") XGBoost原理概述 XGBoost和GBDT的區(qū)別
XGBoost原理概述 XGBoost和GBDT的區(qū)別
作者 |梁云1991
一、XGBoost和GBDT
xgboost是一種集成學(xué)習(xí)算法,屬于3類常用的集成方法(bagging,boosting,stacking)中的boosting算法類別。它是一個(gè)加法模型,基模型一般選擇樹模型,但也可以選擇其它類型的模型如邏輯回歸等。
xgboost屬于梯度提升樹(GBDT)模型這個(gè)范疇,GBDT的基本想法是讓新的基模型(GBDT以CART分類回歸樹為基模型)去擬合前面模型的偏差,從而不斷將加法模型的偏差降低。相比于經(jīng)典的GBDT,xgboost做了一些改進(jìn),從而在效果和性能上有明顯的提升(劃重點(diǎn)面試常考)。第一,GBDT將目標(biāo)函數(shù)泰勒展開到一階,而xgboost將目標(biāo)函數(shù)泰勒展開到了二階。保留了更多有關(guān)目標(biāo)函數(shù)的信息,對提升效果有幫助。第二,GBDT是給新的基模型尋找新的擬合標(biāo)簽(前面加法模型的負(fù)梯度),而xgboost是給新的基模型尋找新的目標(biāo)函數(shù)(目標(biāo)函數(shù)關(guān)于新的基模型的二階泰勒展開)。第三,xgboost加入了和葉子權(quán)重的L2正則化項(xiàng),因而有利于模型獲得更低的方差。第四,xgboost增加了自動(dòng)處理缺失值特征的策略。通過把帶缺失值樣本分別劃分到左子樹或者右子樹,比較兩種方案下目標(biāo)函數(shù)的優(yōu)劣,從而自動(dòng)對有缺失值的樣本進(jìn)行劃分,無需對缺失特征進(jìn)行填充預(yù)處理。
此外,xgboost還支持候選分位點(diǎn)切割,特征并行等,可以提升性能。
二、XGBoost原理概述
下面從假設(shè)空間,目標(biāo)函數(shù),優(yōu)化算法3個(gè)角度對xgboost的原理進(jìn)行概括性的介紹。
1,假設(shè)空間
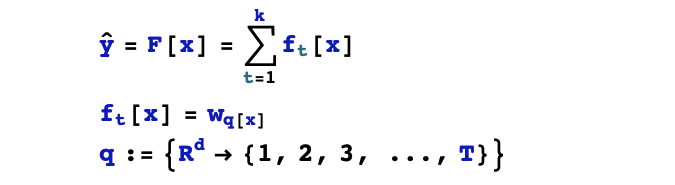
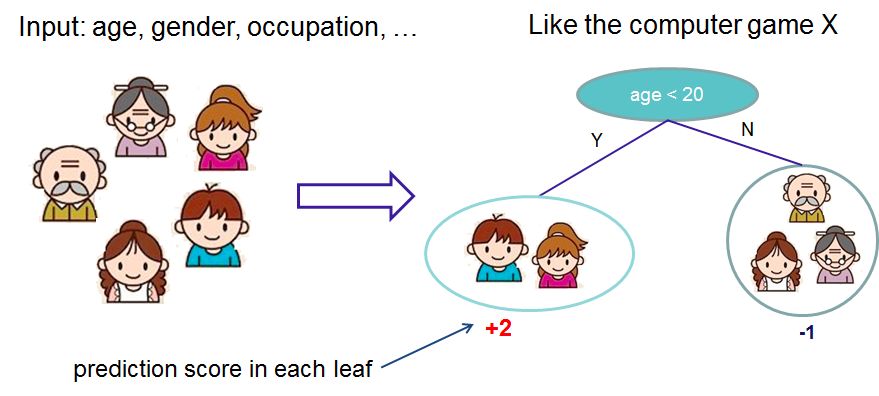
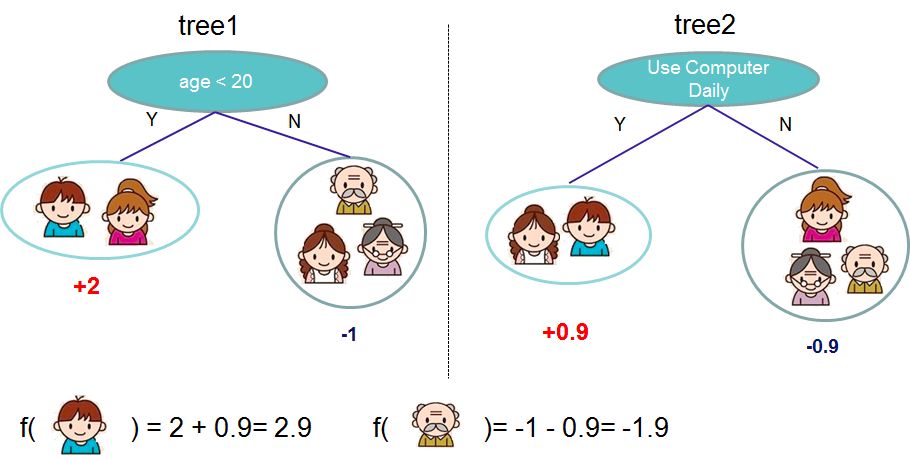
2,目標(biāo)函數(shù)

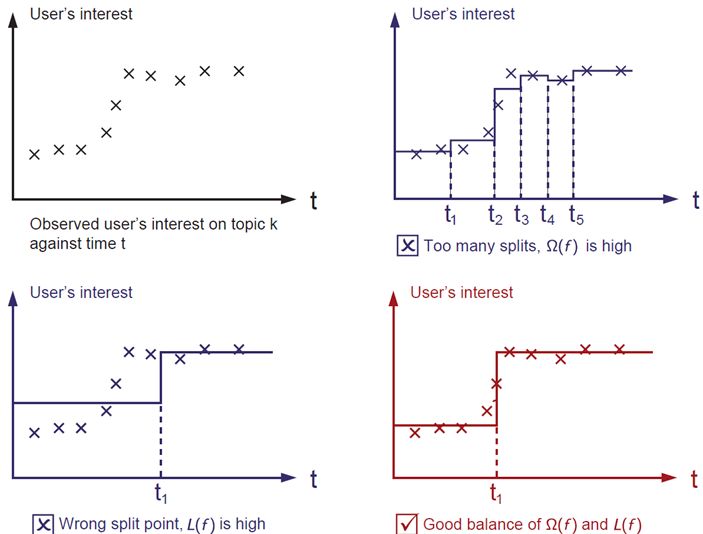
3,優(yōu)化算法
基本思想:貪心法,逐棵樹進(jìn)行學(xué)習(xí),每棵樹擬合之前模型的偏差。
三、第t棵樹學(xué)什么?
要完成構(gòu)建xgboost模型,我們需要確定以下一些事情。
1,如何boost? 如果已經(jīng)得到了前面t-1棵樹構(gòu)成的加法模型,如何確定第t棵樹的學(xué)習(xí)目標(biāo)?
2,如何生成樹?已知第t棵樹的學(xué)習(xí)目標(biāo)的前提下,如何學(xué)習(xí)這棵樹?具體又包括是否進(jìn)行分裂?選擇哪個(gè)特征進(jìn)行分裂?選擇什么分裂點(diǎn)位?分裂的葉子節(jié)點(diǎn)如何取值?
我們首先考慮如何boost的問題,順便解決分裂的葉子節(jié)點(diǎn)如何取值的問題。
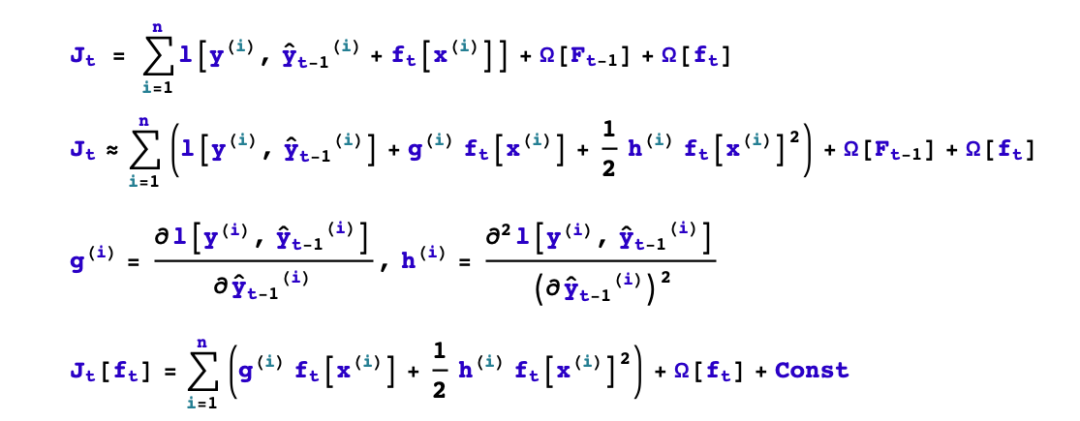


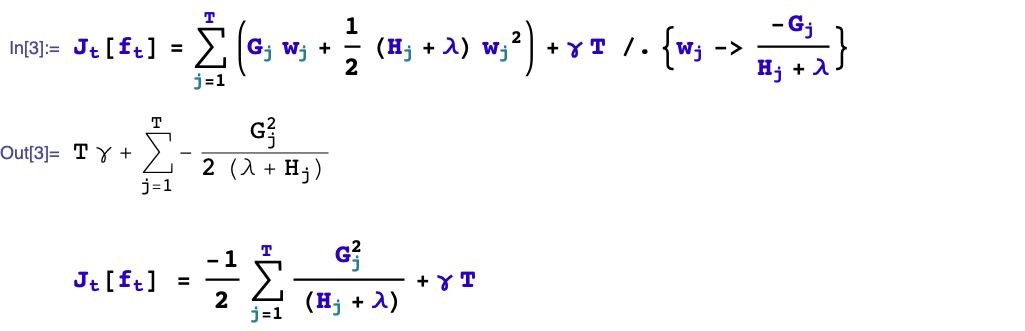
四、如何生成第t棵樹?
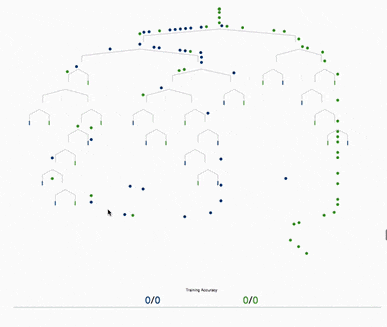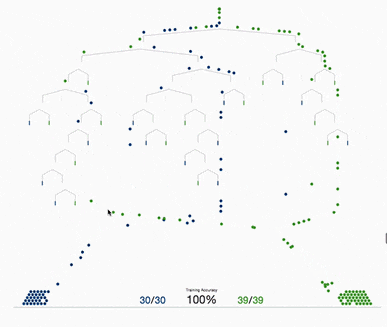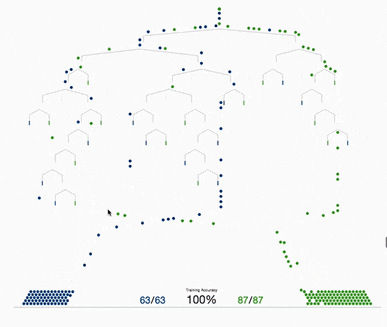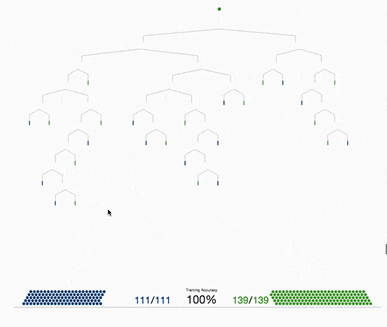
xgboost采用二叉樹,開始的時(shí)候,全部樣本都在一個(gè)葉子節(jié)點(diǎn)上。然后葉子節(jié)點(diǎn)不斷通過二分裂,逐漸生成一棵樹。
xgboost使用levelwise的生成策略,即每次對同一層級的全部葉子節(jié)點(diǎn)嘗試進(jìn)行分裂。對葉子節(jié)點(diǎn)分裂生成樹的過程有幾個(gè)基本的問題:是否要進(jìn)行分裂?選擇哪個(gè)特征進(jìn)行分裂?在特征的什么點(diǎn)位進(jìn)行分裂?以及分裂后新的葉子上取什么值?葉子節(jié)點(diǎn)的取值問題前面已經(jīng)解決了。我們重點(diǎn)討論幾個(gè)剩下的問題。
1,是否要進(jìn)行分裂?
根據(jù)樹的剪枝策略的不同,這個(gè)問題有兩種不同的處理。如果是預(yù)剪枝策略,那么只有當(dāng)存在某種分裂方式使得分裂后目標(biāo)函數(shù)發(fā)生下降,才會進(jìn)行分裂。但如果是后剪枝策略,則會無條件進(jìn)行分裂,等樹生成完成后,再從上而下檢查樹的各個(gè)分枝是否對目標(biāo)函數(shù)下降產(chǎn)生正向貢獻(xiàn)從而進(jìn)行剪枝。xgboost采用預(yù)剪枝策略,只有分裂后的增益大于0才會進(jìn)行分裂。
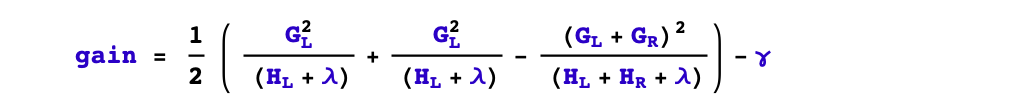
2,選擇什么特征進(jìn)行分裂?
xgboost采用特征并行的方法進(jìn)行計(jì)算選擇要分裂的特征,即用多個(gè)線程,嘗試把各個(gè)特征都作為分裂的特征,找到各個(gè)特征的最優(yōu)分割點(diǎn),計(jì)算根據(jù)它們分裂后產(chǎn)生的增益,選擇增益最大的那個(gè)特征作為分裂的特征。
3,選擇什么分裂點(diǎn)位?
xgboost選擇某個(gè)特征的分裂點(diǎn)位的方法有兩種,一種是全局掃描法,另一種是候選分位點(diǎn)法。
全局掃描法將所有樣本該特征的取值按從小到大排列,將所有可能的分裂位置都試一遍,找到其中增益最大的那個(gè)分裂點(diǎn),其計(jì)算復(fù)雜度和葉子節(jié)點(diǎn)上的樣本特征不同的取值個(gè)數(shù)成正比。
而候選分位點(diǎn)法是一種近似算法,僅選擇常數(shù)個(gè)(如256個(gè))候選分裂位置,然后從候選分裂位置中找出最優(yōu)的那個(gè)。
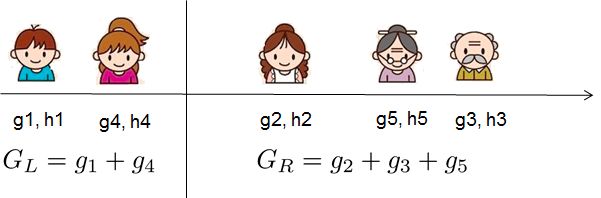
-
GBDT
+關(guān)注
關(guān)注
0文章
13瀏覽量
3874 -
XGBoost
+關(guān)注
關(guān)注
0文章
9瀏覽量
2197
原文標(biāo)題:30分鐘看懂XGBoost的基本原理
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
如何通過XGBoost解釋機(jī)器學(xué)習(xí)
基于xgboost的風(fēng)力發(fā)電機(jī)葉片結(jié)冰分類預(yù)測 精選資料分享
基于xgboost的風(fēng)力發(fā)電機(jī)葉片結(jié)冰分類預(yù)測 精選資料下載
通過學(xué)習(xí)PPT地址和xgboost導(dǎo)讀和實(shí)戰(zhàn)地址來對xgboost原理和應(yīng)用分析

面試中出現(xiàn)有關(guān)Xgboost總結(jié)
基于遺傳算法和隨機(jī)森林的XGBoost改進(jìn)方法
基于XGBoost的樹突狀細(xì)胞算法綜述
在幾個(gè)AWS實(shí)例上運(yùn)行的XGBoost和LightGBM的性能比較
XGBoost超參數(shù)調(diào)優(yōu)指南
詳細(xì)解釋XGBoost中十個(gè)最常用超參數(shù)
XGBoost 2.0介紹
詳解XGBoost 2.0重大更新!






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論