 智能語音機器人工作原理
智能語音機器人工作原理
信息時代,科學技術的飛速發展帶動人工智能化技術的更新進步。機器人的應用領域和范圍也越來越廣泛,在生產、建筑、旅游等各個行業都能夠看到人工智能機器人的身影。 旅游產業與互聯網的結合,要隨著信息技術的發展與時俱進。物聯網、人工智能、虛擬現實等新興的互聯網技術讓旅游產業的未來充滿了挑戰與機遇,導游等依賴大數據的職業完全可能被人工智能機器人取代。
語音助手越來越像人類了,與人類之間的交流不再是簡單的你問我答,不少語音助手甚至能和人類進行深度交談。在交流的背后,離不開自然語言處理(NLP)和自然語言生成(NLG)這兩種基礎技術。機器學習的這兩個分支使得語音助手能夠將人類語言轉換為計算機命令,反之亦然。
這兩種技術有什么差異?工作原理是什么?
NLP vs NLG:了解基本差異
什么是NLP?
NLP指在計算機讀取語言時將文本轉換為結構化數據的過程。簡而言之,NLP是計算機的閱讀語言。可以粗略地說,在NLP中,系統攝取人語,將其分解,分析,確定適當的操作,并以人類理解的語言進行響應。
NLP結合了計算機科學、人工智能和計算語言學,涵蓋了以人類理解的方式解釋和生成人類語言的所有機制:語言過濾、情感分析、主題分類、位置檢測等。
什么是NLG?
自然語言處理由自然語言理解(NLU)和自然語言生成(NLG)構成。NLG是計算機的“編寫語言”,它將結構化數據轉換為文本,以人類語言表達。即能夠根據一些關鍵信息及其在機器內部的表達形式,經過一個規劃過程,來自動生成一段高質量的自然語言文本。
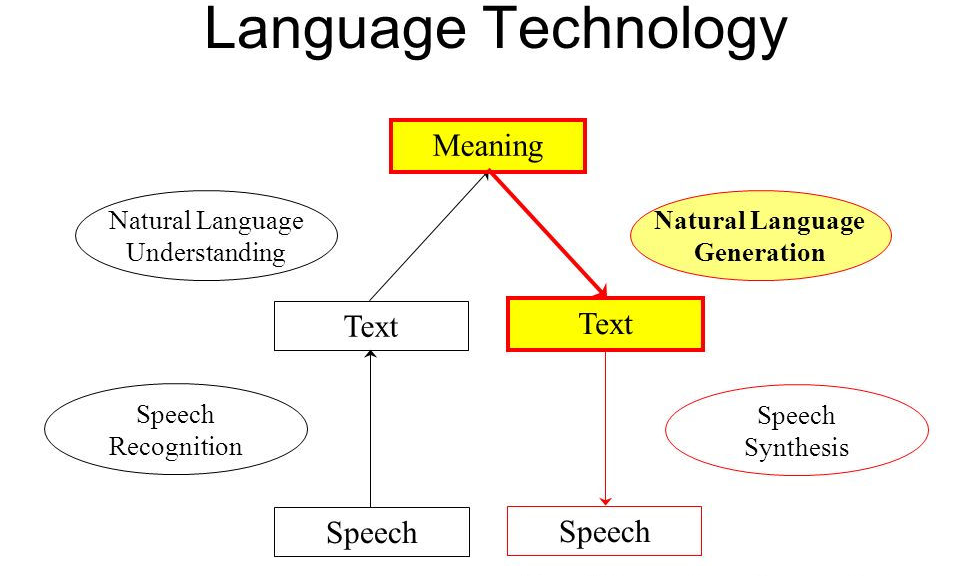
NLP vs NLG:聊天機器人的工作方式
人類談話涉及雙向溝通的方式,聊天機器人也一樣,只是溝通渠道略有不同——您是與機器交談。當給機器人發送消息時,它會將其拾取并使用NLP,機器將文本轉換為自身的編碼命令。然后將該數據發送到決策引擎。
在整個過程中,計算機將自然語言轉換為計算機理解的語言,處理,識別語音。語音識別系統常用的是Hidden Markov模型(HMM),它將語音轉換為文本以確定用戶所說的內容。通過傾聽您所說的內容,將其分解為小單元,并對其進行分析以生成文本形式的輸出或信息。
此后的關鍵步驟是自然語言理解(NLU),如上文所說,它是NLP的另一個子集,試圖理解文本形式的含義。重要的是計算機要理解每個單詞是什么,這是由NLU執行的部分。在對詞匯、語法和其他信息進行篩選時,NLP算法使用統計機器學習、應用自然語言的語法規則,并確定所說的最可能的含義。
另一方面,NLG是一種利用人工智能和計算語言學生成自然語言的系統。它還可以將該文本翻譯成語音。NLP系統首先確定要翻譯成文本的信息,然后組織表達結構,再使用一組語法規則,NLG就能系統形成完整的句子并讀出來。
應用
語音助手只是NLP眾多應用程序之一。它還可用于網絡安全文章、白皮書、科研等領域。例如,NLP對在線內容進行情緒分析,以改進服務并為客戶提供更好的產品。
而NLG通常用于Gmail,它可以為您自動創建答復。創建公司數據圖表的描述說明時,NLG也是很好的工具。
說NLP和NLG完全不相關,也不正確,因為NLP和NLG相當于學習中的閱讀、寫作過程,還是有內在關聯的。
一般智能語音助理或語音機器人工作原理大致如下:
第一階段:語音到文本的過程。信號源→設備(捕獲音頻輸入)→增強音頻輸入→檢測語音→轉換為其他形式(如文本)
第二階段:響應過程。處理文本(如用NLP處理文本,識別意圖)→操作響應。
在檢測語音過程中,就包括分辨是否為語音信號,該過程會通過指定的頻率對模擬信號進行采樣,將模擬聲波轉換為數字數據。這一過程很重要,是否成功地識別語音。如果生成數字數據都是錯誤的,那么后期的處理響應那肯定是錯的。這也是影響智能語音助理或語音機器人識別率的重要因素。
在這個過程,用于語音處理的技術是語音活性檢測 (Voice activity detection,VAD),目的是檢測語音信號是否存在。 VAD技術主要用于語音編碼和語音識別。它可以簡化語音處理,也可用于在音頻會話期間去除非語音片段:可以在IP電話應用中避免對靜音數據包的編碼和傳輸,節省計算時間和帶寬。
與大家分享VAD技術,首先講兩個概念:
信噪比(縮寫為SNR或S / N)是科學和工程中使用的一種度量,它將所需信號的電平與背景噪聲電平進行比較。SNR定義為信號功率與噪聲功率之比,通常以分貝表示。比率高于1:1(大于0 dB)表示信號多于噪聲。
窗口,研究信號源,我們將其分成滑動窗口或僅窗口。
能量檢測器
能量檢測器對于高SNR信號是有效的,但是當SNR下降直到它在1以下變得無效時失去效率。它也不能將語音與諸如沖擊噪聲(將筆放在桌子上),打字,空調或任何噪聲之類的噪聲區分開來。比人聲更響亮或更響亮。
波形和頻譜分析
在波形和頻譜分析中,語音活動檢測利用語音的已知特征。在該方法中應用VAD比基于能量的解決方案更加計算密集,但是能夠更好地檢測非平穩噪聲和低SNR場景中的噪聲。對于濁音音素,聲帶的振動產生諧波豐富的聲音,具有50到250 Hz之間的明顯音調。所有元音,但也有一些輔音,表現出這種諧波結構,因此是語音的特征。代表諧波結構的特征是語音的可靠指標。然而,單獨使用基于諧度或基于音調的特征不能預期無聲語音部分(例如一些摩擦音)被檢測到。此外,音樂或其他諧波噪聲分量可能被誤解為語音。總的來說,對信號的倒譜的分析可以揭示信號能量的來源。同樣的,基于該共振峰結構,也是語音識別系統的重要特征。人類聲道中的可變腔允許揚聲器形成不同的音素。強調諧振(或共振峰)頻率,導致頻譜包絡的特征形狀。平滑很重要,在一個對話中,一個人只有50%的時間在說話,并且存在大量非活動幀。諸如[p] [t] [k] [b]之類的音是靜音,并且靜音部分可能不會被算法識別為語音,這將影響自動語音識別系統的性能。解決方案如下:
要被視為語音,必須至少有3個連續的窗口標記語音(192ms)。它可以防止短暫的噪音被視為語音。
要被認為是沉默,必須至少連續3個窗口標記為靜音。它可以防止過多的語音切入影響語音節奏。
如果窗口被認為是語音,則前3個窗口和3個窗口被認為是語音。它可以防止在句子開頭和結尾丟失信息。
基于統計分析
MFCC,FBANK,PLP是最常用的語音識別功能。有數學運算的連接,旨在通過保持最相關的數據來減少和壓縮信息的數量。
在“信號源→設備(捕獲音頻輸入)→增強音頻輸入→檢測語音”過程中,語音成功采樣識別為數字數據,是后期語言處理的前提,在檢測中文面臨更大挑戰,斷句、語氣、語調等因素直接影響識別率。
-
機器人
+關注
關注
210文章
28231瀏覽量
206614 -
智能語音
+關注
關注
10文章
781瀏覽量
48714 -
自然語言處理
+關注
關注
1文章
614瀏覽量
13513
發布評論請先 登錄
相關推薦





 工商網監
工商網監
評論