 CapsNet再升級!堆棧式膠囊自編碼器面世
CapsNet再升級!堆棧式膠囊自編碼器面世
2017 年,Geoffrey Hinton 在論文《Dynamic Routing Between Capsules》中提出 CapsNet 引起了極大的關注,同時也提供了一個全新的研究的方向。今日,CapsNet 的作者 Sara Sabour、Hinton 老爺子聯合牛津大學的研究者提出了膠囊網絡的改進版本——堆棧式膠囊自編碼器。這種膠囊自編碼器可以無監督地學習圖像中的特征,并在無監督分類任務取得最佳或接近最佳的表現。這也是膠囊網絡第一次在無監督領域取得新的突破。
綜述
一個目標可以被看做是一組相互關聯的部件按照幾何學形式組合的結果。利用這種幾何關系去重建目標的系統應當對視點的變化具有魯棒性,因為其本質的幾何關系不應隨著觀察視角的變化而發生改變。
本文中,研究人員描述了一種無監督的膠囊網絡。其中,觀察組成目標所有部件的神經編碼器被用來推斷目標膠囊的存在和姿態。編碼器通過解碼器的反向傳播方法訓練。
訓練中,解碼器使用姿態預測來預測每個已發現部件的姿態。這些部件是直接從圖像中被發現的,同樣也是使用神經編碼器,該編碼器推斷這些部件及它們的仿射變換。
而對應的解碼器將每個圖像像素建模為由仿射變換部件做出的預測混合。研究人員從目標和目標部件的膠囊中學習無標簽數據,然后將這些目標膠囊的存在向量進行聚類。
得知這些聚類的名稱時,研究人員在 SVHN 和 MNIST 數據集上獲得了當前最佳的無監督分類結果,準確率分別為 55% 和 98.5%。
本文提出了堆棧式膠囊自編碼器(SCAE),該編碼器包含兩個階段。在第一階段,部件膠囊自編碼器(PCAE)將圖像分割為組成部分,推斷其姿態,并將每個圖像像素重建為變換組件模板的像素混合。
在第二階段,目標膠囊自編碼器(OCAE)嘗試將發現的部件及其姿態安排在一個更小的目標集合中。這個目標集合對每個部件進行預測,從而解釋每個部件的姿態。通過將它們的姿態——目標-觀察者關系(OV)和相關的目標-部件關系(OP)相乘,每個目標膠囊都會貢獻這些混合的一部分。
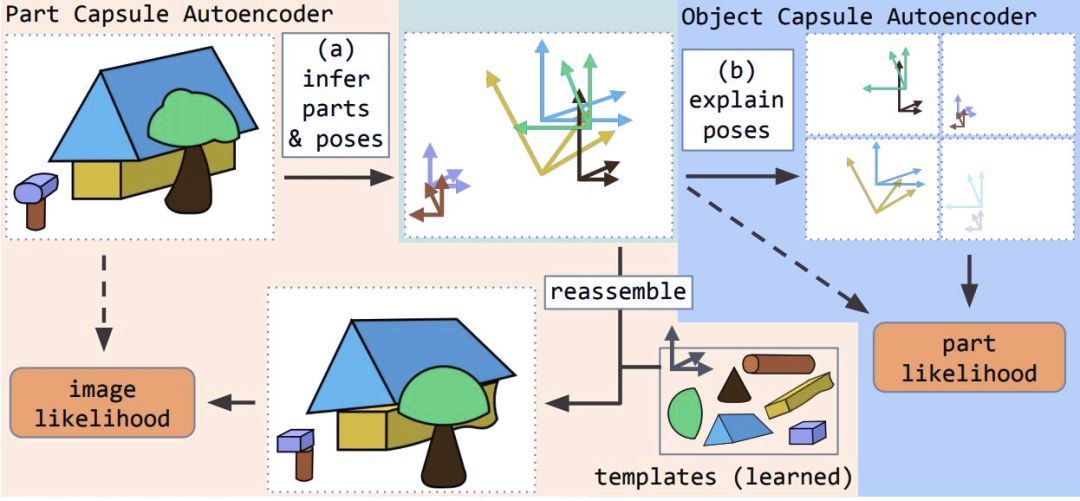
堆棧式膠囊自編碼器的工作原理
堆棧式膠囊自編碼器在使用未標注數據訓練時捕捉所有目標和它們部件之間的空間關系。目標膠囊存在概率的向量傾向于組成緊密的聚類。
當給每個聚類一個分類時,其可以在無監督分類任務上達到當前最佳效果,如 SVHN 數據集上的 55% 和 MNIST 數據集上的 98.5%。以上結果還可以分別提升到 67% 和 99%,而且只需學習不到 300 個參數。
模型架構
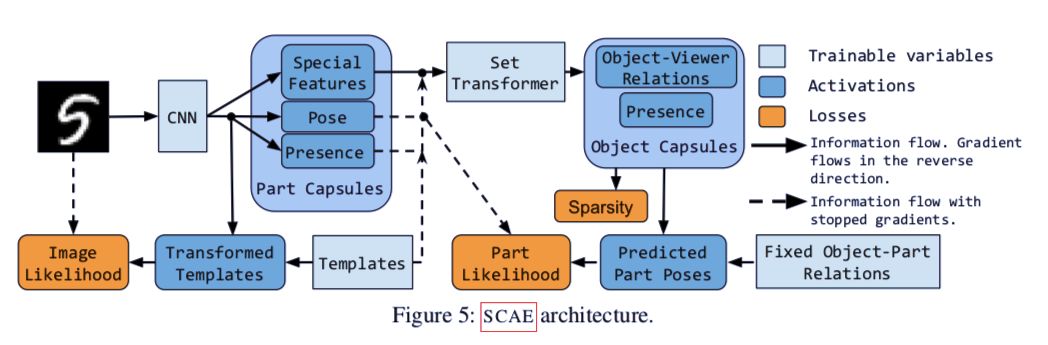
堆棧式膠囊自編碼器的結構
堆棧式膠囊自編碼器的兩個組成部分為:部件膠囊自編碼器(PCAE)和目標膠囊自編碼器(OCAE)。在下文中,論文首先介紹了集群自編碼器(CCAE),通過一系列數學公式說明自編碼器如何分解圖像中的部件的過程,然后由此引出堆棧式膠囊自編碼器的兩個組成部分。
集群自編碼器

圖 2:使用集群自編碼器對不同形狀的點進行聚類的示意圖。
論文首先介紹了集群自編碼器,通過這種結構的數學原理,引出堆棧式膠囊自編碼器的結構。令 {x_m | m = 1, . . . , M } 為一組二維的輸入點,每個點屬于一個集群(見圖2)。首先使用Set Transformer將所有的輸入點(相當于部件膠囊)編碼進k個目標膠囊中,Set Transformer是一種基于注意力機制的、有置換不變性的編碼器h^cap (Lee et al., 2019) 。
一個目標膠囊 k 包括一個膠囊特征向量 c_k(其存在概率 a_k ∈ [0, 1])和一個 3 × 3 的目標-觀察者(OV)關系矩陣。關系矩陣代表著目標(集群)和觀察者之間關系的仿射變換。
需要注意的是,每個目標膠囊每次只能代表一個目標。每個目標膠囊都使用一個獨立的多層感知機 h_k^part 從膠囊特征向量 c_k 中預測 N ≤ M 個候選部件。
每個候選由條件概率 a_k,n ∈ [0, 1] (當其存在),一個關聯標量的標準差λ_k,n,以及一個 3 × 3 的目標-部件(OP)關系矩陣組成。這些代表著目標膠囊和候選部件的仿射變換。
候選預測 μ_k,n 根據目標膠囊 OV 和候選 OP 矩陣相乘得來。然后,研究人員將每個輸入部件建模為高斯混合模型,其中μ_k,n 和 λ_k,n 是各向同性組件的中心和標準差。其標準公式如下:

集群膠囊編碼器的公式。論文通過舉出集群膠囊編碼器的例子,用于說明目標膠囊編碼器和它的區別。
部件膠囊自編碼器
如果要將圖像分解為組成部件的集合關系,就需要首先推斷圖像是由哪些部件組成的,同時也需要了解觀察者和這些部件之間的關系(稱之為他們的姿態)。
在本研究中,每個部件膠囊都有六個維度的自由姿態,一個存在變量,和一個獨特的特征。研究人員把部件發現問題視為自編碼:編碼器學習去推斷不同部件膠囊的姿態和存在,而解碼器學習每個部件的圖像模板。
模板對應的部件是使用其姿態的仿射變換,而這些變換過的模板的像素點被用來為每個圖像像素創建單獨的混合模型。在部件膠囊自編碼器后是目標膠囊自編碼器。
令 y ∈ [0, 1]^h×w×c 為圖像。研究人員將部件膠囊的數量限定在 M 之內。對于每個部件膠囊,他們使用一個編碼器去推斷姿態 x_m ∈ R^6,存在概率 d_m ∈ [0, 1],以及特殊特征 z_m ∈ R^c_z。
雖然后者不會直接參與圖像重建,但是會將對應部件的特殊信息提供給目標膠囊自編碼器。他們會通過目標膠囊自編碼器使用反向傳播微分的方式訓練。
當前條件下,不允許圖像中同一種類型的部件多次出現,從而導致部件膠囊不會在空間中被復制(盡管它們可能會)。然而,確實需要分辨出所有出現在圖像中的部件,因此編碼器會采用帶有從下到上(bottom-up)注意力機制的卷積神經網絡。
對于每個膠囊 k,其預測一個特征矩陣 e^k,特征矩陣是 6(姿態)+1(存在)+c_z(特殊特征)的膠囊參數,其空間維度是 h_e × w_e,以及一個單通道注意力層 a_k。
最終,該膠囊的參數計算公式是 。softmax 是對空間維度上的計算。這種計算有點類似于全局平均池化,但是允許一些空間點比其他點對最終結果的權重影響更大。研究人員將其稱為注意力池化(attention-based pooling)。
。softmax 是對空間維度上的計算。這種計算有點類似于全局平均池化,但是允許一些空間點比其他點對最終結果的權重影響更大。研究人員將其稱為注意力池化(attention-based pooling)。
圖像的像素點被建模為獨立的高斯混合模型。對于每個像素點,研究人員采用其對應的變換模板,并將其視為有著恒定方差的各向同性高斯組件的中心點。其混合概率對部件膠囊的存在概率和在該位置的色值函數 (c 指的是圖像的通道數)都是成比例的。
(c 指的是圖像的通道數)都是成比例的。

部件膠囊自編碼器的公式推導過程
目標膠囊自編碼器(OCAE)
下一步是從已經發現的部件中尋找目標。因此,需要使用相連的姿態 x_m,特殊特征 z_m,以及平滑化的模板 T_m(通過將部件膠囊的特征進行轉化)。這些將會成為目標膠囊自編碼器的輸入,這里和集群自編碼器有一些不同。
首先,研究人員將部件膠囊的存在概率 d_m 輸入目標膠囊自編碼器——由于平衡注意力機制,避免將缺失點考慮在內。
其次,d_m 同時用于衡量部件膠囊的對數似然 cf。另外,除了特殊特征外,不對其他目標膠囊自編碼器的輸入計算梯度,以便提升訓練的穩定性,并避免隱變量崩潰。
最后,通過部件膠囊自編碼器發現的部件有著獨立的特征(模板和特殊特征)。因此,每個部件姿態都可以被解釋為是目標膠囊預測的獨立混合——即每個目標膠囊都做出 M 個候選預測 V_k,1:M,或者對每個部件做出一個候選預測。
最終,部件膠囊的似然公式是:


圖 3:從MNIST(左)和SVHN(中)和CIFAR 10(右)學習到的模板。

圖 4:展示了膠囊自編碼器對MNIST數據集的重建過程。a)MNIST圖像;b)紅色的部件膠囊和綠色的目標膠囊在重建中的組合;c)實際參與重建的被激活膠囊;d)根據圖像捕捉到的信息;e)部件的仿射變換,用于展示其重建圖像的過程。
模型性能評估
堆棧式膠囊自編碼器使用仿射變換,這樣可以使編碼器的輸入由一組較小的變換目標或部件解釋。
無監督分類評價
研究人員在 MNIST、SVHN 和 CIFAR 10 數據集上進行了測試,并將目標膠囊的存在打上類別標簽。他們使用了多種評價方法。
在部件膠囊編碼器上,研究人員在 MNIST 數據集上使用了 24 個單通道,11 × 11 的模板,在 SVHN 和 CIFAR 10 上則分別使用了 32 個 3 通道,14 × 14 的模板。
對于后兩個數據集的圖像,研究人員進行了 Sobel 過濾,作為重建的目標。對于目標膠囊編碼器,研究則分別使用了 24、32 和 64 個目標膠囊。
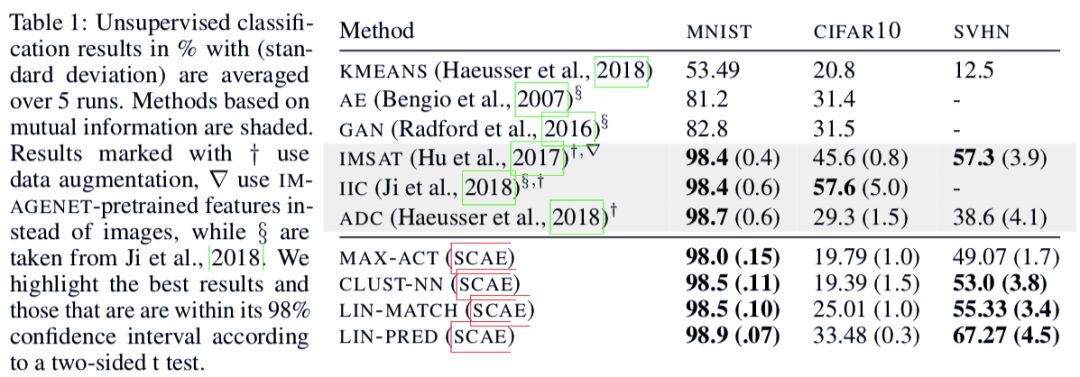
表 1:運行五次后取平均的無監督分類結果和標準差。
-
編碼器
+關注
關注
45文章
3595瀏覽量
134160 -
無監督學習
+關注
關注
1文章
16瀏覽量
2752
原文標題:Hinton老爺子CapsNet再升級,結合無監督,接近當前最佳效果
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
增量式編碼器單圈和多圈怎么知道,如何分辯?

磁電式編碼器磁鐵怎么固定的
磁電編碼器和光電編碼器的區別
模塊式編碼器原理 精度與分辨率

自編碼器的原理和類型
伺服電機編碼器的型號怎么看


編碼器分辨率是什么意思 編碼器分辨率和脈沖數的關系

編碼器好壞怎么判斷,編碼器原理
磁性編碼器和光電編碼器的比較
如何獲取編碼器的脈沖信號? | 編碼器互補輸出和推挽式輸出的區別?






 工商網監
工商網監
評論