 Batch Norm的工作原理2018年被MIT的研究人員推翻
Batch Norm的工作原理2018年被MIT的研究人員推翻
Batch Normalization在2015年被谷歌提出,因為能夠加速訓練及減少學習率的敏感度而被廣泛使用。
但論文中對Batch Norm工作原理的解釋在2018年被MIT的研究人員推翻,雖然這篇論文在2018年就已經提出了,但是我相信還有很多人和我一樣,在網上看相關博客及paper時,大部分內容還是論文提出前寫下的。
現在DL逐漸變成了實驗科學,一般在發現性能上的提升后去分析其產生的原因,但這片論文的思想很好,從數據、公式等一系列角度去推理,分析出來了為什么batch Normalization能work。
batch Normalization的提出
拋開Norm,我們在做特征工程時,經常會將輸入進行歸一化,否則如果某個特征數特別大(比如說一個特征是0-1,一個特征是0-1000),那第二個特征很有可能會對整個模型參數造成很大的影響。或者說,當訓練集數據的分布不一致時,例如前一個輸入的各特征范圍是0-1,后一個是0-100,網絡的訓練效果也不會很好。
所以,就像很多人說的一樣,我們希望在deep learn中,整個網絡中流過的數據都是獨立同分布的。
為什么需要獨立同分布?
我覺得這事可以從兩方面去解釋,
一方面我們希望對訓練集進行訓練后,在測試集上能夠發揮很好的性能。那么我們就需要保證訓練集和測試集是來自同一個空間,準確來說,是符合同一分布,這對同分布提出了要求。此外,在雖然數據來自同一個空間,但我們并不希望所有數據都聚集在空間中的某一小撮,而是希望所有數據對于整個空間來說都具有一定代表性,因此在采樣的過程中我們希望是獨立得去采樣所有的數據。
另一方面,其實是從另一個角度來闡述上一段話,如果數據之間不是同分布的,比如說樣本1所有的特征都處于0-1之間,樣本2處于10-100,那么網絡的參數其實很難去同時迎合兩類分布的數據。
batch Normalization做了什么?
上面講到了數據在最初進來的時候,都希望是獨立同分布的。但是batch Normalization的作者覺得不夠,應該在deep learning中的每層都進行一次處理,保證在每層都是同分布。
他是這么想的:假設網絡有n層,網絡正在訓練,還沒有收斂。這時候x1被輸入,經過了第一層,但是第一層還沒有學到正確的weight,所以經過weight的矩陣乘法后,第二層的數會不會很亂?會不會第二層有些節點值是個位數,有些節點值蹦到好幾百?細想一下,確實挺有可能啊,內部的參數都是隨機初始化的,那蹦啥結果確實不好說啊。然后恐怖的事情來了,第二層這些亂蹦的數,又輸到了第三層,那第三層的輸入就是亂蹦的數,輸出當然好不了,以此類推。
所以主要產生了兩個問題:
1.所以在前面的網絡沒有收斂的時候,后面的網絡其實并學不到什么。一棟大樓底部都是晃的,那上面也好不了。所以必須要等前面的層收斂后,后面層的訓練才有效果。
2.因為一般來說網絡內部每層都需要加一層激活來增加非線性化嘛,那么如果值比較大,它通過激活以后在S曲線上會比較接近0或1,梯度很小,收斂會很慢。
所以batch Normalization就想在每層都加一個norm進行標準化,讓每層的數分布相同,變成均值0,方差1的標準分布。高斯分布的標準化公式就是下面式子中括號內的部分。值減去均值再除以方差,能夠得到均值為0,方差為1的標準正態分布。至于γ和β,是需要學習的兩個參數,γ對數據的方差再進行一個縮放,β對數據的均值產生一個偏移。
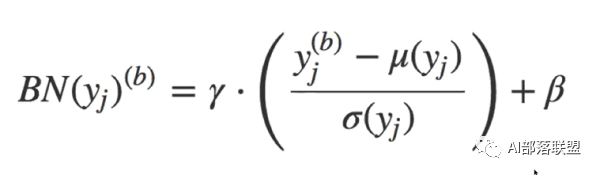
為什么歸一化成均值0,方差1后,還要再修改方差和均值?那歸一化還有意義嗎?
這是因為我們并不能保證這層網絡學到的特征是什么,如果簡單的歸一化,很有可能會被破壞。比如說S型激活函數,如果這層學到的特征在S的頂端那塊,那么我們做歸一化以后,強行把特征帶到了S的中間位置,特征就被破壞了。要注意γ和β是被訓練的參數,且每層都不一樣,所以針對每一層的實際情況,它會去嘗試恢復這層網絡所學到的特征。
結果
使用VGG網路,CIFAR10數據集(下圖),可以看到與不加相比:
1.訓練前期的準確率要高,也就是收斂更快。
2.減少對learning rate的敏感度,圖二在lr=0.5時,不加norm的網絡直接震蕩了,但加nrom的仍然表現良好。
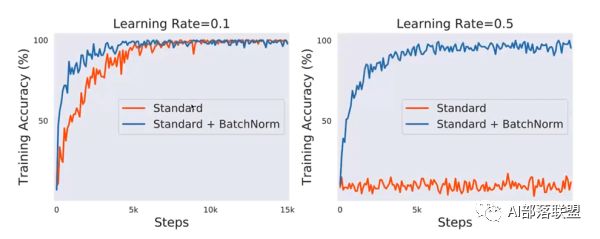
所以batch normalization其實原理不是很高深,只是在每層都加了一個標準化,使得數據同分布,再對其方差和均值進行一個變換以恢復該層捕捉到的特征。最后產生了兩大改變,首先收斂更快,其次對lr的敏感度降低。
那網絡內每層進行一個歸一化,為啥這么簡單的一個思想,一直沒有被運用呢?是researcher想不到嗎?
我相信有很多researcher都嘗試過將各層都重新標準化,但我相信最后的效果一定不太好,因為很多特征重新修改為均值0方差1后,特征的信息會被丟失。所以作者理論的突破性在歸一化以后又使用γ和β重新將數據的分布進行了一個修改,以此來找回丟失的特征,當然了,只要讓這兩個參數能夠自學習就可以了。
其實現在大部分博客沿用的解釋,都是上面這種。包括我之前一直也認為是這樣。
但是《How Does Batch Normalizetion Help Optimization》這篇論文認為,使用norm后的網絡收斂更快,lr敏感度更低是對的,但不是因為論文里說的這種原因,而是因為每層的標準化使得最后的loss函數變成了一個光滑的曲面而造成的最后性能提優。下面來闡述一下思想:
batch Normalization 解釋的反駁
實驗測試
MIT的研究人員并沒有在論文的一開始就提出了自己的解釋。而是說,如果原作者說的是對的,那我們就先按照原作者的思路去驗證一下(因為涉及兩篇paper,所以本文將batch normalization的提出者寫為原作者,How Does Batch Normalizetion Help Optimization的作者寫為來自MIT的研究人員):
原作者認為是因為網絡中各層都標準化后使得分布相同,因此造成的性能提優。
來自MIT的研究人員做了三個實驗作為對比:不適使用norm的普通網絡、使用nrom的普通網絡及添加噪音的Norm網絡。
Norm網絡添加噪音是考慮到原作者認為是同分布造成的性能提優。那么來自MIT的研究人員就在Norm網絡的基礎上,給各層再手動添加噪音,這樣使得第三個網絡雖然使用了norm,但每層的分布已經被打亂,不再滿足同分布的情況。
下圖中的實驗結果表明,即使nrom網絡添加了噪音,但性能仍然和添加norm的網絡差不多。
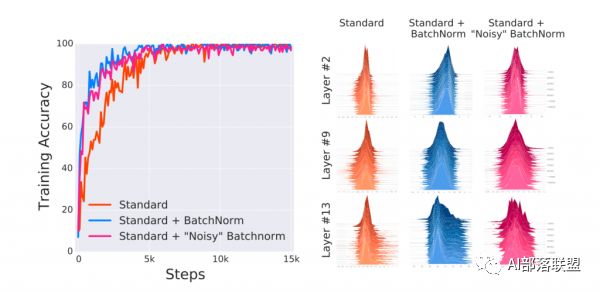
那么最后造成性能提升的原因,肯定不是數據同分布這一解釋,也就是說原作者給出的解釋是錯的,一定有其他的原因。
batch Normalization新解釋的直觀理解
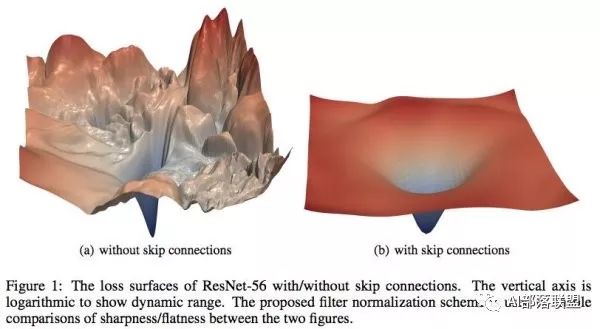
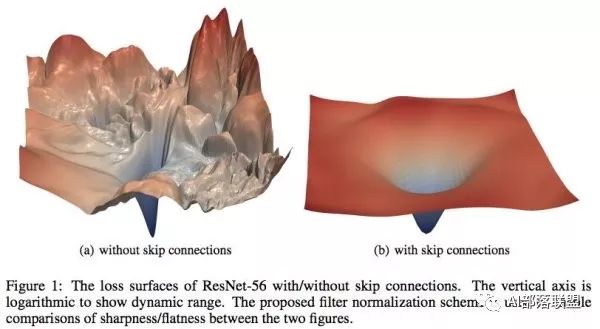
在基礎的學習中,我們都知道在設計loss的時候希望loss函數是光滑的,這樣我們可以很順利地使用梯度下降來更新參數并找到一個較優點。但很多時候loss并不是我們想象中的那么美好。比如說下圖,左邊和右邊都是loss函數,但是左邊的loss雖然連續,但并不光滑。在梯度下降過程中很難保證下降的有效性和快速性,此外也很容易陷入局部最優解。而右邊的圖雖然在四個頂點出也有局部最優解,但總體上來說還是非常理想的一個loss。
MIT的研究人員認為batch normalization的有效性在于它將左邊的原始loss轉變成了右邊的loss,造成了上文提到的兩種結果:
1.收斂速度變。
2.對學習率的設置不再那么敏感。
分析
MIT的研究員定義了兩個函數:
第一個是loss的值的計算,就是下面第一個公式,內部的loss是當前的loss,隨后對loss求導,再乘以學習率,x是內部的參數,對參數進行一個更新,隨后將新參數放入loss函數中,計算當前loss的值。別看這個公式看起來有點繞,實際上就是求當前的loss值。
第二個公式是計算loss的梯度差,也可以看成loss的二次求導吧(我感覺)。
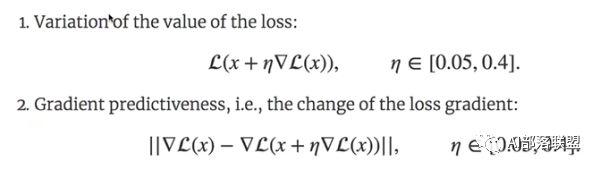
論文中之所以提出這兩個公式,是為了得到兩個量。
第一個公式可以得到訓練過程中的loss,那么把每一個step的loss都拿出來繪制成一條曲線,該曲線可以認為是loss的波動情況。我認為如果一個loss函數本身是比較光滑的,那么第一個公式求出來的loss值并不會有一個比較大的浮動。
第二個量是計算loss的梯度差,它可以認為山坡在沿著下降的方向走時,方向改變是否會較大。也就是說,一個比較好的loss函數,在每一個step中,loss所得到的梯度應該是不會浮動太大的。就好像從山上往下走,我們向下的方向一般都不會在瞬間改變太大,而不是說往下平滑地走著走著(loss梯度穩定),突然前面是個懸崖(loss梯度驟變),而應該是有個臺階(loss梯度平滑改變)。
MIT研究人員將使用norm和普通的網絡對這兩個量進行了對比:
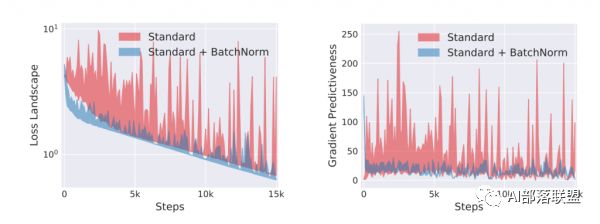
可以看到不使用norm的網絡(紅色),loss的梯度差浮動均較大。而使用了norm的網絡(藍色)浮動很小。也就從側面印證了普通網絡的loss比較趨向于左圖。而使用了norm的,loss趨向右圖。
上面這兩個公式其實就是整篇論文的核心,MIT的研究人煙也正是基于這兩個量從而對原文進行了反駁。
1.在論文中使用了L-Lipschitz常數來定量loss的光滑程度(也就是公式1干的事),限制了loss的光滑程度,(以下定義來自百度百科)
L-Lipschitz:直覺上,利普希茨連續函數限制了函數改變的速度,符合利普希茨條件的函數的斜率,必小于一個稱為利普希茨常數的實數(該常數依函數而定)。對于在實數集的子集的函數
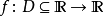
,若存在常數K,使得
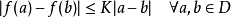
,則稱 f 符合利普希茨條件,對于f 最小的常數K 稱為 f 的利普希茨常數。
我個人覺得就是換了種說法,就是限制loss的一階導數要小于常數k。一階導數在曲線上表現的是斜率必須小于一個值,也就是說斜率不能過大。在這一條件的限制下,loss的面哪怕下降,也是很緩的。
2.論文使用了另一個更強的光滑條件來限制:β-smoothness(也就是公式2干的事)。
β-smoothness限制了就是loss斜率的斜率(可以簡單看成斜率差)不能超過一定值。
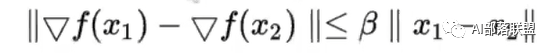
我認為這本質上其實就是二階求導。對二階求導后的結果進行了一個限制,使得函數在二階條件下仍然是一個較為平滑、不會大幅度突變的函數。
也正是因為使用了batch norm的網絡,它的loss從原先的原始凹凸不平狀態變成了一個能滿足L-Lipschitz及β-smoothness兩個強條件的原因,使得bath norm能夠work。
總結
原作者提出了batch norm,并造成了兩個結果:
1.收斂更快。
2.對learning rate的敏感度更低(也就是說lr的設置是否合理不會很大程度地影響最終結果)。
并且認為網絡中每層都進行了一次同分布,是造成結果的主要原因。
MIT研究員根據這一思路,將使用norm的網絡隨機添加高斯噪聲,使得網絡在添加了norm的同時又去除了norm所帶來的同分布效果,但結果顯示優勢仍然存在,因此對原作者的解釋進行了反駁。
隨后MIT研究人員使用了loss的一階信息和二階信息進行了評估,發現使用了norm以后的loss在一階和二階上都具有很好的性質,由此推斷nrom之所以能產生效果,不是原作者提出的解釋,而是因為norm直接作用了loss函數,將loss函數變成了一個一階、二階均平滑的函數。
-
MIT
+關注
關注
3文章
253瀏覽量
23312 -
paper
+關注
關注
0文章
7瀏覽量
3709
原文標題:論文閱讀|How Does Batch Normalization Help Optimization
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
MIT 認為現有的電動車就能取代美國 87%的燃油車,里程焦慮被過分夸大
泰克儀器助力研究人員首次通過太赫茲復用器實現超高速數據傳輸
福州大學研究人員撰文質子交換膜燃料電池工作原理
Facebook向研究人員發布友誼數據
研究人員已經使用機器學習來開發血液測試
AI研究人員如何應對透明AI
蘋果啟動安全研究設備計劃 為安全研究人員提供越獄iPhone
研究人員開發了一種基于深度學習的智能算法
batch normalization時的一些缺陷
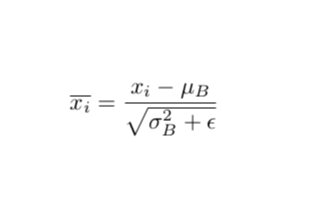
MIT/三星研究人員利用活體拉曼光譜直接觀察葡萄糖指紋圖譜






 工商網監
工商網監
評論