 無需翻譯的無監督復述的新方法:允許從輸入句子生成多樣化、但語義上接近的句子
無需翻譯的無監督復述的新方法:允許從輸入句子生成多樣化、但語義上接近的句子
無需翻譯的無監督復述的新方法:允許從輸入句子生成多樣化、但語義上接近的句子。模型基于矢量量化自動編碼器(VQ-VAE),可以在單純語言環境中解釋句子。它還具有獨特的功能,即與量化瓶頸并行的殘余連接,可以更好地控制解碼器熵并簡化優化過程。
近年來,研究人員一直在嘗試開發自動復述的方法,復述就是對相同語義的不同表達,例如一句話,可以有一千種說法。這需要從文本中自動抽象語義內容。
由于缺乏可用的復映對標記數據集,目前更多的是使用依賴于機器翻譯(MT)技術的方法,已經被證明非常受歡迎。
理論上來看,翻譯技術可能是自動復述的有效解決方案,因為翻譯技術是從語言實現中抽象出語義內容。例如,將相同的句子分配給不同的翻譯者,最終翻譯出來的內容通常是有差別的,這樣就得到一個豐富的解釋集,在復述任務中可能會非常有用。
盡管許多研究人員已經開發出基于翻譯的自動復述方法,但顯然人類并不需要翻譯才能解釋句子。
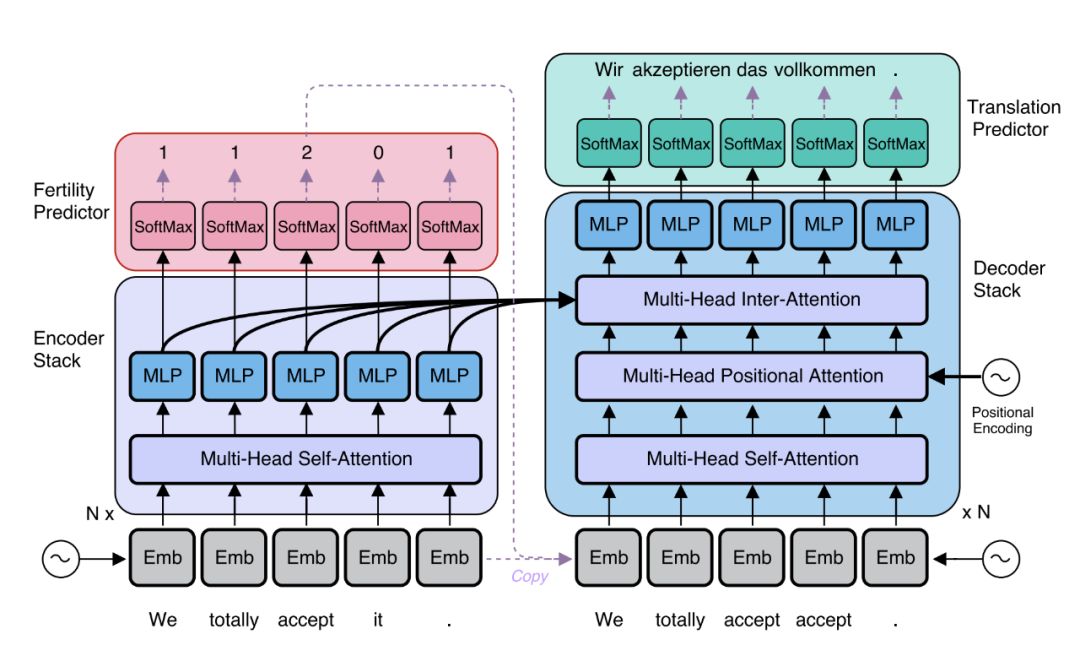
基于這一觀察結果,Google Research的兩位研究人員最近提出了一種新的復述技術,可以不依賴機器翻譯的方法。
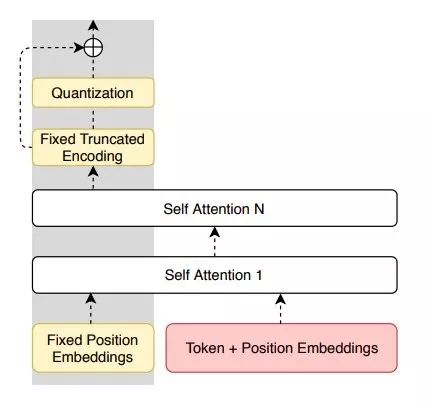
在預先發表在arXiv上的論文中,他們將這種單語方法與其他翻譯技巧進行了比較(例如監督翻譯和無監督翻譯方法),該論文被引用了47次。
進行這項研究的兩位研究人員Aurko Roy和David Grangier在他們的論文中寫道:“這項工作建議只從未標記的單語語料庫中學習復述模型…為此,我們提出了矢量量化變分自動編碼器的殘差變量。”
Aurko Roy
David Grangier
研究人員介紹的模型基于矢量量化自動編碼器(VQ-VAE),可以在單純語言環境中解釋句子。同時,它還具有獨特的特征(即與量化瓶頸并行的殘余連接),這使得能夠更好地控制解碼器熵、并簡化優化過程。他們的模型只需要在一種語言中使用未標記的數據:即用語言來解釋句子。
研究人員在論文中解釋道:“與連續自動編碼器相比,我們的方法允許從輸入句子生成多樣化、但語義上接近的句子。”
在研究中,Roy和Grangier將他們的模型表現與其他基于MT的方法在復述識別、生成和訓練增強方面的表現進行了比較。
他們特別將這種方法,與在平行雙語數據上訓練的監督翻譯方法、以及在兩種不同語言的非平行文本上訓練的無監督翻譯方法進行了比較。
研究人員發現,他們的單語方法在所有任務中均優于無監督翻譯技術。另一方面,他們的模型和監督翻譯方法之間的比較產生了混合的結果:單語方法在識別和增強任務中表現更好,而監督翻譯方法在復述生成方面表現更好。
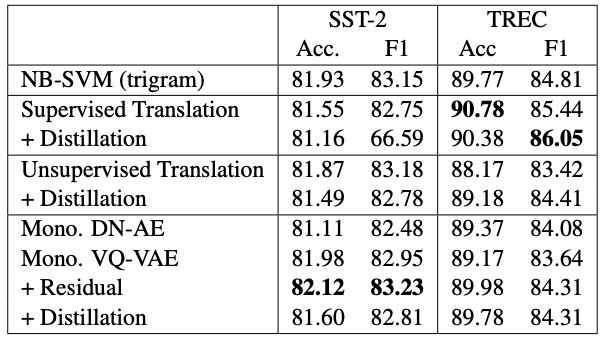
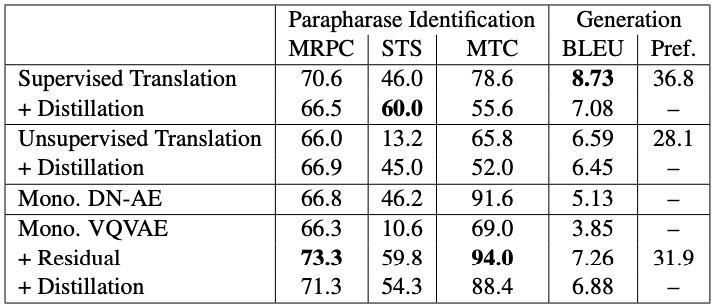
研究人員總結道:“總的來說,我們發現在進行復述識別和數據增強方面,單語模型可以勝過雙語模式。單語模型的生成質量要高于基于無監督翻譯的模型,但并不高于基于有監督翻譯的模型。”
Roy和Grangier的研究結果表明,雖然使用雙語并行數據(即文本及在其他語言中的可能翻譯)在產生復述能夠得到更卓越的表現。然而,在雙語數據不易獲得的情況下,谷歌研究院提出的單語模型可能是一種有用的資源或替代解決方案。
-
解碼器
+關注
關注
9文章
1131瀏覽量
40684 -
谷歌
+關注
關注
27文章
6142瀏覽量
105116 -
數據集
+關注
關注
4文章
1205瀏覽量
24649
原文標題:谷歌NLP新方法:無需翻譯,質量優于無監督翻譯模型
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
NLPIR語義分析是對自然語言處理的完美理解
深入挖掘通用句子編碼器的每個組成部分
一種改進的句子相似度計算模型
英漢機器翻譯中基于模式的譯文生成
漢語句子聯想生成器
以語義、句式以及變量為基礎的翻譯方法
基于分層組合模式的句子組合模型
基于LDA模型的句子主題特征
句子相似度計算方法
自然語言的語義表示學習方法與應用
一種無監督下利用多模態文檔結構信息幫助圖片-句子匹配的采樣方法





 工商網監
工商網監
評論