 視覺對話能力讓AI邁上新臺階
視覺對話能力讓AI邁上新臺階
正如《2001太空漫游》《流浪地球》等科幻大片中無障礙的人機對話系統所描繪的那樣,擁有智能視覺對話能力的AI隨著技術的不斷突破,正在向我們走來。
每個人都有這樣的回憶,小時候語文老師教我們看圖說話,許多小朋友腦洞大開,說出來的答案讓人啼笑皆非。實際上,看圖說話的能力在年幼時期需要訓練,而對于大一點孩子來說就不成問題了。如今,機器人也能做到看圖說話了。
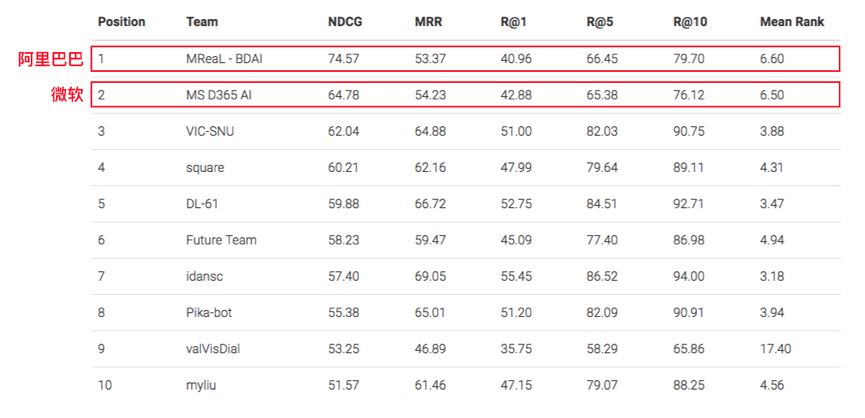
近日,來自中國AI在這項能力上已經打破了世界紀錄。在第二屆全球AI視覺對話競賽(Visual Dialogue Challenge)中,阿里AI擊敗了微軟、首爾大學等十支參賽隊伍,一舉獲得冠軍。
阿里AI在視覺對話競賽中得冠
會“看圖說話”的AI有多聰明?
這場視覺對話競賽由美國佐治亞理工大學、Facebook人工智能實驗室(FAIR)等機構聯合全球視覺技術領域頂級學術會議CVPR發起,是目前視覺對話領域最權威的競賽之一。
該競賽要求參賽的AI在看完近萬張圖片后,回答出人類對于任一圖片任一內容的提問。這要求AI不僅能夠描述出圖片中內容的概況,還要經得起人類對圖片各種細節的追問。比如,在一張撐著雨傘的人物圖片中,說出傘是什么顏色的,有多少人在圖中,附近有什么物品和建筑物等等信息。
視覺對話中AI可以從容應對人類提問(左為AI、右為人類)
競賽結果顯示,阿里AI以74.57%的準確率獲得冠軍,將上一屆比賽的紀錄提高了16.82%,并且超過微軟AI的64.78%的準確率。而在相同的數據集中,人類的準確率僅為64.27%,AI甚至勝過了人類。
傳統的視覺AI主要針對目標的檢測和識別,但對復雜場景中目標之間的邏輯關系理解、推理能力較弱,無法回答表達圖片對象直接關系的復雜問題,也難以將圖片信息轉化為人類理解的語言輸出。
這意味著,要實現視覺對話能力,傳統的視覺AI在學會“看圖”之后,還要有一種語言模型來支撐它“說話”。阿里AI的突破就在于提出了“遞歸探索對話模型”。
視覺對話AI與用戶交流圖像內容
這一模型通過標注信息學習出模仿人類認知復雜場景的思維方式,能識別圖片里的實體以及它們之間的關系,推理出圖片所描述的事件內容,并通過對上下文進行有效建模,綜合集成了圖像識別、關系推理與自然語言理解三大能力,能理解人類提出的問題及真實意圖,給出自然準確的回復。
視覺對話能力讓AI邁上新臺階
AI能“看圖說話”,這樣的應用其實距離我們并不遙遠,微軟之前推出了一款年齡測試工具How-old.net ,曾經刷爆微博和朋友圈,所應用的就是這一技術的應用。
目前微軟還開放了能“看圖說話”的AI系統,用戶進入官網上傳圖片,稍等一會,就能看到系統對于圖片的描述。其準確率雖然不低但依舊有待提升,以一張曾經廣為流傳的黑人問號表情圖片為例,AI很快給出了客觀的回答:“我覺得這是籃球隊員尼克·楊露出牙齒微笑。”
AI視覺對話識別圖片信息
以“看圖說話”為代表的視覺對話是近年來快速崛起的AI研究方向,目的在于教會機器用自然語言與人類討論視覺內容,這能夠使機器擁有了對真實視覺世界的理解與推斷能力,也意味著AI的認知能力將邁上新的臺階。
可以預見,這項技術未來將被應用在人機交互諸多場景:
在火災、地震后在廢墟中尋找幸存者的救援機器人,能夠代替人類之眼,深入危險的現場,及時、高效地綜合指揮指令和場景信息作出行動。
視覺對話技術有望人類提高地震救援效率
視障人士可以通過提問AI,理解圖像中的內容,了解自身所處的周圍環境,為其生活起居帶來更多的便利。
無人駕駛車輛也可以在行駛中通過視覺對話,更加準確理解人類意圖征詢人類的意見,讓乘客的乘坐體驗更好。
正如《2001太空漫游》《流浪地球》等科幻大片中無障礙的人機對話系統所描繪的那樣,擁有智能視覺對話能力的AI隨著技術的不斷突破,正在向我們走來。
-
機器視覺
+關注
關注
161文章
4347瀏覽量
120126 -
AI
+關注
關注
87文章
30227瀏覽量
268465
原文標題:機器人看圖說話能力比肩人類!中國AI超越微軟,打破世界紀錄
文章出處:【微信號:jingzhenglizixun,微信公眾號:機器人博覽】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
AI對話魔法 Prompt Engineering 探索指南

中科曙光推動液冷技術產業加速落地
對話藍牙技術聯盟首席執行官Neville Meijers
消息稱蘋果正在洽談投資OpenAI
AWS與Workday深化合作,推進生成式AI功能開發
納宏光電榮獲ISO9001:2015質量管理體系認證及IATF16949:2016車規質量體系認證,品質管理再上新臺階

聆思CSK6視覺語音大模型AI開發板入門資源合集(硬件資料、大模型語音/多模態交互/英語評測SDK合集)
【AIBOX快速入門】2步玩轉AI對話

臺階儀測量膜厚怎么測

華為助力電信安全公司和江蘇電信實現DDoS攻擊“閃防”能力

和芯星通獲ISO14001環境管理和ISO45001職業健康安全管理體系認證






 工商網監
工商網監
評論