") 從零開始學習機器學習最簡單的 KNN 算法
從零開始學習機器學習最簡單的 KNN 算法
今天開始,我打算寫寫機器學習教程。說實話,相比爬蟲,掌握機器學習更實用競爭力也更強些。
目前網(wǎng)上大多這類教程對新手都不友好,要么直接調用 Sklearn 包,要么滿篇抽象枯燥的算法公式文字,看這些教程你很難入門,而真正適合入門的手寫 Python 代碼教程寥寥無幾。最近看了慕課網(wǎng) bobo 老師的機器學習課程后,大呼過癮,最好的機器學習教程沒有之一。我打算以他的教程為基礎并結合自己的理解,從零開始更新機器學習系列推文。
第一篇推文先不扯諸如什么是機器學習、機器學習有哪些算法這些總結性的文章,在你沒有真正知道它是什么之前,這些看了也不會有印象反而會增加心理負荷。
所以我將長驅直入直接從一個算法實戰(zhàn)開始,就像以前爬蟲教程一樣,當你真正感受到它的趣味性后,才會有想去學它的欲望。
下面就從一個場景故事開始。
01 場景代入
在一個酒吧里,吧臺上擺著十杯幾乎一樣的紅酒,老板跟你打趣說想不想來玩?zhèn)€游戲,贏了免費喝酒,輸了付 3 倍酒錢,贏的概率有 50%。你是個愛冒險的人,果斷說玩。
老板接著道:你眼前的這十杯紅酒,每杯略不相同,前五杯屬于「赤霞珠」,后五杯屬于「黑皮諾」。現(xiàn)在,我重新倒一杯酒,你只需要根據(jù)剛才的十杯正確地告訴我它屬于哪一類。
聽完你有點心虛:根本不懂酒啊,光靠看和嘗根本區(qū)分辨不出來,不過想起自己是搞機器學習的,不由多了幾分底氣爽快地答應了老板。
你沒有急著品酒而是問了老板每杯酒的一些具體信息:酒精濃度、顏色深度等,以及一份紙筆。老板一邊倒一杯新酒,你邊瘋狂打草稿。很快,你告訴老板這杯新酒應該是「赤霞珠」。
老板瞪大了眼下巴也差點驚掉,從來沒有人一口酒都不嘗就能答對,無數(shù)人都是反復嘗來嘗去,最后以猶豫不定猜錯而結束。你神秘地笑了笑,老板信守承諾讓你開懷暢飲。微醺之時,老板終于忍不住湊向你打探是怎么做到的。
你炫耀道:無他,但機器學習熟爾。
02 kNN 算法介紹
接下來,我們就要從這個故事中開始接觸機器學習了,機器學習給很多人的感覺就是「難」,所以我編了上面這個故事,就是要引出機器學習的一個最簡單算法:kNN 算法(K-Nearest Neighbor),也叫 K 近鄰算法。
別被「算法」二字嚇到,我保證你只要有高中數(shù)學加上一點點 Python 基礎就能學會這個算法。
學會 kNN 算法,只需要三步:
了解 kNN 算法思想
掌握它背后的數(shù)學原理(別怕,你初中就學過)
最后用簡單的 Python 代碼實現(xiàn)
在說 kNN 算法前說兩個概念:樣本和特征。
上面的每一杯酒稱作一個「樣本」,十杯酒組成一個樣本集。酒精濃度、顏色深度等信息叫作「特征」。這十杯酒分布在一個多維特征空間中。說到空間,我們最多能感知三維空間,為了理解方便,我們假設區(qū)分赤霞珠和黑皮諾,只需利用:酒精濃度和顏色深度兩個特征值。這樣就能在二維坐標軸來直觀展示。
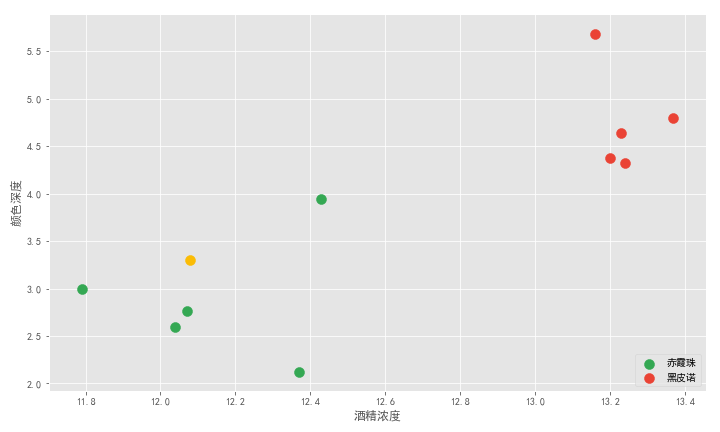
橫軸是酒精濃度值,縱軸是顏色深度值。十杯酒在坐標軸上形成十個點,綠色的 5 個點代表五杯赤霞珠,紅色的 5 個點代表五杯黑皮諾。可以看到兩類酒有明顯的界限。老板新倒的一杯酒是圖中黃色的點。
記得我們的問題么?要確定這杯酒是赤霞珠還是黑皮諾,答案顯而易見,通過主觀距離判斷它應該屬于赤霞珠。
這就用到了 K 近鄰算法思想。該算法首先需要取一個參數(shù) K,機器學習中給的經(jīng)驗取值是 3,我們假設先取 3 ,具體取多少以后再研究。對于每個新來的點,K 近鄰算法做的事情就是在所有樣本點中尋找離這個新點最近的三個點,統(tǒng)計三個點所屬類別然后投票統(tǒng)計,得票數(shù)最多的類別就是新點的類別。
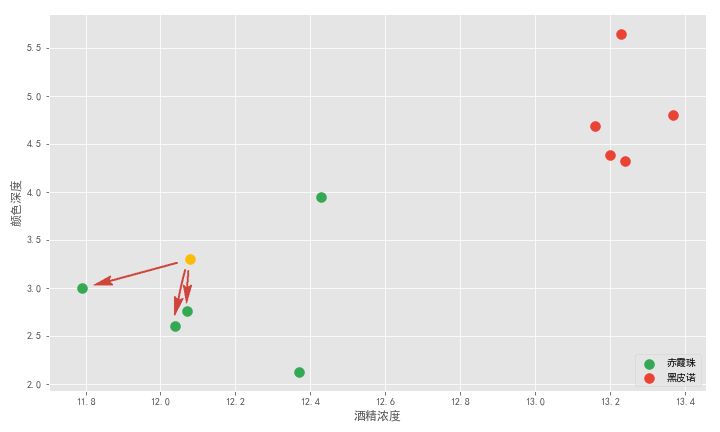
上圖有綠色和紅色兩個類別。離黃色最近的 3 個點都是綠點,所以綠色和紅色類別的投票數(shù)是 3:0 ,綠色取勝,所以黃色點就屬于綠色,也就是新的一杯就屬于赤霞珠。
這就是 K 近鄰算法,它的本質就是通過距離判斷兩個樣本是否相似,如果距離夠近就覺得它們相似屬于同一個類別。當然只對比一個樣本是不夠的,誤差會很大,要比較最近的 K 個樣本,看這 K 個 樣本屬于哪個類別最多就認為這個新樣本屬于哪個類別。
是不是很簡單?
再舉一例,老板又倒了杯酒讓你再猜,你可以在坐標軸中畫出它的位置。離它最近的三個點,是兩個紅點和一個綠點。紅綠比例是 2:1,紅色勝出,所以 K 近鄰算法告訴我們這杯酒大概率是黑皮諾。
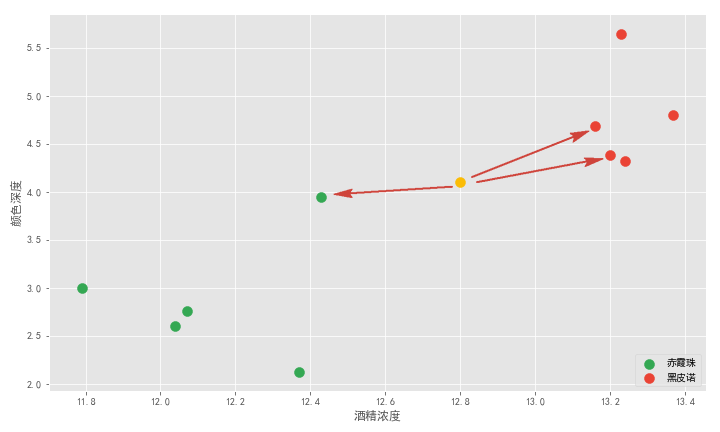
可以看到 K 近鄰算法就是通過距離來解決分類問題。這里我們解決的二分類問題,事實上 K 近鄰算法天然適合解決多分類問題,除此之外,它也適合解決回歸問題,之后一一細講。
02 數(shù)學理論
K 近鄰算法基本思想我們知道了,來看看它背后的數(shù)學原理。該算法的「距離」在二維坐標軸中就是兩點之間的距離,計算距離的公式有很多,一般常用歐拉公式,這個我們中學就學過:
![]()
解釋下就是:空間中 m 和 n 兩個點,它們的距離等于 x y 兩坐標差的平方和再開根。
如果在三維坐標中,多了個 z 坐標,距離計算公式也相同:
![]()
當特征數(shù)量有很多個形成多維空間時,再用 x y z 寫就不方便,我們換一個寫法,用 X 加下角標的方式表示特征維度,這樣 n 維 空間兩點之間的距離公式可以寫成:
![]()
公式還可以進一步精簡:

這就是 kNN 算法的數(shù)學原理,不難吧?
只要計算出新樣本點與樣本集中的每個樣本的坐標距離,然后排序篩選出距離最短的 3 個點,統(tǒng)計這 3 個點所屬類別,數(shù)量占多的就是新樣本所屬的酒類。
根據(jù)歐拉公式,我們可以用很基礎的 Python 實現(xiàn)。
03 Python 代碼實現(xiàn)
首先隨機設置十個樣本點表示十杯酒,我這里取了 Sklearn 中的葡萄酒數(shù)據(jù)
集的部分樣本點,這個數(shù)據(jù)集在之后的算法中會經(jīng)常用到會慢慢介紹。
1import numpy as np 2X_raw = [[14.23, 5.64], 3 [13.2 , 4.38], 4 [13.16, 5.68], 5 [14.37, 4.80 ], 6 [13.24, 4.32], 7 [12.07, 2.76], 8 [12.43, 3.94], 9 [11.79, 3. ],10 [12.37, 2.12],11 [12.04, 2.6 ]]1213y_raw = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
X_raw 的兩列值分別是顏色深度和酒精濃度值,y_raw 中的 0 表示黑皮諾,1 表示赤霞珠。
新的一杯酒信息:
1x_test = np.array([12.8,4.1])
在機器學習中常使用 numpy 的 array 數(shù)組而不是列表 list,因為 array 速度快也能執(zhí)行向量運算,所以在運算之前先把上面的列表轉為數(shù)組:
1X_train = np.array(X_raw)2y_train = np.array(y_raw)
有了 X Y 坐標就可以繪制出第一張散點圖:
1import matplotlib.pyplot as plt 2plt.style.use(‘ggplot’) 3plt.figure(figsize=(10,6)) 4 5plt.scatter(X_train[y_train==1,0],X_train[y_train==1,1],s=100,color=color_g,label=‘赤霞珠’) 6plt.scatter(X_train[y_train==0,0],X_train[y_train==0,1],s=100,color=color_r,label=‘黑皮諾’) 7plt.scatter(x_test2[0],x_test2[1],s=100,color=color_y) # x_test 8 9plt.xlabel(‘酒精濃度’)10plt.ylabel(‘顏色深度’)11plt.legend(loc=‘lower right’)1213plt.tight_layout()14plt.savefig(‘葡萄酒樣本.png’)
接著,根據(jù)歐拉公式計算黃色的新樣本點到每個樣本點的距離:
1from math import sqrt 2distances = [sqrt(np.sum((x - x_test)**2)) for x in X_train] # 列表推導式 3distances 4 5[out]: 6[1.7658142597679973, 7 1.5558920271021373, 8 2.6135799203391503, 9 1.9784084512557052,10 1.5446682491719705,11 0.540092584655631,12 0.7294518489934753,13 0.4172529209005018,14 1.215113163454334,15 0.7011419257183239]
上面用到了列表生成式,以前的爬蟲教程中經(jīng)常用到,如果不熟悉可以在公眾號搜索「列表生成式」關鍵字復習。
這樣就計算出了黃色點到每個樣本點的距離,接著找出最近的 3 個點,可以使用 np.argsort 函數(shù)返回樣本點的索引位置:
1sort = np.argsort(distances)2sort34[out]:array([7, 5, 9, 6, 8, 4, 1, 0, 3, 2], dtype=int64)
通過這個索引值就能在 y_train 中找到對應酒的類別,再統(tǒng)計出排名前 3 的就行了:
1K = 3 2topK = [y_train[i] for i in sort[:K]]3topK45[out]:[1, 1, 1]
可以看到距離黃色點最近的 3 個點都是綠色的赤霞珠,與剛才肉眼觀測的結果一致。
到這里,距離輸出黃色點所屬類別只剩最后一步,使用 Counter 函數(shù)統(tǒng)計返回類別值即可:
1from collections import Counter2votes = Counter(topK)3votes4[out]:Counter({1: 3})56predict_y = votes.most_common(1)[0][0]7predict_y8[out]:1
最后的分類結果是 1 ,也就是新的一杯酒是赤霞珠。
我們使用 Python 手寫完成了一個簡易的 kNN 算法,是不是不難?
如果覺得難,來看一個更簡單的方法:調用 sklearn 庫中的 kNN 算法,俗稱調包,只要 5 行代碼就能得到同樣的結論。
04 sklearn 調包
1from sklearn.neighbors import KNeighborsClassifier 2kNN_classifier = KNeighborsClassifier(n_neighbors=3)3kNN_classifier.fit(X_train,y_train )4x_test = x_test.reshape(1,-1)5kNN_classifier.predict(x_test)[0]67[out]:1
首先從 sklearn 中引入了 kNN 的分類算法函數(shù) KNeighborsClassifier 并建立模型,設置最近的 K 個樣本數(shù)量 n_neighbors 為 3。接下來 fit 訓練模型,最后 predict 預測模型得到分類結果 1,和我們剛才手寫的代碼結果一樣的。
你可以看到,sklearn 調包雖然簡單,不過作為初學者最好是懂得它背后的算法原理,然后用 Python 代碼親自實現(xiàn)一遍,這樣入門機器學習才快。
-
KNN
+關注
關注
0文章
22瀏覽量
10797 -
機器學習
+關注
關注
66文章
8381瀏覽量
132426
原文標題:Python手寫機器學習最簡單的KNN算法
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
NPU與機器學習算法的關系
【每天學點AI】KNN算法:簡單有效的機器學習分類器
人工智能、機器學習和深度學習存在什么區(qū)別

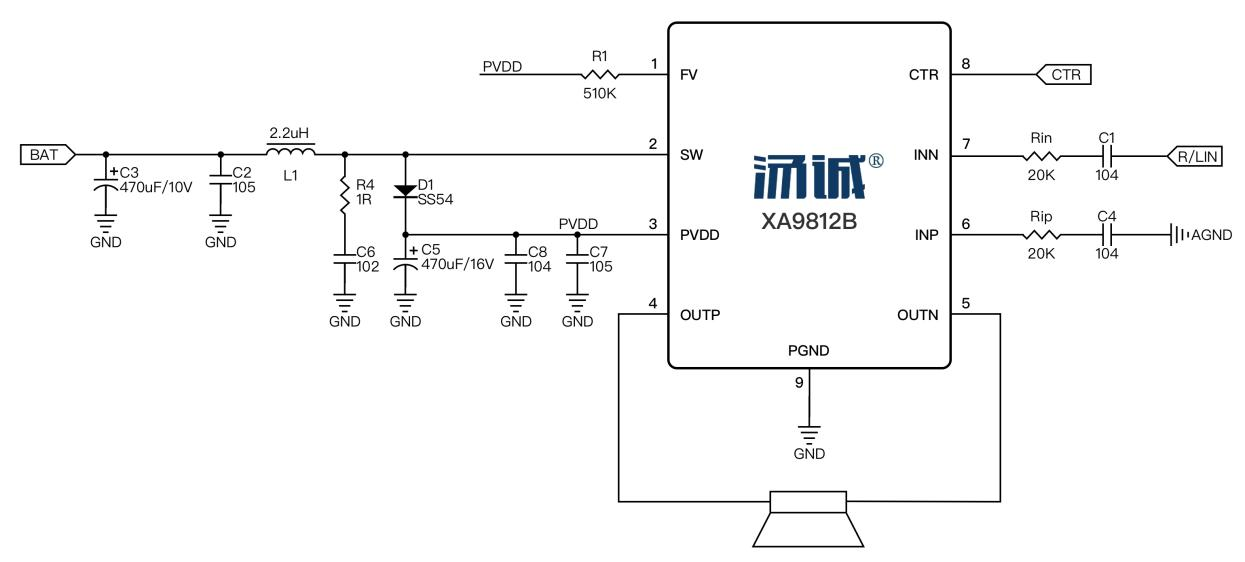
合肥湯誠音頻功放芯片XA9812B早教機套裝兒童智能學習機應用解決方案
【「時間序列與機器學習」閱讀體驗】+ 簡單建議
BP神經(jīng)網(wǎng)絡的學習機制
機器學習算法原理詳解
深度學習與傳統(tǒng)機器學習的對比
機器學習的經(jīng)典算法與應用

小度發(fā)布首款百度文心大模型學習機
全球首款基于文心大模型的學習機—小度學習機Z30重磅發(fā)布
AI大模型落地學習機,大模型應用成學習機創(chuàng)新方向
大牛談如何學習機器視覺?
如何從零開始構建深度學習項目?(如何啟動一個深度學習項目)

如何使用TensorFlow構建機器學習模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論