù)已經(jīng)取得了巨大進(jìn)步。這些平臺現(xiàn)在可以讓我們體驗更加身臨其境的虛擬世界,讓機(jī)器人幫我們完成具有挑戰(zhàn)性的運動類任務(wù),例如在雪中行走,搬運重物等。那么,我們能否很快就能擁有可以會擺放餐桌、會做菜的機(jī)器人了呢?
很遺憾,這個目標(biāo)現(xiàn)在離我們還有點遠(yuǎn)。
在日常生活中人與物體發(fā)生相互作用的一些例子
為什么?要弄清這個問題,需要從日常人類生活中的相互作用的多樣性說起。我們幾乎無時無刻不在進(jìn)行活動,這些活動中包括簡單的動作,比如吃水果,或更復(fù)雜一些的,比如做飯。這些活動中都會發(fā)生人和周圍事物的相互作用,這個過程是多步的,會受到物理學(xué)、人類目標(biāo),日常習(xí)慣和生物力學(xué)的支配。
為了開發(fā)更具動態(tài)性的虛擬世界和更智能的機(jī)器人,我們需要教機(jī)器捕獲,理解和復(fù)制這些交互行為。我們可以以大型視頻集(如YouTube,Netflix,F(xiàn)acebook)的形式,廣泛提供了解這些交互所需的信息。
本文將描述從視頻中學(xué)習(xí)人與對象的多級交互活動所采取的一些初級步驟。主要討論生成適用于VR/ AR技術(shù)的人與對象交互動畫,研究如何使機(jī)器人能巧妙地對用戶行為和交互作出反應(yīng)。
問題和挑戰(zhàn)
我們將研究重點放在人類進(jìn)行的各種交互活動的子集上,常見的如家用桌上或辦公室中的人與物體的交互,比如用手拿取桌子上的目標(biāo)。下圖中類似的桌面交互活動占到我們?nèi)粘P袨橹械暮艽笠徊糠郑捎谑?物體的配置空間很大,因此這些交互活動的模式和特征難以捕獲。
上圖是我們收集的視頻中的一些桌面交互活動實例。我們收集了75個視頻(20個驗證視頻)。
我們的目標(biāo)是通過學(xué)習(xí)大型視頻集來識別、表示和生成這些真實的交互。這必須要解決具有挑戰(zhàn)性的基于視覺的識別任務(wù),產(chǎn)生與當(dāng)前和過去的環(huán)境狀態(tài)一致、時間空間一致的多步交互。這些交互還應(yīng)符合基本物理定律(比如不能穿透物體),人類習(xí)慣(比如不能端著帶杯柄的咖啡杯),并受到人體生物力學(xué)特征的限制(比如夠不到太遠(yuǎn)的物體)。
人類活動的空間及其支持的相互作用存在無數(shù)可能。與對象的交互會導(dǎo)致連續(xù)的時空上的轉(zhuǎn)換,使交互模式難以形式化。不過,這些復(fù)雜的相互作用可以按照順序進(jìn)行建模,即總結(jié)出從給定狀態(tài)到后續(xù)狀態(tài)的變化概率。
為了在這個順序模型中進(jìn)行參數(shù)化表示,我們引入了一個稱為動作劃分(action plot)的表示,負(fù)責(zé)表示由手完成的、導(dǎo)致場景中的狀態(tài)發(fā)生改變的一系列動作。每個動作定義交互中的唯一階段,并表示為動作元組,每個動作元組由動作標(biāo)簽、持續(xù)時間、參與對象、結(jié)束狀態(tài)和位置組成。這種離散化處理方式更加突出了人與物體相互作用的組合性質(zhì),同時抽象出時空變換的復(fù)雜度。
從視頻中識別人與物體的交互
學(xué)習(xí)生成包含多步驟交互行為的動作劃分,捕捉現(xiàn)實世界中人和物體交互行為的物理約束和因果關(guān)系。我們的目標(biāo)是從人類場景交互的視頻集合中進(jìn)行自動學(xué)習(xí),因為這是一種快速,廉價、多功能的設(shè)置。為了完全表示動作劃分,需要首先獲取有關(guān)對象的實例、類別和位置,然后確定手的位置,最后進(jìn)行動作檢測和分割,這些信息都要從視頻中提取,難度很大。
我們通過自動化的pipeline,利用計算機(jī)視覺領(lǐng)域的最新進(jìn)展,在動作劃分任務(wù)上實現(xiàn)了最高的精度。
對象和實例跟蹤:動作劃分中的一個重要組成部分是對象類別、實例、位置和狀態(tài)。我們使用基于更快的R-CNN架構(gòu)的物體檢測器來在每幀圖像中找到候選邊界框和標(biāo)簽和對象位置,通過時間濾波減少檢測抖動。為了推斷對象的狀態(tài),在每個邊界框的內(nèi)容上訓(xùn)練分類器。
手部檢測:由于大多數(shù)交互涉及手部,因此圖像處理目的是推斷出手在操縱哪些物體,以及手部遮擋時的物體位置。我們使用完全卷積神經(jīng)網(wǎng)絡(luò)(FCN)架構(gòu)來檢測手部動作。該網(wǎng)絡(luò)使用來自GTEA數(shù)據(jù)集中的手工掩模的數(shù)據(jù)進(jìn)行訓(xùn)練,并根據(jù)我們視頻集的子集進(jìn)行微調(diào)。通過手部檢測和物體的運動方式,可以推斷出手的實時狀態(tài)(是空閑,還是被占用),這是一個重要的信息。
動作劃分:要為每個視頻幀生成動作標(biāo)簽,我們需要識別所涉及的動作以及它們的開始和結(jié)束時間(即動作分段)。我們采用兩階段方法:(1)為每幀圖像提取有意義的圖像特征,(2)利用提取的特征對每幀的動作標(biāo)簽進(jìn)行分類,并對動作進(jìn)行分段劃分。為了增加動作劃分的魯棒性,使用LSTM網(wǎng)絡(luò)來暫時聚合信息。詳細(xì)信請參閱論文。
使用遞歸神經(jīng)網(wǎng)絡(luò)生成
利用上文中描述的動作劃分表示可以對復(fù)雜的時空交互進(jìn)行緊湊編碼,第2部分中的識別系統(tǒng)可以利用視頻創(chuàng)建動作劃分。現(xiàn)在的目標(biāo)是使用視頻集合中提取的動作圖來學(xué)習(xí)生成新的交互。為了使問題易于處理,我們將動作元組中的時變和時不變參數(shù)進(jìn)行解耦處理,更具體地說,是使用多對多RNN來建模,并利用與時間無關(guān)的高斯混合模型。
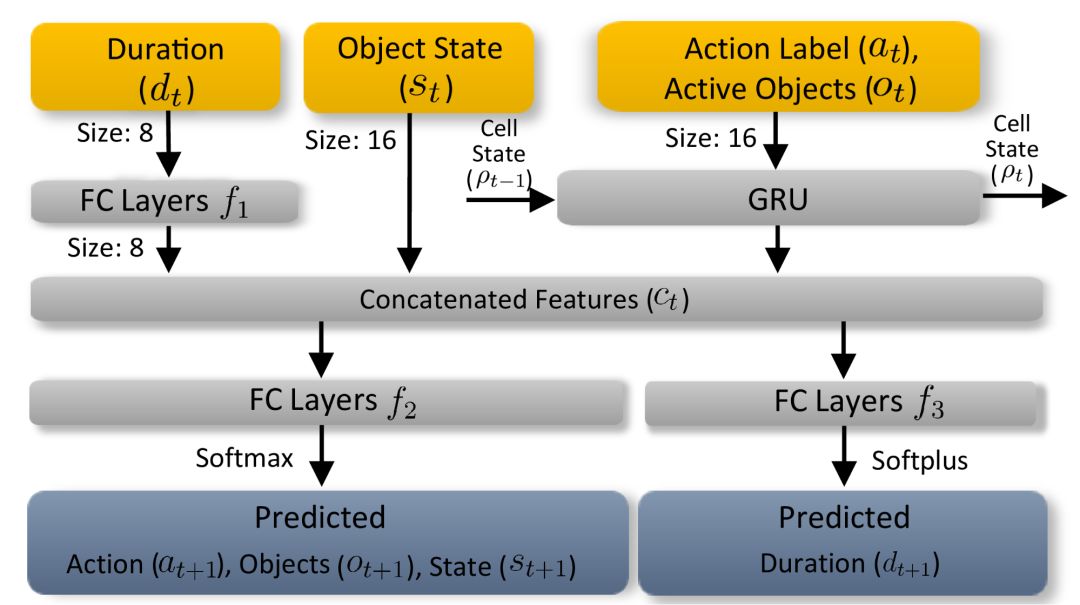
時間依賴性動作分割RNN:從自然語言處理中的類似序列問題中汲取靈感,使用狀態(tài)保持遞歸神經(jīng)網(wǎng)絡(luò)(RNN)來模擬交互事件中與時間相關(guān)的參數(shù)。
動作分割RNN會學(xué)習(xí)并預(yù)測包括動作標(biāo)簽、活動對象,對象狀態(tài)和持續(xù)時間組成的下一狀態(tài)。每個時間步長上的輸入會首先嵌入到指定大小的向量中。
與時間無關(guān)的物體位置模型:人和物體之間的許多相互作用需要通過建模,生成新的合理物體運動。物體的分布存在強(qiáng)烈的先驗性特征。比如在杯子周圍存在打開的瓶子是很常見的,但在筆記本電腦周圍就很少見。由于這些先驗性特征對時間因素的依賴性不高,我們可以利用高斯混合模型(GMM)對視頻集合進(jìn)行學(xué)習(xí),并進(jìn)行建模。
與時間無關(guān)的對象位置模型的學(xué)習(xí)和建模。此圖為從視頻集合中學(xué)習(xí)的可能對象位置的熱圖。
結(jié)果與應(yīng)用實例
動畫合成:我們的方法可以學(xué)習(xí)單個動作的前后因果依賴性,所以可用于生成在訓(xùn)練期間未見過的新的動作圖像,并將這些動作圖渲染成逼真的動畫,如下圖所示。利用這一點可以產(chǎn)生虛擬/增強(qiáng)現(xiàn)實領(lǐng)域的新應(yīng)用,向人們傳授新技能(比如沖咖啡)。
機(jī)器人仿真和運動規(guī)劃:可以在智能和反應(yīng)環(huán)境中啟用應(yīng)用,改善老年人和殘疾人的生活。我們開發(fā)了帶差動驅(qū)動器的機(jī)器杯。杯子的動作由實時識別、表示和生成pipeline驅(qū)動。杯子可以實時捕獲交互并編碼為動作圖像,預(yù)測可能的未來狀態(tài)。機(jī)器人使用這些預(yù)測來做出適當(dāng)?shù)姆磻?yīng)。
下圖中的“召喚杯”顯示出用手抓杯子的過程。智能杯子會朝人手的方向移動,以防用戶伸手夠不到。但是,如果檢測到用戶的手中之前已經(jīng)拿了一本書,智能杯就不會移動,因為我們的方法隱式學(xué)會了“一次只讓手拿住一個物體”的物理約束。
“召喚杯”表現(xiàn)出了手、智能杯子和瓶子之間更復(fù)雜相互作用的實例。當(dāng)手去移動裝滿的瓶子時,智能杯自動定位以便手將瓶中的水倒進(jìn)杯里。但是,當(dāng)檢測到瓶子是空的時,智能杯不會做出反應(yīng)。只有掌握復(fù)雜的人和對象之間的交互特征,才能實現(xiàn)這種語義規(guī)劃。
討論與未來方向
本研究是識別、表示和生成合理的動態(tài)人與對象交互過程的第一步。我們提出了一種方法,通過識別視頻中的交互過程,使用動作劃分緊湊地表示出這些交互,并生成新的交互,從而自動學(xué)習(xí)視頻集合中的交互。雖然我們已經(jīng)取得了很大的成果,但仍有一些明顯的局限性。
我們用以進(jìn)行動作劃分的RNN無法捕獲的長時間范圍內(nèi)的活動。目前的應(yīng)用也僅限于桌上的交互式任務(wù)。在未來,我們計劃將研究范圍擴(kuò)展至長期的交互活動上,并改善我們生成的交互的合理性。
我們的方法為學(xué)習(xí)生成人與對象的交互活動提供了堅實的基礎(chǔ)。但是要想創(chuàng)建更具沉浸感和動態(tài)的虛擬現(xiàn)實,還需要進(jìn)行廣泛的研究,將來我們也許可以構(gòu)建會做晚餐、會洗碗的機(jī)器人。
本研究的論文將于2019年 Eurographics會議上發(fā)表。
-
機(jī)器人
+關(guān)注
關(guān)注
210文章
28231瀏覽量
206621 -
虛擬現(xiàn)實
+關(guān)注
關(guān)注
15文章
2285瀏覽量
94853 -
AR技術(shù)
+關(guān)注
關(guān)注
4文章
251瀏覽量
17273
原文標(biāo)題:斯坦福黑科技打造新型交互機(jī)器人:看視頻一學(xué)就會!
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論