") 如何使用TensorFlow2.0構(gòu)建和部署端到端的圖像分類器
如何使用TensorFlow2.0構(gòu)建和部署端到端的圖像分類器
2019 年 3 月 6 日,谷歌在 TensorFlow 開發(fā)者年度峰會(huì)上發(fā)布了最新版的 TensorFlow 框架 TensorFlow2.0 。新版本對(duì) TensorFlow 的使用方式進(jìn)行了重大改進(jìn),使其更加靈活和更具人性化。具體的改變和新增內(nèi)容可以從 TensorFlow 的官網(wǎng)找到,本文將介紹如何使用 TensorFlow2.0 構(gòu)建和部署端到端的圖像分類器,以及新版本中的新增內(nèi)容,包括:
使用 TensorFlow Datasets 下載數(shù)據(jù)并進(jìn)行預(yù)處理
使用 Keras 高級(jí) API 構(gòu)建和訓(xùn)練圖像分類器
下載 InceptionV3 卷積神經(jīng)網(wǎng)絡(luò)并對(duì)其進(jìn)行微調(diào)
使用 TensorFlow Serving 為訓(xùn)練好的模型發(fā)布服務(wù)接口
本教程的所有源代碼都已發(fā)布到 GitHub 庫(kù)中,有需要的讀者可下載使用。
項(xiàng)目地址:
https://github.com/himanshurawlani/practical_intro_to_tf2
在此之前,需要提前安裝 TF nightly preview,其中包含 TensorFlow 2.0 alpha 版本,代碼如下:
$pipinstall-U--pretensorflow
1. 使用 TensorFlow Datasets 下載數(shù)據(jù)并進(jìn)行預(yù)處理
TensorFlow Datasets 提供了一組可直接用于 TensorFlow 的數(shù)據(jù)集,它能夠下載和準(zhǔn)備數(shù)據(jù),并最終將數(shù)據(jù)集構(gòu)建成 tf.data.Dataset 形式。
通過 pip 安裝 TensorFlow Datasets 的 python 庫(kù),代碼如下:
$ pip install tfds-nightly
1.1 下載數(shù)據(jù)集
TensorFlow Datasets 中包含了許多數(shù)據(jù)集,按照需求添加自己的數(shù)據(jù)集。
具體的操作方法可見:
https://github.com/tensorflow/datasets/blob/master/docs/add_dataset.md
如果我們想列出可用的數(shù)據(jù)集,可以用下面的代碼:
import tensorflow_datasets as tfdsprint(tfds.list_builders())
在下載數(shù)據(jù)集之前,我們最好先了解下該數(shù)據(jù)集的詳細(xì)信息,例如該數(shù)據(jù)集的功能信息和統(tǒng)計(jì)信息等。本文將使用 tf_flowers 數(shù)據(jù)集,該數(shù)據(jù)集的詳細(xì)信息可以在 TensorFlow 官網(wǎng)找到,具體內(nèi)容如下:
數(shù)據(jù)集的總可下載大小
通過 tfds.load() 返回的數(shù)據(jù)類型/對(duì)象
數(shù)據(jù)集是否已定義了標(biāo)準(zhǔn)分割形式:訓(xùn)練、驗(yàn)證和測(cè)試的大小
對(duì)于本文即將使用的 tf_flowers 數(shù)據(jù)集,其大小為 218MB,返回值為 FeaturesDict 對(duì)象,尚未進(jìn)行分割。由于該數(shù)據(jù)集尚未定義標(biāo)準(zhǔn)分割形式,我們將利用 subsplit 函數(shù)將數(shù)據(jù)集分割為三部分,80% 用于訓(xùn)練,10% 用于驗(yàn)證,10% 用于測(cè)試;然后使用 tfds.load() 函數(shù)來(lái)下載數(shù)據(jù),該函數(shù)需要特別注意一個(gè)參數(shù) as_supervised,該參數(shù)設(shè)置為 as_supervised=True,這樣函數(shù)就會(huì)返回一個(gè)二元組 (input, label) ,而不是返回 FeaturesDict ,因?yàn)槎M的形式更方便理解和使用;接下來(lái),指定 with_info=True ,這樣就可以得到函數(shù)處理的信息,以便加深對(duì)數(shù)據(jù)的理解,代碼如下:
import tensorflow_datasets as tfdsSPLIT_WEIGHTS = (8, 1, 1)splits = tfds.Split.TRAIN.subsplit(weighted=SPLIT_WEIGHTS)(raw_train, raw_validation, raw_test), metadata = tfds.load(name="tf_flowers", with_info=True, split=list(splits),# specifying batch_size=-1 will load full dataset in the memory# batch_size=-1,# as_supervised: `bool`, if `True`, the returned `tf.data.Dataset`# will have a 2-tuple structure `(input, label)` as_supervised=True)
1.2 對(duì)數(shù)據(jù)集進(jìn)行預(yù)處理
從 TensorFlow Datasets 中下載的數(shù)據(jù)集包含很多不同尺寸的圖片,我們需要將這些圖像的尺寸調(diào)整為固定的大小,并且將所有像素值都進(jìn)行標(biāo)準(zhǔn)化,使得像素值的變化范圍都在 0~1 之間。這些操作顯得繁瑣無(wú)用,但是我們必須進(jìn)行這些預(yù)處理操作,因?yàn)樵谟?xùn)練一個(gè)卷積神經(jīng)網(wǎng)絡(luò)之前,我們必須指定它的輸入維度。不僅如此,網(wǎng)絡(luò)中最后全連接層的 shape 取決于 CNN 的輸入維度,因此這些預(yù)處理的操作是很有必要的。
如下所示,我們將構(gòu)建函數(shù) format_exmaple(),并將它傳遞給 raw_train, raw_validation 和 raw_test 的映射函數(shù),從而完成對(duì)數(shù)據(jù)的預(yù)處理。需要指明的是,format_exmaple() 的參數(shù)和傳遞給 tfds.load() 的參數(shù)有關(guān):如果 as_supervised=True,那么 tfds.load() 將下載二元組 (image, labels) ,該二元組將作為參數(shù)傳遞給 format_exmaple();如果 as_supervised=False,那么 tfds.load() 將下載一個(gè)字典
def format_example(image, label): image = tf.cast(image, tf.float32) # Normalize the pixel values image = image / 255.0 # Resize the image image = tf.image.resize(image, (IMG_SIZE, IMG_SIZE)) return image, labeltrain = raw_train.map(format_example)validation = raw_validation.map(format_example)test = raw_test.map(format_example)
除此之外,我們還對(duì) train 對(duì)象調(diào)用 .shuffle(BUFFER_SIZE) ,用于打亂訓(xùn)練集的順序,該操作能夠消除樣本的次序偏差。Shuffle 的緩沖區(qū)大小最后設(shè)置得和數(shù)據(jù)集一樣大,這樣能夠保證數(shù)據(jù)被充分的打亂。接下來(lái)我們要用 .batch(BATCH_SIZE) 來(lái)定義這三類數(shù)據(jù)集的 batch 大小,這里我們將 batch 的大小設(shè)置為 32 。最后我們用 .prefetch() 在后臺(tái)預(yù)加載數(shù)據(jù),該操作能夠在模型訓(xùn)練的時(shí)候進(jìn)行,從而減少訓(xùn)練時(shí)間,下圖直觀地描述了 .prefetch() 的作用。
不采取 prefetch 操作,CPU 和 GPU/TPU 的大部分時(shí)間都處在空閑狀態(tài)
采取 prefetch 操作后,CPU 和 GPU/TPU 的空閑時(shí)間顯著較少
在該步驟中,有幾點(diǎn)值得注意:
操作順序很重要。如果先執(zhí)行 .shuffle() 操作,再執(zhí)行 .repeat() 操作,那么將進(jìn)行跨 batch 的數(shù)據(jù)打亂操作,每個(gè) epoch 中的 batch 數(shù)據(jù)都是被提前打亂的,而不用每次加載一個(gè) batch 就打亂依一次它的數(shù)據(jù)順序;如果先執(zhí)行 .repeat() 操作,再執(zhí)行 .shuffle() 操作,那么每次只有單個(gè) batch 內(nèi)的數(shù)據(jù)次序被打亂,而不會(huì)進(jìn)行跨 batch 的數(shù)據(jù)打亂操作。
將 buffer_size 設(shè)置為和數(shù)據(jù)集大小一樣,這樣數(shù)據(jù)能夠被充分的打亂,但是 buffer_size 過大會(huì)導(dǎo)致消耗更多的內(nèi)存。
在開始進(jìn)行打亂操作之前,系統(tǒng)會(huì)分配一個(gè)緩沖區(qū),用于存放即將進(jìn)行打亂的數(shù)據(jù),因此在數(shù)據(jù)集開始工作之前,過大的 buffer_size 會(huì)導(dǎo)致一定的延時(shí)。
在緩沖區(qū)沒有完全釋放之前,正在執(zhí)行打亂操作的數(shù)據(jù)集不會(huì)報(bào)告數(shù)據(jù)集的結(jié)尾。而數(shù)據(jù)集會(huì)被 .repeat() 重啟,這將會(huì)又一次導(dǎo)致 3 中提到的延時(shí)。
上面提到的 .shuffle ()和 .repeat(),可以用 tf.data.Dataset.apply() 中的 tf.data.experimental.shuffle_and_repeat() 來(lái)代替:
ds = image_label_ds.apply( tf.data.experimental.shuffle_and_repeat(buffer_size=image_count))ds = ds.batch(BATCH_SIZE)ds = ds.prefetch(buffer_size=AUTOTUNE)
1.3 數(shù)據(jù)增廣
數(shù)據(jù)增廣是提高深度學(xué)習(xí)模型魯棒性的重要技術(shù),它可以防止過擬合,并且能夠幫助模型理解不同數(shù)據(jù)類的獨(dú)有特征。例如,我們想要得到一個(gè)能區(qū)分“向日葵”和“郁金香”的模型,如果模型只學(xué)習(xí)了花的顏色從而進(jìn)行辨別,那顯然是不夠的。我們希望模型能夠理解花瓣的形狀和相對(duì)大小,是否存在圓盤小花等等。
為了防止模型使用顏色作為主要的判別依據(jù),可以使用黑白圖片或者改變圖片的亮度參數(shù)。為了減小圖片拍攝方向?qū)е碌钠睿梢噪S機(jī)旋轉(zhuǎn)數(shù)據(jù)集中的圖片,依次類推,可以得到更多增廣的圖像。
在訓(xùn)練階段,對(duì)數(shù)據(jù)進(jìn)行實(shí)時(shí)增廣操作,而不是手動(dòng)的將這些增廣圖像添加到數(shù)據(jù)上。用如下所示的映射函數(shù)來(lái)實(shí)現(xiàn)不同類型的數(shù)據(jù)增廣:
defaugment_data(image,label): print("Augment data called!") image = tf.image.random_flip_left_right(image) image = tf.image.random_contrast(image, lower=0.0, upper=1.0) # Add more augmentation of your choice return image, labeltrain = train.map(augment_data)
1.4 數(shù)據(jù)集可視化
通過可視化數(shù)據(jù)集中的一些隨機(jī)樣本,不僅可以發(fā)現(xiàn)其中存在的異常或者偏差,還可以發(fā)現(xiàn)特定類別的圖像的變化或相似程度。使用 train.take() 可以批量獲取數(shù)據(jù)集,并將其轉(zhuǎn)化為 numpy 數(shù)組, tfds.as_numpy(train) 也具有相同的作用,如下代碼所示:
plt.figure(figsize=(12,12)) for batch in train.take(1): for i in range(9): image, label = batch[0][i], batch[1][i] plt.subplot(3, 3, i+1) plt.imshow(image.numpy()) plt.title(get_label_name(label.numpy())) plt.grid(False) # ORfor batch in tfds.as_numpy(train): for i in range(9): image, label = batch[0][i], batch[1][i] plt.subplot(3, 3, i+1) plt.imshow(image) plt.title(get_label_name(label)) plt.grid(False) # We need to break the loop else the outer loop # will loop over all the batches in the training set break
運(yùn)行上述代碼,我們得到了一些樣本圖像的可視化結(jié)果,如下所示:
2. 用tf.keras 搭建一個(gè)簡(jiǎn)單的CNN模型
tf.keras 是一個(gè)符合 Keras API 標(biāo)準(zhǔn)的 TensorFlow 實(shí)現(xiàn),它是一個(gè)用于構(gòu)建和訓(xùn)練模型的高級(jí)API,而且對(duì) TensorFlow 特定功能的支持相當(dāng)好(例如 eager execution 和 tf.data 管道)。 tf.keras 不僅讓 TensorFlow 變得更加易于使用,而且還保留了它的靈活和高效。
張量 (image_height, image_width, color_channels) 作為模型的輸入,在這里不用考慮 batch 的大小。黑白圖像只有一個(gè)顏色通道,而彩色圖像具有三個(gè)顏色通道 (R,G,B) 。在此,我們采用彩色圖像作為輸入,輸入圖像尺寸為 (128,128,3) ,將該參數(shù)傳遞給 shape,從而完成輸入層的構(gòu)建。
接下來(lái)我們將用一種很常見的模式構(gòu)建 CNN 的卷積部分:一系列堆疊的 Conv2D 層和 MaxPooling2D 層,如下面的代碼所示。最后,將卷積部分的輸出((28,28,64)的張量)饋送到一個(gè)或多個(gè)全連接層中,從而實(shí)現(xiàn)分類。
值得注意的是,全連接層的輸入必須是一維的向量,而卷積部分的輸出卻是三維的張量。因此我們需要先將三維的張量展平成一維的向量,然后再將該向量輸入到全連接層中。數(shù)據(jù)集中有 5 個(gè)類別,這些信息可以從數(shù)據(jù)集的元數(shù)據(jù)中獲取。因此,模型最后一個(gè)全連接層的輸出是一個(gè)長(zhǎng)度為 5 的向量,再用 softmax 函數(shù)對(duì)它進(jìn)行激活,至此就構(gòu)建好了 CNN 模型。
from tensorflow import keras# Creating a simple CNN model in keras using functional APIdef create_model(): img_inputs = keras.Input(shape=IMG_SHAPE) conv_1 = keras.layers.Conv2D(32, (3, 3), activation='relu')(img_inputs) maxpool_1 = keras.layers.MaxPooling2D((2, 2))(conv_1) conv_2 = keras.layers.Conv2D(64, (3, 3), activation='relu')(maxpool_1) maxpool_2 = keras.layers.MaxPooling2D((2, 2))(conv_2) conv_3 = keras.layers.Conv2D(64, (3, 3), activation='relu')(maxpool_2) flatten = keras.layers.Flatten()(conv_3) dense_1 = keras.layers.Dense(64, activation='relu')(flatten) output = keras.layers.Dense(metadata.features['label'].num_classes, activation='softmax')(dense_1) model = keras.Model(inputs=img_inputs, outputs=output) return model
上面的模型是通過 Kearas 的 Functional API 構(gòu)建的,在 Keras中 還有另一種構(gòu)建模型的方式,即使用 Model Subclassing API,它按照面向?qū)ο蟮慕Y(jié)構(gòu)來(lái)構(gòu)建模型并定義它的前向傳遞過程。
2.1 編譯和訓(xùn)練模型
在 Keras 中,編譯模型就是為其設(shè)置訓(xùn)練過程的參數(shù),即設(shè)置優(yōu)化器、損失函數(shù)和評(píng)估指標(biāo)。通過調(diào)用 model 的 .fit() 函數(shù)來(lái)設(shè)置這些參數(shù),例如可以設(shè)置訓(xùn)練的 epoch 次數(shù),再例如直接對(duì) trian 和 validation 調(diào)用 .repeat() 功能,并傳遞給 .fit() 函數(shù),這樣就可以保證模型在數(shù)據(jù)集上循環(huán)訓(xùn)練指定的 epoch 次數(shù)。
在調(diào)用 .fit() 函數(shù)之前,我們需要先計(jì)算幾個(gè)相關(guān)的參數(shù):
# Calculating number of images in train, val and test setsnum_train, num_val, num_test = (metadata.splits['train'].num_examples * weight/10 for weight in SPLIT_WEIGHTS)steps_per_epoch = round(num_train)//BATCH_SIZEvalidation_steps = round(num_val)//BATCH_SIZE
如上代碼所示,由于下載的數(shù)據(jù)集沒有定義標(biāo)準(zhǔn)的分割形式,我們通過設(shè)置 8:1:1 的分割比例,將數(shù)據(jù)集依次分為訓(xùn)練集、驗(yàn)證集和測(cè)試驗(yàn)證集。
steps_per_epoch:該參數(shù)定義了訓(xùn)練過程中,一個(gè) epoch 內(nèi) batch 的數(shù)量,該參數(shù)的值等于樣本數(shù)量除以 batch 的大小。
validation_steps:該參數(shù)和 steps_per_epoch 具有相同的內(nèi)涵,只是該參數(shù)用于驗(yàn)證集。
def train_model(model): model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) # Creating Keras callbacks tensorboard_callback = keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1) model_checkpoint_callback = keras.callbacks.ModelCheckpoint( 'training_checkpoints/weights.{epoch:02d}-{val_loss:.2f}.hdf5', period=5) os.makedirs('training_checkpoints/', exist_ok=True) early_stopping_checkpoint = keras.callbacks.EarlyStopping(patience=5) history = model.fit(train.repeat(), epochs=epochs, steps_per_epoch=steps_per_epoch, validation_data=validation.repeat(), validation_steps=validation_steps, callbacks=[tensorboard_callback, model_checkpoint_callback, early_stopping_checkpoint]) return history
2.2 可視化訓(xùn)練過程中的評(píng)估指標(biāo)變化
如下圖所示,我們將訓(xùn)練集和驗(yàn)證集上的評(píng)估指標(biāo)進(jìn)行了可視化,該指標(biāo)為 train_model() 或者 manually_train_model() 的返回值。在這里,我們使用 Matplotlib 繪制曲線圖:
訓(xùn)練集和驗(yàn)證集的評(píng)估指標(biāo)隨著訓(xùn)練epoch的變化
這些可視化圖能讓我們更加深入了解模型的訓(xùn)練程度。在模型訓(xùn)練過程中,確保訓(xùn)練集和驗(yàn)證集的精度在逐漸增加,而損失逐漸減少,這是非常重要的。
如果訓(xùn)練精度高但驗(yàn)證精度低,那么模型很可能出現(xiàn)了過擬合。這時(shí)我們需要對(duì)數(shù)據(jù)進(jìn)行增廣,或者直接從網(wǎng)上下載更多的圖像,從而增加訓(xùn)練集。此外,還可以采用一些防止過擬合的技術(shù),例如 Dropout 或者 BatchNormalisation 。
如果訓(xùn)練精度和驗(yàn)證精度都較高,但是驗(yàn)證精度比訓(xùn)練精度略高,那么驗(yàn)證集很可能包含較多易于分類的圖像。有時(shí)我們使用 Dropout 和 BatchNorm 等技術(shù)來(lái)防止過擬合,但是這些操作會(huì)為訓(xùn)練過程添加一些隨機(jī)性,使得訓(xùn)練更加困難,因此模型在驗(yàn)證集上表現(xiàn)會(huì)更好些。稍微拓展一點(diǎn)講,由于訓(xùn)練集的評(píng)估指標(biāo)是對(duì)一個(gè) epoch 的平均估計(jì),而驗(yàn)證集的評(píng)估指標(biāo)卻是在這個(gè) epoch 結(jié)束后,再對(duì)驗(yàn)證集進(jìn)行評(píng)估的,因此驗(yàn)證集所用的模型可以說(shuō)要比訓(xùn)練集的模型訓(xùn)練的更久一些。
TensorFlow2.0 可以在 Jupyter notebook 中使用功能齊全的 TensorBoard 。在模型開始訓(xùn)練之前,先啟動(dòng) TensorBoard ,這樣我們就可以在訓(xùn)練過程中動(dòng)態(tài)觀察這些評(píng)估指標(biāo)的變化。如下代碼所示(注意:需要提前創(chuàng)建 logs/ 文件夾):
%load_ext tensorboard.notebook%tensorboard --logdir logs/
Jupyer notebook 中的TensorBoard 視圖
3. 使用預(yù)訓(xùn)練的模型
在上一節(jié)中,我們訓(xùn)練了一個(gè)簡(jiǎn)單的 CNN 模型,它給出了大約 70% 的準(zhǔn)確率。通過使用更大、更復(fù)雜的模型,獲得更高的準(zhǔn)確率,預(yù)訓(xùn)練模型是一個(gè)很好的選擇。預(yù)訓(xùn)練模型通常已經(jīng)在大型的數(shù)據(jù)集上進(jìn)行過訓(xùn)練,通常用于完成大型的圖像分類任務(wù)。直接使用預(yù)訓(xùn)練模型來(lái)完成我們的分類任務(wù),我們也可以運(yùn)用遷移學(xué)習(xí)的方法,只使用預(yù)訓(xùn)練模型的一部分,重新構(gòu)建屬于自己的模型。
簡(jiǎn)單來(lái)講,遷移學(xué)習(xí)可以理解為:一個(gè)在足夠大的數(shù)據(jù)集上經(jīng)過訓(xùn)練的模型,能夠有效地作為視覺感知的通用模型,通過使用該模型的特征映射,我們就可以構(gòu)建一個(gè)魯棒性很強(qiáng)的模型,而不需要很多的數(shù)據(jù)去訓(xùn)練。
3.1 下載預(yù)訓(xùn)練模型
本次將要用到的模型是由谷歌開發(fā)的 InceptionV3 模型,該模型已經(jīng)在 ImageNet 數(shù)據(jù)集上進(jìn)行過預(yù)訓(xùn)練,該數(shù)據(jù)集含有 1.4M 張圖像和相應(yīng)的 1000 個(gè)類別。InceptionV3 已經(jīng)學(xué)習(xí)了我們常見的 1000 種物體的基本特征,因此,該模型具有強(qiáng)大的特征提取能力。
模型下載時(shí),需要指定參數(shù) include_top=False,該參數(shù)使得下載的模型不包含最頂層的分類層,因?yàn)槲覀冎幌胧褂迷撃P瓦M(jìn)行特征提取,而不是直接使用該模型進(jìn)行分類。預(yù)訓(xùn)練模型的分類模塊通常受原始的分類任務(wù)限制,如果想將預(yù)訓(xùn)練模型用在新的分類任務(wù)上,我們需要自己構(gòu)建模型的分類模塊,而且需要將該模塊在新的數(shù)據(jù)集上進(jìn)行訓(xùn)練,這樣才能使模型適應(yīng)新的分類任務(wù)。
from tensorflow import keras# Create the base model from the pre-trained model MobileNet V2base_model = keras.applications.InceptionV3(input_shape=IMG_SHAPE,# We cannot use the top classification layer of the pre-trained model as it contains 1000 classes.# It also restricts our input dimensions to that which this model is trained on (default: 299x299) include_top=False, weights='imagenet')
我們將預(yù)訓(xùn)練模型當(dāng)做一個(gè)特征提取器,輸入(128,128,3)的圖像,得到(2,2,2048)的輸出特征。特征提取器可以理解為一個(gè)特征映射過程,最終的輸出特征是輸入的多維表示,在新的特征空間中,更加利于圖像的分類。
3.2 添加頂層的分類層
由于指定了參數(shù) include_top=False,下載的 InceptionV3 模型不包含最頂層的分類層,因此我們需要添加一個(gè)新的分類層,而且它是為 tf_flowers 所專門定制的。通過 Keras 的序列模型 API,將新的分類層堆疊在下載的預(yù)訓(xùn)練模型之上,代碼如下:
def build_model(): # Using Sequential API to stack up the layers model = keras.Sequential([ base_model, keras.layers.GlobalAveragePooling2D(), keras.layers.Dense(metadata.features['label'].num_classes, activation='softmax') ]) # Compile the model to configure training parameters model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) return modelinception_model = build_model()
以上代碼理解如下:
對(duì)于每張圖片,使用 keras.layers.GlobalAveragePooling2D() 層對(duì)提取的特征 (2x2x2048) 進(jìn)行平均池化,從而將該特征轉(zhuǎn)化為長(zhǎng)度為 2048 的向量。
在平均池化層之上,添加一個(gè)全連接層 keras.layers.Dense(),將長(zhǎng)度為 2048 的向量轉(zhuǎn)化為長(zhǎng)度為 5 的向量。
值得注意的是,在模型的編譯和訓(xùn)練過程中,我們使用 base_model.trainable = False 將卷積模塊進(jìn)行了凍結(jié),該操作可以防止在訓(xùn)練期間更新卷積模塊的權(quán)重,接下來(lái)就可以在 tf_flowers 數(shù)據(jù)集上進(jìn)行模型訓(xùn)練了。
3.3 訓(xùn)練頂層的分類層
訓(xùn)練的步驟和上文中 CNN 的訓(xùn)練步驟相同,如下圖所示,我們繪制了訓(xùn)練集和驗(yàn)證集的判據(jù)指標(biāo)隨訓(xùn)練過程變化的曲線圖:
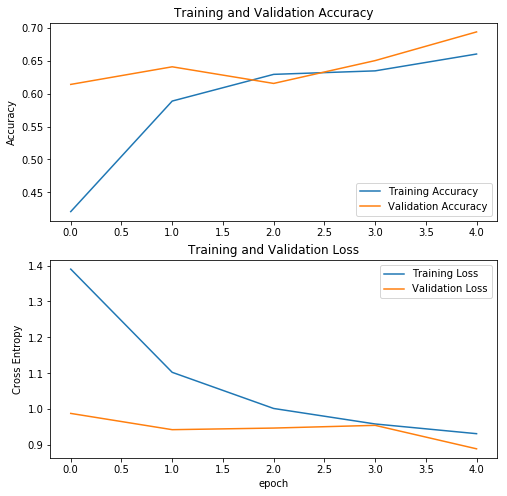
開始訓(xùn)練預(yù)訓(xùn)練模型后,訓(xùn)練集和驗(yàn)證集的評(píng)估指標(biāo)隨著訓(xùn)練epoch的變化
從圖中可以看到,驗(yàn)證集的精度高略高于訓(xùn)練集的精度。這是一個(gè)好兆頭,說(shuō)明該模型的泛化能力較好,使用測(cè)試集來(lái)評(píng)估模型可以進(jìn)一步驗(yàn)證模型的泛化能力。如果想讓模型取得更好的效果,對(duì)模型進(jìn)行微調(diào)。
3.4 對(duì)預(yù)訓(xùn)練網(wǎng)絡(luò)進(jìn)行微調(diào)
在上面的步驟中,我們僅在 InceptionV3 模型的基礎(chǔ)上簡(jiǎn)單訓(xùn)練了幾層網(wǎng)絡(luò),而且在訓(xùn)練期間并沒有更新其卷積模塊的網(wǎng)絡(luò)權(quán)重。為了進(jìn)一步提高模型的性能,對(duì)卷積模塊的頂層進(jìn)行微調(diào)。在此過程中,卷積模塊的頂層和我們自定義的分類層聯(lián)系了起來(lái),它們都將為 tf_flowers 數(shù)據(jù)集提供定制化的服務(wù)。具體的內(nèi)容可以參見 TensorFlow 的官網(wǎng)解釋。
鏈接:
https://www.tensorflow.org/alpha/tutorials/images/transfer_learning#fine_tuning
下面的代碼將 InceptionV3 的卷積模塊頂層進(jìn)行了解凍,使得它的權(quán)重可以跟隨訓(xùn)練過程進(jìn)行改變。由于模型已經(jīng)發(fā)生了改變,不再是上一步的模型了,因此在訓(xùn)練新的模型之前,我們需要對(duì)模型重新編譯一遍。
# Un-freeze the top layers of the modelbase_model.trainable = True# Let's take a look to see how many layers are in the base modelprint("Number of layers in the base model: ", len(base_model.layers))# Fine tune from this layer onwardsfine_tune_at = 249# Freeze all the layers before the `fine_tune_at` layerfor layer in base_model.layers[:fine_tune_at]: layer.trainable = False# Compile the model using a much lower learning rate.inception_model.compile(optimizer = tf.keras.optimizers.RMSprop(lr=0.0001), loss='sparse_categorical_crossentropy', metrics=['accuracy'])history_fine = inception_model.fit(train.repeat(), steps_per_epoch = steps_per_epoch, epochs = finetune_epochs, initial_epoch = initial_epoch, validation_data = validation.repeat(), validation_steps = validation_steps)
微調(diào)的目的是使得模型提取的特征更加適應(yīng)新的數(shù)據(jù)集,因此,微調(diào)后的模型可以讓準(zhǔn)確度提高好幾個(gè)百分點(diǎn)。但是如果我們的訓(xùn)練數(shù)據(jù)集非常小,并且和 InceptionV3 原始的預(yù)訓(xùn)練集非常相似,那么微調(diào)可能會(huì)導(dǎo)致模型過擬合。如下圖所示,在微調(diào)之后,我們?cè)俅卫L制了訓(xùn)練集和驗(yàn)證集的評(píng)估指標(biāo)的變化。
注意:本節(jié)中的微調(diào)操作是針對(duì)預(yù)訓(xùn)練模型中的少量頂層卷積層進(jìn)行的,所需要調(diào)節(jié)的參數(shù)量較少。如果我們將預(yù)訓(xùn)練模型中所有的卷積層都解凍了,直接將該模型和自定義的分類層聯(lián)合,通過訓(xùn)練算法對(duì)所有圖層進(jìn)行訓(xùn)練,那么梯度更新的量級(jí)是非常巨大的,而且預(yù)訓(xùn)練模型將會(huì)忘記它曾經(jīng)學(xué)會(huì)的東西,那么預(yù)訓(xùn)練就沒有太大的意義了。
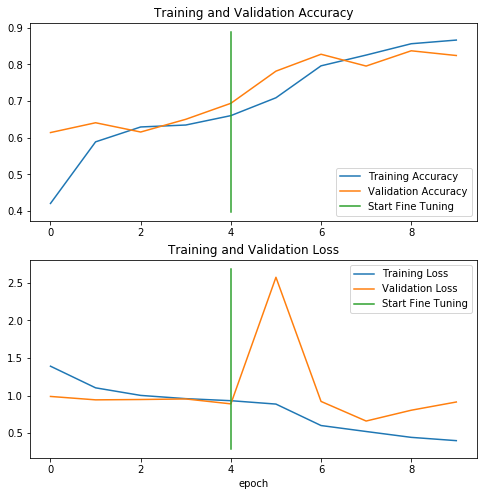
微調(diào)模型后,訓(xùn)練集和驗(yàn)證集的評(píng)估指標(biāo)隨著訓(xùn)練epoch的變化
從圖中可以看到,訓(xùn)練集和驗(yàn)證集的精度都有所提升。我們觀察到,在從微調(diào)開始的第一個(gè) epoch 結(jié)束后,驗(yàn)證集的誤差開始上升,但它最終還是隨著訓(xùn)練過程而下降了。這可能是因?yàn)闄?quán)重更新得過快,從而導(dǎo)致了震蕩。因此,相比于上一步中的模型,微調(diào)更加適合較低的學(xué)習(xí)率。
4. 使用 TensorFlow Serving 為模型發(fā)布服務(wù)
TensorFlow Serving 能夠?qū)⒛P桶l(fā)布,從而使得我們能夠便捷地調(diào)用該模型,完成特定環(huán)境下的任務(wù)。TensorFlow Serving 將提供一個(gè) URL 端點(diǎn),我們只需要向該端點(diǎn)發(fā)送 POST 請(qǐng)求,就可以得到一個(gè)JSON 響應(yīng),該響應(yīng)包含了模型的預(yù)測(cè)結(jié)果。可以看到,我們根本就不用擔(dān)心硬件配置的問題,一個(gè)簡(jiǎn)單的 POST 請(qǐng)求就可以解決復(fù)雜的分類問題。
4.1 安裝 TensorFlow Serving
1、添加 TensorFlow Serving的源(一次性設(shè)置)
$ echo "deb [arch=amd64] http://storage.googleapis.com/tensorflow-serving-apt stable tensorflow-model-server tensorflow-model-server-universal" | sudo tee /etc/apt/sources.list.d/tensorflow-serving.list && $ curl https://storage.googleapis.com/tensorflow-serving-apt/tensorflow-serving.release.pub.gpg | sudo apt-key add -
2、安裝并更新 TensorFlow ModelServer
$ apt-get update && apt-get install tensorflow-model-server
一旦安裝完成,就可以使用如下命令開啟 TensorFlow Serving 服務(wù)。
$tensorflow_model_server
4.2 將 Keras 模型導(dǎo)出為 SavedModel 格式
為了將訓(xùn)練好的模型加載到 TensorFlow Serving 服務(wù)器中,首先我們需要將模型保存為 SavedModel 格式。TensorFlow 提供了 SavedModel 格式的導(dǎo)出方法,該方法簡(jiǎn)單易用,很快地導(dǎo)出 SavedModel 格式。
下面的代碼會(huì)在指定的目錄中創(chuàng)建一個(gè) protobuf 文件,通過該文件,查詢模型的版本號(hào)。在實(shí)際的使用中,請(qǐng)求服務(wù)的版本號(hào),TensorFlow Serving 將會(huì)為我們選擇相應(yīng)版本的模型進(jìn)行服務(wù)。每個(gè)版本的模型都會(huì)導(dǎo)出到相應(yīng)的子目錄下。
from tensorflow import keras# '/1' specifies the version of a model, or "servable" we want to exportpath_to_saved_model = 'SavedModel/inceptionv3_128_tf_flowers/1'# Saving the keras model in SavedModel formatkeras.experimental.export_saved_model(inception_model, path_to_saved_model)# Load the saved keras model backrestored_saved_model = keras.experimental.load_from_saved_model(path_to_saved_model)
4.3 啟動(dòng) TensorFlow Serving 服務(wù)器
在本地啟動(dòng) TensorFlow Serving 服務(wù)器,可以使用如下代碼:
$ tensorflow_model_server --model_base_path=/home/ubuntu/Desktop/Medium/TF2.0/SavedModel/inceptionv3_128_tf_flowers/ --rest_api_port=9000 --model_name=FlowerClassifier
--model_base_path:該路徑必須指定為絕對(duì)路徑,否則就會(huì)報(bào)如下的錯(cuò)誤:
Failed to start server. Error: Invalid argument: Expected model ImageClassifier to have an absolute path or URI; got base_path()=./inceptionv3_128_tf_flowers
--rest_api_port:Tensorflow Serving 將會(huì)在 8500 端口上啟動(dòng)一個(gè) gRPC ModelServer 服務(wù),而 REST API 會(huì)在 9000 端口開啟。
--model_name:用于指定 Tensorflow Serving 服務(wù)器的名字,當(dāng)我們發(fā)送 POST 請(qǐng)求的時(shí)候,將會(huì)用到服務(wù)器的名字。服務(wù)器的名字可以按照我們的喜好來(lái)指定。
4.4 向TensorFlow服務(wù)器發(fā)送 REST請(qǐng)求
TensorFlow ModelServer 支持 RESTful API。我們需要將預(yù)測(cè)請(qǐng)求作為一個(gè) POST,發(fā)送到服務(wù)器的 REST 端點(diǎn)。在發(fā)送 POST 請(qǐng)求之前,先加載示例圖像,并對(duì)它做一些預(yù)處理。
TensorFlow Serving服務(wù)器的期望輸入為(1,128,128,3)的圖像,其中,"1" 代表 batch 的大小。通過使用 Keras 庫(kù)中的圖像預(yù)處理工具,能夠加載圖像并將其轉(zhuǎn)化為指定的大小。
服務(wù)器 REST 端點(diǎn)的 URL 遵循以下格式:
http://host:port/v1/models/${MODEL_NAME}[/versions/${MODEL_VERSION}]:predict
其中,/versions/${MODEL_VERSION} 是一個(gè)可選項(xiàng),用于選擇服務(wù)的版本號(hào)。下面的代碼先加載了輸入圖像,并對(duì)其進(jìn)行了預(yù)處理,然后使用上面的 REST 端點(diǎn)發(fā)送 POST 請(qǐng)求:
import json, requestsfrom tensorflow.keras.preprocessing.image import img_to_array, load_imgimport numpy as npimage_path = 'sunflower.jpg'# Loading and pre-processing our input imageimg = image.img_to_array(image.load_img(image_path, target_size=(128, 128))) / 255.img = np.expand_dims(img, axis=0)payload = {"instances": img.tolist()}# sending post request to TensorFlow Serving serverjson_response = requests.post('http://localhost:9000/v1/models/FlowerClassifier:predict', json=payload)pred = json.loads(json_response.content.decode('utf-8'))# Decoding the response using decode_predictions() helper function# You can pass "k=5" to get top 5 predicitonsget_top_k_predictions(pred, k=3)
代碼的輸出如下:
Top 3 predictions:[('sunflowers', 0.978735), ('tulips', 0.0145516), ('roses', 0.00366251)]
5. 總結(jié)
最后對(duì)本文的要點(diǎn)簡(jiǎn)單總結(jié)如下:
利用 TensorFlow Datasets ,我們只需要幾行代碼,就可以下載公開可用的數(shù)據(jù)集。不僅如此, TensorFlow Datasets 還能有效構(gòu)建數(shù)據(jù)集,對(duì)模型訓(xùn)練有很大的幫助。
tf.keras 不僅能夠讓我們從頭開始構(gòu)建一個(gè) CNN 模型,它還能幫助我們利用預(yù)訓(xùn)練的模型,在短時(shí)間內(nèi)訓(xùn)練一個(gè)有效的花卉分類模型,并且獲得更高的準(zhǔn)確率。
使用 TensorFlow Serving 服務(wù)器能夠?qū)⒂?xùn)練好的模型發(fā)布。我們只需要調(diào)用 URL 端點(diǎn),就可以輕松將訓(xùn)練好的模型集成到網(wǎng)站或者其他應(yīng)用程序中。
-
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1205瀏覽量
24649 -
cnn
+關(guān)注
關(guān)注
3文章
351瀏覽量
22178 -
tensorflow
+關(guān)注
關(guān)注
13文章
329瀏覽量
60500
原文標(biāo)題:掌聲送給TensorFlow 2.0!用Keras搭建一個(gè)CNN | 入門教程
文章出處:【微信號(hào):rgznai100,微信公眾號(hào):rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
如何搭建DotNet Core 21自動(dòng)化構(gòu)建和部署環(huán)境
高階API構(gòu)建模型和數(shù)據(jù)集使用
如何使用pycoral、tensorflow-lite和edgetpu構(gòu)建核心最小圖像?
使用MobilenetV2、ARM NN和TensorFlow Lite Delegate預(yù)建二進(jìn)制文件進(jìn)行圖像分類教程
為WiMAX構(gòu)建端到端的網(wǎng)絡(luò)架構(gòu)
基于WiMAX接入技術(shù)的端到端網(wǎng)絡(luò)架構(gòu)
TensorFlow2.0終于問世,Alpha版可以搶先體驗(yàn)

tensorflow能做什么_tensorflow2.0和1.0區(qū)別
基于深度神經(jīng)網(wǎng)絡(luò)的端到端圖像壓縮方法

基于生成式對(duì)抗網(wǎng)絡(luò)的端到端圖像去霧模型

一種對(duì)紅細(xì)胞和白細(xì)胞圖像分類任務(wù)的主動(dòng)學(xué)習(xí)端到端工作流程
構(gòu)建端到端的流程體系

HDR Vivid端到端產(chǎn)業(yè)鏈加速構(gòu)建
華為IPv6+端到端解決方案通過信通院IPv6+ 2.0 Advanced測(cè)試評(píng)估






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論