 開辟新篇章!谷歌機器學習又有新進展!
開辟新篇章!谷歌機器學習又有新進展!
在谷歌最新的論文中,研究人員提出了“非政策強化學習”算法OPC,它是強化學習的一種變體,它能夠評估哪種機器學習模型將產生最好的結果。數據顯示,OPC比基線機器學習算法有著顯著的提高,更加穩健可靠。
在谷歌AI研究團隊一篇新發表的論文《通過非政策分類進行非政策評估》(Off-PolicyEvaluation via Off-Policy Classification)和博客文章中,他們提出了所稱的“非政策分類”,即OPC(off-policy classification)。它能夠評估AI的表現,通過將評估視為一個分類問題來驅動代理性能。
研究人員認為他們的方法是強化學習的一種變體,它利用獎勵來推動軟件政策實現與圖像輸入協同工作這個目標,并擴展到包括基于視覺的機器人抓取在內的任務。
“完全脫離政策強化學習是一種變體。代理完全從舊數據中學習,對于工程師來說這是很有吸引力的,因為它可以在不需要物理機器人的情況下進行模型迭代。”
Robotics at Google(專注機器學的的谷歌新團隊)的軟件工程師Alexa Irpan寫道,“完全脫離政策的RL,可以在先前代理收集的同一固定數據集上訓練多個模型,然后選擇出最佳的那個模型。”
但是OPC并不像聽起來那么容易,正如Irpan在論文中所描述的,非政策性強化學習可以通過機器人進行人工智能模型培訓,但不能進行評估。并且在需要評估大量模型的方法中,地面實況評估通常效率太低。
OPC在假設任務狀態變化方面幾乎沒有隨機性,同時假設代理在實驗結束時用“成功或失敗”來解決這個問題。兩個假設中第二個假設的二元性質,允許為每個操作分配兩個分類標簽(“有效”表示成功或“災難性”表示失敗)。
另外,OPC還依賴Q函數(通過Q學習算法學習)來估計行為的未來總回報。代理商選擇具有最大預期回報的行動,其績效通過所選行動的有效頻率來衡量(這取決于Q函數如何正確地將行動分類為有效與災難性),并以分類準確性作為非政策評估分數。
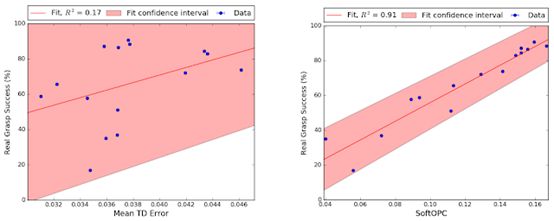
(左圖為基線,右圖為建議的方法之一,SoftOpC)
谷歌AI團隊使用完全非策略強化學習對機器學習策略進行了模擬培訓,然后使用從以前的實際數據中列出的非策略分數對其進行評估。
在機器人抓取任務時,他們報告OPC的一種變體SoftOPC在預測最終成功率方面表現最佳。假設有15種模型(其中7種純粹在模擬中訓練)具有不同的穩健性,SoftOPC產生的分數與與真正的抓取成功密切相關,并且相比于基線方法更加穩定可靠。
在未來的研究中,研究人員打算用“噪聲”(noisier)和非二進制動力學來探索機器學習任務。“我們認為這個結果有希望應用于許多現實世界的RL問題,”Irpan在論文結尾寫道。
-
谷歌
+關注
關注
27文章
6142瀏覽量
105096 -
機器學習
+關注
關注
66文章
8377瀏覽量
132407
發布評論請先 登錄
相關推薦
魏德米勒開啟產業數智轉型新篇章
揚帆出海!穩石氫能AEM電解槽出貨智利,開啟全球商業化新篇章!

摩爾線程與中國移動攜手,共筑生態與應用開創數智新篇章
復合機器人:開啟智能倉儲新篇章

阿里巴巴AI賦能海外擴張新篇章
探索未來智能制造新篇章——富唯智能復合機器人


深開鴻與哈工大重慶研究院合作共同開啟智能機器人與協同技術的新篇章

深開鴻與哈工大重慶研究院攜手打造智能機器人與協同技術新篇章

華盛昌與易達云成功簽署戰略協議,共同開啟合作新篇章






 工商網監
工商網監
評論