") Adobe研究院的研究者們提出了全新的通用深度網(wǎng)絡架構(gòu)CPNet
Adobe研究院的研究者們提出了全新的通用深度網(wǎng)絡架構(gòu)CPNet
斯坦福大學和Adobe研究院的研究者們提出了全新的通用深度網(wǎng)絡架構(gòu)CPNet,用于學習視頻中圖片之間的長程對應關系,來解決現(xiàn)有方法在處理視頻長程運動中的局限性。在三大視頻分類數(shù)據(jù)集上取得了優(yōu)于之前結(jié)果的性能。相關論文獲CVPR 2019 oral。
這是一款全新的通用深度網(wǎng)絡架構(gòu)。
現(xiàn)有的視頻深度學習架構(gòu)通常依賴于三維卷積、自相關、非局部模塊等運算,這些運算難以捕捉視頻中幀間的長程運動/相關性。
近日,來自斯坦福和Adobe的研究人員,受到點云上深度學習方法的啟發(fā),提出了一個通用的深度網(wǎng)絡架構(gòu)CPNet,用于學習視頻中圖片之間的長程對應關系,來解決上述問題。

arXiv地址:
https://arxiv.org/abs/1905.07853
研究人員們所提出的CPNet是一個全新的通用的視頻深度學習框架。該網(wǎng)絡通過尋找對應的表征來學習視頻中圖片之間稀疏且不規(guī)則的對應模式,并且可以融合進現(xiàn)有的卷積神經(jīng)網(wǎng)絡架構(gòu)中。
研究人員在三個視頻分類數(shù)據(jù)集上進行了實驗,結(jié)果表明,CPNet在性能上取得了較大的突破。
CPNet:對應提議網(wǎng)絡
視頻是由一串圖片組成。然而,視頻并不是任意圖片隨機的堆砌,其前后幀有強烈的相關性,表現(xiàn)為一幀圖片中的物體通常會在其它幀中出現(xiàn)。
相比于單張靜態(tài)的圖片,這樣的對應關系構(gòu)成了視頻中動態(tài)的部分。我們總結(jié)視頻中圖片之間的對應關系有如下三大特點:
對應位置有相似的視覺或語義特征。這也是我們?nèi)祟惻卸▋蓭械南袼厥欠駥儆谕晃矬w的標準之一。
對應位置在空間維和時間維上都可以有任意長的距離。空間維上,物體可以很快從圖片的一端運動到另一端;時間維上,物體可以在視頻中存在任意長的時間。
潛在的對應位置所占比例為少數(shù)。對于一個像素/表征,在其它幀中通常只有極少的相似像素/表征是可能的對應,其它明顯不相似的像素/表征則可以忽略掉。換言之,對應關系存在不規(guī)則性和稀疏性。
那么什么樣的網(wǎng)絡架構(gòu)可以滿足上述特點呢?
三維卷積無法檢測相似性;自相關是局部操作,無法勝任長程對應;非局部模塊側(cè)重于注意力機制,無法適應稀疏性和不規(guī)則性,也無法學到長程運動的方向。因此我們需要全新的網(wǎng)絡架構(gòu)。
圖1
我們提出了對應提議網(wǎng)絡CPNet(Correspondence Proposal Network),其架構(gòu)能同時滿足上述三種特點。
核心思想如圖1所示:深度網(wǎng)絡架構(gòu)中,我們將視頻表征張量視為一個點云,在語義特征空間中(而非一般的時空空間),對于表征張量中的每一個表征即“點”,我們尋找其在其它幀里最近的k個“點”,并將其視為該表征的潛在對應。然后類似于點云上的深度學習,對于這k對“點”中的每一對,我們使用相同且互相獨立的神經(jīng)網(wǎng)絡處理他們的特征向量和位置,然后用最大池化操作從k個輸出中提取出最強的響應。本質(zhì)上,我們的網(wǎng)絡架構(gòu)可以學到從這k對潛在對應中選擇出最有趣的信息。如此一來,最后的輸出表征向量就包含了視頻中的動態(tài)信息。
CPNet的架構(gòu)
我們將網(wǎng)絡的核心命名為”CP模塊“,其結(jié)構(gòu)如下,大致分為兩個部分。輸入和輸出都是一個THW x C的視頻表征張量,我們將這兩者都視為一個THW個點的帶C維特征向量的點云。
第一個部分為語義特征空間k最近鄰算法,如圖2所示。我們先求出所有表征對之間的負L2語義距離得到THW x THW形狀的矩陣;然后將對角線上的T個HW x HW子矩陣的元素置為負無窮,這樣位于同一幀的表征就可以排除在潛在對應表征之外了。之后對每一行進行arg top k操作就可以得到潛在對應表征的下標。
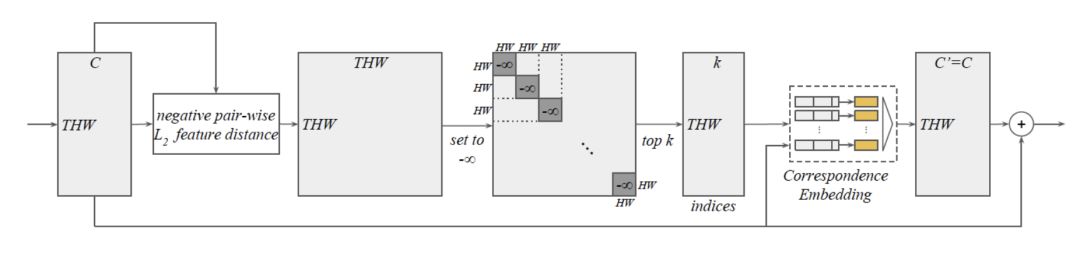
圖2
第二個部分為對應關系的學習。我們用上一步得到的下標從輸入視頻表征張量中提取出表征。對于每一個輸入表征和其k個最近鄰表征組成的k對表征對中的一對,我們將這一對表征的語義特征向量以及其之間的時空相對位置連在一起,得到k個長向量。然后我們將這k個長向量送入相同且互相獨立的多層感知器(MLP),然后再用元素級的最大池化操作(element-wise max-pooling)得到輸出向量,也就是輸出視頻表征張量該表征位置的語義特征向量。

圖3
為了防止訓練時梯度爆炸或消失,類似于ResNet中的跳躍連接,我們將上一步的輸出表征張量加回到了輸入表征張量中。可以看到,該模塊可以無縫銜接進現(xiàn)有的卷積神經(jīng)網(wǎng)絡架構(gòu)如ResNet中。在實驗中,所有CP模塊一開始初始化為全等操作,這樣我們就可以使用ImageNet預訓練模型來初始化網(wǎng)絡其它部分的參數(shù)。
實驗結(jié)果
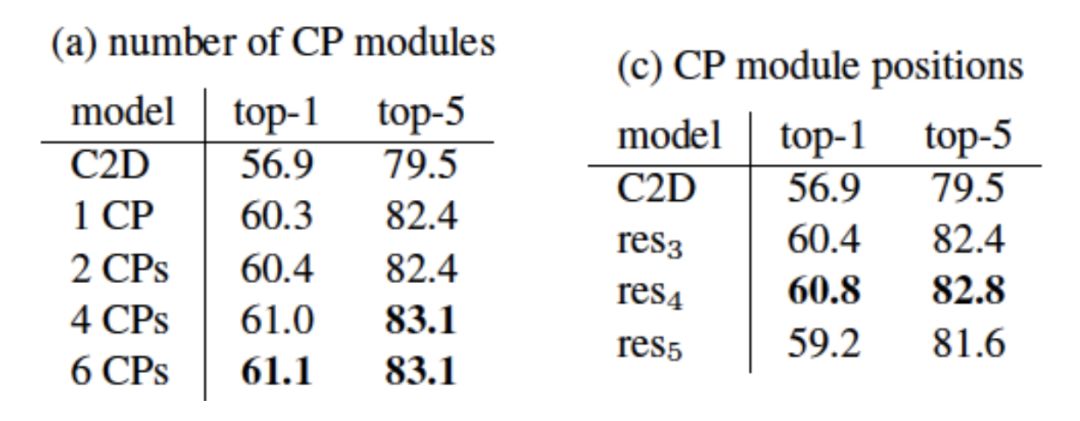
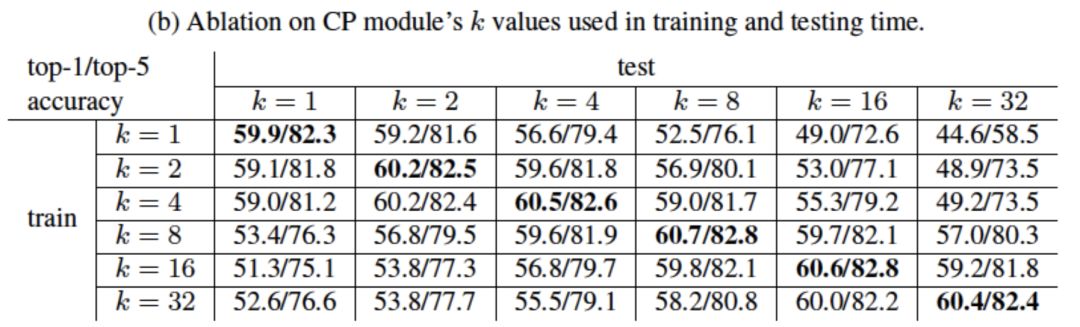
我們在大規(guī)模視頻分類數(shù)據(jù)集上進行了實驗。首先,我們在Kinetics數(shù)據(jù)集上進行了小規(guī)模模型的實驗來研究CP模塊的數(shù)量、位置以及k值的大小對視頻分類結(jié)果的影響。由結(jié)果可知,模型的性能隨CP模塊數(shù)量增多而提高并趨于飽和;CP模塊放置的位置對性能有影響;k值在訓練時和推理時保持一致且合適的值可以得到最佳性能。
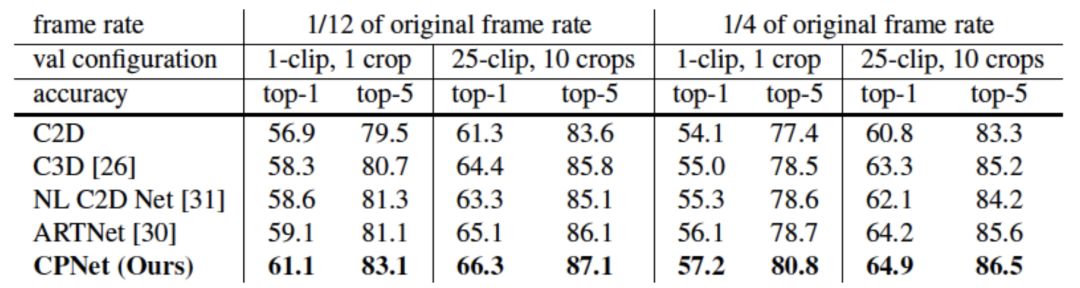
我們在Kinetics數(shù)據(jù)集上與其它已發(fā)表結(jié)果進行了比較。我們同時比較了小規(guī)模和大規(guī)模模型。CPNet在參數(shù)數(shù)量更少的情況下取得優(yōu)于之前結(jié)果的性能。
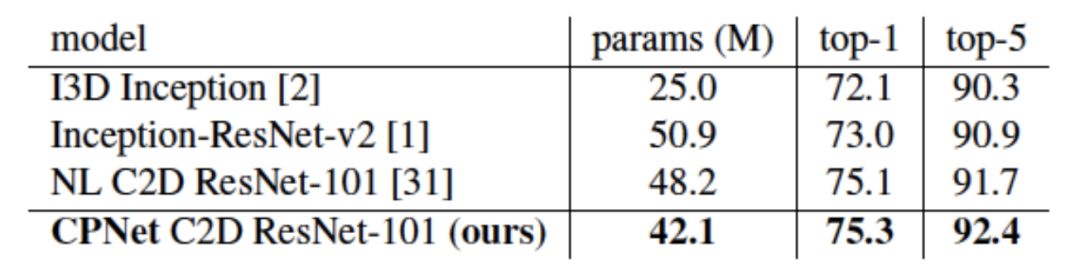
我們也在Something-Something和Jester數(shù)據(jù)集上與其它已發(fā)表結(jié)果進行了比較。相比于Kinetics,這兩個數(shù)據(jù)集更偏重動態(tài)信息對分類的影響。CPNet同樣在參數(shù)數(shù)量更少的情況下取得優(yōu)于之前結(jié)果。
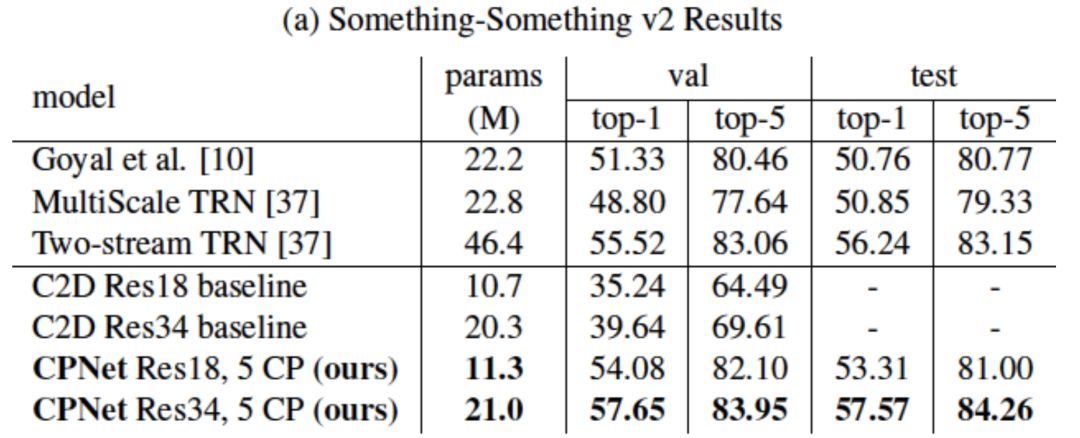
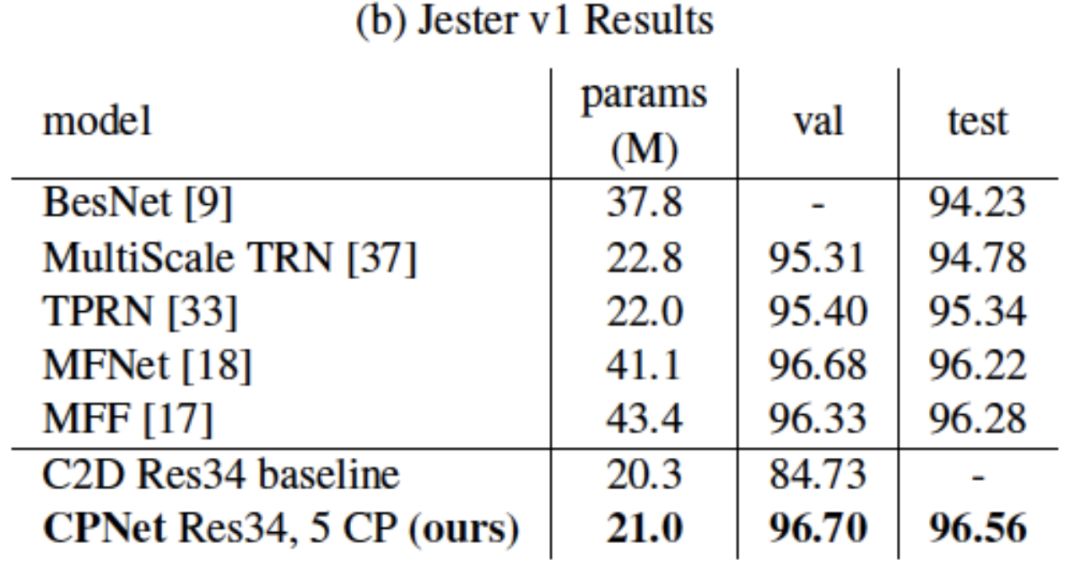
值得注意的是,相比于沒有CP模塊的基準二維卷積ResNet,CPNet僅僅額外加入了極少的參數(shù),就在這兩個數(shù)據(jù)集上得到了極大的性能提升,進一步證明了其學習視頻中動態(tài)信息的強大能力。
模型的可視化
我們對訓練好的模型進行了可視化來理解其工作原理。
我們選取了一個表征的位置,然后在圖片中用箭頭標注出其k個最近鄰表征的位置。特別地,我們用紅色箭頭標注出哪些最近鄰表征在最大池化過程中被選中。我們同時用熱圖來顯示表征圖在經(jīng)過CP模塊后的變化。

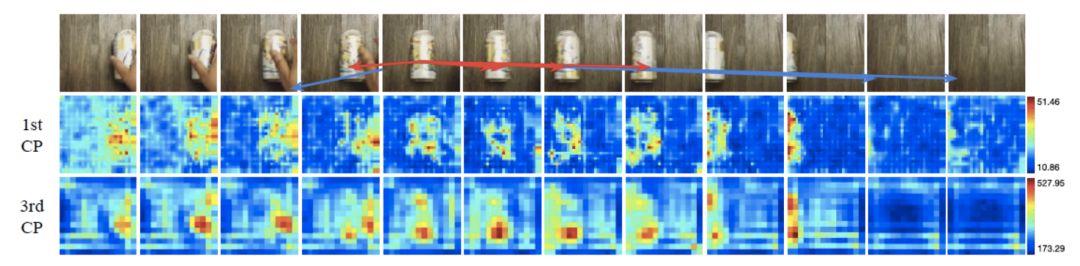
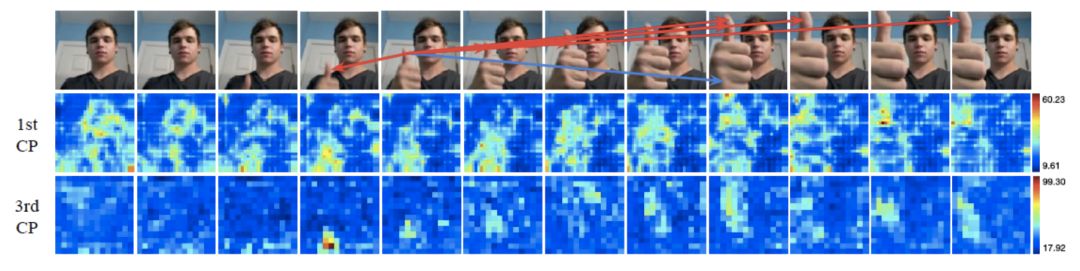
可以看到,通過語義特征的距離,CP模塊可以大致找到正確的潛在對應位置,例如上圖中的籃球、易拉罐和大拇指。
在上述例子中,對于錯誤的對應提議,CP模塊也能在最大池化過程中忽略掉它們。同時,熱圖顯示CP模塊對于處于運動狀態(tài)的圖片部分更加敏感。
-
矩陣
+關注
關注
0文章
422瀏覽量
34502 -
數(shù)據(jù)集
+關注
關注
4文章
1205瀏覽量
24644 -
深度學習
+關注
關注
73文章
5492瀏覽量
120978
原文標題:斯坦福&Adobe CVPR 19 Oral:全新通用深度網(wǎng)絡架構(gòu)CPNet
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論