") 一個完整的MNIST測試集,其中包含60000個測試樣本
一個完整的MNIST測試集,其中包含60000個測試樣本
盡管MNIST是源于NIST數(shù)據(jù)庫的基準數(shù)據(jù)集,但是導出MNIST的精確處理過程已經(jīng)隨著時間的推移被人們多遺忘。因此,作者提出了一種足以替代MNIST數(shù)據(jù)集的重建數(shù)據(jù)集,并且它不會帶來準確度的降低。作者將每個MNIST數(shù)字與它在NIST中的源相對應,并得到了更加豐富的元數(shù)據(jù),如作者標識符、分區(qū)標識符等。作者還重建了一個完整的MNIST測試集,其中包含60000個測試樣本,而不是通常使用的10000個樣本。由于多余的50000個樣本沒有被使用,因此可以用來探究25年來已有的MNIST實驗模型在該數(shù)據(jù)集上的測試效果。
引言
MNIST數(shù)據(jù)集被用作機器學習的基準集已經(jīng)超過二十年了。在過去的十年中,許多研究者都表示該數(shù)據(jù)集已經(jīng)被過度使用了。特別是它僅有10000個樣本用于測試,這引起了不少的關注。已有數(shù)百篇論文的方法在這個測試集上取得越來越好的效果。那這些模型是否在測試集上過擬合?我們還能相信在這個數(shù)據(jù)集上得到的新結論嗎?機器學習的數(shù)據(jù)集多久會變得無用?
NIST手寫字符集的第一部分已經(jīng)在一年前發(fā)布,它是一個由2000名人口普查局員工手寫的訓練集和500名高中生手寫的更具挑戰(zhàn)性的測試集。 LeCun、Cortes 和Burges的目標是創(chuàng)建一個具有類似分布的訓練集和測試集。這個過程生成了兩組60000個樣本的數(shù)據(jù)集,可能是由于當時電腦計算這些數(shù)據(jù)集的速度非常慢,他們將測試集下采樣到僅10000個樣本,因此多余的50000樣本從未被用于任何的測試。
本文研究的目的是重建MNIST預處理算法,以便將每個MNIST數(shù)字圖追溯到NIST中原始的手寫體。這種重建是基于可用信息,之后通過迭代細化來提升它的水平。第2節(jié)描述了這個過程,并計算了重建樣本與官方MNIST樣本的匹配程度。重建的訓練集包含了與原有MNIST訓練集相匹配的60000張圖片。類似的,重建的10000張測試圖片也與MNIST測試集里面的每張圖片相匹配。剩下的50000張是對在MNIST中丟失的50000張圖像的重建。
與Recht等人一致,重建這50000張樣本,使得研究人員可以量化官方MNIST測試集在25年來退化的過程。第3節(jié)比較和討論了在一些知名算法在原始MNIST測試集、重建MNIST測試集,以及丟失的50000測試樣本集上進行測試的性能。本文的實驗結果在不同數(shù)據(jù)集上驗證了Recht et al. [2018, 2019]指出的趨勢。
重構MNIST
圖1:LeCun94年文獻中描述MNIST的處理過程
圖1 顯示的是MNIST創(chuàng)建的過程。作者提到,該描述錯誤地描述了數(shù)字圖在hsf4分區(qū)中的位數(shù),在原始的NIST測試集中應該是58527,而不是58646。這兩段話給出了一個相對精確的處理方法,使用它生成的數(shù)據(jù)集比實際MNIST訓練集多了一個0,少了一個8。盡管并不匹配,這些類分布是如此相近,以至于hsf4分區(qū)中確實好像缺少了119位。那么應該如何來裁剪128x128的二進制NIST圖像?應該使用哪種啟發(fā)式算法來忽略不屬于圖片本身的噪聲像素?以及對于最終的中心坐標,應該如何四舍五入呢?
本文的初始重建算法是根據(jù)圖1中的描述得到的,但作者在Lush代碼庫里面發(fā)現(xiàn)了另一種重采用的算法,它不是使用雙線性插值或雙三次插值,而是計算輸入和輸出的精確重疊像素。作者重建的第一個QMNISTV1與實際的MNIST非常相似,但是存在著鋸齒圖像,因此作者通過微調初始中心坐標和重采樣算法,得到了QMNISTV2。
圖2:并排顯示MNIST和QMNIST的圖像,其中放大圖說明了重建的圖片是抗鋸齒像素的。
接著,作者又發(fā)現(xiàn)MNIST和QMNIST之間的最小距離L2是一個較可靠的指標,因此作者使用匈牙利算法計算匹配度,并進一步調整裁剪算法,這樣一步一步迭代調整,又可以得到QMNISTV3、V4、V5。最終得到了QMNIST。
評估QMNIST
作者做了一系列實驗來評估QMNIST與MNIST之間的差距。
表1:在MNIST和QMNIST之間抖動像素的四分位數(shù),L2距離表示一個像素的差異,L1距離表示像素之間的最大絕對差。
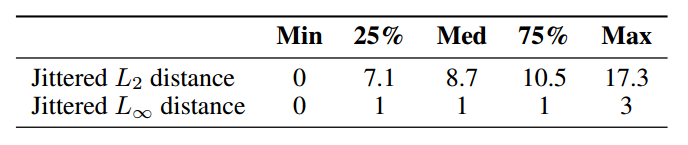
表2:在沒有平移或+-1像素平移下,MNIST和QMNIST訓練圖像標齊的數(shù)量
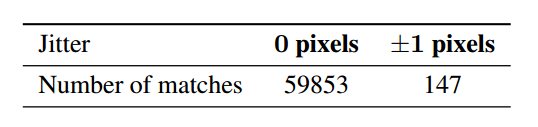
表3:在MNIST和QMNIST訓練集上訓練LeNet5卷積網(wǎng)絡,并在MNIST測試集、QMNIST測試集和QMNIST新部分上進行測試

重構觀察到的結論
重構MNIST,使作者發(fā)現(xiàn)了一些之前未報道過的關于MNIST的事情。
1、整個NIST手寫字符集只有三個重復的數(shù)字,其中只有一個屬于生成MNIST的字段,但被MNIST作者刪除了。
2、MNIST測試集的前5001張圖片似乎是從高中生(#2350-#2599)寫的圖片中隨機挑選出來的,接下來的4999張圖片是按順序(#35000-#39998)由48位人工普查局員工(#326-#373)撰寫的,雖然人數(shù)有點少,可能讓人擔心統(tǒng)計樣本有問題,但這些圖像比較干凈,幾乎對總測試誤差沒有影響。
3、第一個MNIST訓練集樣本中的偶數(shù)圖像與高中學生所寫的數(shù)字完全匹配,其余圖像是NIST圖像#0到#30949的順序。這意味著在連續(xù)的mini-batch的MNIST訓練圖像中,圖像可能是同一人寫的。因此作者建議在minibatch中,打亂訓練集。
4、28x28MNIST圖像的中心點存在舍入誤差。事實中,MNIST數(shù)字的平均中心原理圖像幾何中心至少半個像素。這很重要,因為使用正確的圖像進行訓練,然后在MNIST上進行測試,可能會使模型性能下降很多。
5、MNIST重采樣代碼中的缺陷會在粗字符的暗區(qū)域產生低幅周期性的圖像。這在Lush代碼中仍然可見,這些模式的周期取決于傳遞給重采樣代碼的輸入和輸出圖像的相對大小。
6、關于將二次采樣圖像的連續(xù)值像素轉換為整數(shù)值像素有一些奇怪的事情。我們當前的代碼將每個圖像中觀察到的范圍線性映射到區(qū)間【0.0,255.0】,之后四舍五入到最接近的整數(shù)。然而,像素比較直方圖顯示MNIST值128的像素更多,值255的像素更少。
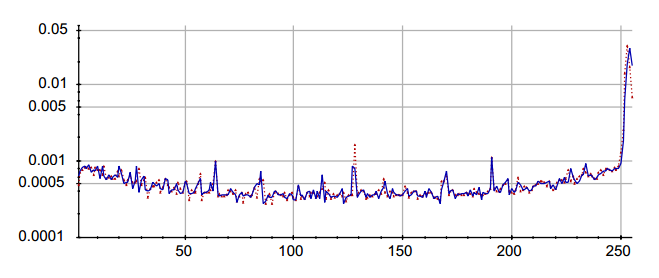
圖3:像素直方圖對比,紅色為MNIST,藍色為QMNIST。
泛化性能評估
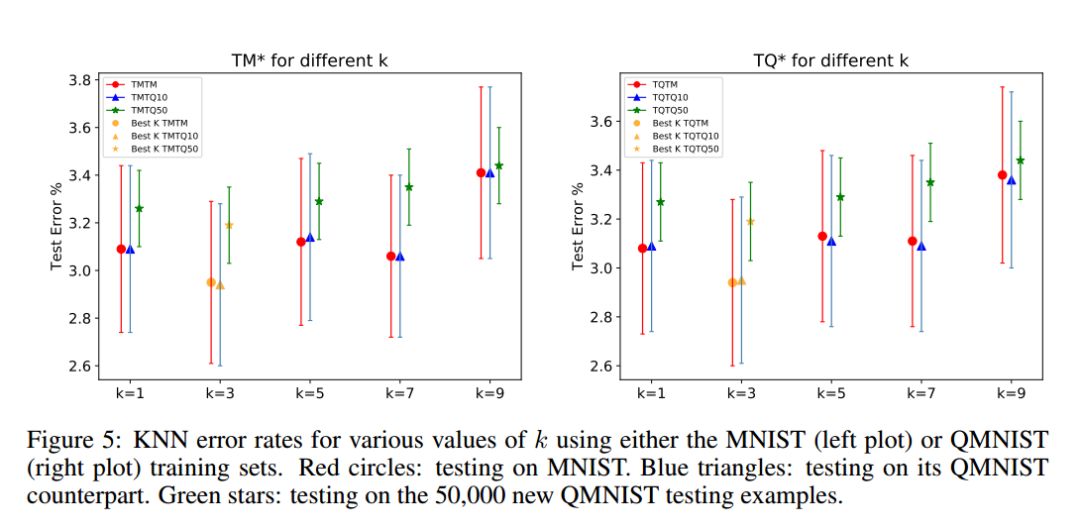
本節(jié)是利用未用的50000個樣本,來重新審視已經(jīng)報道過的一些論文結論。Recht等人對CIFAR10和ImageNet有類似的研究。作者使用了三個測試集:MNIST測試集(10000張)、重建的QMNIST測試集(10000張,QMNIST10),以及重建的未用的50000張測試集(QMNIST50)。在MNIST訓練集上,類似地,我們使用TQTM、TQTQ10和TQTQ50來表示結果。這些數(shù)據(jù)都沒有使用數(shù)據(jù)增強。作者使用了KNN、SVM、MLP、Lenet5等方法。
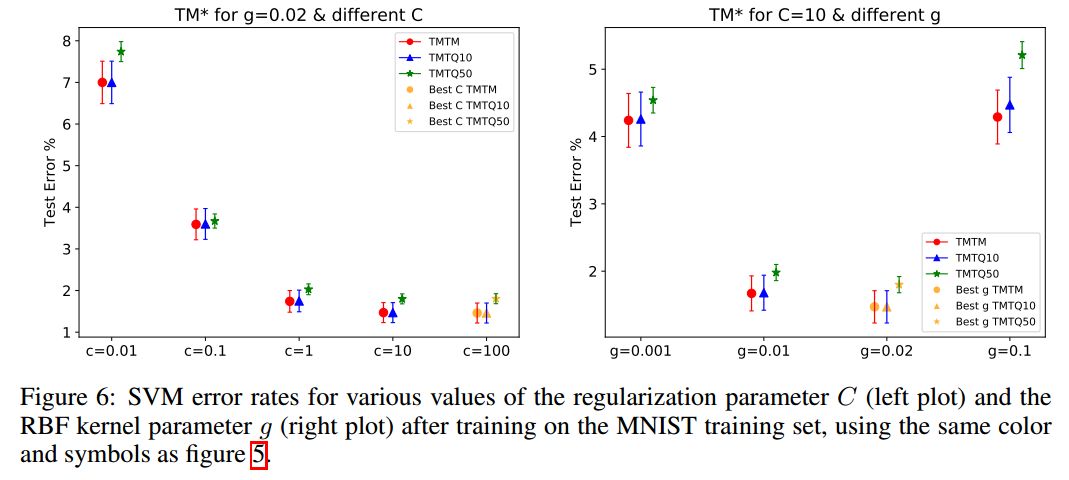
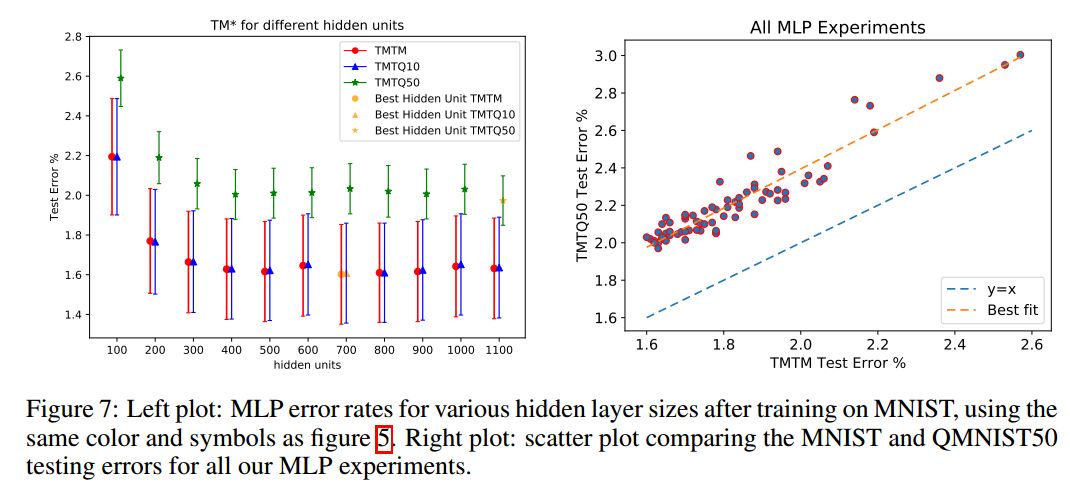
總結
作者重構了MNIST數(shù)據(jù)集,不僅是重新溯源到NIST源圖像和相關元數(shù)據(jù),還重構了原始MNIST測試集,包括從未發(fā)布的50000個測試樣本。經(jīng)過長時間的研究,作者的發(fā)現(xiàn)與Recht等人的成果一致。所有這些結果都表明“測試集腐爛”問題確實存在,但遠遠沒有研究者擔心的那么嚴重,重復使用相同測試集會影響性能,但它同樣有利于模型選擇。
-
機器學習
+關注
關注
66文章
8377瀏覽量
132406 -
數(shù)據(jù)集
+關注
關注
4文章
1205瀏覽量
24641 -
MNIST
+關注
關注
0文章
10瀏覽量
3361
原文標題:MNIST重生,測試集增加至60000張!
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
計算機視覺/深度學習領域常用數(shù)據(jù)集匯總
深度學習中開發(fā)集和測試集的定義
開發(fā)集和測試集應該有多大?
清洗誤標注的開發(fā)集和測試集樣本
如何研究帶有菊花鏈路由的BGA測試樣本?
TensorFlow邏輯回歸處理MNIST數(shù)據(jù)集
TensorFlow邏輯回歸處理MNIST數(shù)據(jù)集
如何利用keras打包制作mnist數(shù)據(jù)集
針對特定測試樣本的隱寫分析方法
MNIST是一個簡單的計算機視覺數(shù)據(jù)集
如何用Fashion-MNIST數(shù)據(jù)集搭建一個用于辨認時尚單品的機器學習模型
基于測試樣本誤差重構的協(xié)同表示分類方法
兆易創(chuàng)新“一種NAND閃存芯片的測試樣本”專利獲授權





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論