") 深度學(xué)習(xí)和普通機(jī)器學(xué)習(xí)的區(qū)別
深度學(xué)習(xí)和普通機(jī)器學(xué)習(xí)的區(qū)別
文章標(biāo)題是個很有趣的問題,深度學(xué)習(xí)作為機(jī)器學(xué)習(xí)的子集,它和普通機(jī)器學(xué)習(xí)之間到底有什么區(qū)別呢?作者使用了一種很普通的方式來回答這個問題。
本質(zhì)上,深度學(xué)習(xí)提供了一套技術(shù)和算法,這些技術(shù)和算法可以幫助我們對深層神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)進(jìn)行參數(shù)化——人工神經(jīng)網(wǎng)絡(luò)中有很多隱含層數(shù)和參數(shù)。深度學(xué)習(xí)背后的一個關(guān)鍵思想是從給定的數(shù)據(jù)集中提取高層次的特征。因此,深度學(xué)習(xí)的目標(biāo)是克服單調(diào)乏味的特征工程任務(wù)的挑戰(zhàn),并幫助將傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)進(jìn)行參數(shù)化。
現(xiàn)在,為了引入深度學(xué)習(xí),讓我們來看看一個更具體的例子,這個例子涉及多層感知器(MLP)。
在MLP中,“感知器”這個詞可能有點讓人困惑,因為我們并不想只在我們的網(wǎng)絡(luò)中使用線性神經(jīng)元。利用MLP,我們可以學(xué)習(xí)復(fù)雜的函數(shù)來解決非線性問題。因此,我們的網(wǎng)絡(luò)通常由連接輸入和輸出層的一個或多個“隱藏”層組成。這些隱藏的層通常有某種S型的激活函數(shù)(logs-s形或雙曲正切等)。例如,在我們的網(wǎng)絡(luò)中,一個邏輯回歸單元,返回0-1范圍內(nèi)的連續(xù)值。
一個簡單的MLP看起來就像這樣:
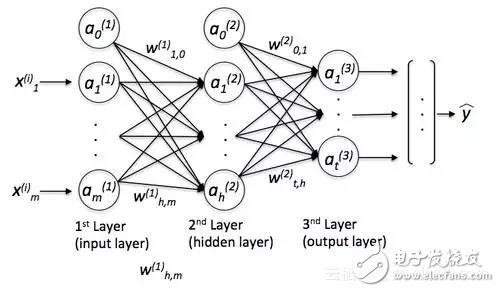
其中y是最終的類標(biāo)簽,我們返回的是基于輸入x的預(yù)測,“a”是我們激活的神經(jīng)元,而“w”是權(quán)重系數(shù)。現(xiàn)在,如果我們向這個MLP添加多個隱藏層,我們也會把網(wǎng)絡(luò)稱為“深度”。這種“深度”網(wǎng)絡(luò)的問題在于,為這個網(wǎng)絡(luò)學(xué)習(xí)“好”的權(quán)重變得越來越難。當(dāng)我們開始訓(xùn)練我們的網(wǎng)絡(luò)時,我們通常會將隨機(jī)值賦值為初始權(quán)重,這與我們想要找到的“最優(yōu)”解決方案很不一樣。在訓(xùn)練過程中,我們使用流行的反向傳播算法(將其視為反向模式自動微分)來傳播從右到左的“錯誤”,并計算每一個權(quán)重的偏導(dǎo)數(shù),從而向成本(或“錯誤”)梯度的相反方向邁進(jìn)。現(xiàn)在,深度神經(jīng)網(wǎng)絡(luò)的問題是所謂的“消失梯度”——我們添加的層越多,就越難“更新”我們的權(quán)重,因為信號變得越來越弱。由于我們的網(wǎng)絡(luò)的權(quán)重在開始時可能非常糟糕(隨機(jī)初始化),因此幾乎不可能用反向傳播來參數(shù)化一個具有“深度”的神經(jīng)網(wǎng)絡(luò)。
這就是深度學(xué)習(xí)發(fā)揮作用的地方。粗略地說,我們可以把深度學(xué)習(xí)看作是一種“聰明”的技巧或算法,可以幫助我們訓(xùn)練這種“深度”神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)。有許多不同的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),但是為了繼續(xù)以MLP為例,讓我來介紹卷積神經(jīng)網(wǎng)絡(luò)(CNN)的概念。我們可以把它看作是我們的MLP的“附加組件”,它可以幫助我們檢測到我們的MLP“好”的輸入。
在一般機(jī)器學(xué)習(xí)的應(yīng)用中,通常有一個重點放在特征工程部分;算法學(xué)習(xí)的模型只能是和輸入數(shù)據(jù)一樣好。當(dāng)然,我們的數(shù)據(jù)集必須要有足夠多的、具有辨別能力的信息,然而,當(dāng)信息被淹沒在無意義的特征中,機(jī)器學(xué)習(xí)算法的性能就會受到嚴(yán)重影響。深度學(xué)習(xí)的目的是從雜亂的數(shù)據(jù)中自動學(xué)習(xí);這是一種算法,它為我們提供了具有意義的深層神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu),使其能夠更有效地學(xué)習(xí)。我們可以把深度學(xué)習(xí)看作是自動學(xué)習(xí)“特征工程”的算法,或者我們也可以簡單地稱它們?yōu)椤疤卣?a target="_blank">探測器”,它可以幫助我們克服一系列挑戰(zhàn),并促進(jìn)神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)。
讓我們在圖像分類的背景下考慮一個卷積神經(jīng)網(wǎng)絡(luò)。在這里,我們使用所謂的“接收域”(將它們想象成“窗口”),它們會經(jīng)過我們的圖像。然后,我們將這些“接受域”(例如5x5像素的大小)和下一層的1個單元連接起來,這就是所謂的“特征圖”。在這個映射之后,我們構(gòu)建了一個所謂的卷積層。注意,我們的特征檢測器基本上是相互復(fù)制的——它們共享相同的權(quán)重。它的想法是,如果一個特征檢測器在圖像的某個部分很有用,它很可能在其他地方也有用,與此同時,它還允許用不同的方式表示圖像的各個部分。
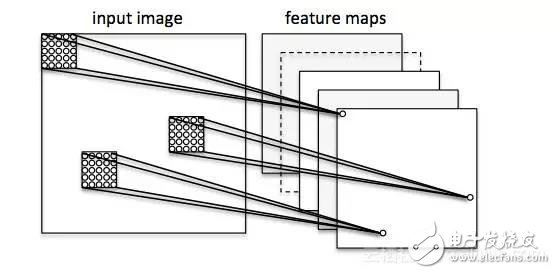
接下來,我們有一個“池”層,在這個層中,我們將我們的特征映射中的相鄰特征減少為單個單元(例如,通過獲取最大特征,或者對其進(jìn)行平均化)。我們在很多測試中都這樣做,最終得出了我們的圖像的幾乎不不變的表示形式(確切的說法是“等變量”)。這是非常強(qiáng)大的,因為無論它們位于什么位置,我們都可以在圖像中檢測到對象。
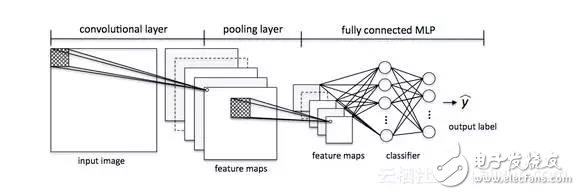
本質(zhì)上,CNN這個附加組件在我們的MLP中充當(dāng)了特征提取器或過濾器。通過卷積層,我們可以從圖像中提取有用的特征,通過池層,我們可以使這些特征在縮放和轉(zhuǎn)換方面有一定的不同。
-
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8382瀏覽量
132439 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5493瀏覽量
120998
發(fā)布評論請先 登錄
相關(guān)推薦
機(jī)器學(xué)習(xí)和深度學(xué)習(xí)的區(qū)別在哪?看完就知道了
一文詳解機(jī)器學(xué)習(xí)和深度學(xué)習(xí)的區(qū)別

如何區(qū)分深度學(xué)習(xí)與機(jī)器學(xué)習(xí)

一文讀懂深度學(xué)習(xí)與機(jī)器學(xué)習(xí)的差異

5分鐘內(nèi)看懂機(jī)器學(xué)習(xí)和深度學(xué)習(xí)的區(qū)別
深度學(xué)習(xí)和機(jī)器學(xué)習(xí)的六個本質(zhì)區(qū)別你知道幾個?
深度學(xué)習(xí)與機(jī)器學(xué)習(xí)的區(qū)別是什么
從五個方面詳談機(jī)器學(xué)習(xí)和深度學(xué)習(xí)的區(qū)別
機(jī)器學(xué)習(xí)和深度學(xué)習(xí)的關(guān)鍵區(qū)別
機(jī)器學(xué)習(xí)和深度學(xué)習(xí)有什么區(qū)別?

人工智能與機(jī)器學(xué)習(xí)、深度學(xué)習(xí)的區(qū)別

AI、機(jī)器學(xué)習(xí)和深度學(xué)習(xí)的區(qū)別及應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論