") 人工智能 | 深度學(xué)習(xí)涉足美妝領(lǐng)域,網(wǎng)紅博主要失業(yè)?
人工智能 | 深度學(xué)習(xí)涉足美妝領(lǐng)域,網(wǎng)紅博主要失業(yè)?
場景描述:風(fēng)靡各大直播平臺的美妝博主,憑借高超的化妝技術(shù)吸金無數(shù)。而人工智能也已經(jīng)開始學(xué)習(xí)這一本領(lǐng)。利用深度學(xué)習(xí)與計算機視覺技術(shù),僅僅根據(jù)人的眼睛特征,就能給出適合用戶的美妝搭配。
關(guān)鍵詞:幾何變換 triplet 損失函數(shù) 遷移學(xué)習(xí)
近年來,網(wǎng)絡(luò)上涌現(xiàn)出越來越多的美妝博主,他們講解美妝技巧,分享化妝品試用效果,以此積累粉絲,與商家合作銷售產(chǎn)品。
比如,前段時間大火的李佳琦,被稱為「口紅魔鬼」的美妝博主。他曾瘋狂地在一次直播中一口氣試了380 種口紅色號,并創(chuàng)下一分鐘內(nèi)售出14,000 支口紅的紀(jì)錄。
然而,很多愛化妝的妹子應(yīng)該早有領(lǐng)悟,明明買了和博主一模一樣的口紅,可畫出來效果卻不一樣。看到「李佳琦」們試用的色號很美很仙很貴氣,可到了自己嘴上怎么就……
口紅界的「賣家秀」和「買家秀」
沒錯,正是因為每個人的臉型、膚色、唇形等等都不一樣,才導(dǎo)致了「賣家秀」和「買家秀」的結(jié)果。
那么問題來了,怎樣才能知道最適合自己的美妝產(chǎn)品是哪款呢?一個叫做 Mira 的公司給出的答案是:用深度學(xué)習(xí)。
深度學(xué)習(xí)也愛美妝
許多人印象中,人工智能、深度學(xué)習(xí)這些名詞和美妝應(yīng)該八竿子打不著關(guān)系,但位于美國洛杉磯的創(chuàng)企 Mira 可不這么想。
這家公司決定用人工智能技術(shù)幫助廣大愛美女士,比如獲取化妝靈感,購買合適的美妝產(chǎn)品等。
美妝前后,效果堪比換臉
在隨機和數(shù)十位美妝人士詳聊后,Mira 團隊了解到,目前女性消費者在尋找合適的化妝產(chǎn)品和美妝方法時,遇到的最大困難是,沒有權(quán)威且可信的聲音能針對她們個人的美容需求做出指導(dǎo)。
在本文我們就聊聊 Mira 的技術(shù)團隊如何用深度學(xué)習(xí)和計算機視覺技術(shù)發(fā)現(xiàn)切中這個問題要害的實例:找到講解人類具體眼型和面部膚色的美妝大咖、圖片和視頻等信息。
沿著這種方式, Mira 團隊借助三個簡單但強大的知識——幾何變換、triplet 損失函數(shù)和遷移學(xué)習(xí),只用最小限度的人類輸入數(shù)據(jù)就能解決種種困難的美妝推斷問題。
AI 幫你選擇最合適的眼妝
眼部分類示意圖
愛化妝的女士都知道,找到適合自己眼睛的美妝產(chǎn)品和方法是很困難的——每個人的眼型和面部膚色都不一樣。
即便是同一種眼妝(比如煙熏妝),根據(jù)眼型不同,所用的化妝方法也大不相同。
雖然像 Birchbox 等推出了一些有用的化妝指南,但 Mira 團隊經(jīng)過調(diào)查發(fā)現(xiàn),美妝愛好者們通常還是喜歡聽聽專業(yè)且可信的建議,尤其是和自己眼型相似的人的化妝建議,她們對這些建議的重視程度甚至都超過了美容專家的意見。
利用人工智能技術(shù),現(xiàn)在我們根據(jù)自己的眼部特征,以及自己其它獨特的面部特征,就能讓自己知道怎么化妝、買什么化妝品。
AI 美妝第一步:尋找相似性
我們把問題形式化一下:根據(jù)一組面部照片,以及少許數(shù)量的人工標(biāo)記的照片(標(biāo)記了眼睛顏色、眼瞼形狀等),找到兩個眼睛之間的視覺相似性度量(《紅樓夢》中「這個妹妹我曾見過的」就是這個意思)。然后用分類器捕捉人工標(biāo)記的屬性。
本文先重點講解如何確定眼睛之間的相似度,后面會詳細(xì)解釋如何進行分類任務(wù)。
原始圖像并不是很適合計算視覺相似性或者進行分類任務(wù)。因為它們包含的很多相似性都是表面上的(比如畫的妝很相似,由于強光才造成膚色看起來不同)。
而這些和人物真正的眼部結(jié)構(gòu)及面部膚色并沒有關(guān)系。而且,原始圖像一般都處于高維空間,這就需要大量的有標(biāo)記訓(xùn)練數(shù)據(jù)用于分類任務(wù)。
如上圖,如果僅直接比較圖像像素,人物的眼睛都高度相似,但仔細(xì)注意會發(fā)現(xiàn),雖然人物的眼影、光線和視線方向一致,但她們的眼睛顏色和面部膚色卻各不相同。
處理原始圖像的困難所在:雖然上圖兩人的眼睛大不相同,但初始數(shù)據(jù)比較起來卻很相似
那么 Mira 的首要任務(wù)就是:要獲得眼部照片的低維和密集的數(shù)學(xué)表達形式,也就是我們所說的「嵌套」(embeddings)。
它只會捕捉任務(wù)所需的圖像品質(zhì)(嵌套是一種分類特征,以連續(xù)值特征表示。通常,嵌套是指將高維度向量映射到低維度的空間。)這樣一來,「嵌套」應(yīng)當(dāng)忽略這些信息:
眼睛姿勢/視線方向
具體的光線狀況(當(dāng)然還有強大的濾鏡這些)
不管是臉部畫了什么樣的妝
當(dāng)用三重函數(shù)訓(xùn)練眼睛嵌入時,系統(tǒng)學(xué)會了忽略不相關(guān)特征
AI 美妝第二步:投影變換進行圖像歸一化
我們可以通過一個簡單的預(yù)處理步驟——投影變化刪除一整個類別的表面相似性。
雖然裁減過的眼部照片會出現(xiàn)很多明顯的結(jié)構(gòu)性差異(比如眼睛不在照片中心,或者由于頭部傾斜的原因出現(xiàn)旋轉(zhuǎn)等),但投影變化能讓我們「扭曲」照片,這樣就能保證相同的眼部標(biāo)志處于相同的坐標(biāo)。
借助一丁點的線性代數(shù)原理,我們就可以將一張圖像「扭曲」,這樣一組點會映射為一個新的理想的形狀。旋轉(zhuǎn)和拉伸圖像的過程如下所示:
使用投影變化,可以將上面的圖像進行扭曲處理,上圖中的 4 個紅點會組成一個矩形,從而將紅點圍住的文本「拉直」。Mira 團隊在將眼部照片進行正常化處理時,應(yīng)用了同樣的方法。
研究人員接用 dlib 檢測出臉部標(biāo)記(如果你對 dlib 感興趣,可以在以下鏈接中了解:http://blog.dlib.net/2014/08/real-time-face-pose-estimation.html)。
剪裁照片中的眼部部位,將其「扭曲」處理,確保它們對齊和一致。這步操作能讓他們專注于讓「嵌套」不受人物頭部姿勢和傾斜角度的影響。
接著進行圖像歸一化:檢測出面部標(biāo)志,剪裁眼部圖像,然后用投影轉(zhuǎn)換將眼部圖像「扭曲」至標(biāo)準(zhǔn)位置。
圖像預(yù)處理流程中的圖像樣本
AI 美妝第三步:用 triplet 損失函數(shù)進行表示學(xué)習(xí)
「扭曲」處理后的圖像進行直接比較時,仍會表現(xiàn)出一些表面相似性,包括視線方向和相似的化妝等。深度學(xué)習(xí)技術(shù)就是解決這個問題的藥方。
研究人員訓(xùn)練了一個卷積神經(jīng)網(wǎng)絡(luò),用眼部照片輸入它后會輸出向量,相比不同人之間,同一個人眼部照片輸出的向量更具相似性。神經(jīng)網(wǎng)絡(luò)會學(xué)習(xí)輸出每個人眼在不同環(huán)境下的穩(wěn)定持續(xù)的表示形式。
當(dāng)然,這里所以靠的正是前面所說的triplet 損失函數(shù),其公式如下所示:
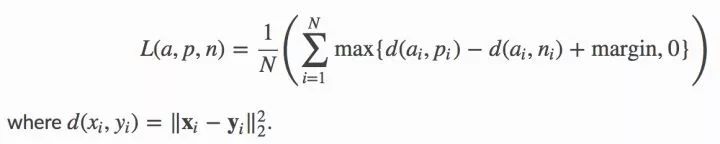
這詳細(xì)說明了當(dāng)函數(shù)將具體個體(錨點和正樣本)的兩個「嵌套」放置的位置比錨點和無關(guān)個體(負(fù)樣本)的位置更近時,模型的損失和優(yōu)化目標(biāo)會遞減。
模型架構(gòu)示意圖
當(dāng)研究人員將眼部照片應(yīng)用到模型中時,他們發(fā)現(xiàn)生成的「嵌套」很好地指出了具有相似眼部結(jié)構(gòu)和面部膚色的兩張照片。
眼部嵌套相似的照片示例
這里所用的方法其實和谷歌的FaceNet 很像,也就是通過對照片進行「扭曲」和一致性處理,應(yīng)用 triplet 損失函數(shù),生成臉部級別的圖像嵌套。
AI 美妝第四步:合并嵌套
研究人員對生成的嵌套進行了簡單調(diào)試,讓其同樣適用于支持人級(Person-level)的眼部表示——提取出每個幀的全部噪聲數(shù)據(jù)。
通過使用上面神經(jīng)網(wǎng)絡(luò)的預(yù)訓(xùn)練權(quán)重,研究人員又采用了新的損失函數(shù),該函數(shù)將多組嵌套的平均值放在極為相近的位置(相對于無關(guān)個體),如下所示:
使用先前神經(jīng)網(wǎng)絡(luò)的預(yù)訓(xùn)練權(quán)重,研究人員可以讓網(wǎng)絡(luò)能夠以求平均值的方式將眼部嵌套合并在一起,能看到模型快速收斂。這個過程就是常說的遷移學(xué)習(xí)。
遷移學(xué)習(xí)讓嵌套能夠合并為一個個體眼睛的更為整體的表示。雖然此時神經(jīng)網(wǎng)絡(luò)架構(gòu)非常復(fù)雜了,但模型由于采用了遷移學(xué)習(xí)的原因能夠快速收斂。
最終,研究人員用數(shù)據(jù)集對模型進行了驗證,發(fā)現(xiàn)模型生成的嵌套能夠捕捉個體之間的很細(xì)微的相似性,如下所示:
每一行人物的眼部嵌套之間非常相似
看你一眼,就給出完美妝容建議
通過獲得單張照片中人眼的高質(zhì)量數(shù)學(xué)表示,研究人員就能找出人物眼睛構(gòu)造的相似性,這就為只根據(jù)人的眼睛,為他/她匹配合適的眼妝風(fēng)格打下了基礎(chǔ)。
Mira 技術(shù)團隊表示接下來的任務(wù)是應(yīng)用幾種監(jiān)督式學(xué)習(xí)方法(分類眼型、回歸眼睛顏色等),以及一些分析方法,搭建出能為人們提供化妝建議的 AI 模型。
也就是說,未來,妹子們不必再發(fā)愁畫什么樣的妝最適合自己的眼睛和膚色了,更不必機械地參考標(biāo)準(zhǔn)化妝指南和美妝博主試色效果,AI 會為你推薦更適合你自己的美妝術(shù)。
如此一來,美妝博主們恐怕要被搶飯碗了?不過,李佳琦也不用再那么辛苦地,在一次直播中試色 380 次了。
注:本文所有代碼和結(jié)果的實現(xiàn)用到了 NumPy,SciPy,Matplotlib,Chainer,dlib 和 SqueezeNet 架構(gòu)。
超神經(jīng)百科
遷移學(xué)習(xí)
遷移學(xué)習(xí)是一種機器學(xué)習(xí)方法,就是把為任務(wù) A 開發(fā)的模型作為初始點,重新使用在為任務(wù) B 開發(fā)模型的過程中。
深度學(xué)習(xí)中,在計算機視覺任務(wù)和自然語言處理任務(wù)中,將預(yù)訓(xùn)練的模型作為新模型的起點是一種常用的方法,通常這些預(yù)訓(xùn)練的模型在開發(fā)神經(jīng)網(wǎng)絡(luò)的時候已經(jīng)消耗了巨大的時間資源和計算資源,遷移學(xué)習(xí)可以將已習(xí)得的強大技能遷移到相關(guān)的的問題上。
以下是兩個常用的方法:
1. 開發(fā)模型的方法
2. 預(yù)訓(xùn)練模型的方法
-
人工智能
+關(guān)注
關(guān)注
1791文章
46859瀏覽量
237584 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5492瀏覽量
120978
原文標(biāo)題:深度學(xué)習(xí)涉足美妝領(lǐng)域,網(wǎng)紅博主要失業(yè)?
文章出處:【微信號:TheBigData1024,微信公眾號:人工智能與大數(shù)據(jù)技術(shù)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
嵌入式和人工智能究竟是什么關(guān)系?
人工智能、機器學(xué)習(xí)和深度學(xué)習(xí)存在什么區(qū)別

《AI for Science:人工智能驅(qū)動科學(xué)創(chuàng)新》第6章人AI與能源科學(xué)讀后感
《AI for Science:人工智能驅(qū)動科學(xué)創(chuàng)新》第一章人工智能驅(qū)動的科學(xué)創(chuàng)新學(xué)習(xí)心得
risc-v在人工智能圖像處理應(yīng)用前景分析
人工智能ai4s試讀申請
名單公布!【書籍評測活動NO.44】AI for Science:人工智能驅(qū)動科學(xué)創(chuàng)新
報名開啟!深圳(國際)通用人工智能大會將啟幕,國內(nèi)外大咖齊聚話AI
FPGA在人工智能中的應(yīng)用有哪些?
人工智能大模型在工業(yè)網(wǎng)絡(luò)安全領(lǐng)域的應(yīng)用
人工智能、機器學(xué)習(xí)和深度學(xué)習(xí)是什么
人工智能深度學(xué)習(xí)的五大模型及其應(yīng)用領(lǐng)域
機器學(xué)習(xí)怎么進入人工智能
嵌入式人工智能的就業(yè)方向有哪些?
深度學(xué)習(xí)在人工智能中的 8 種常見應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論