 你見證過Hadoop十年從無到有,再到稱王嘛?
你見證過Hadoop十年從無到有,再到稱王嘛?
我們很榮幸能夠見證Hadoop十年從無到有,再到稱王。感動于技術的日新月異時,希望通過這篇內容深入解讀Hadoop的昨天、今天和明天,憧憬下一個十年。
本文分為技術篇、產業篇、應用篇、展望篇四部分
技術篇
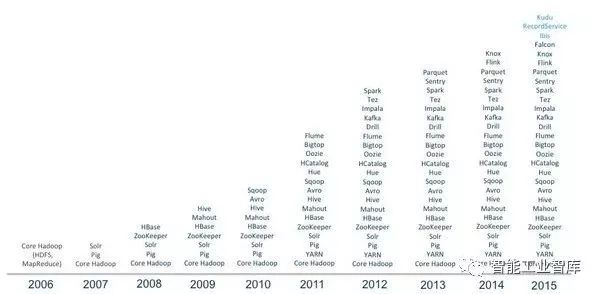
2006年項目成立的一開始,“Hadoop”這個單詞只代表了兩個組件——HDFS和MapReduce。到現在的10個年頭,這個單詞代表的是“核心”(即Core Hadoop項目)以及與之相關的一個不斷成長的生態系統。這個和Linux非常類似,都是由一個核心和一個生態系統組成。
現在Hadoop在一月發布了2.7.2的穩定版, 已經從傳統的Hadoop三駕馬車HDFS,MapReduce和HBase社區發展為60多個相關組件組成的龐大生態,其中包含在各大發行版中的組件就有25個以上,包括數據存儲、執行引擎、編程和數據訪問框架等。
Hadoop在2.0將資源管理從MapReduce中獨立出來變成通用框架后,就從1.0的三層結構演變為了現在的四層架構:
底層——存儲層,文件系統HDFS
中間層——資源及數據管理層,YARN以及Sentry等
上層——MapReduce、Impala、Spark等計算引擎
頂層——基于MapReduce、Spark等計算引擎的高級封裝及工具,如Hive、Pig、Mahout等等
存儲層
HDFS已經成為了大數據磁盤存儲的事實標準,用于海量日志類大文件的在線存儲。經過這些年的發展,HDFS的架構和功能基本固化,像HA、異構存儲、本地數據短路訪問等重要特性已經實現,在路線圖中除了Erasure Code已經沒什么讓人興奮的feature。
隨著HDFS越來越穩定,社區的活躍度也越來越低,同時HDFS的使用場景也變得成熟和固定,而上層會有越來越多的文件格式封裝:列式存儲的文件格式,如Parquent,很好的解決了現有BI類數據分析場景;以后還會出現新的存儲格式來適應更多的應用場景,如數組存儲來服務機器學習類應用等。未來HDFS會繼續擴展對于新興存儲介質和服務器架構的支持。
2015年HBase 發布了1.0版本,這也代表著 HBase 走向了穩定。最新HBase新增特性包括:更加清晰的接口定義,多Region 副本以支持高可用讀,Family粒度的Flush以及RPC讀寫隊列分離等。未來HBase不會再添加大的新功能,而將會更多的在穩定性和性能方面進化,尤其是大內存支持、內存GC效率等。
Kudu是Cloudera在2015年10月才對外公布的新的分布式存儲架構,與HDFS完全獨立。其實現參考了2012年Google發表的Spanner論文。鑒于Spanner在Google 內部的巨大成功,Kudu被譽為下一代分析平臺的重要組成,用于處理快速數據的查詢和分析,填補HDFS和HBase之間的空白。其出現將進一步把Hadoop市場向傳統數據倉庫市場靠攏。
Apache Arrow項目為列式內存存儲的處理和交互提供了規范。目前來自Apache Hadoop社區的開發者們致力于將它制定為大數據系統項目的事實性標準。
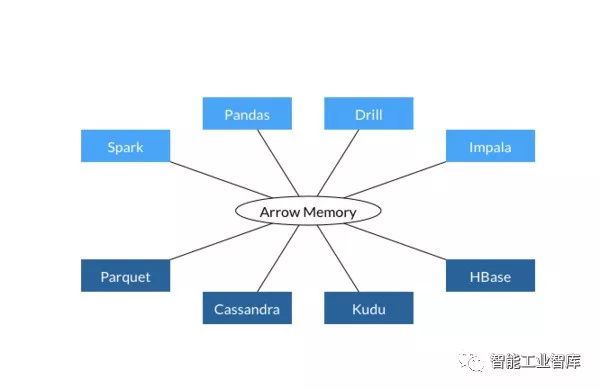
Arrow項目受到了Cloudera、Databricks等多個大數據巨頭公司支持,很多committer同時也是其他明星大數據項目(如HBase、Spark、Kudu等)的核心開發人員。再考慮到Tachyon等似乎還沒有找到太多實際接地氣的應用場景,Arrow的高調出場可能會成為未來新的內存分析文件接口標準。
管控層
管控又分為數據管控和資源管控。
隨著Hadoop集群規模的增大以及對外服務的擴展,如何有效可靠的共享利用資源是管控層需要解決的問題。脫胎于MapReduce1.0的YARN成為了Hadoop 2.0通用資源管理平臺。由于占據了Hadoop的地利,業界對其在資源管理領域未來的前景非常看好。
傳統其他資源管理框架如Mesos,還有現在興起的Docker等都會對YARN未來的發展產生影響。如何提高YARN性能、如何與容器技術深度融合,如何更好的適應短任務的調度,如何更完整的多租戶支持、如何細粒度的資源管控等都是企業實際生產中迫在眉睫的需求,需要YARN解決。要讓Hadoop走得更遠,未來YARN需要做的工作還很多。
另一方面大數據的安全和隱私越來越多的受到關注。Hadoop依靠且僅依靠Kerberos來實現安全機制,但每一個組件都將進行自己的驗證和授權策略。開源社區似乎從來不真正關心安全問題,如果不使用來自Hortonworks的Ranger或來自Cloudera 的Sentry這樣的組件,那么大數據平臺基本上談不上安全可靠。
Cloudera剛推出的RecordService組件使得Sentry在安全競賽中拔得先機。RecordService不僅提供了跨所有組件一致的安全顆粒度,而且提供了基于Record的底層抽象(有點像Spring,代替了原來Kite SDK的作用),讓上層的應用和下層存儲解耦合的同時、提供了跨組件的可復用數據模型。
計算引擎層
Hadoop生態和其他生態最大的不同之一就是“單一平臺多種應用”的理念了。傳的數據庫底層只有一個引擎,只處理關系型應用,所以是“單一平臺單一應用”;而NoSQL市場有上百個NoSQL軟件,每一個都針對不同的應用場景且完全獨立,因此是“多平臺多應用”的模式。而Hadoop在底層共用一份HDFS存儲,上層有很多個組件分別服務多種應用場景,如:
確定性數據分析:主要是簡單的數據統計任務,例如OLAP,關注快速響應,實現組件有Impala等;
探索性數據分析:主要是信息關聯性發現任務,例如搜索,關注非結構化全量信息收集,實現組件有Search等;
預測性數據分析:主要是機器學習類任務,例如邏輯回歸等,關注計算模型的先進性和計算能力,實現組件有Spark、MapReduce等;
數據處理及轉化:主要是ETL類任務,例如數據管道等,關注IO吞吐率和可靠性,實現組件有MapReduce等
…
其中,最耀眼的就是Spark了。IBM宣布培養100萬名Spark開發人員,Cloudera在One Platform倡議中宣布支持Spark為Hadoop的缺省通用任務執行引擎,加上Hortonworks全力支持Spark,我們相信Spark將會是未來大數據分析的核心。
雖然Spark很快,但現在在生產環境中仍然不盡人意,無論擴展性、穩定性、管理性等方面都需要進一步增強。同時,Spark在流處理領域能力有限,如果要實現亞秒級或大容量的數據獲取或處理需要其他流處理產品。Cloudera宣布旨在讓Spark流數據技術適用于80%的使用場合,就考慮到了這一缺陷。我們確實看到實時分析(而非簡單數據過濾或分發)場景中,很多以前使用S4或Storm等流式處理引擎的實現已經逐漸Kafka+Spark Streaming代替。
Spark的流行將逐漸讓MapReduce、Tez走進博物館。
服務層
服務層是包裝底層引擎的編程API細節,對業務人員提供更高抽象的訪問模型,如Pig、Hive等。
而其中最炙手可熱的就是OLAP的SQL市場了。現在,Spark有70%的訪問量來自于SparkSQL!SQL on Hadoop到底哪家強?Hive、Facebook的Pheonix、Presto、SparkSQL、Cloudera推的Impala、MapR推的Drill、IBM的BigSQL、還是Pivital開源的HAWQ?
這也許是碎片化最嚴重的地方了,從技術上講幾乎每個組件都有特定的應用場景,從生態上講各個廠家都有自己的寵愛,因此Hadoop上SQL引擎已經不僅僅是技術上的博弈(也因此考慮到本篇中立性,此處不做評論)。可以遇見的是,未來所有的SQL工具都將被整合,有些產品已經在競爭鐘逐漸落伍,我們期待市場的選擇。
周邊的工具更是百花齊放,最重要的莫過于可視化、任務管理和數據管理了。
有很多開源工具都支持基于Hadoop 的查詢程序編寫以及即時的圖形化表示,如HUE、Zeppelin等。用戶可以編寫一些SQL或Spark代碼以及描述代碼的一些標記,并指定可視化的模版,執行后保存起來,就可供其他人復用,這鐘模式也被叫做“敏捷BI”。這個領域的商業產品更是競爭激烈,如Tableau、Qlik等。
調度類工具的鼻祖Oozie能實現幾個MapReduce任務串連運行的場景,后來的Nifi及Kettle等其他工具則提供了更加強大的調度實現,值得一試。
毫無疑問,相對與傳統的數據庫生態,Hadoop的數據治理相對簡單。Atlas是Hortonworks新的數據治理工具,雖然還談不上完全成熟,不過正取得進展。Cloudera的Navigator是Cloudera商業版本的核心,匯聚了生命周期管理、數據溯源、安全、審計、SQL遷移工具等一系列功能。Cloudera收購Explain.io以后將其產品整合為Navigator Optimizator組件,能幫助用戶把傳統的SQL應用遷移到Hadoop平臺并提供優化建議,可以節省數人月的工作量。
算法及機器學習
實現基于機器學習的自動的智能化數據價值挖掘是大數據和Hadoop最誘人的愿景了,也是很多企業對大數據平臺的最終期望。隨著可獲得的數據越來越多,未來大數據平臺的價值更多的取決于其計算人工智能的程度。
現在機器學習正慢慢跨出象牙塔,從一個少部分學術界人士研究的科技課題變成很多企業正在驗證使用的數據分析工具,而且已經越來越多的進入我們的日常生活。
機器學習的開源項目除了之前的Mahout、MLlib、Oryx等,今年發生了很多令人矚目的大事,迎來了數個明星巨頭的重磅加入:
2015年1月,Facebook開源前沿深度學習工具“Torch”。
2015年4月,亞馬遜啟動其機器學習平臺Amazon Machine Learning,這是一項全面的托管服務,讓開發者能夠輕松使用歷史數據開發并部署預測模型。
2015年11月,谷歌開源其機器學習平臺TensorFlow。
同一月,IBM開源SystemML并成為Apache官方孵化項目。
同時,微軟亞洲研究院將分布式機器學習工具DMTK通過Github開源。DMTK由一個服務于分布式機器學習的框架和一組分布式機器學習算法組成,可將機器學習算法應用到大數據中。
2015年12月,Facebook開源針對神經網絡研究的服務器“Big Sur”,配有高性能圖形處理單元(GPUs),轉為深度學習方向設計的芯片。
產業篇
現在使用Hadoop的企業以及靠Hadoop賺錢的企業已經成千上萬。幾乎大的企業或多或少的已經使用或者計劃嘗試使用Hadoop技術。就對Hadoop定位和使用不同,可以將Hadoop業界公司劃分為四類:
第一梯隊:這類公司已經將Hadoop當作大數據戰略武器。
第二梯隊:這類公司將Hadoop 產品化。
第三梯隊:這類公司創造對Hadoop整體生態系統產生附加價值的產品。
第四梯隊:這類公司消費Hadoop,并給規模比第一類和第二類小的公司提供基于Hadoop的服務。

時至今日,Hadoop雖然在技術上已經得到驗證、認可甚至已經到了成熟期。其中最能代表Hadoop發展軌跡的莫過于商業公司推出的Hadoop發行版了。自從2008年Cloudera成為第一個Hadoop商業化公司,并在2009年推出第一個Hadoop發行版后,很多大公司也加入了做Hadoop產品化的行列。
“發行版”這個詞是開源文化特有的符號,看起來任何一個公司只要將開源代碼打個包,再多多少少加個佐料就能有一個“發行版”,然而背后是對海量生態系統組件的價值篩選、兼容和集成保證以及支撐服務。
2012年以前的發行版基本為對Hadoop打補丁為主,出現了好幾個私有化Hadoop版本,所折射的是Hadoop產品在質量上的缺陷。同期HDFS、HBase等社區的超高活躍度印證了這個事實。
而之后的公司更多是工具、集成、管理,所提供的不是“更好的Hadoop”而是如何更好的用好“現有”的Hadoop。
2014年以后,隨著Spark和其他OLAP產品的興起,折射出來是Hadoop善長的離線場景等已經能夠很好的解決,希望通過擴大生態來適應新的硬件和拓展新的市場。
Cloudera提出了Hybrid Open Source的架構:核心組件名稱叫CDH(Cloudera's Distribution including Apache Hadoop),開源免費并與Apache社區同步,用戶無限制使用,保證Hadoop基本功能持續可用,不會被廠家綁定;數據治理和系統管理組件閉源且需要商業許可,支持客戶可以更好更方便的使用Hadoop技術,如部署安全策略等。Cloudera也在商業組件部分提供在企業生產環境中運行Hadoop所必需的運維功能,而這些功能并不被開源社區所覆蓋,如無宕機滾動升級、異步災備等。
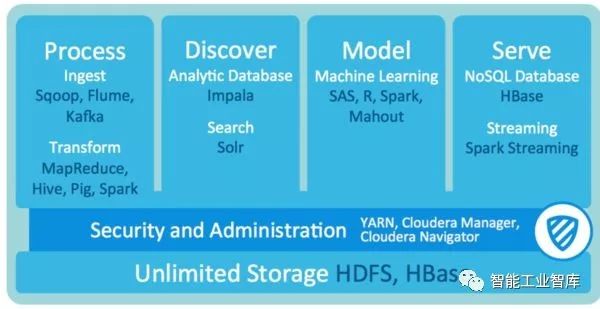
Hortonworks采用了100%完全開源策略,產品名稱為HDP(Hortonworks Data Platform)。所有軟件產品開源,用戶免費使用,Hortonworks提供商業的技術支持服務。與CDH相比,管理軟件使用開源Ambari,數據治理使用Atlas,安全組件使用Ranger而非Sentry,SQL繼續緊抱Hive大腿。
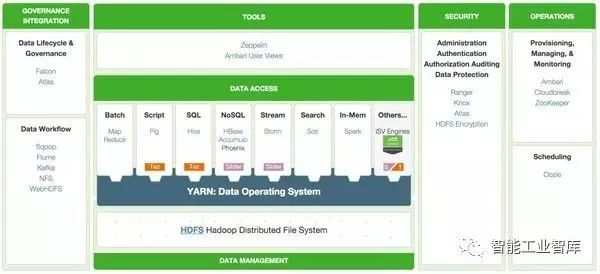
MapR采用了傳統軟件廠商的模式,使用私有化的實現。用戶購買軟件許可后才能使用。其OLAP產品主推Drill,又不排斥Impala。
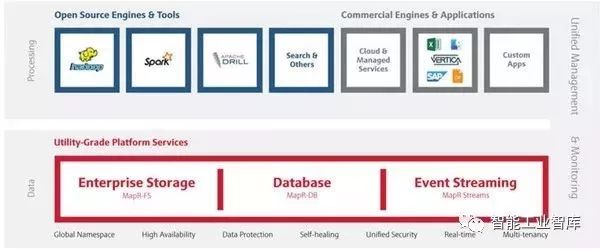
現在主流的公有云如AWS、Azure等都已經在原有提供虛擬機的IaaS服務之外,提供基于Hadoop的PaaS云計算服務。未來這塊市場的發展將超過私有Hadoop部署。
應用篇
Hadoop平臺釋放了前所未有的計算能力,同時大大降低了計算成本。底層核心基礎架構生產力的發展,必然帶來的是大數據應用層的迅速建立。
對于Hadoop上的應用大致可以分為這兩類:
IT優化
將已經實現的應用和業務搬遷到Hadoop平臺,以獲得更多的數據、更好的性能或更低的成本。通過提高產出比、降低生產和維護成本等方式為企業帶來好處。
這幾年Hadoop在數個此類應用場景中已經被證明是非常適合的解決方案,包括:
歷史日志數據在線查詢:傳統的解決方案將數據存放在昂貴的關系型數據庫中,不僅成本高、效率低,而且無法滿足在線服務時高并發的訪問量。以HBase為底層存儲和查詢引擎的架構非常適合有固定場景(非ad hoc)的查詢需求,如航班查詢、個人交易記錄查詢等等。現在已經成為在線查詢應用的標準方案,中國移動在企業技術指導意見中明確指明使用HBase技術來實現所有分公司的清賬單查詢業務。
ETL任務:不少廠商已經提供了非常優秀的ETL產品和解決方案,并在市場中得到了廣泛的應用。然而在大數據的場景中,傳統ETL遇到了性能和QoS保證上的嚴重挑戰。多數ETL任務是輕計算重IO類型的,而傳統的IT硬件方案,如承載數據庫的小型計算機,都是為計算類任務設計的,即使使用了最新的網絡技術,IO也頂多到達幾十GB。
采用分布式架構的Hadoop提供了完美的解決方案,不僅使用share-nothing的scale-out架構提供了能線性擴展的無限IO,保證了ETL任務的效率,同時框架已經提供負載均衡、自動FailOver等特性保證了任務執行的可靠性和可用性。
數據倉庫offload:傳統數據倉庫中有很多離線的批量數據處理業務,如日報表、月報表等,占用了大量的硬件資源。而這些任務通常又是Hadoop所善長的
經常被問到的一個問題就是,Hadoop是否可以代替數據倉庫,或者說企業是否可以使用免費的Hadoop來避免采購昂貴的數據倉庫產品。數據庫界的泰斗Mike Stonebroker在一次技術交流中說:數據倉庫和Hadoop所針對的場景重合型非常高,未來這兩個市場一定會合并。
我們相信在數據倉庫市場Hadoop會遲早替代到現在的產品,只不過,那時候的Hadoop已經又不是現在的樣子了。就現在來講,Hadoop還只是數據倉庫產品的一個補充,和數據倉庫一起構建混搭架構為上層應用聯合提供服務。
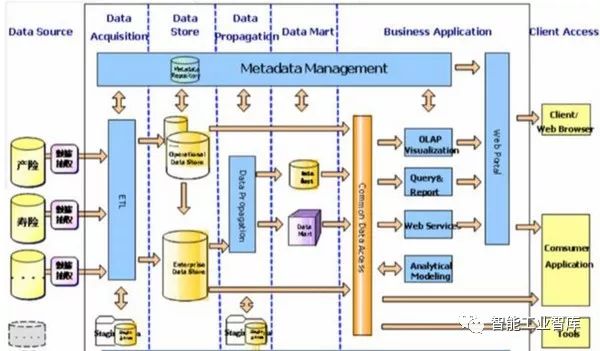
業務優化
在Hadoop上實現原來尚未實現的算法、應用,從原有的生產線中孵化出新的產品和業務,創造新的價值。通過新業務為企業帶來新的市場和客戶,從而增加企業收入。
Hadoop提供了強大的計算能力,專業大數據應用已經在幾乎任何垂直領域都很出色,從銀行業(反欺詐、征信等)、醫療保健(特別是在基因組學和藥物研究),到零售業、服務業(個性化服務、智能服務,如UBer的自動派車功能等)。
在企業內部,各種工具已經出現,以幫助企業用戶操作核心功能。例如,大數據通過大量的內部和外部的數據,實時更新數據,可以幫助銷售和市場營銷弄清楚哪些客戶最有可能購買。客戶服務應用可以幫助個性化服務; HR應用程序可幫助找出如何吸引和留住最優秀的員工等。
為什么Hadoop如此成功?這個問題似乎是個馬后炮,但當我們今天驚嘆于Hadoop在短短10年時間取得如此統治性地位的時候,確實會自然而然地思考為什么這一切會發生。基于與同期其他項目的比較,我們認為有很多因素的綜合作用造就了這一奇跡:
技術架構:Hadoop推崇的本地化計算理念,其實現在可擴展性、可靠性上的優勢,以及有彈性的多層級架構等都是領先其他產品而獲得成功的內在因素。沒有其他任何一個這樣復雜的系統能快速的滿足不斷變化的用戶需求。
硬件發展:摩爾定律為代表的scale up架構遇到了技術瓶頸,不斷增加的計算需求迫使軟件技術不得不轉到分布式方向尋找解決方案。同時,PC服務器技術的發展使得像Hadoop這樣使用廉價節點組群的技術變為可行,同時還具有很誘人的性價比優勢。
工程驗證:Google發表GFS和MapReduce論文時已經在內部有了可觀的部署和實際的應用,而Hadoop在推向業界之前已經在Yahoo等互聯網公司驗證了工程上的可靠性和可用性,極大的增加了業界信心,從而迅速被接納流行。而大量的部署實例又促進了Hadoop的發展喝成熟。
社區推動:Hadoop生態一直堅持開源開放,友好的Apache許可基本消除了廠商和用戶的進入門檻,從而構建了有史以來最大最多樣化最活躍的開發者社區,持續地推動著技術發展,讓Hadoop超越了很多以前和同期的項目。
關注底層:Hadoop 的根基是打造一個分布式計算框架,讓應用程序開發人員更容易的工作。業界持續推動的重點一直在不斷夯實底層,并在諸如資源管理和安全領域等領域不斷開花結果,為企業生產環境部署不斷掃清障礙。
下一代分析平臺
過去的十年中Apache Hadoop社區以瘋狂的速度發展,現在儼然已經是事實上的大數據平臺標準。但仍有更多的工作要做!大數據應用未來的價值在于預測,而預測的核心是分析。下一代的分析平臺會是什么樣呢?它必定會面臨、同時也必須要解決以下的問題:
更多更快的數據。
更新的硬件特性及架構。
更高級的分析。
更安全。
因此,未來的幾年,我們會繼續見證“后Hadoop時代”的下一代企業大數據平臺:
內存計算時代的來臨。隨著高級分析和實時應用的增長,對處理能力提出了更高的要求,數據處理重點從IO重新回到CPU。以內存計算為核心的Spark將代替以IO吞吐為核心的MapReduce成為分布式大數據處理的缺省通用引擎。做為既支持批處理有支持準實時流處理的通用引擎,Spark將能滿足80%以上的應用場景。
然而,Spark畢竟核心還是批處理,擅長迭代式的計算,但并不能滿足所有的應用場景。其他為特殊應用場景設計的工具會對其補充,包括:
a) OLAP。OLAP,尤其是聚合類的在線統計分析應用,對于數據的存儲、組織和處理都和單純離線批處理應用有很大不同。
b) 知識發現。與傳統應用解決已知問題不同,大數據的價值在于發現并解決未知問題。因此,要最大限度地發揮分析人員的智能,將數據檢索變為數據探索。
統一數據訪問管理。現在的數據訪問由于數據存儲的格式不同、位置不同,用戶需要使用不同的接口、模型甚至語言。同時,不同的數據存儲粒度都帶來了在安全控制、管理治理上的諸多挑戰。未來的趨勢是將底層部署運維細節和上層業務開發進行隔離,因此,平臺需要系統如下的功能保證:
a) 安全。能夠大數據平臺上實現和傳統數據管理系統中相同口徑的數據管理安全策略,包括跨組件和工具的一體化的用戶權利管理、細粒度訪問控制、加解密和審計。
b) 統一數據模型。通過抽象定義的數據描述,不僅可以統一管理數據模型、復用數據解析代碼,還可以對于上層處理屏蔽底層存儲的細節,從而實現開發/處理與運維/部署的解偶。
簡化實時應用。現在用戶不僅關心如何實時的收集數據,而且關心同時盡快的實現數據可見和分析結果上線。無論是以前的delta架構還是現在lambda架構等,都希望能夠有一種解決快速數據的方案。Cloudera最新公開的Kudu雖然還沒有進入產品發布,但卻是現在解決這個問題可能的最佳方案:采用了使用單一平臺簡化了快速數據的“存取用”實現,是未來日志類數據分析的新的解決方案。
翹首展望,下一個十年
10年以后的Hadoop應該只是一個生態和標準的“代名詞”了,下層的存儲層不只是HDFS、HBase和Kudu等現有的存儲架構,上層的處理組件更會像app store里的應用一樣多,任何第三方都可以根據Hadoop的數據訪問和計算通信協議開發出自己的組件,用戶在市場中根據自己數據的使用特性和計算需求選擇相應的組件自動部署。
當然,有一些明顯的趨勢必然影響著Hadoop的前進:
云計算
現在50%的大數據任務已經運行在云端,在3年以后這個比例可能會上升到80%。Hadoop在公有云的發展要求更加有保障的本地化支持。
硬件
快速硬件的進步會迫使社區重新審視Hadoop的根基,Hadoop社區絕不會袖手旁觀。
物聯網的發展會帶來海量的、分布的和分散的數據源。Hadoop將適應這種發展。
以后的十年會發生什么?以下是筆者的一些猜想:
SQL和NoSQL市場會合并,NewSQL和Hadoop技術相互借鑒而最終走向統一,Hadoop市場和數據倉庫市場會合并,然而產品碎片化會繼續存在。
Hadoop與其他資源管理技術和云平臺集成,融合docker和unikernal等技術統一資源調度管理,提供完整多租戶和QoS能力,企業數據分析中心合并為單一架構。
企業大數據產品場景化。以后直接提供產品和技術的公司趨于成熟并且轉向服務。越來越多的新公司提供的是行業化、場景化的解決方案,如個人網絡征信套件以及服務。
大數據平臺的場景“分裂”。與現在談及大數據言必稱Hadoop以及某某框架不同,未來的數據平臺將根據不同量級的數據(從幾十TB到ZB)、不同的應用場景(各種專屬應用集群)出現細分的階梯型的解決方案和產品,甚至出現定制化一體化產品。
后記
現在Hadoop儼然已經成為企業數據平臺的“新常態”。我們很榮幸能夠見證Hadoop十年從無到有,再到稱王。在我們感動于技術的日新月異時,希望能通過本文能為Hadoop的昨天、今天和明天做出一點自己的解讀,算是為Hadoop慶祝10歲生日獻上的禮物。
筆者水平有限,加之時間緊迫,膚淺粗糙之處,還請各位讀者原諒和指教。文中有些內容引自網絡,某些出處未能找到,還請原作者原諒。
大數據的明天是美好的,未來Hadoop一定是企業軟件的必備技能,希望我們能一起見證。
-
核心
+關注
關注
0文章
44瀏覽量
15023 -
物聯網
+關注
關注
2903文章
44273瀏覽量
371238 -
大數據
+關注
關注
64文章
8863瀏覽量
137295
原文標題:一文看懂Hadoop
文章出處:【微信號:aicapital,微信公眾號:全球人工智能】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
蘋果十年造車終成空,轉向all in AI
何小鵬宣布未來十年愿景,加速全球化AI汽車布局
沃達豐與谷歌深化十年戰略合作
十年預言:Chiplet的使命
BOE京東方與聯合國教科文組織UNESCO簽訂合作協議 成為首個支持聯合國“科學十年”的中國科技企業

聯發科談未來十年的戰略布局
特斯拉入華十年全球車主超600萬,中國車主已達170萬
Redmi新十年產品定位:Turbo系列重塑中端性能格局
工業機器人減速器行業的十年變革
從無到有,PCB工廠的神奇設備之旅!

跨周期,創未來!華秋喜獲中國產業互聯網十周年-杰出企業
跨周期,創未來!華秋喜獲中國產業互聯網十周年-杰出企業

跨周期,創未來!華秋喜獲中國產業互聯網十周年-杰出企業






 工商網監
工商網監
評論