 Linux微服務架構中容錯隔離的詳細資料技術
Linux微服務架構中容錯隔離的詳細資料技術
我們知道,在單體應用的架構下一旦程序發生了故障,那么整個應用可能就沒法使用了,所以我們要把單體應用拆分成具有多個服務的微服務架構,來減少故障的影響范圍。但是在微服務架構下,有一個新的問題就是,由于服務數變多了,假設單個服務的故障率是不變的,那么整體微服務系統的故障率其實是提高了的。
比如:假設單個服務的故障率是0.01%,也就是可用性是99.99%,如果我們總共有10個微服務,那么我們整體的可用性就是99.99%的十次方,得到的就是99.90%的可用性(也就是故障率為0.1%)。可見,相對于之前的單體應用,整個系統可能發生故障的風險大幅提升。
那么在這種情況下,我們應該怎么去保證微服務架構的可用性呢?
其實我們參考造船行業對船艙進水風險的隔離方法,如上圖。
造船行業有一個專業術語叫做「艙壁隔離」,利用艙壁將不同的船艙隔離起來,如果某一個船艙進了水,那么就可以立即封閉艙門,形成艙壁隔離,只損失那一個船艙,其他船艙不受影響,整個船只還是可以正常航行。
對應到微服務架構中,我們要做的就是最大限度的隔離單個服務的風險,也就是「 容錯隔離 」的方法。
一、微服務架構中可用性風險有哪些?
在聊「容錯隔離」方法之前,我們先來看一下微服務架構中,常見的可用性風險到底有哪些吧,知道了有哪些風險我們才知道該如何去規避、去隔離風險。
我們可以從項目部署規模的角度去分析風險:
單機可用性風險:
這個很好理解,就是微服務部署所在的某一臺機器出現了故障,造成的可用性風險。這種風險發生率很高,因為單機器在運維中本身就容易發生各種故障,例如 硬盤壞了、機器電源故障等等,這些都是時有發生的事情。不過雖然這種風險發生率高,但危害有限,因為我們大多數服務并不只部署在一臺機器上,可能多臺都有,因此只需要做好監控,發現故障之后,及時的將這臺故障機器從服務集群中剔除即可,等修復了再重新上線到集群里。
單機房可用性風險:
這種風險的概率比單機器的要低很多,但是也不是完全不可能發生,在實際情況中,還是有一定概率的。比如最為常見的就是通往機房的光纖被挖斷了,前段時間支付寶所在機房不是就發生過光纖被挖么。
咱們全國大小城市都在瘋狂的進行基建,修橋修路修房子,GDP就這么搞起來了,地下的光纖挖斷幾根不是再正常不過的事情了么,哈哈。
如果我們的服務全部都部署在單個機房,而機房又出故障了,那就沒轍了。好在,現在大多數中大型項目都會采用多機房部署的方案,比如同城雙活、異地多活等。一旦某個機房出現了故障不可用了,咱們立即采用切換路由的方式,把這個機房的流量切到其它機房里。
跨機房集群可用性風險:
既然都跨機房集群了,可用性理論上應該沒啥問題啊。但要知道這是在物理層面沒有問題了,如果咱們的代碼有坑,或者因為特殊原因用戶流量激增,導致我們的服務扛不住了,那在跨機房集群的情況下一樣會不可用。但如果我們提前做好了「容錯隔離」的一些方案,比如 限流、熔斷 等等,用上這些方法還是可以保證一部分服務或者一部分用戶的訪問是正常。
二、「 容錯隔離 」的方法有哪些?
好了,上面講了微服務架構中可能遇到這么多的可用性風險,并且也知道了「容錯隔離」的重要性,下面我們再來看看常見的「容錯隔離」方法有哪些:
超時:
這也是簡單的容錯方式。就是指在服務之間調用時,設置一個 主動超時時間,超過了這個時間閾值后,如果“被依賴的服務”還沒有返回數據的話,“調用者”就主動放棄,防止因“被依賴的服務”的故障所影響。
限流
顧名思義,就是限制最大流量。系統能提供的最大并發有限,同時來的請求又太多,服務不過來啊,就只好排隊限流了,就跟去景點排隊買票、去商場吃飯排隊等號的道理一樣一樣兒的。
降級
這個與限流類似,一樣是流量太多,系統服務不過來。這個時候可以可將不是那么重要的功能模塊進行降級處理,停止服務,這樣可以釋放出更多的資源供給核心功能的去用。同時還可以對用戶分層處理,優先處理重要用戶的請求,比如VIP收費用戶等。
延遲處理
這個方式是指設置一個流量緩沖池,所有的請求先進入這個緩沖池等待處理,真正的服務處理方按順序從這個緩沖池中取出請求依次處理,這種方式可以減輕后端服務的壓力,但是對用戶來說體驗上有延遲。
熔斷
可以理解成就像電閘的保險絲一樣,當流量過大或者錯誤率過大的時候,保險絲就熔斷了,鏈路就斷開了,不提供服務了。當流量恢復正常,或者后端服務穩定了,保險絲會自動街上(熔斷閉合),服務又可以正常提供了。這是一種很好的保護后端微服務的一種方式。
熔斷技術中有個很重要的概念就是:斷路器,可以參考下圖:
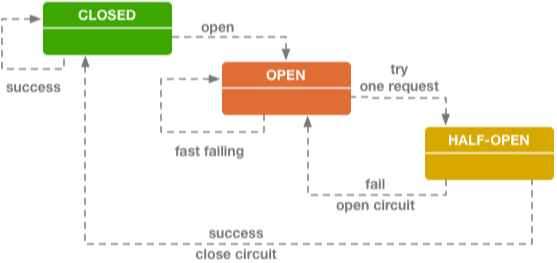
斷路器其實就是一個狀態機原理,有三種狀態:Closed(閉合狀態,也就是正常狀態)、Open(開啟狀態,也就是當后端服務出故障后鏈路斷開,不提供服務的狀態)、Half-Open(半閉合狀態,就是允許一小部分流量進行嘗試,嘗試后發現服務正常就轉為Closed狀態,服務依舊不正常就轉為Open狀態)。
三、「 容錯隔離 」的應用?
在容錯隔離或者說熔斷技術方面做得最出名的框架就是 Hystrix 了。Hystrix是由Netflix開源,在業內應用非常廣泛。
下面是Hystrix的原理流程圖:
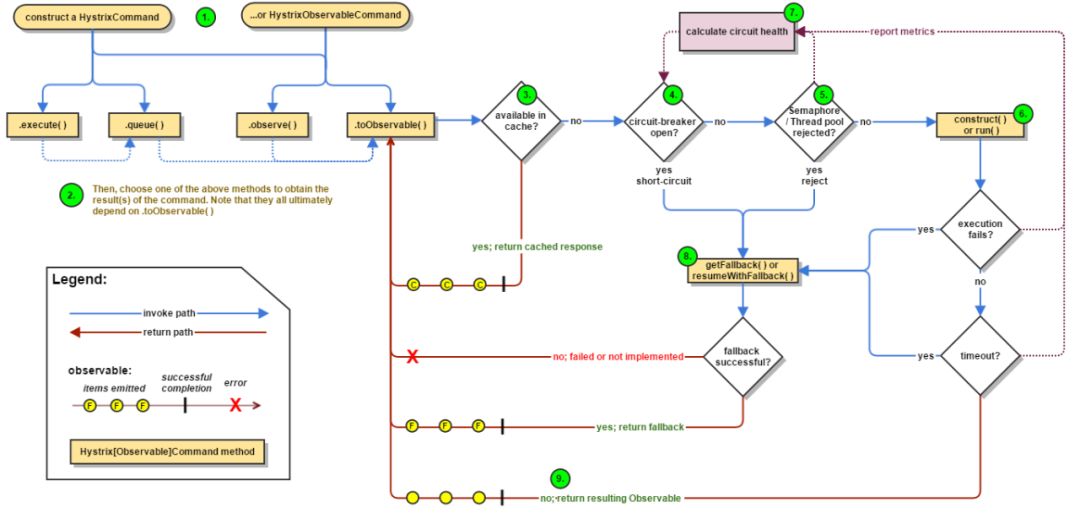
這是新版流程,比之前舊版本又復雜很多,如果不講解一下,估計很多人都不容易看懂。
圖中標注了數字1-9,可以按照這個數字順序去理解這個流程。
當我們使用了Hystrix之后,請求會被封裝到HystrixCommand中,這也就是第一步。然后第二步就是開始執行請求,Hystrix支持同步執行(圖中.execute方法)、異步執行(圖中.queue方法)和響應式執行(圖中.observer)。然后第三步判斷緩存,如果存在與緩存中,則直接返回緩存結果。如果不在緩存中,則走第四步,判斷 斷路器 的狀態是否是開啟的,如果是開啟狀態,也就是短路了,那就進行失敗返回,跳到第八步,第八步需要對失敗返回的處理也需要再做一次判斷,要么正常失敗返回,返回相應信息,要么根本沒有實現失敗返回的處理邏輯,就直接報錯。如果 斷路器 不是開啟狀態,那請求就繼續走,進行第五步,判斷線程/隊列是否滿了,如果滿了,那么同樣跳到第八步,如果線程沒滿,則走到第六步,執行遠程調用邏輯,然后判斷遠程調用是否成功,調用發生異常了就挑到第八步,調用正常就挑到第九步正常返回信息。
圖中的第七步,非常牛逼的一個模塊,是來收集Hystrix流程中的各種信息來對系統做監控判斷的。
另外,Hystrix的斷路器實現原理也很關鍵,下面就是Hystrix斷路器的原理圖:
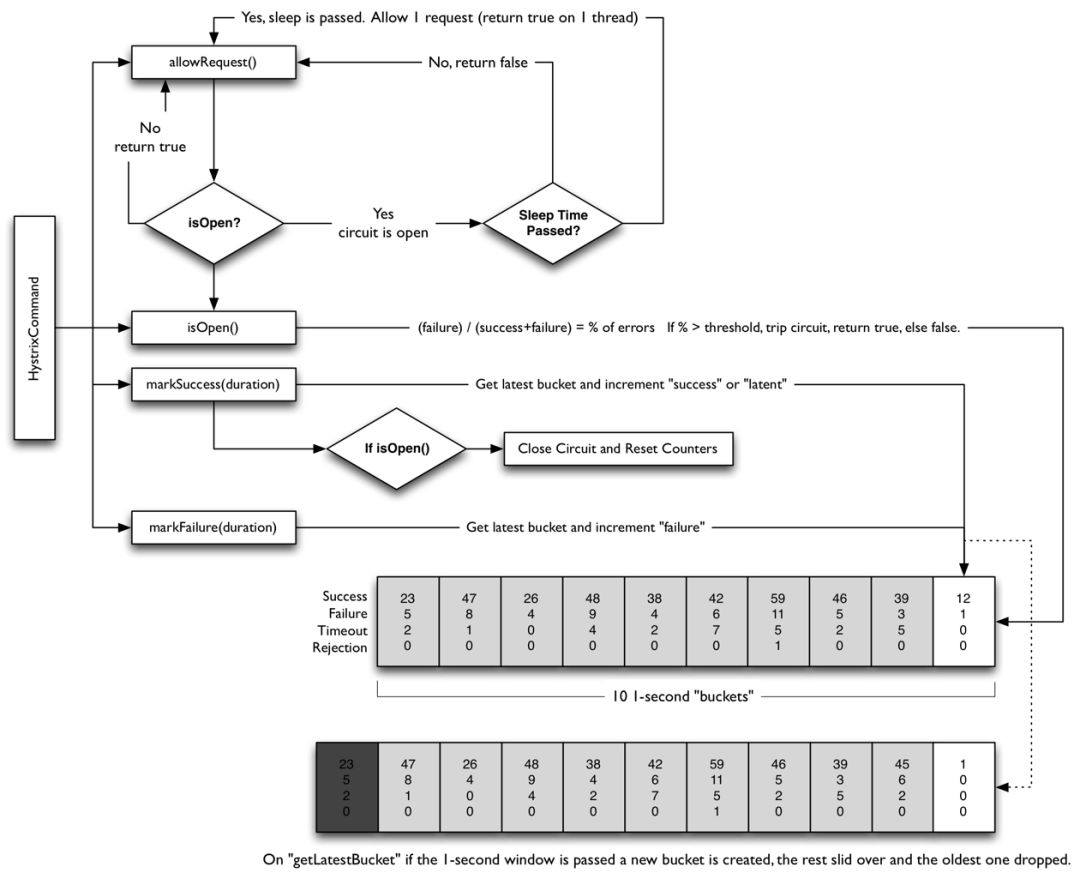
Hystrix通過滑動時間窗口算法來實現斷路器的,是以秒為單位的滑桶式統計,它總共包含10個桶,每秒鐘一個生成一個新的桶,往前推移,舊的桶就廢棄掉。
每一個桶中記錄了所有服務調用的狀態,調用次數、是否成功等信息,斷路器的開關就是把這10個桶進行聚合計算后,來判斷當前是應該開啟還是閉合的。
以上,就是對微服務架構中「容錯隔離」的一些思考。
-
保險絲
+關注
關注
4文章
583瀏覽量
44071 -
Linux
+關注
關注
87文章
11232瀏覽量
208949 -
斷路器
+關注
關注
23文章
1927瀏覽量
51634
原文標題:微服務架構之「 容錯隔離 」
文章出處:【微信號:LinuxHub,微信公眾號:Linux愛好者】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
微服務架構和CQRS架構基本概念介紹
微服務優勢_微服務架構的好處與不足
什么是微服務架構_微服務架構的優缺點及應用
微服務架構有哪些_微服務架構設計模式
微服務軟件架構應用研究綜述
什么是微服務架構?
springcloud微服務架構
設計微服務架構的原則






 工商網監
工商網監
評論