 神經網絡時代,中文分詞還有必要嗎?
神經網絡時代,中文分詞還有必要嗎?
【導讀】通常,中文文本處理的第一步稱為分詞,這好像已經成為一種“共識”,但對其必要性的研究與探討很少看到。本文中,作者就提出了一個非常基礎的問題:基于深度學習方法的自然語言處理過程中,中文分詞(CWS)是必要的嗎?
近日,香濃科技 AI 團隊(Shannon AI)與斯坦福大學聯合聯合發表了一篇研究《Is Word Segmentation Necessary for Deep Learning of Chinese Representations》,并被 ACL 2019 接收。
在這項研究中,作者在四個端到端 NLP 基線任務中進行評測,對比基于分詞的 word model (“詞”級別)和無需分詞的 char model (“字”級別)兩種模型的效果,評測內容包括語言建模、機器翻譯、句子匹配/改寫和文本分類。實驗結果顯示,基于char model 比 word model 效果更優。

論文中,本文還進一步通過實驗分析了兩種模型存在差異的原因。作者認為,除了大家都認為的 OOV(out-of-vocabulary) 帶來的影響, word model 的 data sparsity (數據稀疏)問題也是導致過擬合的一個重要原因。也正是希望這項研究,可以讓大家發現分詞有意思的地方,還有它還未曾被大家挖掘、探索的一面,以及rethinking 分詞在基于深度學習模型的 NLP 任務的必要性。
論文作者之一,香濃科技(Shannon AI)李紀為也參與到這項研究中,還在知乎上回答了大家對這篇研究的疑問。
問:如何評價李紀為的論文Is Word Segmentation Necessary?
李紀為:中文分詞確實是個非常有意思、也很重要的話題,這篇文章嘗試拋磚引玉去探究一下這個問題,也希望這一問題獲得學術界更廣泛的重視。因為之前的工作,分詞本身的優缺點并沒有詳盡地被探討。鑒于筆者本身的局限性,文章在 intro 的結尾也提到:Instead of making a conclusive (and arrogant) argument that Chinese word segmentation is not necessary, we hope this paper could foster more discussions and explorations on the necessity of the long-existing task of CWS in the community, alongside with its underlying mechanisms.
這個問題涉及到的更本質的問題,就是語言學的structure在深度學習的框架下有多重要 (因為詞是一種基本的語言學structure)。這個問題近兩年學者有不同的爭論,有興趣的同學可以看 manning 和 lecun的 debate。更早的15年,manning 和 andrew ng 就有過討論,當時 andrew的想法比lecun還要激進,認為如果有足夠的訓練數據和強有力的算法,哪怕英文都不需要word,char就夠了。
debate 鏈接:
https://www.youtube.com/watch?v=fKk9KhGRBdI
也有網友質疑論文中的實驗:
@Cyunsiu To:這類論文是有意義的,但是這篇論文的實驗持質疑態度。
這篇文章在分析分詞不 work 的時候,很大一部分把不 work 的原因歸因于 oov 太多,我個人不認同,至少分類動不動就能開十萬+ 級別的詞表,一方面 oov 不會太多,另一方面即使 oov 太多,也應該分析一下哪些 oov 導致模型不 work 吧,其實我個人認為根本不是 oov 的原因造成的。要不然英文里面的 word 也不會 work 了。
對此,李紀為回答道:
李紀為:文章提到幾個方面,OOV 是其中一個方面,但并不是所有。除了 OOV 之外, data sparsity 也是一個重要原因。從文章的圖2上看,在同樣的數據集上,對于不同 OOV 的frequency bar (意思是 frequency 小于 1 算作 OOV,還是 frequency 小于 5 算作 OOV),實驗結果是先升再降的。這個其實也比較好理解,如果 frequency bar 小,對于那些 infrequent 的詞會單獨認為是詞,而不是 OOV。因為 data sparsity 的問題,會使學習不充分,從而影響了效果。 從這個角度,char 模型比 word 模型會學習得更充分。
以上回答來源
https://www.zhihu.com/question/324672243
究竟這項論文中是如何實驗對比得出 char 模型效果優于 word 模型效果的?OOV 和 data sparsity 又帶來了哪些影響?下面我們就為大家解讀分析。
一、介紹
英文(以及其他基于拉丁字母的語言)和中文(以及其他沒有明顯的詞語分隔符的語言,如韓文和日文)存在一個明顯的差別:根據空格就能很明顯、直接地識別每個英文詞,但中文中并不存在這樣的詞語分隔符,這也是中文分詞任務(CWS)的來源。在深度學習中,詞往往是操作的基本單位,本文將此種模型稱為基于詞語的模型(word model)。在模型中,分詞后得到的詞語,再使用固定長度的向量來表示,這就和英語詞語的處理方式相同了。那 word model 存在哪些缺陷呢?
首先,data sparsity會導致模型出現過擬合,OOV則會限制模型的學習能力。根據齊普夫定律(Zipf’s law),很多中文詞的出現頻率都非常低,這使得模型難以學習到詞語的語義信息。以使用較為廣泛的 Chinese Treebank 數據集(Chinese Treebank dataset, CTB)為例進行說明。通過使用結巴分詞對 CTB 數據集進行切詞,可以得到615,194個詞語,其中不同詞語50,266個。這些詞語中,有24,458個詞僅出現一次,占總詞數的48.7%,僅占語料的4%。表1展示了針對這一語料的統計數據,可以看出基于詞語的數據集非常稀疏。由于詞語數的增加會使模型參數增多,數據稀疏很容易引起過擬合問題。另外,由于維護大規模的詞語-向量表存在難度,很多詞語都會被處理為OOV,進一步限制了模型的學習能力。
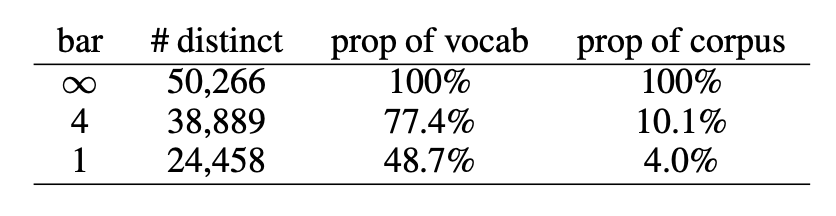
表1 CTB 詞語統計數據
第二,現在的分詞技術還存在很多問題,分詞不當產生的錯誤會導致 NLP 任務出現偏差。中文中詞語并沒有清晰的邊界,增加了中文分詞的難度和復雜性。從不同的語言學角度來看,中文分詞也可以有不同的標準。從表2展示的例子可以看出,在使用最廣泛的兩個中文分詞數據庫 PKU 和 CTB 中,相同的句子存在不同的分詞結果。
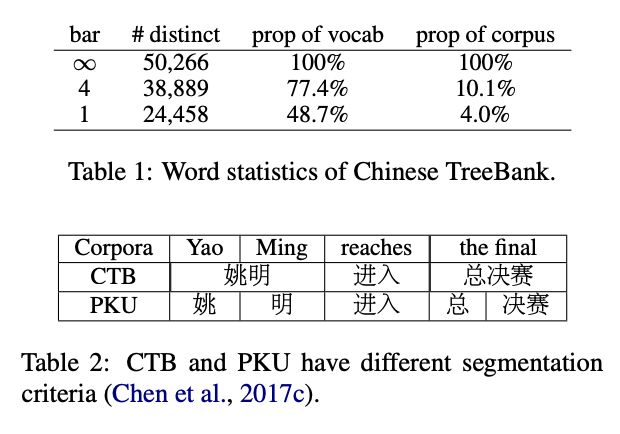
表2 CTB 和 PKU 不同的分詞標準
第三,分詞產生的收益效果尚不明確。還取決于帶標簽的 CWS 數據能夠帶來附加語義信息的多少。對于word model 和 char model而言,兩者的差異在于是否使用了帶標簽的 CWS 數據作為模型學習使用的信號。但在現有研究中,針對這一問題討論較少。舉例來說,在機器翻譯模型中,學者往往使用百萬級的樣例進行訓練,但帶標簽的 CWS 數據集規模往往較小( CTB 有6.8萬條數據,PKU 有2.1 萬條數據),而且領域較為狹窄。這一數據似乎并不能為模型效果帶來明顯的增益。
其實在大規模使用神經網絡模型方法之前,就有學者對分詞是否必要及其能夠帶來增益的多少進行了討論。在信息檢索領域,有學者指出,如果在查詢詞和檢索內容中應用相同的分詞方法,就能提升檢索效果。但如果在char model中使用 bigram 對字符進行表示,則word model的優勢就會大大減弱;在機器翻譯的相關研究中,有學者指出,分詞并不能帶來明顯的效果提升,也并非提升模型效果的關鍵因素。
在本文中,探討基于深度學習的中文自然語言處理任務中分詞的必要性,作者首先在不涉及分詞的任務中比較了word model 和 char model的效果差異。作者通過語言建模、文本分類、機器翻譯和句子匹配四個 NLP 任務比較了兩個模型的效果,并發現char model 的效果更佳,比混合模型的效果更佳或等同。這一結果說明,實際上cahr model已經對足夠的語義信息進行了編碼。
另外,本文對word model的不足也做了進一步的探究,并指出了導致模型缺陷的主要原因,例如,OOV、data sparsity 會導致過擬合,以及領域轉換能力較差。
二、回顧
對分詞的研究并不是一項新研究,曾經大家都是如何進行實驗與研究的呢?
自2003年第一個國際中文分詞庫出現以來,中文分詞取得了很多進展。在早期,大多時候,分詞都基于一個預定義的詞典進行。在這一時期,一個最為簡單且具有健壯性的模型即最大匹配模型,該模型最簡單的版本即從左至右的最大匹配模型(maxmatch)。這一時期,新模型的提出主要來源于出現新的分詞標準。
隨著統計機器學習模型的出現, CWS 問題逐漸變為打標簽問題。例如,使用 BEMS 標簽進行標注,確認句子的起始詞(Start),結尾詞(End),中間詞(Middle)或獨立詞(Single)。傳統的序列標注方法包括 HMM,、MEMN,、CRF 等。
到了神經網絡時代,基于神經元的 CWS 模型包括CNN、RNN、LSTM等。這類模型能更靈活地使用上下文語義信息對詞語進行標注,并且使特征工程更簡單易行。詞語的神經元表示可以作為 CRF 模型的特征,也可作為決策層的輸入。
三、實驗結果
在這一部分,我們將為大家展示研究中作者將兩種模型在 4 個 NLP 任務中實驗的評測結果。在模型訓練中,為便于比較,作者使用網格搜索對超參數進行了微調,包括學習率、dropout、batch size等。
3.1 語言建模
該任務要求模型通過給定的前述語境信息的表示,預測后續詞語。在語言建模任務中使用CTB 6.0數據集來對比兩模型效果。將數據劃分為訓練集、驗證集和測試集,占比分別為80%,10%,10%,使用 Jieba 進行分詞,LSTM 模型對字符和詞語進行了編碼。
實驗中,對比了不同維度下,單獨的 word、char 模型和混合模型的效果。可以發現,char 模型的效果都優于 word 模型,維度為 2048 時,ppl 達到最優的結果差距明顯。作者在標準 CWS 包和 LTP 包也進行了實驗,并獲得了相同的結果。
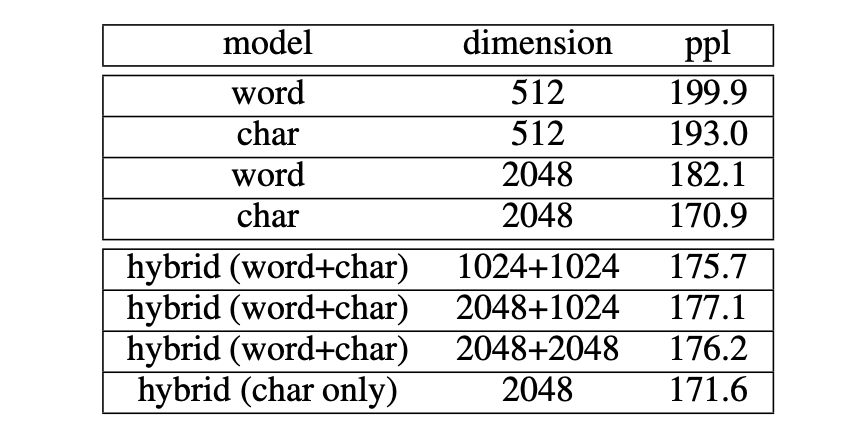
表3 語言建模結果:char model 優于 word model
另外,本文對混合模型的效果也進行了探究,為便于比較,本文構建了兩種不同的混合模型,對 word+char 及 only char進行表示。詞的表示由其組成詞的表示向量和剩余字符的表示向量聯合構成。由于中文詞語的構成字符數量不定,為保證輸出數據維度一致,本文使用 CNN 對字符向量的結合進行了處理。
可以發現,在語言建模任務中,分詞沒有帶來明顯的模型增益,加入詞嵌入信息還降低了模型效果。
3.2 機器翻譯
本部分評測使用中英翻譯,使用語料為從 LDC 語料中抽取的125萬個句子對。驗證數據使用的是NIST 2002 ,測試數據使用的是NIST 2003,2004,2005,2006和2008。實驗使用了出現頻次最高的前30,000個英語詞語,以及前27,500個中文詞語。char model 的詞語量設置為4500。作者對中譯英和英譯中兩種任務都進行了評測,表4所示中譯英結果,表5表示英譯中結果。
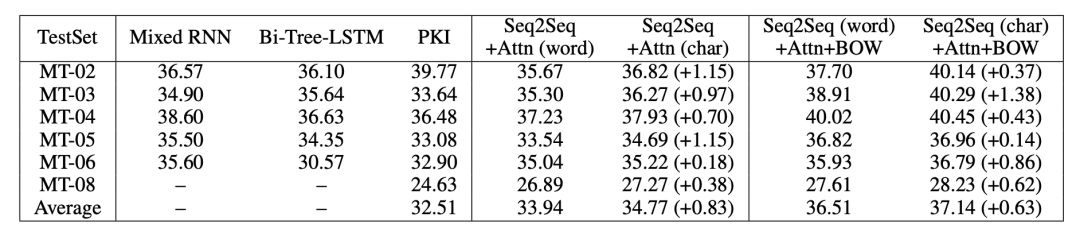
表4 中譯英機器翻譯評測結果(Mixed RNN, Bi-Tree-LSTM, PKI 模型效果)
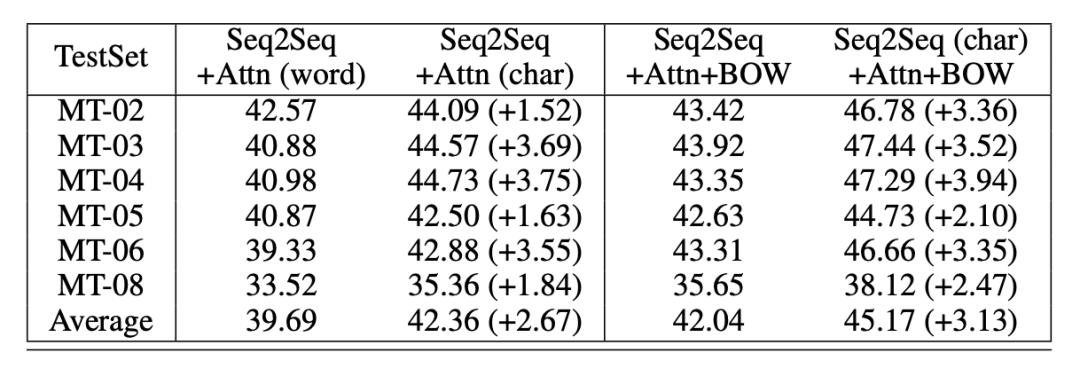
表5 英譯中機器翻譯評測結果
在機器翻譯中,無論是「中譯英」還是「英譯中」任務,char 模型效果都優于word模型。
3.3 句子匹配
作者基于 BQ 和 LCQMC兩個語料對句子匹配任務進行了評測。這兩個語料為每一個語句對提供了一個二元標簽,以標示兩個句子是否具有相似性(或相同意圖)。在這部分實驗中,評測內容為使用不同模型對語句對的二元標簽進行預測。評測結果如表6所示。在句子匹配任務中,基于char 模型效果優于基于word的模型效果,表明 char 模型更能捕捉單元之間的語義聯系。

表6 LCQMC 和 BQ 語料庫的評測結果
3.4 文本分類
文本分類任務中使用的評測基線包括 ChinaNews, Ifeng, JD_Full, JD _binary, Dianping。作者使用雙向 LSTM 模型對基于word和基于char的模型分別進行訓練用于評測,評測結果如表7所示。除 ChinaNews語料庫外,基于字符的模型的表現均優于基于詞語的模型。
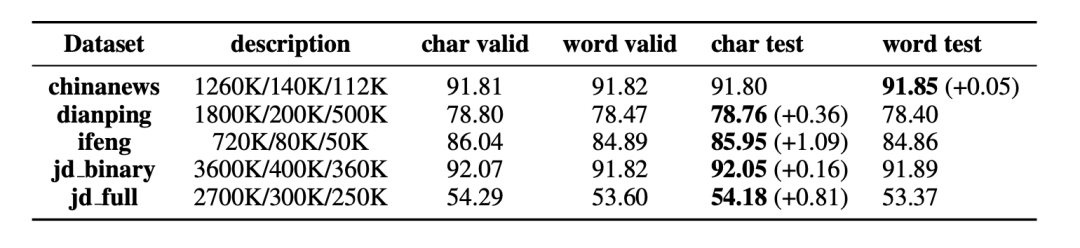
表7 文本分類任務的驗證和測試情況
領域適應能力
模型的領域適應能力展現了模型基于對已有數據分布(源領域)的訓練,學習新數據分布(目標領域)的能力。作者基于不同的情感分析數據庫對兩種模型進行了評測,結果如表8所示。可以發現,基于字符的模型具有更強的領域適應能力,且表現更優。
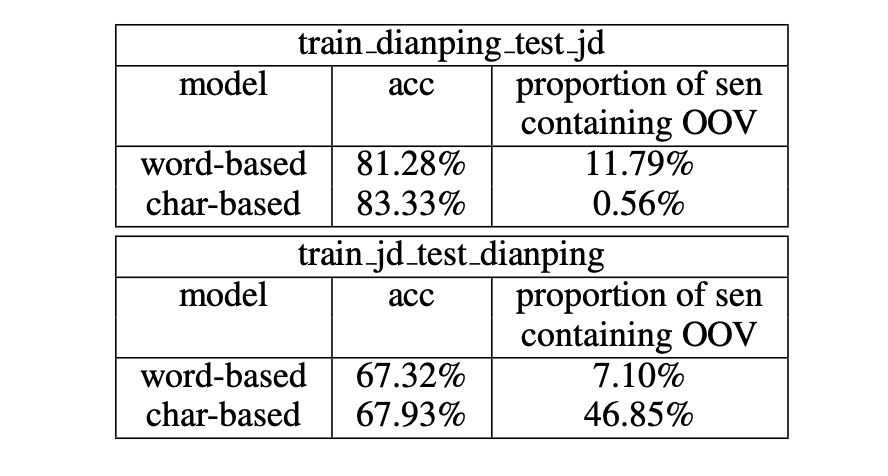
表8 基于字符的模型和基于詞語的模型的領域適應能力
四、分析
在這一部分,作者探究了 char model 效果優于 word model 的原因,盡管未能完全指出基于詞語的模型的運行機制,但作者嘗試分析了幾個主要的影響因素。
4.1 數據稀疏性
防止詞規模過大的常用方法是設置詞頻率的閾值,并使用 UNK 字符替代所有未達到閾值的詞語。閾值的設置對詞規模的大小有直接影響,并進一步影響了模型參數的數量。圖2展示了詞匯量、頻率閾值以及模型效果之間的聯系。無論是char模型還是model模型,當詞規模過大,模型效果都會明顯下降。模型對于低頻詞的語義的學習是存在困難的。因此,要獲得較好的基于詞語或字符的模型訓練效果,必須保證詞語或字符的出現頻率。但對于word模型,這一條件更難以達到。
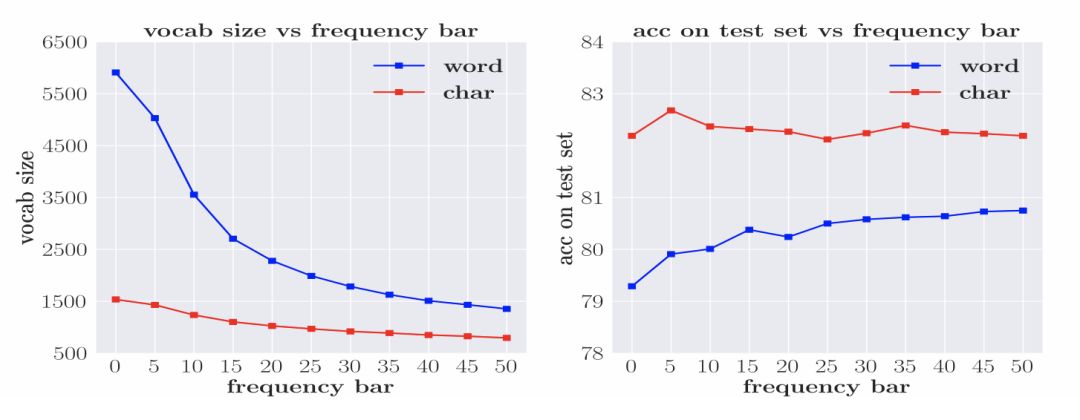
圖2 數據稀疏性對基于詞語和基于字符的模型的影響
4.2OOV
對word model來說,OOV是另一重要影響因素。但考慮到簡單降低詞頻率的閾值以減少OOV,會使數據稀疏問題更加嚴重,因此本文采用了一個替代性策略,即基于不同的詞頻率閾值,分別移除驗證集和測試集中包含OOV的句子。圖4展示了訓練集詞匯數量、準確度和詞頻率閾值間的關系。隨著詞頻率閾值的增加,兩種模型效果的差異在逐漸減小。
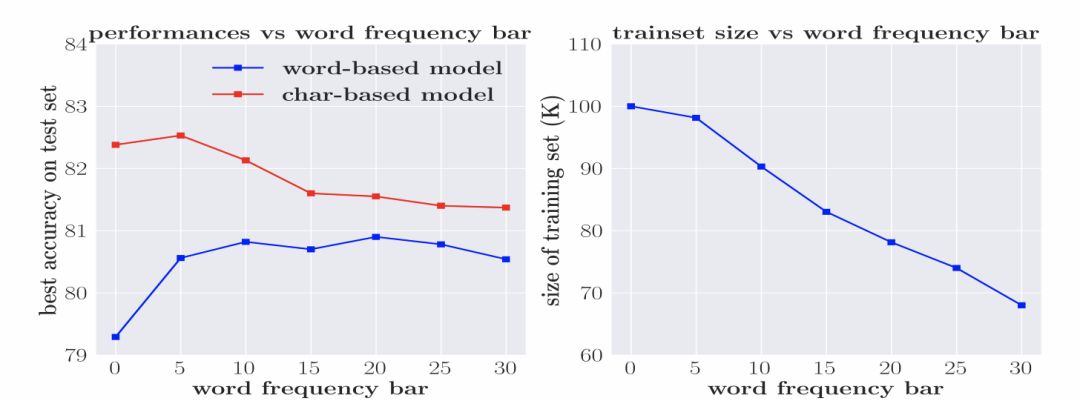
圖4 移除包含OOV的訓練實例帶來的影響
4.3 過擬合
數據稀疏導致模型需要學習的參數增加,使得模型更加容易過擬合。本文在 BQ 數據集上進行了實驗,結果如圖1所示。要獲得與基于詞語的模型相似的效果,基于詞語的模型需要設置更高的 dropout 值。
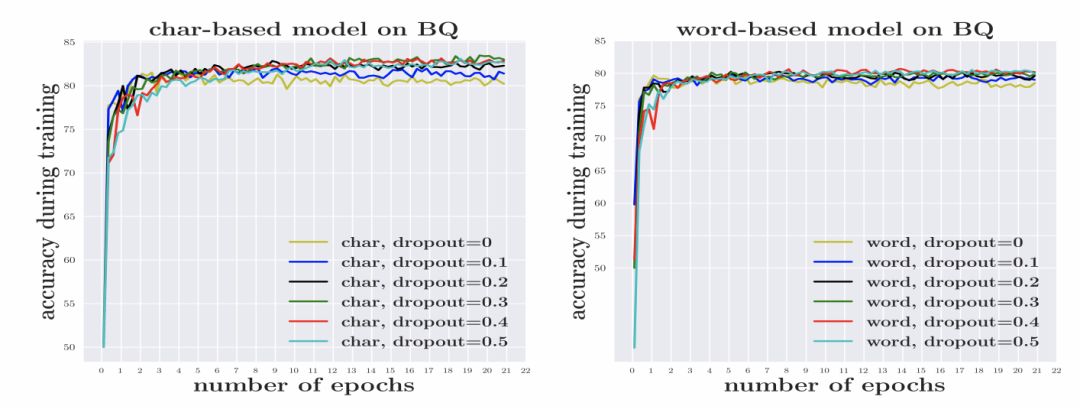
圖1 dropout 對基于詞語和基于字符的模型的影響
4.4 可視化
圖3 展示了char model在 BQ 數據集上獲得更好的語義匹配效果的原因。該熱圖展示了 BiPMP 計算出的兩句子間的注意力匹配值。對于char model而言,句子間的映射更加容易。
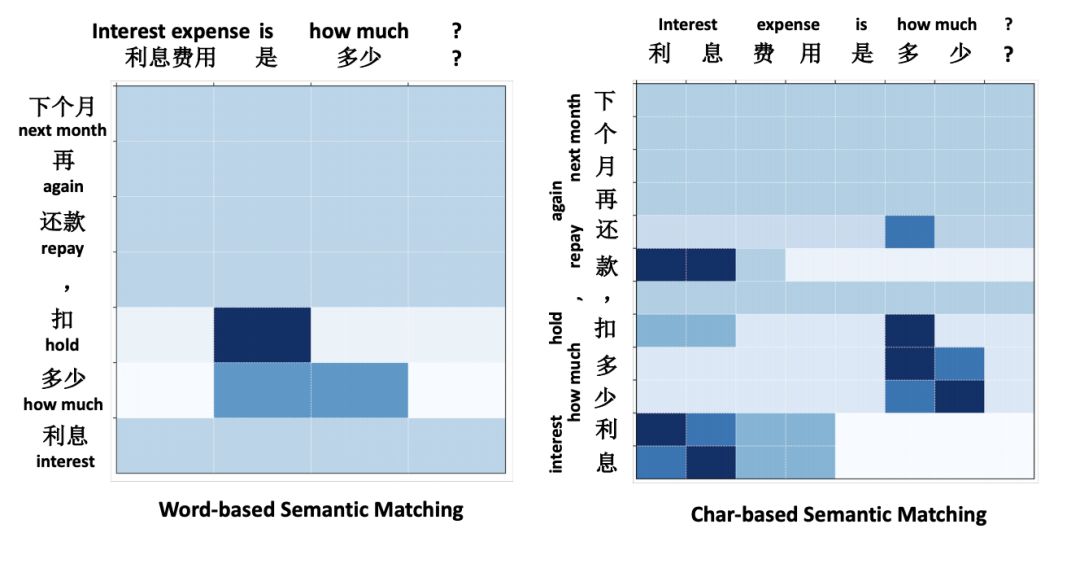
圖4 基于詞語和基于字符的模型對兩個中文語句的語義匹配情況
五、結論
這項研究探究了基于深度學習方法中文 NLP 任務中,分詞的必要性這一基礎性問題,并在四類端到端自然語言處理任務上發現char 模型效果更優于 word 模型。本文認為,word模型效果不佳的原因在于OOV、數據稀疏導致的過擬合和領域轉換能力差問題。也希望這篇論文可以啟發更多針對中文分詞必要性的探討工作。
-
神經網絡
+關注
關注
42文章
4762瀏覽量
100541 -
機器翻譯
+關注
關注
0文章
139瀏覽量
14873 -
深度學習
+關注
關注
73文章
5492瀏覽量
120978
原文標題:中文NLP的分詞真有必要嗎?李紀為團隊四項任務評測一探究竟 | ACL 2019
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
詳解深度學習、神經網絡與卷積神經網絡的應用






 工商網監
工商網監
評論