") LaserNet:基于激光雷達(dá)數(shù)據(jù)的激光網(wǎng)絡(luò)自動駕駛?cè)S目標(biāo)檢測
LaserNet:基于激光雷達(dá)數(shù)據(jù)的激光網(wǎng)絡(luò)自動駕駛?cè)S目標(biāo)檢測
本文介紹了一種基于激光雷達(dá)數(shù)據(jù)的激光網(wǎng)絡(luò)自動駕駛三維目標(biāo)檢測方法——LaserNet。高效的處理結(jié)果來自于在傳感器的自然距離視圖中處理激光雷達(dá)數(shù)據(jù)。在激光雷達(dá)視場范圍內(nèi)的操作有許多挑戰(zhàn),不僅包括遮擋和尺度變化,還有基于傳感器如何捕獲數(shù)據(jù)來提供全流程信息。
本文介紹的方法是使用一個全卷積網(wǎng)絡(luò)來預(yù)測每個點在三維物體上的多模態(tài)分布,然后有效地融合這些多模態(tài)分布來生成對每個對象的預(yù)測。實驗表明,把每個檢測建模看作一個分布,能獲得更好的整體檢測性能。基準(zhǔn)測試結(jié)果表明,相比其他的檢測方法,本方法的運行時間更少;在訓(xùn)練大量數(shù)據(jù)來克服視場范圍目標(biāo)檢測問題上,本方法獲得最佳性能。
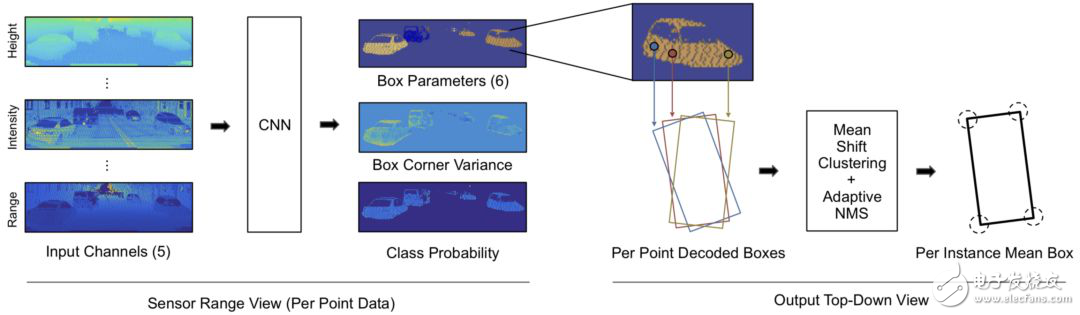
LaserNet通過以下幾個步驟實現(xiàn)三維檢測:
使用傳感器的固有范圍視場來構(gòu)建一個密集的輸入圖像;
圖像通過全卷積網(wǎng)絡(luò)生成一組預(yù)測;
對于圖像中的每個激光雷達(dá)點,預(yù)測一個類概率,并在俯視圖中對邊界框架進(jìn)行概率分布回歸;
每個激光雷達(dá)點分布通過均值漂移聚類進(jìn)行組合,以降低單個預(yù)測中的噪聲;
檢測器進(jìn)行端到端訓(xùn)練,在邊界框架上定義損失;
用一種新的自適應(yīng)非最大抑制(NMS)算法來消除重疊的邊框分布。
上圖為深層聚合網(wǎng)絡(luò)架構(gòu)。列表示不同的分辨率級別,行表示聚合階段。
上圖為特征提取模塊(左)和特征聚合模塊(右)。虛線表示對特征圖進(jìn)行了卷積。
上圖為自適應(yīng)NMS。在兩輛車并排放置的情況下,左邊的虛線描述了產(chǎn)生的一組可能的預(yù)測。為了確定邊界框是否封裝了唯一的對象,使用預(yù)測的方差(如中間所示)來估計最壞情況下的重疊(如右圖所示)。在本例中,由于實際重疊小于估計的最壞情況重疊,因此將保留這兩個邊界框。
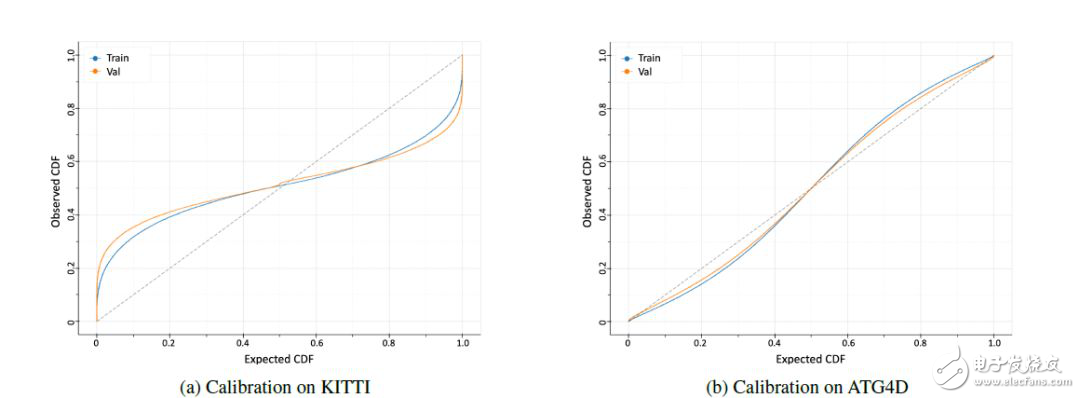
上圖為在訓(xùn)練集和驗證集上的邊界框上的預(yù)測分布的校準(zhǔn)的圖。結(jié)果表明,該模型不能學(xué)習(xí)KITTI上的概率分布,而能夠?qū)W習(xí)較大的ATG4D上的分布。
【實驗結(jié)果】

上表顯示了與其他最先進(jìn)的方法相比,LaserNet在驗證集上的結(jié)果。像KITTI基準(zhǔn)一樣,我們計算了汽車0.7 IoU和自行車及行人0:5 IoU的平均精度(AP)。在這個數(shù)據(jù)集上,LaserNet在0-70米范圍內(nèi)表現(xiàn)優(yōu)于現(xiàn)有的最先進(jìn)的方法。此外,LaserNet在所有距離上都優(yōu)于LiDAR-only方法,只有在附加圖像數(shù)據(jù)提供最大價值的長距離上,車輛和自行車上的LiDAR-RGB方法優(yōu)于LaserNet。

對ATG4D數(shù)據(jù)集進(jìn)行消融研究,結(jié)果如上表所示。
預(yù)測概率分布。預(yù)測概率分布最大的改進(jìn)是預(yù)測邊界框架的分布。當(dāng)僅預(yù)測平均邊界框時,公式(6)為簡單平均,公式(9)為框角損失。此外,邊界框的得分在本例中是類概率。實驗結(jié)果表明,性能上的損失是由于概率與邊界框架的準(zhǔn)確性沒有很好地相關(guān)性導(dǎo)致的。
圖像形成:Velodyne 64E激光雷達(dá)中的激光器并不是均勻間隔的。通過使用激光id將點映射到行,并在傳感器捕獲數(shù)據(jù)時直接處理數(shù)據(jù),可以獲得性能上的提高。
均值漂移聚類:每個點獨立地預(yù)測邊界框的分布,通過均值漂移聚類將獨立的預(yù)測組合起來實現(xiàn)降噪。
非極大值抑制:當(dāng)激光雷達(dá)的點稀疏時,有多個邊界框的配置可以解釋觀測到的數(shù)據(jù)。通過預(yù)測各點的多模態(tài)分布,進(jìn)一步提高了該方法的查全率。在生成多模態(tài)分布時,使用具有嚴(yán)格閾值的NMS是不合適的。或者,我們可以使用軟NMS來重新評估置信度,但是這打破了對置信度的概率解釋。通過自適應(yīng)NMS算法,保持了概率解釋,并獲得了更好的性能。

對于自動駕駛而言,運行時性能同樣重要。上表比較了LaserNet(在NVIDIA 1080Ti GPU上測量)和KITTI上現(xiàn)有方法的運行時的性能。Forward Pass是指運行網(wǎng)絡(luò)所花費的時間,除Forward Pass外,總時間還包括預(yù)處理和后處理。由于在一個小的密集的范圍視場內(nèi)處理,LaserNet比目前最先進(jìn)的方法快兩倍。

使用訓(xùn)練集中的5,985個掃描點訓(xùn)練網(wǎng)絡(luò),并保留其余的掃描以進(jìn)行驗證。使用與之前相同的學(xué)習(xí)時間表對網(wǎng)絡(luò)進(jìn)行5萬次迭代訓(xùn)練,并在單個GPU上使用12個批處理。為了避免在這個小的訓(xùn)練集上過度擬合,采用數(shù)據(jù)增強手段隨機翻轉(zhuǎn)范圍圖像,并在水平維度上隨機像素移動。在這樣一個小的數(shù)據(jù)集中,學(xué)習(xí)邊界框上的概率分布,特別是多模態(tài)分布是非常困難的。因此,訓(xùn)練網(wǎng)絡(luò)只檢測車輛并預(yù)測邊界框上的單峰概率分布。如上表所示,我們的方法在這個小數(shù)據(jù)集上的性能比當(dāng)前最先進(jìn)的鳥瞰圖檢測器差。
-
檢測器
+關(guān)注
關(guān)注
1文章
860瀏覽量
47651 -
激光雷達(dá)
+關(guān)注
關(guān)注
967文章
3938瀏覽量
189593 -
自動駕駛
+關(guān)注
關(guān)注
783文章
13682瀏覽量
166137
發(fā)布評論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論