 電子發燒友App
電子發燒友App


??? 關鍵詞:漢字庫,單片機,液晶顯示
1 便攜式設備的常用設計方法
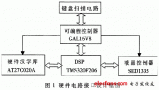
一般的便攜式設備采用如圖1所示的電路框圖設計(根據需要可增可減)。在該系統中,用圖形點陣液晶模塊作為顯示,24C256用作漢字庫的存儲,X1203用于日歷時鐘,鍵盤/觸摸屏作為輸入設備,RS232用于通訊,ISD系列語音芯片可以記錄語音及播放語音。這里只討論使用點陣液晶顯示漢字的情況以及漢字庫的設計方法。一般漢字庫有以下幾種方案實現。
(2)使用大容量的ROM芯片專門做漢字庫。用這種方式可以使用全部的國標漢字,是一種較常用的方法。一般采用27C040芯片,但占用系統I/O數較多,占印刷板面積大,單是27C040就需要19根地址線,8根數據線,還有一些控制信號,還可能需要一片地址鎖存芯片。這種方法在便攜式設備的設計時一般不采用。
??? (3)使用自帶漢字庫的液晶模塊。這較為方便,但成本較為高昂,一般為固定規格的漢字,常用的是16×16點陣,使用不靈活。
(4)使用I2C器件實現漢字庫的設計。下面將詳細討論這種方法。
2 設計綜述
用串行I2C方式的EEPROM實現漢字庫設計,這種方式下系統的構成成本低廉,體積小巧,方便靈活。在圖1的設計中,使用128×64點陣規模的常用液晶模塊,可以顯示12×12點陣的漢字5排,每排10個漢字。使用了一片24C512做漢字庫,它有64K字節的存儲空間,可以存放64K/24=2 730個漢字的12×12點陣字模。如果采用壓縮的方法,每個12×12點陣的漢字占用18個字節,則可存放64K/18=3 640個漢字。如果使用兩片則可以容納7 280個漢字,而使用多片時同樣占用兩根口線,且不額外占用資源,同時還可以連接其他的I2C器件,如日歷芯片、I2C方式的A/D、D/A等,如果24Cxxx還有空余空間,則可以作為記錄器,記錄數據。在實際應用時,我們使用尺寸小的液晶模塊(50 mm×40 mm×3 mm),這樣,整個電路除鍵盤外全蓋在液晶模塊的下面,如果使用液晶上的觸摸屏作為鍵盤,則所有電路的大小可以與液晶屏的尺寸一樣,整個系統相當小巧,非常適合掌上設備或其他便攜式設備應用。
如果使用其他方式實現漢字庫,則體積將會較大:使用程序空間做字庫,則只能實現很少的漢字字模,而ROM尺寸小的芯片還不能實現;若用27C040等則體積肯定大;使用帶字庫的模塊則厚度較大。
24C512芯片與MCU接口只占用兩根I/O口線:SDA,SCL。因此,隨便使用89C51的I/O連接即可,見圖1(注意:需要10kΩ的上拉電阻),多片時只是在每一片的地址端加以區別,而不需要額外的I/O口線。
3 設計方法
3.1 漢字字模數據
下面以“使用此漢字庫”為例說明字模點陣的形成情況。液晶屏的“使用此漢字庫”是按如圖2所示的方式一點一點地顯示的。圖中的每一點對應液晶屏上的每一點。我們只須將所有的點陣數據寫入液晶模塊的緩沖區就可以了。
常用的12864液晶模塊使用HD61202作液晶控制器,所以,該模塊是豎著取模的(由HD61202所決定),而且最高位在下面(請參見HD61201的詳細資料)。所以“漢”的字模數據為:
這里,以“漢”為例,第一個數據088H是最左邊的上面第一豎排有點的位置所對應的數據,而且下面為高位。第二個數據091H為左邊的上面第二豎排有點的位置所對應的數據,依次類推,得到“漢”上半部分的前12個點陣數據,同樣可以得到“漢”下半部分的后12個點陣數據。可以看出,在下半部分的字模,實質上只有一半數據有用,另一半全是0,故,可以采用壓縮的辦法,縮減字模數據,即下半部分的點陣數據完全可以兩個數據縮減成一個數據。比如“漢”壓縮后的字模數據為,上半部分不變,前12個數據與原來相同,下半部分兩兩組合為一個字節,后半部分只有6個字節,這樣,一個漢字就只需要18個字節,這樣可以大大節省存儲器的使用:
088H,091H,064H,018H,002H,01EH,062H,082H,062H,01FH,002H,000H,00FH,008H 084H,021H,024H,088H
如果液晶模塊所使用的控制器是6963或1330/1335等,則必須橫著取字模,相應的“漢”的字模數據為(每字節右邊為高位):
DB 000H,002H,0F2H,007H,024H,002H,029H,002HDB 02AH,002H,044H,001H,044H,001H,083H,000HDB 082H,000H,042H,001H,022H,002H,01AH,00CH
壓縮算法與61202的不一樣,為左邊不變,右邊壓縮,數據組織上為奇數(對應點陣的右半邊)壓縮,偶數不變。
3.2 漢字字模數據存放在24Cxxx中
在一般情況下為自定義漢字庫,也有使用全漢字庫的情況。在全字庫的情況下,可以把現有的漢字庫直接存放在兩片24C512中(采用壓縮方法,每個漢字18字節)。這兩片的地址分別是:0-0FFFFH,10000H-1FFFFH。
??? 漢字首地址=((區碼-1)×94+位碼-1)×18。
大多數情況下使用漢字不會很多,一般用的是自定義漢字庫。用一片24C256芯片(見Atmel公司24C256技術手冊)可以存放用戶常用漢字1 820(32K/18)個,或1 365(32K/24)個,剩余空間可以用作數據記錄,對一般用戶來說足夠了。但放在程序ROM里,將占用32K程序區,對使用小ROM容量(比如89C2051,PIC系列,430F11x等)芯片的場合是不可能的,而用一片24Cxxx芯片就完全解決了,只占用兩根I/O口線!這么多數據怎么存放在24C256中呢?很簡單,使用編程器。大多數的編程器都支持24Cxxx的編程。先使用字模提取軟件得到你所需要的漢字的字模數據,一般情況在購買液晶時會附送的。一般情況會用匯編的DB偽指令來定義,或使用C語言的數組來定義:unsigned char code hzdot〔24*xxxx〕={0x12,0x32,......}。得到這些數據后,用相應的單片機編譯軟件得到編程器能用的.hex或.bin文件,再使用編程器燒寫。在用字模軟件取漢字模的時候,必須將漢字按照一定的順序進行排列,使用此漢字庫的時候再按照這個順序就可以將漢字依次顯示出來。
3.3 字模數據在24Cxxx中的存放情況舉例
用戶自定義的漢字庫已經存放在24Cxxx中了,下面是字庫中的開始部分,漢字“使用此漢字庫……”的字模,取模方式為縱向、下為高位,其中地址列為在24C256中的片內地址。
從表1與圖2可以看出,漢字字模在24C256中的存放規則:第一個漢字的字模數據放在24C256中從0000H開始的24個單元,即0000-0017H。第二個放在24C256中從0018H開始的24個單元,即0018H-002FH……,依次類推。每個漢字在字庫中的第一個字模數據在24C256中的地址為:X×24+0,(X為用戶漢字庫中的第幾個漢字)第二個字模數據在24C256中的地址為:X×24+1,第三個字模數據在24C256中的地址為:X×24+2,……,依次類推,用戶漢字庫中的第X個漢字的第I個字模數據為:
X×24+I。
由此,我們在液晶屏上顯示漢字的時候依次寫出X×24+I(I為00-23)就可以了。24Cxxx為I2C總線方式的EEPROM存儲器,用作漢字庫時,我們只需要掌握從中讀出數據的方法,寫入數據的工作就讓編程器去完成。下面介紹如何讀取漢字庫中的漢字信息。
4 24Cxxx漢字庫的使用
所需要的漢字庫已經存放在24Cxxx存儲器中了,只需要將它們取出來顯示在液晶屏上。下面舉例說明:在系統中需要1 300個漢字,使用24C256作為漢字庫,可以存放32 768/24=1 365個12×12點陣的漢字,能滿足要求。在使用中每一個漢字有一個唯一的編碼,序號從0000到1299。要寫某一個漢字在液晶屏上只需要給出它的編碼即可。
4.1 24C256的讀寫
24C256的讀寫遵循I2C總線的規約,需進行總線啟動、數據讀寫、應答信號查詢、總線停止等操作,這些子程序假設都已經有了,在程序中聲明如下:
4.2 將器件中的數據讀取出來在液晶屏上顯示
下面,我們在液晶屏的的第2行的開始顯示“使用此漢字庫”。先讀取連續的24個漢字點陣數據,程序如下:
這六個漢字在漢字庫中的編碼依次為:
0000 0001 002 0003 0004 0005,
則每一個漢字點陣數據的第一個位置分別為:
0000×24,0001×24,0002×240003×24,0004×24,0005×24
以每一個漢字的第一個數據位置為起始地址依次讀取24個數據到顯示緩存,再調用顯示程序(寫顯示緩存的數據到液晶模塊中)……。相應的程序如下:
2 徐愛鈞.單片機高級語言C51應用程序設計.北京:電子工業出版社,1998














 工商網監
工商網監
評論