 太秀了!DeepMind推出最強表示學習模型BigBiGAN
太秀了!DeepMind推出最強表示學習模型BigBiGAN
今天,DeepMind爆出一篇重磅論文,引發學術圈熱烈反響:基于最強圖像生成器BigGAN,打造了BigBiGAN,在無監督表示學習和圖像生成方面均實現了最先進的性能!Ian Goodfellow也稱贊“太酷了!”
GAN在圖像合成方面一次次讓人們驚嘆不已!
例如,被稱為史上最強圖像生成器的BigGAN——許多人看到BigGAN生成的圖像都要感嘆“太逼真了!DeepMind太秀了吧!”
BigGAN生成的逼真圖像
這不是最秀的。今天,DeepMind的一篇新論文再次引發學術圈熱烈反響,論文題為《大規模對抗性表示學習》。
論文鏈接:
https://arxiv.org/pdf/1907.02544.pdf
在這篇論文中,DeepMind基于最先進的BigGAN模型構建了BigBiGAN模型,通過添加編碼器和修改鑒別器將其擴展到表示學習。
BigBiGAN表明,“圖像生成質量的進步轉化為了表示學習性能的顯著提高”。
研究人員廣泛評估了BigBiGAN模型的表示學習和生成性能,證明這些基于生成的模型在ImageNet上的無監督表示學習和無條件圖像生成方面都達到了state of the art的水平。
這篇論文在Twitter上引發很大反響。GAN發明人Ian Goodfellow說:“很有趣,又回到了表示學習。我讀PhD期間,我和大多數合作者都對作為樣本生成的副產品的表示學習很感興趣,而不是樣本生成本身。”
Goodfellow說:“當年我們在寫最初的GAN論文時,我的合著者@dwf(David Warde-Farley)試圖得到一些類似于BiGAN的東西,用于表示學習。5年后看到這一成果,我覺得太酷了。”
Andrej Karpathy也說:“無監督/自監督學習是一個非常豐富的領域,它將消除目前對大規模數據集的必要性.”
總結而言,這篇論文展示了GAN可以用于無監督表示學習,并在ImageNet上獲得了最先進的結果。
下面是BigBiGAN生成的一些重建樣本,可以看到,重建是傾向于強調高級語義,而不是像素級的細節。
下面,新智元帶來對這篇論文的詳細解讀。
基于BigGAN打造BigBiGAN:學習高級語義,而非細節
近年來,我們已經看到視覺數據生成模型的快速發展。雖然這些模型以前局限于模式單一或少模式、結構簡單、分辨率低的領域,但隨著建模和硬件的進步,它們已經獲得了令人信服地生成復雜、多模態、高分辨率圖像分布的能力。
直觀地說,在特定域中生成數據的能力需要高度理解所述域的語義。這一想法長期以來頗具吸引力,因為原始數據既便宜——可以從互聯網等來源獲得幾乎無限的供應——又豐富,圖像包含的信息遠遠超過典型的機器學習模型訓練用來預測的類別標簽。
然而,盡管生成模型取得的進展不可否認,但仍然存在一些令人困擾的問題:這些模型學到了什么語義,以及如何利用它們進行表示學習?
僅憑原始數據就能真正理解生成這個夢想幾乎不可能實現。相反,最成功的無監督學習方法利用了監督學習領域的技術,這是一種被稱為自監督學習(self-supervised learnin)的方法。
這些方法通常涉及以某種方式更改或保留數據的某些方面,并訓練模型來預測或生成缺失信息的某些方面。
例如,Richard Zhang等人的研究(CVPR 2016)提出了一種非監督學習的圖像著色方法,在這種方法中,模型被給予輸入圖像中顏色通道的子集,并經過訓練來預測缺失的通道。
作為無監督學習手段的生成模型為self-supervised的任務提供了一個很有吸引力的替代方案,因為它們經過訓練,可以對整個數據分布建模,而不需要修改原始數據。
GAN是一類應用于表示學習的生成模型。GAN框架中的生成器是一個從隨機采樣的潛在變量(也稱為“噪聲”)到生成數據的前饋映射,其中學習信號由經過訓練的鑒別器提供,用來區分真實數據和生成的數據樣本,引導生成器的輸出跟隨數據分布。
作為GAN框架的擴展,Vincent Dumoulin等人(ICLR 2017)提出adversarially learned inference(ALI)[7],或Jeff Donahue等人(ICLR 2017)提出bidirectional GAN (BiGAN)[4]方法,這些方法通過編碼器模塊將實際數據映射到潛在數據(與生成器學習的映射相反)來增強標準GAN。
在最優判別器的極限下,[4]論文表明確定性BiGAN的行為類似于自編碼器,最大限度地降低了重建成本l?;然而,重建誤差曲面的形狀是由參數鑒別器決定的,而不是像誤差l?這樣的簡單像素級度量。
由于鑒別器通常是一個功能強大的神經網絡,我們希望它能產生一個誤差曲面,在重建時強調“語義”誤差,而不是強調低層次的細節。
BigBiGAN重建的更多圖像
論文證明了通過BiGAN或ALI框架學習的編碼器是在ImageNet上學習下游任務的一種有效的視覺表示方法。然而,它使用了DCGAN風格的生成器,無法在這個數據集上生成高質量的圖像,因此編碼器能夠建模的語義也相當有限。
在這項工作中,我們再次使用BigGAN作為生成器,這是一個能夠捕獲ImageNet圖像中的許多模式和結構的先進模型。我們的貢獻如下:
我們證明了BigBiGAN (BiGAN with BigGAN generator)與ImageNet上無監督表示學習的最先進技術相匹敵。
我們為BigBiGAN提出了一個更穩定的聯合鑒別器。
我們對模型設計選擇進行了全面的實證分析和消融研究。
我們證明,表示學習目標還有助于無條件生成圖像,并展示了無條件生成ImageNet的最先進結果。
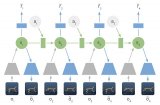
BigBiGAN框架的結構
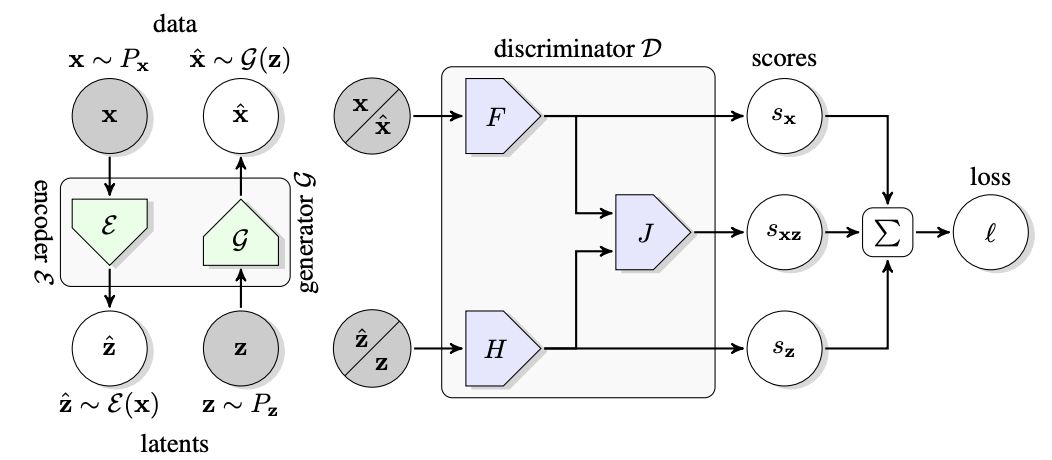
BigBiGAN框架的結構
BigBiGAN框架的結構如上圖所示。
聯合判別器D用于計算損失l。其輸入是data-latent pairs,可以是從數據分布 和編碼器
和編碼器 輸出采樣的
輸出采樣的 ,或從生成器G輸入和潛在分布
,或從生成器G輸入和潛在分布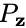 采樣的?
采樣的? 。損失l包括一元數據項
。損失l包括一元數據項 和一元潛在項,以及將數據和潛在分布聯系起來的共同項。
和一元潛在項,以及將數據和潛在分布聯系起來的共同項。
評估和結果:表示學習、圖像生成實現最優性能
表示學習
我們現在從上述簡化學習結果中獲取基于train-val分類精度的最優模型,在官方ImageNet驗證集上得出結果,并與最近的無監督學習研究文獻中的現有技術水平進行比較。
為了進行這些比較,我們還提供了基于規模較小的ResNet-50的最佳性能GAN變種的分類結果。詳細比較結果在表2中給出。
與當前許多自監督學習方法相比,本文中采用的純基于生成模型的BigBiGAN方法在表示學習方面表現良好,在最近的無監督學習任務上的表現達到了SOTA 水平,最近公布的結果顯示,本文中的方法在使用表2的AvePool相同的表示學習架構和特征的旋轉預測預訓練任務中,將top-1精度由55.4%提高到60.8%。

表1:多個BigBiGAN變體的性能結果,在生成圖像的初始分數(IS)和Fréchet初始距離(FID),監督式邏輯回歸分類器ImageNet top-1精度百分比(Cls。)由編碼器特征訓練,并基于從訓練集中隨機抽樣的10K圖像進行分割計算,我們將其稱為“train-val”分割。
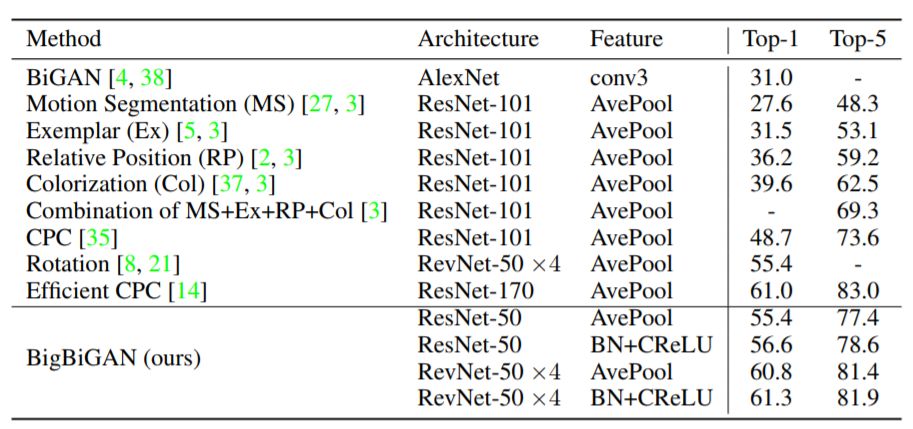
表2:在官方ImageNet驗證集上對BigBiGAN模型與最近的基于監督式邏輯回歸分類器的其他方法的對比。

表3:我們的BigBiGAN與無監督(無條件)生成方法、以及之前報告的無監督BigGAN的性能結果對比。
無監督式圖像生成
表3所示為BigBiGAN進行無監督生成的結果,與基于BigGAN的無監督生成結果做比較。請注意,這些結果與表1中的結果不同,因為使用的是數據增強方法(而非表1中的用于所有結果的ResNet樣式預處理方法)。
這些結果表明,BigBiGAN顯著提升了以IS和FID為量度的基線無條件BigGAN生成結果的性能。
圖2:從無監督的BigBiGAN模型中選擇的圖像重建結果。上面一行的圖像是真實圖像(x~Px),下面一行圖像是由G(E(x))計算出的這些圖像的重建結果。與大多數顯式重建成本(例如像素數量)不同,由(Big)BiGAN 實現隱式最小化的重建成本更多傾向于強調圖像的語義及其他更高級的細節。
圖像重建:更偏重高級語義,而非像素細節
圖2中所示的圖像重建在像素上遠達不到完美,可能部分原因是目標沒有明確強制執行重建成本,在訓練時甚至對重建模型進行計算。然而,它們可以為編碼器ε學習建模的特征提供一些幫助。
比如,當輸入圖像中包含狗、人或食物時,重建結果通常是姿勢、位置和紋理等相同特征“類別”的不同實例。例如,臉朝同一方向的另一只類似的狗。重建結果傾向于保留輸入的高級語義,而不是低級細節,這表明BigBiGAN的訓練在鼓勵編碼器對前者進行建模,而不是后者。
-
編碼器
+關注
關注
45文章
3595瀏覽量
134158 -
圖像
+關注
關注
2文章
1083瀏覽量
40418 -
DeepMind
+關注
關注
0文章
129瀏覽量
10819
原文標題:DeepMind爆出無監督表示學習模型BigBiGAN,GAN之父點贊!
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
大語言模型:原理與工程時間+小白初識大語言模型
未來的AI 深挖谷歌 DeepMind 和它背后的技術
機器學習如何賦能風力發電?DeepMind 做了以下嘗試 精選資料推薦
太秀了!小學生都開始學習華為鴻蒙了?
基于邊采樣的網絡表示學習模型
DeepMind攜手Unity,加速機器學習和人工智能研究
谷歌、DeepMind重磅推出PlaNet 強化學習新突破
BigBiGAN問世,“GAN父”都說酷的無監督表示學習模型有多優秀?
谷歌和DeepMind研究人員合作提出新的強化學習方法Dreamer 可利用世界模型實現高效的行為學習
語言模型做先驗,統一強化學習智能體,DeepMind選擇走這條通用AI之路

谷歌DeepMind發布機器人大模型RT-2,提高泛化與涌現能力

再登Nature!DeepMind大模型突破60年數學難題,解法超出人類已有認知






 工商網監
工商網監
評論