") 從8小時(shí)到80秒,NVIDIA如何實(shí)現(xiàn)AI訓(xùn)練用時(shí)大突破?
從8小時(shí)到80秒,NVIDIA如何實(shí)現(xiàn)AI訓(xùn)練用時(shí)大突破?
“天下武功,唯快不破”,你需要以“快”制勝。
如今,全球頂級(jí)公司的研究人員和數(shù)據(jù)科學(xué)家團(tuán)隊(duì)們都在致力于創(chuàng)建更為復(fù)雜的AI模型。但是,AI模型的創(chuàng)建工作不僅僅是設(shè)計(jì)模型,還需要對(duì)模型進(jìn)行快速地訓(xùn)練。
這就是為什么說,如果想在AI領(lǐng)域保持領(lǐng)導(dǎo)力,就首先需要有賴于AI基礎(chǔ)設(shè)施的領(lǐng)導(dǎo)力。而這也正解釋了為什么MLPerf AI訓(xùn)練結(jié)果如此之重要。
通過完成全部6項(xiàng)MLPerf基準(zhǔn)測(cè)試,NVIDIA展現(xiàn)出了全球一流的性能表現(xiàn)和多功能性。NVIDIA AI平臺(tái)在訓(xùn)練性能方面創(chuàng)下了八項(xiàng)記錄,其中包括三項(xiàng)大規(guī)模整體性能紀(jì)錄和五項(xiàng)基于每個(gè)加速器的性能紀(jì)錄。
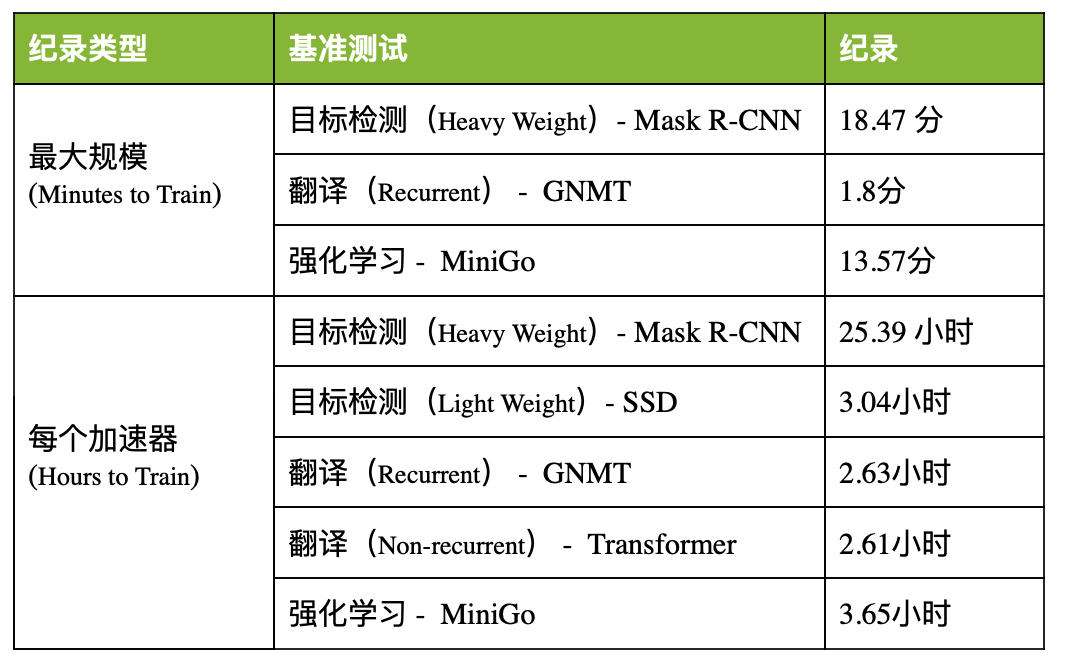
表1:NVIDIA MLPerf AI紀(jì)錄
每個(gè)加速器的比較基于早前報(bào)告的基于單一NVIDIA DGX-2H(16個(gè)V100 GPU)、與其他同規(guī)模相比較的MLPerf 0.6的性能(除MiniGo采用的是基于8個(gè)V100 GPU的NVIDIA DGX-1)|最大規(guī)模MLPerf ID:Mask R-CNN:0.6-23,GNMT:0.6-26,MiniGo:0.6-11 |每加速器MLPerf ID:Mask R-CNN,SSD,GNMT,Transformer:全部使用0.6-20,MiniGo:0.6-10
以上測(cè)試結(jié)果數(shù)據(jù)由谷歌、英特爾、百度、NVIDIA、以及創(chuàng)建MLPerf AI基準(zhǔn)測(cè)試的其他數(shù)十家頂級(jí)技術(shù)公司和大學(xué)提供背書,能夠轉(zhuǎn)化為具有重要意義的創(chuàng)新。
簡(jiǎn)而言之,NVIDIA的AI平臺(tái)如今能夠在不到兩分鐘的時(shí)間內(nèi)完成此前需要一個(gè)工作日才能完成的模型訓(xùn)練。
各公司都知道,釋放生產(chǎn)力是一件重中之重的要?jiǎng)?wù)。超級(jí)計(jì)算機(jī)如今已經(jīng)成為了AI的必備工具,樹立AI領(lǐng)域的領(lǐng)導(dǎo)力首先需要強(qiáng)大的AI計(jì)算基礎(chǔ)設(shè)施支持。
NVIDIA最新的MLPerf結(jié)果很好地展示了將NVIDIA V100 Tensor核心GPU應(yīng)用于超算級(jí)基礎(chǔ)設(shè)施中所能帶來的益處。
在2017年春季的時(shí)候,使用搭載了V100 GPU的NVIDIA DGX-1系統(tǒng)訓(xùn)練圖像識(shí)別模型ResNet-50,需要花費(fèi)整整一個(gè)工作日(8小時(shí))的時(shí)間。
而如今,同樣的任務(wù),NVIDIA DGX SuperPOD使用相同的V100 GPU,采用Mellanox InfiniBand進(jìn)行互聯(lián),并借助可用于分布式AI訓(xùn)練的最新NVIDIA優(yōu)化型AI軟件,僅需80秒即可完成。
80秒的時(shí)間,甚至都不夠用來沖一杯咖啡。
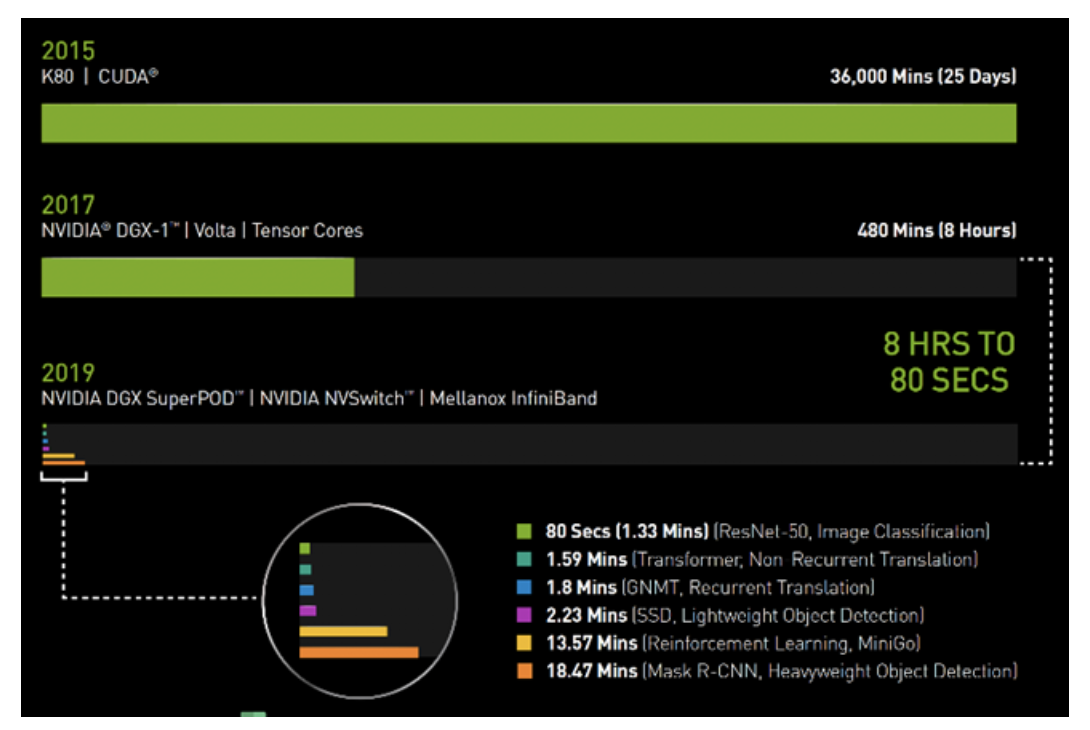
圖1:AI時(shí)間機(jī)器
2019年MLPerf ID(按圖表從上到下的順序):ResNet-50:0.6-30 | Transformer:0.6-28 | GNMT:0.6-14 | SSD:0.6-27 | MiniGo:0.6-11 | Mask R-CNN:0
AI的必備工具:DGX SuperPOD能夠更快速地完成工作負(fù)載
仔細(xì)觀察今日的MLPerf結(jié)果,會(huì)發(fā)現(xiàn)NVIDIA DGX SuperPOD是唯一在所有六個(gè)MLPerf類別中耗時(shí)都少于20分鐘的AI平臺(tái):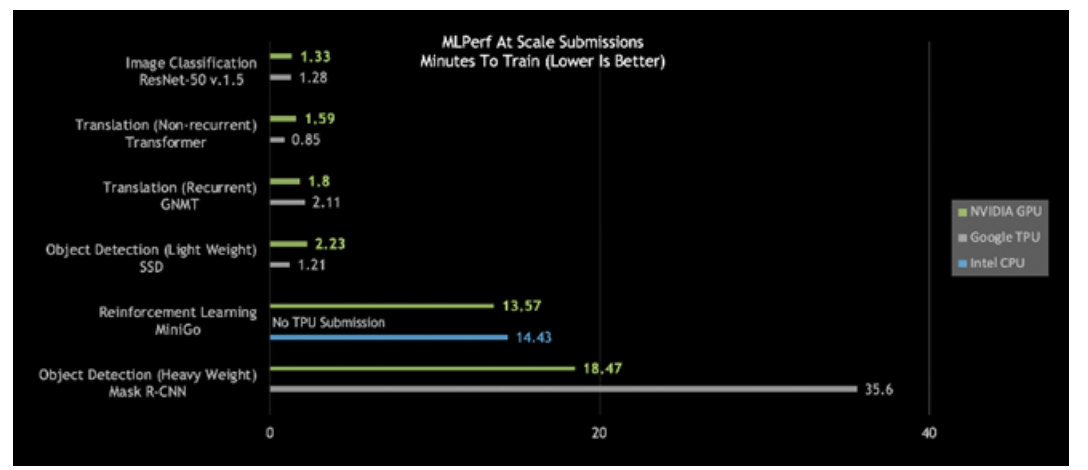 ?
?圖2:DGX SuperPOD打破大規(guī)模AI紀(jì)錄
大規(guī)模MLPerf 0.6性能|大規(guī)模MLPerf ID:RN50 v1.5:0.6-30,0.6-6 | Transformer:0.6-28,0.6-6 | GNMT:0.6-26,0.6-5 | SSD:0.6-27,0.6-6 | MiniGo:0.6-11,0.6-7 | Mask R-CNN:0.6-23,0.6-3
更進(jìn)一步觀察會(huì)發(fā)現(xiàn),針對(duì)重量級(jí)目標(biāo)檢測(cè)和強(qiáng)化學(xué)習(xí),這些最困難的AI問題,NVIDIA AI平臺(tái)在總體訓(xùn)練時(shí)間方面脫穎而出。
使用Mask R-CNN深度神經(jīng)網(wǎng)絡(luò)的重量級(jí)目標(biāo)檢測(cè)可為用戶提供高級(jí)實(shí)例分割。其用途包括將其與多個(gè)數(shù)據(jù)源(攝像頭、傳感器、激光雷達(dá)、超聲波等)相結(jié)合,以精確識(shí)別并定位特定目標(biāo)。
這類AI工作負(fù)載有助于訓(xùn)練自動(dòng)駕駛汽車,為其提供行人和其他目標(biāo)的精確位置。另外,在醫(yī)療健康領(lǐng)域,它能夠幫助醫(yī)生在醫(yī)療掃描中查找并識(shí)別腫瘤。其意義的重要性非同小可。
NVIDIA的“重量級(jí)目標(biāo)檢測(cè)”用時(shí)不到19分鐘,性能幾乎是第二名的兩倍。
強(qiáng)化學(xué)習(xí)是另一有難度的類別。這種AI方法能夠用于訓(xùn)練工廠車間機(jī)器人,以簡(jiǎn)化生產(chǎn)。城市也可以用這種方式來控制交通燈,以減少擁堵。NVIDIA采用NVIDIA DGX SuperPOD,在創(chuàng)紀(jì)錄的13.57分鐘內(nèi)完成了對(duì)MiniGo AI強(qiáng)化訓(xùn)練模型的訓(xùn)練。
咖啡還沒好,任務(wù)已完成:即時(shí)AI基礎(chǔ)設(shè)施提供全球領(lǐng)先性能
打破基準(zhǔn)測(cè)試紀(jì)錄不是目的,加速創(chuàng)新才是目標(biāo)。這就是為什么NVIDIA構(gòu)建的DGX SuperPOD不僅性能強(qiáng)大,而且易于部署。DGX SuperPOD全面配置了可通過NGC容器注冊(cè)表免費(fèi)獲取的優(yōu)化型CUDA-X AI軟件,可提供開箱即用的全球領(lǐng)先AI性能。
在這個(gè)由130多萬名CUDA開發(fā)者組成的生態(tài)系統(tǒng)中,NVIDIA與開發(fā)者們合作,致力于為所有AI框架和開發(fā)環(huán)境提供有力支持。
我們已經(jīng)助力優(yōu)化了數(shù)百萬行代碼,讓我們的客戶能夠?qū)⑵銩I項(xiàng)目落地,無論您身在何處都可以找到NVIDIA GPU,無論是在云端,還是在數(shù)據(jù)中心,亦或是邊緣。
AI基礎(chǔ)設(shè)施如今有夠快,未來會(huì)更快
更好的一點(diǎn)在于,這一平臺(tái)的速度一直在提升。NVIDIA每月都會(huì)發(fā)布CUDA-X AI軟件的新優(yōu)化和性能改進(jìn),集成型軟件堆棧可在NGC容器注冊(cè)表中免費(fèi)下載,包括容器化的框架、預(yù)先訓(xùn)練好的模型和腳本。借助在CUDA-X AI軟件堆棧上的創(chuàng)新,NVIDIA DGX-2H服務(wù)器的MLPerf 0.6吞吐量比NVIDIA七個(gè)月前發(fā)布的結(jié)果提升了80%。
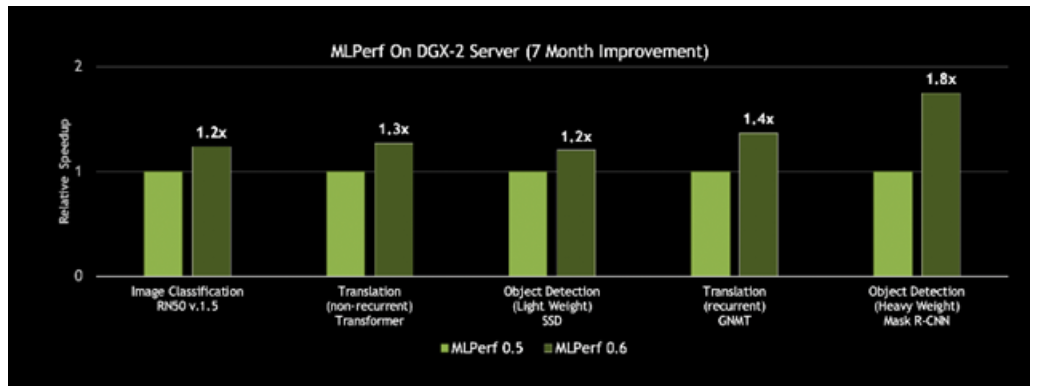
圖3:基于同一服務(wù)器,性能提升高達(dá)80%
對(duì)單個(gè)歷元上單一DGX-2H服務(wù)器的吞吐量進(jìn)行比較(數(shù)據(jù)集單次通過神經(jīng)網(wǎng)絡(luò))| MLPerf ID 0.5 / 0.6比較:ResNet-50 v1.5: 0.5-20/0.6-30 | Transformer: 0.5-21/0.6-20 | SSD: 0.5-21/0.6-20 | GNMT: 0.5-19/0.6-20 | Mask R-CNN: 0.5-21/0.6-20
聲明:本文內(nèi)容及配圖由入駐作者撰寫或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點(diǎn)僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場(chǎng)。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問題,請(qǐng)聯(lián)系本站處理。
舉報(bào)投訴
-
AI
+關(guān)注
關(guān)注
87文章
30172瀏覽量
268431 -
MLPerf基準(zhǔn)測(cè)試
+關(guān)注
關(guān)注
0文章
1瀏覽量
1072 -
模型訓(xùn)練
+關(guān)注
關(guān)注
0文章
18瀏覽量
1331
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
《算力芯片 高性能 CPUGPUNPU 微架構(gòu)分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
標(biāo)量、向量、矩陣的表示;從硬件實(shí)現(xiàn)看,不同廠商各顯神通。谷歌TPU采用脈動(dòng)陣列計(jì)算單元,通過數(shù)據(jù)流向的精心編排提升計(jì)算密度;NVIDIA張量核心支持多精度計(jì)算,Hopper架構(gòu)更是引入了稀疏性加速。華為
發(fā)表于 11-24 17:12
全新NVIDIA NIM微服務(wù)實(shí)現(xiàn)突破性進(jìn)展
全新 NVIDIA NIM 微服務(wù)實(shí)現(xiàn)突破性進(jìn)展,可助力氣象技術(shù)公司開發(fā)和部署 AI 模型,實(shí)現(xiàn)對(duì)降雪、結(jié)冰和冰雹的預(yù)測(cè)。
NVIDIA AI助力實(shí)現(xiàn)更好的癌癥檢測(cè)
由美國(guó)頂級(jí)醫(yī)療中心和研究機(jī)構(gòu)的專家組成了一個(gè)專家委員會(huì),該委員會(huì)正在使用 NVIDIA 支持的聯(lián)邦學(xué)習(xí)來評(píng)估聯(lián)邦學(xué)習(xí)和 AI 輔助注釋對(duì)訓(xùn)練 AI 腫瘤分割模型的影響。
NVIDIA助力麗蟾科技打造AI訓(xùn)練與推理加速解決方案
麗蟾科技通過 Leaper 資源管理平臺(tái)集成 NVIDIA AI Enterprise,為企業(yè)和科研機(jī)構(gòu)提供了一套高效、靈活的 AI 訓(xùn)練與推理加速解決方案。無論是在復(fù)雜的

端到端InfiniBand網(wǎng)絡(luò)解決LLM訓(xùn)練瓶頸
ChatGPT對(duì)技術(shù)的影響引發(fā)了對(duì)人工智能未來的預(yù)測(cè),尤其是多模態(tài)技術(shù)的關(guān)注。OpenAI推出了具有突破性的多模態(tài)模型GPT-4,使各個(gè)領(lǐng)域取得了顯著的發(fā)展。 這些AI進(jìn)步是通過大規(guī)模模型訓(xùn)練

NVIDIA Nemotron-4 340B模型幫助開發(fā)者生成合成訓(xùn)練數(shù)據(jù)
Nemotron-4 340B 是針對(duì) NVIDIA NeMo 和 NVIDIA TensorRT-LLM 優(yōu)化的模型系列,該系列包含最先進(jìn)的指導(dǎo)和獎(jiǎng)勵(lì)模型,以及一個(gè)用于生成式 AI 訓(xùn)練

NVIDIA AI Foundry 為全球企業(yè)打造自定義 Llama 3.1 生成式 AI 模型
Foundry 提供從數(shù)據(jù)策管、合成數(shù)據(jù)生成、微調(diào)、檢索、防護(hù)到評(píng)估的全方位生成式 AI 模型服務(wù),以便部署自定義 Llama 3.1 NVIDIA NIM 微服務(wù)和新的
發(fā)表于 07-24 09:39
?681次閱讀

AI訓(xùn)練的基本步驟
AI(人工智能)訓(xùn)練是一個(gè)復(fù)雜且系統(tǒng)的過程,它涵蓋了從數(shù)據(jù)收集到模型部署的多個(gè)關(guān)鍵步驟。以下是對(duì)AI訓(xùn)練
NVIDIA為新工業(yè)革命打造 AI 工廠和數(shù)據(jù)中心
領(lǐng)先的計(jì)算機(jī)制造商推出一系列?Blackwell 賦能的系統(tǒng),搭載 Grace CPU、NVIDIA 網(wǎng)絡(luò)和基礎(chǔ)設(shè)施 豐富的產(chǎn)品組合覆蓋云、專用系統(tǒng)、嵌入式和邊緣 AI 系統(tǒng)等 產(chǎn)品配置豐富,從單
進(jìn)一步解讀英偉達(dá) Blackwell 架構(gòu)、NVlink及GB200 超級(jí)芯片
NVIDIA NVLink,支持 FP4 AI 精度。
GB200 NVL72是一款性能卓越的計(jì)算平臺(tái),采用更快的第二代Transformer引擎和FP8精度,可將大型語言模型的訓(xùn)練速
發(fā)表于 05-13 17:16
NVIDIA將數(shù)字孿生與實(shí)時(shí)AI結(jié)合實(shí)現(xiàn)工業(yè)自動(dòng)化
NVIDIA 軟件(Omniverse、Metropolis、Isaac 和 cuOpt)共同打造了一個(gè) AI Gym,讓機(jī)器人和 AI 智能體能夠在復(fù)雜的工業(yè)領(lǐng)域中進(jìn)行訓(xùn)練并接受評(píng)估

NVIDIA生成式AI研究實(shí)現(xiàn)在1秒內(nèi)生成3D形狀
NVIDIA 研究人員使 LATTE3D (一款最新文本轉(zhuǎn) 3D 生成式 AI 模型)實(shí)現(xiàn)雙倍加速。

基于NVIDIA Megatron Core的MOE LLM實(shí)現(xiàn)和訓(xùn)練優(yōu)化
本文將分享阿里云人工智能平臺(tái) PAI 團(tuán)隊(duì)與 NVIDIA Megatron-Core 團(tuán)隊(duì)在 MoE (Mixture of Experts) 大語言模型(LLM)實(shí)現(xiàn)與訓(xùn)練優(yōu)化上的創(chuàng)新工作。

NVIDIA 人工智能開講 | 什么是 AI For Science?詳解 AI 助力科學(xué)研究領(lǐng)域的新突破
”兩大音頻 APP上搜索“ NVIDIA 人工智能開講 ”專輯,眾多技術(shù)大咖帶你深度剖析核心技術(shù),把脈未來科技發(fā)展方向! AI For Science (亦稱 “AI In Science” ),是人工智能領(lǐng)域的一大熱門話題,

NVIDIA 為部分大型亞馬遜 Titan 基礎(chǔ)模型提供訓(xùn)練支持
GPU 和海量的數(shù)據(jù)集上所訓(xùn)練而成。 不過這可能會(huì)給想要使用生成式 AI 的企業(yè)帶來很多巨大的挑戰(zhàn)。 NVIDIA NeMo (一個(gè)用于構(gòu)建、自定義和運(yùn)行 LLM 的框架)能夠幫助企業(yè)克服上述挑戰(zhàn)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論