 自動駕駛模擬仿真系統中的傳感器模型
自動駕駛模擬仿真系統中的傳感器模型
攝像頭
攝像頭仿真就是生成圖像,逼真的圖像,通過計算機圖形學對三維景物(CAD)模型添加顏色與光學屬性。現在流行的Unreal Engine或者Unity 3D,就是基于物理的渲染引擎,實現一些CAD模型的繪制算法,比如光線跟蹤(ray tracing)或者光線投射(ray casting),來實現圖像合成(如圖展示光線和圖像的關系)。一些開源的自動駕駛仿真系統比如Intel Carla(Car Learning to Act)和Microsoft AirSim都采用了這些渲染引擎。
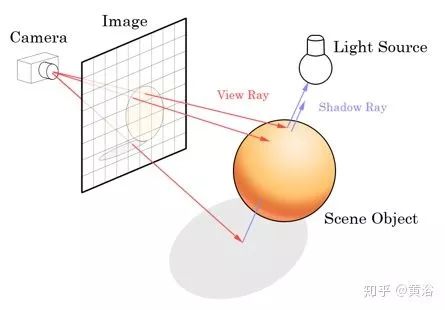
有一些開源的虛擬圖像庫,已經在計算機視覺的研究中得到應用,比如Virtual KITTI,FCAV (UM Ford Center for Autonomous Vehicles)和Synthia等,下面圖有一些各自的圖像例子。
理論上,在計算機圖形學有各種光照模型和繪制模型,當年Nvidia在GPU硬件對圖形學算法加速做出了重大貢獻,包括著名的voxel shader和pixel shader(fragment shader)。大家說計算機視覺是計算機圖形學的逆過程,只是它和計算機圖形學也可以結合,結果有兩個重要輸出,一個是增強現實(AR),另一個是基于圖像的繪制(IBR)。
AR的思想在仿真系統也可以體現,比如在真實的街景中可以插入合成的車輛或者行人。IBR在虛擬環境生成的過程中可以通過一些拍攝的圖像生成一些背景以簡化實際渲染的計算量。更甚至,通過機器學習,比如GAN,在大量真實圖像數據的訓練情況下,和圖形學的CAD模型結合,也可以合成新場景圖像。
除了3-D幾何和物理模型之外,還需要對相機鏡頭的結構與光學特性,內部數據采集過程進行仿真,例如焦距,畸變,亮度調節,伽瑪調節,景深(depth of field),白平衡,高動態范圍(HDR)色調調整等。
激光雷達
介紹一篇模擬激光雷達的論文。首先,采用非常流行的游戲GTA-V(Grand Theft Auto V)獲取模擬的點云和高保真圖像。
為了模擬真實的駕駛場景,在游戲中使用自主車(ego vehicle),安裝有虛擬激光雷達,并通過AI接口在虛擬世界中進行自動駕駛。系統同時收集激光雷達點云并捕捉游戲圖像。在虛擬環境中,虛擬攝像頭和虛擬激光雷達放在同一個位置。這樣做有兩個優點:
可以輕松地對收集的數據進行健全性檢查(sanity check),因為點云和相應的圖像必須保持一致;
游戲的虛擬攝像頭和虛擬激光雷達之間的標定可以自動完成,然后收集的點云和場景圖像可以組合在一起作為傳感器融合任務的神經網絡訓練數據集。
光線投射(ray tracing)用于模擬虛擬激光雷達發射的每個激光射線。光線投射將光線起點和終點的3D坐標作為輸入,并返回該光線命中的第一個點3D坐標,該點將用于計算點的距離。激光雷達參數包括垂直視場(VFOV),垂直分辨率,水平視場(HFOV),水平分辨率,俯仰角,激光射線的最大范圍和掃描頻率。
如下圖顯示了一些可配置的參數:(a)虛擬激光雷達前向圖的正視圖:黑色虛線是水平線,α是垂直視場(FOV),θ是垂直分辨率,σ是俯仰角; (b)表示虛擬激光雷達的俯視圖,β是水平FOV,φ是水平分辨率。
該系統實現3-D激光雷達點云和攝像頭圖像的自動校準,而且用戶可以選擇所需的游戲場景,并指定和改變游戲場景的8個維度:汽車模型,位置,方向,數量,背景,顏色,天氣和時間。前5個維度同時影響激光雷達點云和游戲圖像,而后3個維度僅影響游戲圖像。
介紹一篇基于機器學習模擬雷達的論文工作。由于多徑反射,干涉,反射表面,離散單元和衰減等影響,雷達建模不簡單。詳細基于物理原理的雷達模擬是有的,但對實際場景而言計算量難以承受。
一種構建概率隨機汽車雷達模型的方法基于深度學習和GAN,產生的模型體現了基本的雷達效應,同時保持實時計算的速度。采用深度神經網絡作為雷達模型,從數據中學習端到端的條件概率分布。網絡的輸入是空間柵格和對象列表,輸出是讀取的傳感器數據。
如上圖是在深度學習框架下模擬雷達數據的表示。空間柵格是具有兩個主要尺寸,即距離和方位角的的3D張量,第3維度是由不同類型的信息層組成。這個類似于RGB圖像,其像素信息存儲在空間維度和顏色通道中。那么,這種空間柵格同樣適合CNN模型。
提供兩個直接參數化概率分布的基準雷達模型:正態分布和高斯混合模型。多變量正態分布通常用于機器學習,因為它具有良好的數學性能。不過,正態分布是單峰的。而且正態分布的參數與目標變量的維數呈二次方增長。這里CNN模型的輸出是具有兩層的張量網格:一個平均值,一個對角對數方差。
隨機雷達模型的一個重要挑戰是,傳感器輸出是多模態和空間相關的。回歸方法將平滑可能的解決方案,導致模糊的預測。而變分自動編碼器(VAE)允許學習一對多概率分布而無需明確輸出哪個分布。
該模型的架構是一個編碼器-解碼器網絡。
編碼器獲取光柵和對象列表并產生潛在的特征表示x,解碼器采用特征表示和隨機生成的噪聲值并產生預測的傳感器測量值。編碼器由兩分支組成,即一個空間光柵和一個對象列表,這些分支合并在一起產生潛在的特征表示。兩個分支完全由卷積層組成。輸出被扁平化級聯在一起,然后使用有ReLU的全連接層處理。
解碼器使用編碼特征和隨機噪聲生成功率值的雷達極坐標網格。 在VAE重新參數化時候,隨機噪聲加入輸入信號。使用ReLU激活的全連接層連接和處理噪聲和潛在特征,然后重新整形和一系列反卷積層處理,產生輸出雷達信號。
其他傳感器
其他傳感器,如GPS,IMU,超聲波雷達和V2X傳感器,也可以模擬仿真其數據。
GPS模擬GPS位置以及GPS噪聲模型參數,輸出車的經緯度,速度,航向等。
IMU模擬車的加速度和角速度,特別是GPS信號丟失時車的位置,速度、和航向的累積誤差。
超聲波雷達(主要是自動泊車)模擬超聲波雷達位置,角度和障礙物的距離。
V2X模擬動態交通流設備數據,甚至要反映通信延時或丟包的情況。
-
攝像頭
+關注
關注
59文章
4812瀏覽量
95463 -
自動駕駛
+關注
關注
783文章
13690瀏覽量
166162
原文標題:自動駕駛模擬仿真系統中的傳感器模型
文章出處:【微信號:IV_Technology,微信公眾號:智車科技】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
MEMS技術在自動駕駛汽車中的應用
FPGA在自動駕駛領域有哪些優勢?
FPGA在自動駕駛領域有哪些應用?
自動駕駛識別技術有哪些
自動駕駛汽車傳感器有哪些
XV7181BB 陀螺儀傳感器在自動駕駛設備中的應用

自動駕駛仿真測試實踐:高精地圖仿真

揭秘自動駕駛:未來汽車的感官革命,究竟需要哪些超級傳感器?
未來已來,多傳感器融合感知是自動駕駛破局的關鍵
探索自動駕駛傳感器仿真模型的可信度







 工商網監
工商網監
評論