 教你如何處理不平衡數據集
教你如何處理不平衡數據集
分類是機器學習最常見的問題之一,處理它的最佳方法是從分析和探索數據集開始,即從探索式數據分析(Exploratory Data Analysis,EDA)開始。除了生成盡可能多的數據見解和信息,它還用于查找數據集中可能存在的任何問題。在分析用于分類的數據集時,類別不平衡是常見問題之一。
什么是數據不平衡(類別不平衡)?
數據不平衡通常反映了數據集中類別的不均勻分布。例如,在信用卡欺詐檢測數據集中,大多數信用卡交易類型都不是欺詐,僅有很少一部分類型是欺詐交易,如此以來,非欺詐交易和欺詐交易之間的比率達到50:1。本文中,我將使用來自Kaggle的信用卡欺詐交易數據數據集,你可以從這里下載。
首先,我們先繪制類分布圖,查看不平衡情況。
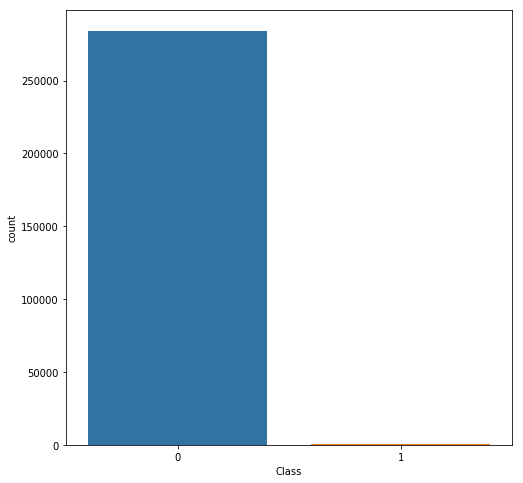
如你所見,非欺詐交易類型數據數量遠遠超過欺詐交易類型。如果我們在不解決這個類別不平衡問題的情況下訓練了一個二分類模型,那么這個模型完全是有偏差的,稍后我還會向你演示它影響特征相關性的過程并解釋其中的原因。
現在,我們來介紹一些解決類別不平衡問題的技巧,你可以在這里找到完整代碼的notebook。
重采樣(過采樣和欠采樣)
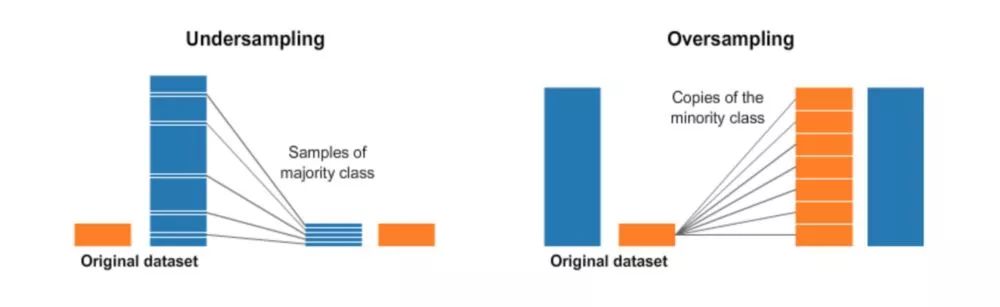
這聽起來很直接。欠采樣就是一個隨機刪除一部分多數類(數量多的類型)數據的過程,這樣可以使多數類數據數量可以和少數類(數量少的類型)相匹配。
對多數類進行欠采樣
對數據集進行欠采樣之后,我重新畫出了類型分布圖(如下),可見兩個類型的數量相等。

平衡數據集(欠采樣)
第二種重采樣技術叫過采樣,這個過程比欠采樣復雜一點。它是一個生成合成數據的過程,試圖學習少數類樣本特征隨機地生成新的少數類樣本數據。對于典型的分類問題,有許多方法對數據集進行過采樣,最常見的技術是SMOTE(Synthetic Minority Over-sampling Technique,合成少數類過采樣技術)。簡單地說,就是在少數類數據點的特征空間里,根據隨機選擇的一個K最近鄰樣本隨機地合成新樣本。
還記得我說過不平衡的數據會影響特征相關性嗎?讓我向您展示處理不平衡類問題前后的特征相關性。
重采樣之后:
請注意,現在特征相關性更明顯了。在解決不平衡問題之前,大多數特征并沒有顯示出相關性,這肯定會影響模型的性能。除了會關系到整個模型的性能,特征性相關性還會影響ML模型的性能,因此修復類別不平衡問題非常重要。
集成方法(采樣器集成)
在機器學習中,集成方法會使用多種學習算法和技術,以獲得比單獨使用其中一個算法更好的性能(是的,就像一個民主投票系統)。當使用集合分類器時,bagging方法變得流行起來,它通過構建多個分類器在隨機選擇的不同數據集上進行訓練。在scikit-learn庫中,有一個名叫“Bagging Classifier”的集成分類器,然而這個分類器不能訓練不平衡數據集。當訓練不平衡數據集時,這個分類器將會偏向多數類,從而創建一個有偏差的模型。
為了解決這個問題,我們可以使用imblearn庫中的BalancedBaggingClassifier。它允許在訓練集成分類器中每個子分類器之前對每個子數據集進行重采樣。
因此,BalancedBaggingClassifier除了需要和Scikit Learn BaggingClassifier相同的參數以外,還需要2個參數sampling_strategy和replacement來控制隨機采樣器的執行。
使用集合采樣器訓練不平衡數據集
這樣,您就可以訓練一個分類器來處理類別不平衡問題,而不必在訓練前手動進行欠采樣或過采樣。總之,每個人都應該知道,建立在不平衡數據集上的ML模型會難以準確預測稀有點和少數點,整體性能會受到限制。因此,識別和解決這些點的不平衡對生成模型的質量和性能是至關重要的。
-
機器學習
+關注
關注
66文章
8377瀏覽量
132406 -
數據分析
+關注
關注
2文章
1427瀏覽量
34012
原文標題:一文教你如何處理不平衡數據集(附代碼)
文章出處:【微信號:BigDataDigest,微信公眾號:大數據文摘】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
如何理解矢量測量中“平衡”與“不平衡
基于主動學習不平衡多分類AdaBoost改進算法
手把手教你解決-深度學習訓練數據不平衡問題
三相電壓不平衡產生原因_三相電壓不平衡的治理措施
三相不平衡有哪些處理方法
為什么三相變頻電源出現不平衡?如何處理?






 工商網監
工商網監
評論