 AMD全新GPU架構解析 性能提升14%功耗降低23%
AMD全新GPU架構解析 性能提升14%功耗降低23%
E3 2019游戲大會期間,AMD正式發布了基于7nm新工藝、Navi新核心、RDNA新架構的新一代顯卡Radeon RX 5700系列,包括RX 5700 XT、RX 5700兩款型號,均面向規模最為龐大的甜點級市場和主流游戲玩家。
AMD發布的新一代RX 5700系列顯卡基于7nm新工藝和Navi新核心,而在底層是全新的RDNA架構,已經走過七年半的GCN架構就此揮手作別。
這些年來,很多用戶玩家尤其是A飯一直期待一個全新的GPU架構,但這種事兒的難度遠超一般人想象,某種程度上設計一個新的GPU架構甚至要比設計一個新的CPU架構還要難。RDNA架構就花費了AMD研發團隊長達四年的時間,凝聚了無數人的心血,也開啟了AMD顯卡歷史上第五代重大架構的新時代。
2000年前,R100核心是A卡的第一代架構,用的還是固定單元設計,3D幾何轉換和光照效果如今看起來都極為原始。
2001-2007年的R200-R500是第二代架構,簡單的VS紋理著色器、PS像素著色器分離式設計,不同的只是比例不同,整個渲染流水線就像一個單通道的單行道。
2008-2011年的第三代TeraScale架構(代表核心R600)實現了一個飛躍,VS、PS融合為統一著色器,也就是我們常說的流處理器,支持VLIW(超長指令字),然后就是2011-2019年的GCN架構(代表核心Southern Islands),統一著色器加獨立的標量、矢量單元,二者比例為1:4。
如今,迎來了全新的RDNA(Radeon DNA),還是統一著色器,但標量和矢量單元走向融合,支持SIMT(單指令多線程) ILP(指令集并行),類似CPU處理器的SIMD(單指令多數據流),單線程性能和指令集執行效率大大提升。
需要強調的是,RDNA是一個全方位重新設計的架構,并不是GCN的又一個升級版,也不是與GCN的混合體,只是集成了GCN架構的指令以保持向下兼容,現有技術仍然可以在RDNA架構上得到支持。
RDNA架構將是AMD GPU顯卡未來多年的基石,接下來我們將看到采用7nm+工藝的第二代版本RDNA 2,看路線圖有望明年初和我們見面。
除了RDNA新架構,Navi核心還有7nm工藝、GDDR6顯存、PCIe 4.0總線、Radeon媒體引擎、Radeon顯示引擎等諸多全新特性。
Navi 10核心集成了103億個晶體管,相比Vega 64 125億個少了大約18%,而核心面積只有251平方毫米,相比Vega 64 495平方毫米更是小了足足一半,因此單位面積性能提升了足足1.3倍。
盡管晶體管更少、面積更小,Navi 10核心的性能相比于Vega 64卻提升了14%,同時功耗降低了23%,能效比因此大漲50%。
純架構性能上,Navi相比于Vega在同等功耗、同等配置下提升多達50%,反應到實際產品上,這貢獻了產品性能提升的60%左右,另外有大約25%來自7nm新工藝的加持,還有約15%來自頻率以及功耗的改進。
AMD表示,RDNA架構的設計理念主要有四個方面,性能上要滿足在現代游戲負載需求,能效上要充分優化功耗和帶寬利用率,功能上要壯大生態,擴展性上要從移動到桌面到云端通吃。
為實現上述目標,RDNA架構主要從三大方面進行了變革,包括CU計算單元、緩存、流水線,接下來我們逐一和大家分享,但鑒于GPU架構的技術性太強,我們只是蜻蜓點水地大致看一下,最后還有AMD關于光線追蹤的規劃。
新的計算單元設計一共分為40組,每組2個標量處理器、64個流處理器、4個64位雙線性過濾單元,總計80個、2560個、160個,執行延遲更低,單線程性能更強,緩存效率更高,整體計算能效比GCN架構有著巨大的提升,而且可適應從游戲到計算各種負載。
多級緩存一致性可以帶來更低的延遲、更高的帶寬、更低的功耗,包括各處零級緩存、512KB一級緩存、4MB二級緩存。
整個圖形引擎也做了重新調整,更加順暢高效,包括幾何引擎、64個紋理單元、4個異步計算引擎(ACE),負載分配更加均衡,可以在更低的功耗下達成更高的頻率,能效更高。
CU計算單元方面,雖然看起來每一組還是64個流處理器,數量沒變,但這個數字是AMD反復設計后與處理資源最為平衡的的組合,同時整個計算單元的結構進行了徹底重組,和GCN時代完全不一樣了。
RDNA架構下,每個CU計算單元的標量解碼和發射單元、矢量解碼和發射單元、調度器的數量都增加了一倍來到兩個,指令處理率因此也提升一倍。
同時,四個SIM16矢量單元、四個SIMD4特殊功能單元變為兩個SIMD32、兩個SIMD8,比如64個線程可組合為兩個Wave32,然后由兩個SIMD32執行兩個Wave32,實現單時鐘周期指令發射(之前需要四個),SIMD ALU單元的利用率也從25%來到了100%,而且支持Wave32、Wave64兩種執行模式,以應對不同負載需求。
此外,為了強化資源調度和利用的效率,RDNA架構還將每兩個CU計算單元緊密地捆綁在了一起,組成一個工作組處理器(Work Group Processor),使得可用ALU單元、寄存器數量翻番,緩存帶寬更是之前的四倍。
緩存方面,RDNA架構設計了一套多級一致性結構,每個雙CU組合內都有自己的零級緩存,與ALU單元的載入帶寬翻番,增加了四組新的一級緩存(都是16-way 128KB),降低了二級緩存(16-way 4MB)的擁堵,整體延遲和功耗大大減低。
按照AMD的說法,零級緩存的延遲降低了21%,一二級緩存降低24%,內存延遲也低了7%。
另外在一致性多級緩存下,到處都支持Delta數據壓縮(DCC/圖中箭頭黃色部分),提高傳輸率,同時還改進了色彩壓縮算法,可供顯示引擎讀取,著色器也能同時讀寫壓縮的色彩數據。
圖形引擎流水線方面進行了大刀闊斧的重組,包括四個增強的ACE異步計算引擎,地位更加中心化的結合處理器(包含四個原語單元),64個像素單元。
異步計算一直是A卡的獨門絕技,也是起在DX12、Vulkan API下表現更好的關鍵,如今得到增強后,可以更精準地實時控制其他模塊。
有趣的是,RDNA GPU架構設計也借鑒了Zen CPU架構設計的一些先進理念,尤其是在時鐘門控方面,效率和能效極高,同時還減少了達到更高頻率所需要的邏輯層級。
Radeon顯示引擎也大幅躍進,支持FreeSync 2 HDR、HDMI 2.0/DisplayPort 1.4 HDR,針對高分辨率HR顯示器優化,可輸出4K/240Hz、8K/60Hz,而且都只需一根數據線即可達成,同時還優化了VR頭顯顯示。
Radeon多媒體引擎則大大改進了視頻編解碼,增加了新的H.265 HDR/WCG編碼器,全面支持H.264 1080p600、4K150、8K30解碼和1080p360、4K90編碼,H.265 1080p360、4K90、8K24解碼和1080p360、4K60編碼,VP9 4K90、8K24解碼,整體編碼速度加快40%。
對于大家非常關注的光線追蹤支持,GCN、RDNA架構都沒有專門的硬件單元加速,不過事實上,AMD ProRender、Radeon Rays都早就支持了光線追蹤,分別面向內容創作渲染和游戲開發。
在下一代RDNA架構上,AMD會通過硬件單元,支持特定的光線追蹤效果在游戲中實時渲染,而即便到了更遙遠的未來,AMD也不會將光線追蹤全部一股腦扔給硬件來本地處理,否則效率會非常低下,而是將借助云計算,實現全場景的光線追蹤,保證畫面效果的同時,不會給本地硬件太大的壓力。
-
處理器
+關注
關注
68文章
19160瀏覽量
229121 -
amd
+關注
關注
25文章
5441瀏覽量
133937 -
顯卡
+關注
關注
16文章
2423瀏覽量
67460 -
GPU架構
+關注
關注
0文章
15瀏覽量
8452
原文標題:四年研發,終成正果!AMD 全新GPU架構解析:相比 Vega 64 面積更小,性能提升14%,功耗降低23%
文章出處:【微信號:wc_ysj,微信公眾號:旺材芯片】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
AMD最強AI芯片,性能強過英偉達H200,但市場仍不買賬,生態是最大短板?

《算力芯片 高性能 CPUGPUNPU 微架構分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--了解算力芯片GPU
AMD與NVIDIA GPU優缺點
【「算力芯片 | 高性能 CPU/GPU/NPU 微架構分析」閱讀體驗】--全書概覽
AMD全新處理器擴大數據中心CPU的領先地位
名單公布!【書籍評測活動NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架構分析
GPU云服務器架構解析及應用優勢
AMD推出全新AMD銳龍和EPYC處理器,擴大數據中心和PC領域領先地位

進一步解讀英偉達 Blackwell 架構、NVlink及GB200 超級芯片
天璣9300旗艦芯:全大核CPU架構,性能與能效的提升
深入解讀AMD最新GPU架構
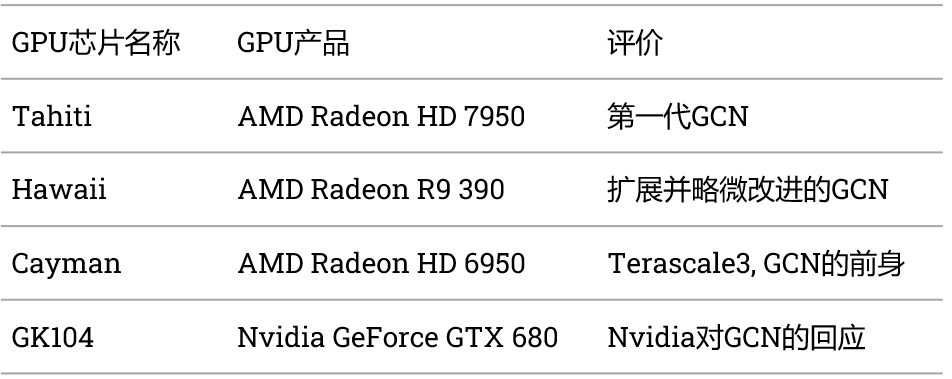
揭秘GPU: 高端GPU架構設計的挑戰







 工商網監
工商網監
評論