 ICML 2019最佳論文新鮮出爐!
ICML 2019最佳論文新鮮出爐!
今日,國際機器學習頂會ICML公布2019年最佳論文獎:來自蘇黎世聯邦理工大學、谷歌大腦等的團隊和英國劍橋大學團隊獲此殊榮。另外,大會還公布了7篇獲最佳論文提名的論文。
ICML 2019最佳論文新鮮出爐!
今日,國際機器學習頂會ICML 2019于美國長灘市公布了本屆大會最佳論文結果:
本屆ICML兩篇最佳論文分別是:
《挑戰無監督解耦表示中的常見假設》,來自蘇黎世聯邦理工學院(ETH Zurich)、MaxPlanck 智能系統研究所及谷歌大腦;
《稀疏高斯過程回歸變分的收斂速度》,來自英國劍橋大學。
除此之外,大會還公布了七篇獲得提名獎(Honorable Mentions)論文。
據了解,今年ICML共提交3424篇論文,其中錄取774篇,論文錄取率為22.6%。錄取率較去年ICML 2018的25%有所降低。
論文錄取結果地址:
https://icml.cc/Conferences/2019/AcceptedPapersInitial?fbclid=IwAR0zqRJfPz2UP7dCbZ8Jcy7MrsedhasX13ueqkKl934EsksuSj3J2QrrRAQ
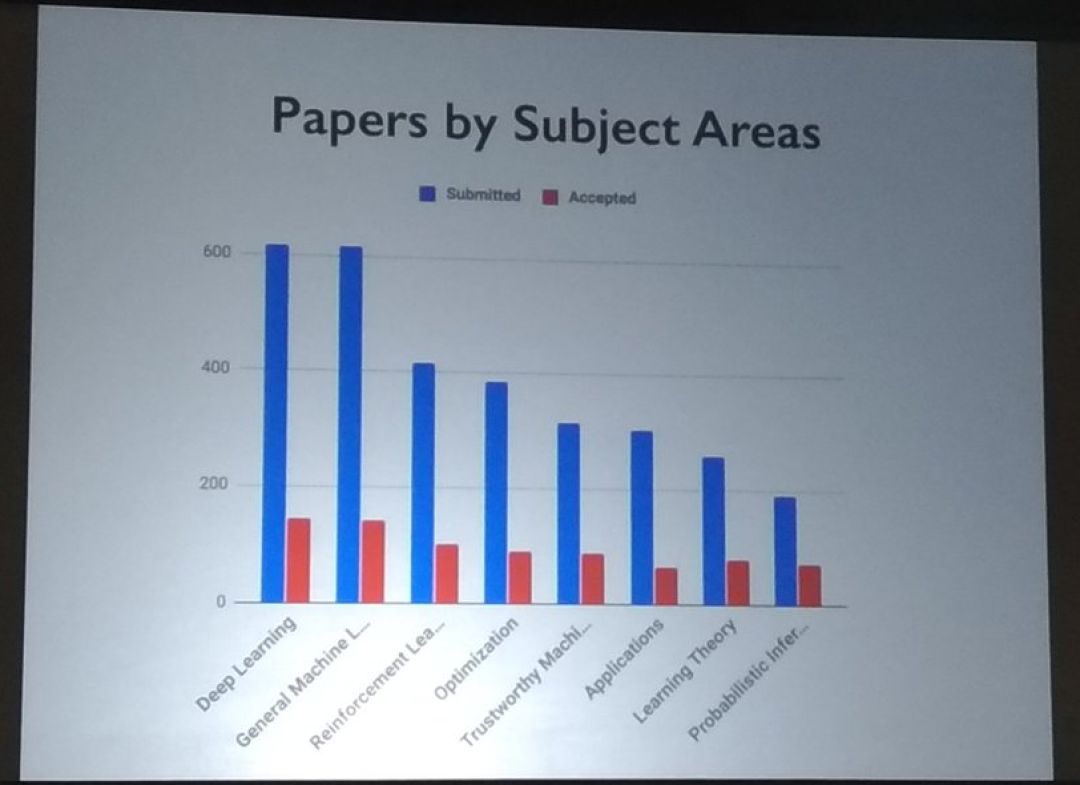
提交論文最多的子領域分別是:深度學習、通用機器學習、強化學習、優化等
最佳論文:大規模深入研究無監督解耦表示
第一篇最佳論文的作者來自蘇黎世聯邦理工學院(ETH Zurich)、MaxPlanck 智能系統研究所及谷歌大腦。
論文標題:挑戰無監督解耦表示中的常見假設
Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations
作者:Francesco Locatello, Stefan Bauer, Mario Lucic, Gunnar R?tsch, Sylvain Gelly, Bernhard Sch?lkopf, Olivier Bachem
論文地址:
http://proceedings.mlr.press/v97/locatello19a/locatello19a.pdf
這是一篇大規模深入研究無監督解耦表示(Disentangled Representation)的論文,對近年來絕大多數的非監督解耦表示方法進行了探索、利用 2.5GPU 年的算力在 7 個數據集上訓練了 12000 多個模型。基于大規模的實驗結果,研究人員對這一領域的一些假設產生了質疑,并為解耦學習的未來發展方向給出了建議。此外,研究人員還同時發布了研究中所使用的代碼和上萬個預訓練模型,并封裝了 disentanglement_lib供研究者進行實驗復現和更深入的探索。
論文摘要
無監督學習解耦表示背后的關鍵思想是,真實世界數據是由一些變量的解釋因子生成的,這些因子可以通過無監督學習算法恢復。在本文中,我們認真回顧了該領域的最新進展,并對一些常見假設提出挑戰。
我們首先從理論上證明,如果沒有對模型和數據的歸納偏置,解耦表示的無監督學習基本上是不可能的。然后,我們在7個不同數據集上訓練了超過12000個模型,涵蓋了最重要的方法和評估指標,進行了可重復的大規模實驗研究。
我們觀察到,雖然不同的方法都成功地執行了相應損失“鼓勵”的屬性,但如果沒有監督,似乎無法識別出良好解耦的模型。此外,增加解耦似乎不會降低下游任務學習的樣本復雜度。
我們的研究結果表明,未來關于解耦學習的工作應該明確歸納偏見和(隱式)監督的作用,研究強制解耦學習表示的具體好處,并考慮覆蓋多個數據集的可重復的實驗設置。
本文從理論和實踐兩方面對這一領域中普遍存在的一些假設提出了挑戰。本研究的主要貢獻可概括如下:
我們在理論上證明,如果沒有對所考慮的學習方法和數據集產生歸納偏置,那么解耦表示的無監督學習基本上是不可能的。
我們在一項可重復的大規模實驗研究中研究了當前的方法及其歸納偏置,該研究采用了完善的無監督解耦學習實驗方案。我們實現了六種最新的無監督解耦學習方法以及六種從頭開始的解耦方法,并在七個數據集上訓練了超過12000個模型。
我們發布了disentanglement_lib,這是一個用于訓練和評估解耦表示的新庫。由于復制我們的結果需要大量的計算工作,我們還發布了超過10000個預訓練的模型,可以作為未來研究的基線。
我們分析實驗結果,并挑戰了無監督解耦學習中的一些共識:
(i)雖然所有考慮的方法都證明有效確保聚合后驗的各個維度不相關,我們觀察到的表示維度是相關的
(ii)由于random seeds和超參數似乎比模型選擇更重要,我們沒有發現任何證據表明所考慮的模型可以用于以無監督的方式可靠地學習解耦表示。此外,如果不訪問ground-truth標簽,即使允許跨數據集傳輸良好的超參數值,似乎也無法識別良好訓練的模型。
(iii)對于所考慮的模型和數據集,我們無法驗證以下假設,即解耦對于下游任務是有用的,例如通過降低學習的樣本復雜性。
基于這些實證證據,我們提出了進一步研究的三個關鍵領域:
(i)歸納偏置的作用以及隱性和顯性監督應該明確:無監督模型選擇仍然是一個關鍵問題。
(ii) 應證明強制執行學習表示的特定解耦概念的具體實際好處。
(iii) 實驗應在不同難度的數據集上建立可重復的實驗設置。
最佳論文:稀疏高斯過程回歸變分的收斂速度
第二篇最佳論文來自英國劍橋大學。
論文標題:《稀疏高斯過程回歸變分的收斂速度》
Rates of Convergence for Sparse Variational Gaussian Process Regression
作者:DavidR. Burt1,Carl E. Rasmussen1,Mark van der Wilk2
arXiv地址:
https://arxiv.org/pdf/1903.03571.pdf
論文摘要
自從許多研究人提出了對高斯過程后驗的變分近似法后,避免了數據集大小為N時O(N3)的縮放。它們將計算成本降低到O(NM2),其中M≤N是誘導變量的數量。雖然N的計算成本似乎是線性的,但算法的真正復雜性取決于M如何增加以確保一定的近似質量。
研究人員通過描述KL向后發散的上界行為來解決這個問題。證明了在高概率下,M的增長速度比N慢, KL的發散度可以任意地減小。
一個特別有趣的例子是,對于具有D維度的正態分布輸入的回歸,使用流行的 Squared Exponential核M就足夠了。研究結果表明,隨著數據集的增長,高斯過程后驗可以真正近似地逼近,并為如何在連續學習場景中增加M提供了具體的規則。
總結
研究人員證明了稀疏GP回歸變分近似到后驗變分近似的KL發散的界限,該界限僅依賴于先驗核的協方差算子的特征值的衰減。
這些邊界證明了直觀的結果,平滑的核、訓練數據集中在一個小區域,允許高質量、非常稀疏的近似。這些邊界證明了用M≤N進行真正稀疏的非參數推理仍然可以提供可靠的邊際似然估計和點后驗估計。
對非共軛概率模型的擴展,是未來研究的一個有前景的方向。
DeepMind、牛津、MIT等7篇最佳論文提名
除了最佳論文外,本次大會還公布了7篇獲得榮譽獎的論文。

Analogies Explained: Towards Understanding Word Embeddings
作者:CarlAllen1,Timothy Hospedales1,來自愛丁堡大學。
論文地址:https://arxiv.org/pdf/1901.09813.pdf
SATNet: Bridging deep learning and logical reasoning using a differentiable satisfiability solver
作者:Po-WeiWang1,Priya L. Donti1 2,Bryan Wilder3,Zico Kolter1 4,分別來自卡耐基梅隆大學、南加州大學、Bosch Center for Artificial Intelligence。
論文地址:https://arxiv.org/pdf/1905.12149.pdf
A Tail-Index Analysis of Stochastic Gradient Noise in Deep Neural Networks
作者:Umut?im?ekli?,L, event Sagun?, Mert Gürbüzbalaban?,分別來自巴黎薩克雷大學、洛桑埃爾科爾理工大學、羅格斯大學。
論文地址:https://arxiv.org/pdf/1901.06053.pdf
Towards A Unified Analysis of Random Fourier Features
作者:Zhu Li,Jean-Fran?ois Ton,Dino Oglic,Dino Sejdinovic,分別來自牛津大學、倫敦國王學院。
論文地址:https://arxiv.org/pdf/1806.09178.pdf
Amortized Monte Carlo Integration
作者:Adam Golinski、Yee Whye Teh、Frank Wood、Tom Rainforth,分別來自牛津大學和英屬哥倫比亞大學。
論文地址:http://www.gatsby.ucl.ac.uk/~balaji/udl-camera-ready/UDL-12.pdf
Social Influence as Intrinsic Motivation for Multi-Agent Deep Reinforcement Learning
作者:Natasha Jaques, Angeliki Lazaridou, Edward Hughes, Caglar Gulcehre, Pedro A. Ortega, DJ Strouse, Joel Z. Leibo, Nando de Freitas,分別來自MIT媒體實驗室、DeepMind和普林斯頓大學。
論文地址:https://arxiv.org/pdf/1810.08647.pdf
Stochastic Beams and Where to Find Them: The Gumbel-Top-k Trick for Sampling Sequences Without Replacement
作者:Wouter Kool, Herke van Hoof, Max Welling,分別來自荷蘭阿姆斯特丹大學,荷蘭ORTEC和加拿大高等研究所(CIFAR)。
論文地址:https://arxiv.org/pdf/1903.06059.pdf
ICML 2019:谷歌成為最大贏家,清北、南大港中文榜上有名
本次大會還統計了收錄論文的領域分布情況:
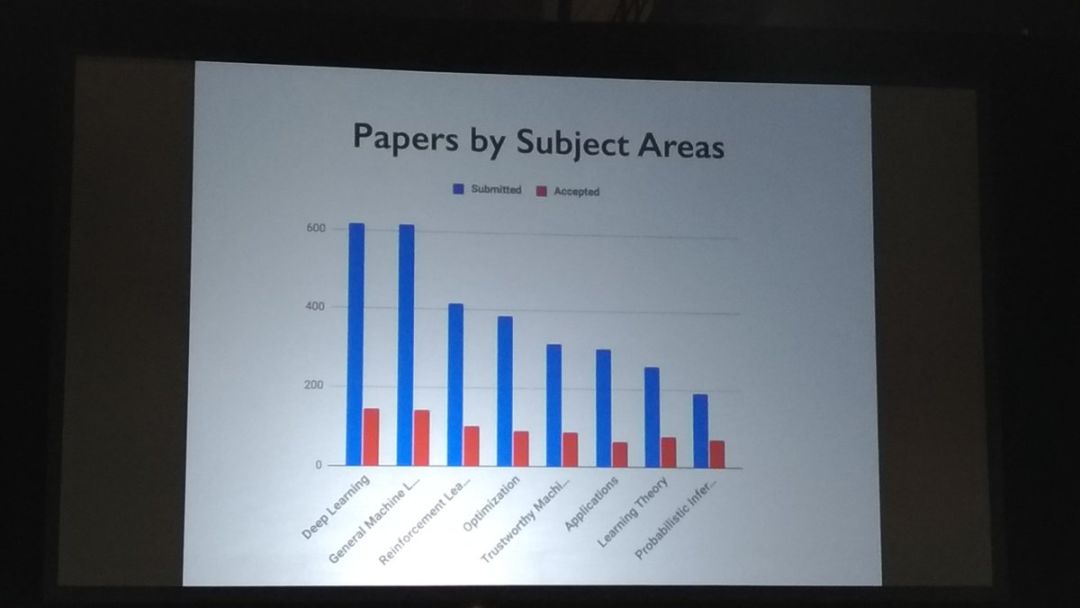
提交論文最多的子領域分別是:深度學習、通用機器學習、強化學習、優化等。
而早在上個月,Reddit網友就發表了他和他的公司對本次ICML 2019論文錄取情況的統計結果。
地址:
https://www.reddit.com/r/MachineLearning/comments/bn82ze/n_icml_2019_accepted_paper_stats/
今年,在所有錄取的論文中,谷歌無疑成為了最大贏家。
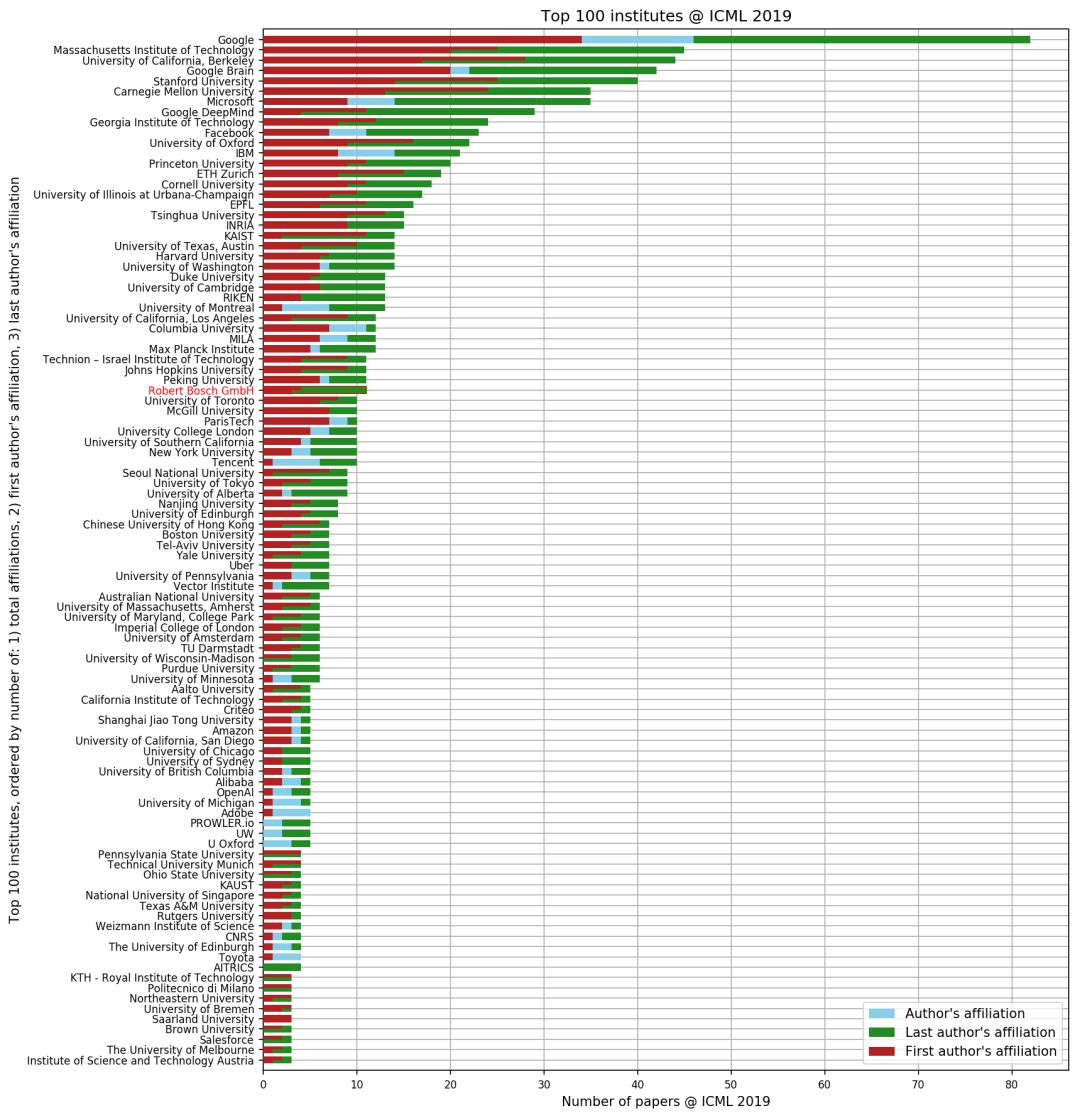
錄取論文總數排名(按研究所)
上表顯示了以研究所(包括產業界和學術界)為單位,錄取論文總數的排名。這項統計中至少有一位作者隸屬于某研究所,因此一篇論文可以出現多次且隸屬多個研究所。
排名地址:
https://i.redd.it/wdbw91yheix21.png
其中,藍色代表論文總數,綠色和紅色分別代表第一作者和通訊作者參與錄取論文的論文數量。并且,附屬機構是手動合并到研究所的,例如Google Inc.、Google AI、Google UK都將映射到Google。
可以看到谷歌錄取論文的數量遠超其它研究所,位列第一;緊隨其后的是MIT、伯克利、谷歌大腦、斯坦福、卡內基梅隆以及微軟。
作者還分別根據學界和產業界進行了統計Top 50排名。
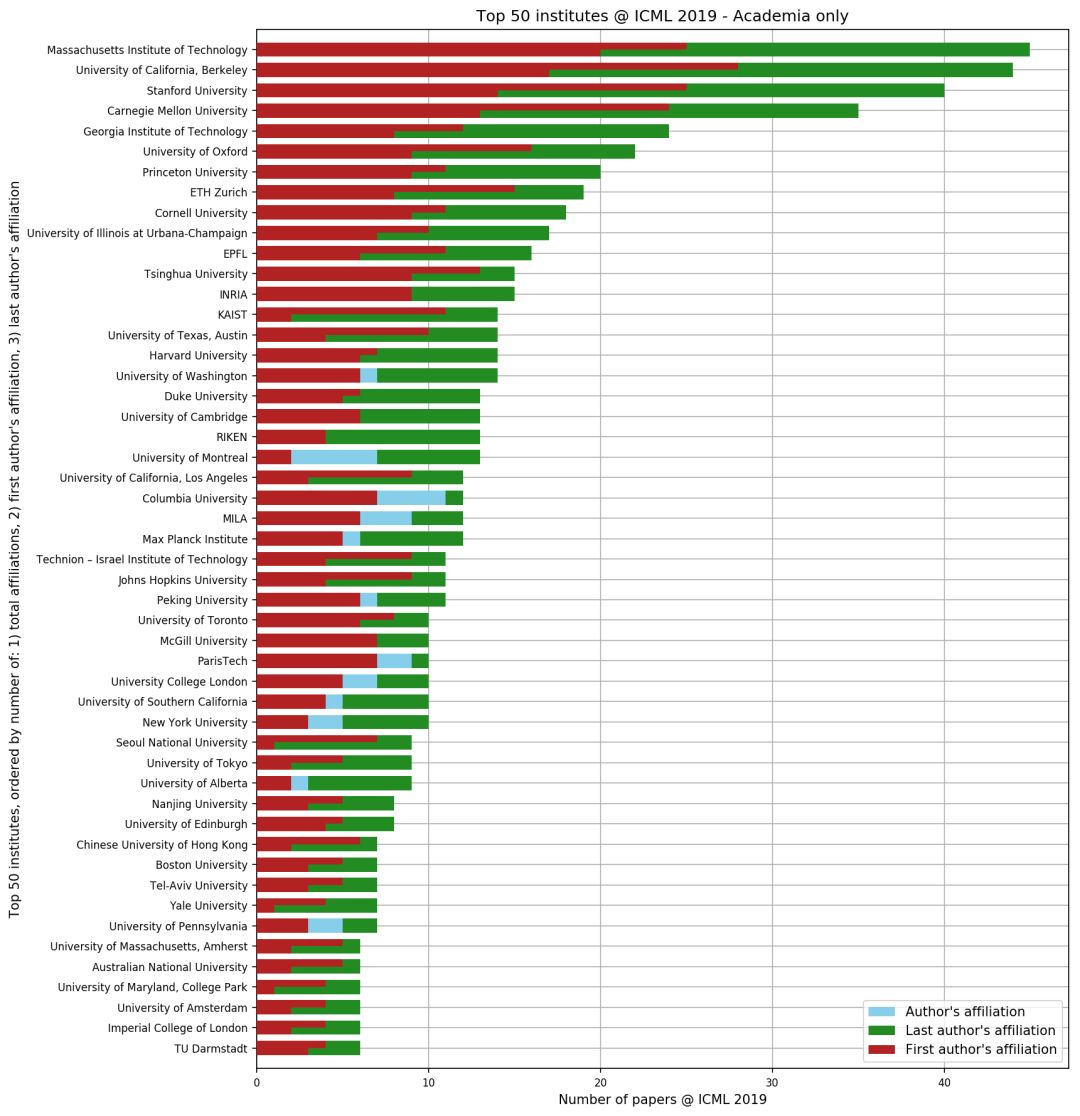
排名統計可視化地址:
https://i.redd.it/37hxhsmfzix21.png
在學界排名中,MIT、加州伯克利分校、斯坦福和卡內基梅隆奪冠前四,成為本屆錄取論文數的第一梯隊,且與第二梯隊拉開了一定差距。
國內上榜的院校包括清華大學、北京大學、南京大學、香港中文大學。
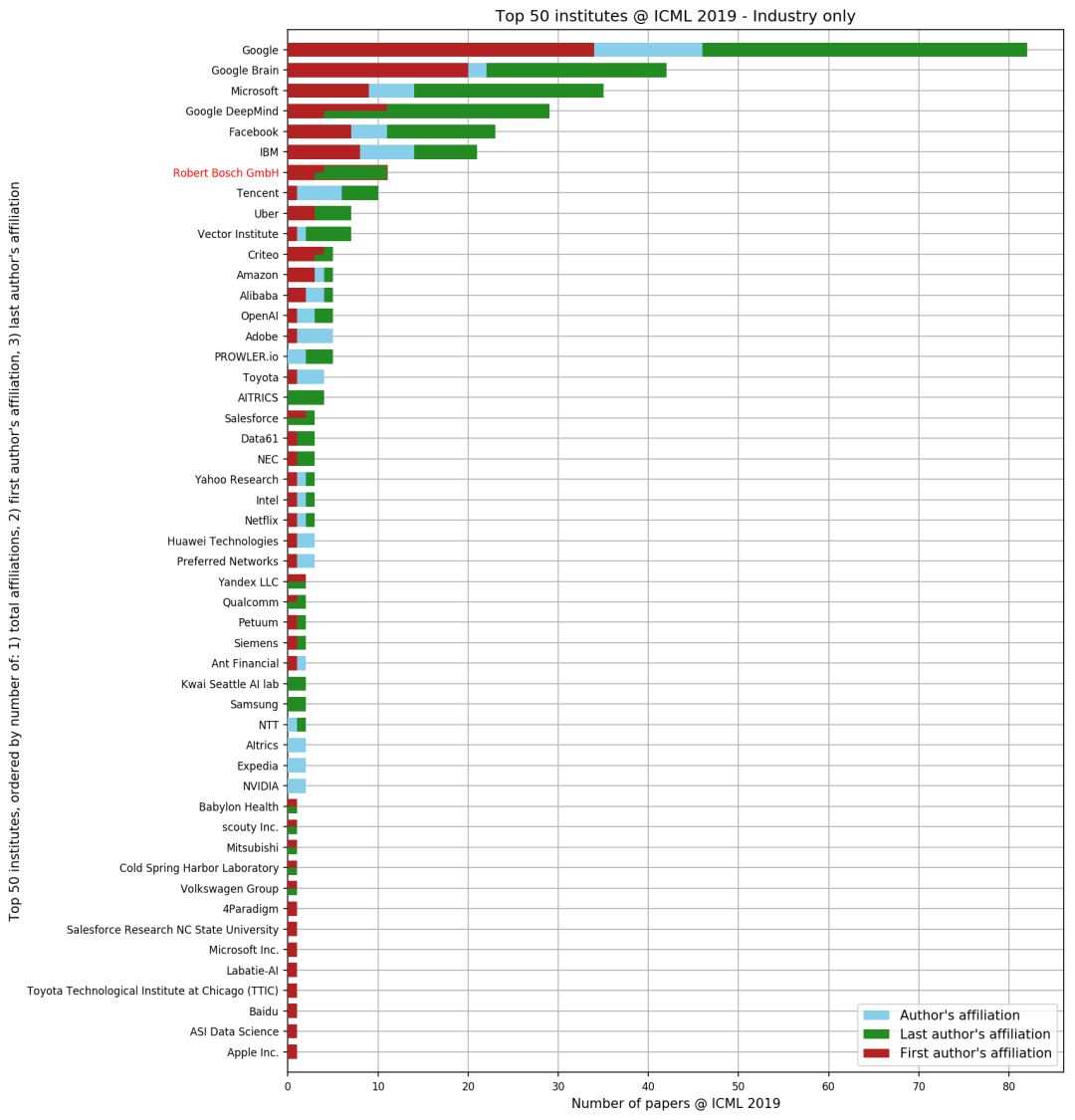
排名可視化地址:
https://i.redd.it/wa6kjzmhzix21.png
在企業研究所Top 50排名中,谷歌無疑成為最大贏家:谷歌、谷歌大腦和谷歌DeepMind分別取得第一、第二和第四的好成績。微軟、Facebook和IBM成績也較優異,位居第三、第五和第六。
而對于國內企業,騰訊(Tencent)成績較好,位居第八名。
此外,從本屆ICML 2019錄取論文情況來看,還可以得到如下統計:
452篇論文(58.4%)純屬學術研究;
60篇論文(7.8%)來自工業研究機構;
262篇論文(33.9%)作者隸屬于學術界和工業界。
總結上述的統計,我們可以得到如下結果:
77%的貢獻來自學術界;
23%的貢獻來自產業界。
-
智能系統
+關注
關注
2文章
392瀏覽量
72423 -
機器學習
+關注
關注
66文章
8381瀏覽量
132428 -
論文
+關注
關注
1文章
103瀏覽量
14951
原文標題:ICML 2019最佳論文出爐,超高數學難度!ETH、谷歌、劍橋分獲大獎
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
安波福蘇州榮獲“2024大蘇州最佳雇主”及“2024最佳HR團隊獎”
流媒體后視鏡市場份額連續6年稱霸全國,新產品即將上市

遠峰科技:流媒體后視鏡市場份額連續6年稱霸全國,新產品即將上市

中科馭數聯合處理器芯片全國重點實驗室獲得“CCF芯片大會最佳論文獎”
Samtec在2024慕尼黑上海電子展精彩回顧

格靈深瞳名列「智慧校園體育品牌影響力綜合評價」榜首

2024年汽車軟件開發狀況調查結果出爐:軟件研發人員必看

智能家居議程新鮮出爐!報名最后倒計時!

基于高光譜成像的蔬菜新鮮度檢測

蔚來智能駕駛月度運營報告新鮮出爐:新增智能駕駛用戶11,816名
天合光能獲評PV Tech 2023最佳ESG表現光伏公司
2023年動力電池數據新鮮出爐






 工商網監
工商網監
評論