 電子發燒友App
電子發燒友App


路由算法詳解
引言
如果您已經閱讀過博聞網中的路由器工作原理一文,您會了解到路由器的作用是管理網絡流量和找到發送分組數據包的最佳路由。但是您是否想過路由器是怎么做到這一點的?路由器需要一些網絡狀態的信息來決定如何發送分組數據包以及發往哪里。但是它是怎樣收集這些信息的?
在本篇博聞網文章中,我們將帶您詳細了解路由器需要哪些信息來決定往哪發送分組數據包。
路由器基礎知識
路由器使用路由算法來找到到達目的地的最佳路由。當我們說“最佳路由”時,我們考慮的參數包括諸如跳躍數(分組數據包在網絡中從一個路由器或中間節點到另外的節點的行程)、延時以及分組數據包傳輸通信耗時。
關于路由器如何收集網絡的結構信息以及對之進行分析來確定最佳路由,我們有兩種主要的路由算法:總體式路由算法和分散式路由算法。采用分散式路由算法時,每個路由器只有與它直接相連的路由器的信息——而沒有網絡中的每個路由器的信息。這些算法也被稱為DV(距離向量)算法。采用總體式路由算法時,每個路由器都擁有網絡中所有其他路由器的全部信息以及網絡的流量狀態。這些算法也被稱為LS(鏈路狀態)算法。我們將在下一節討論LS算法。
LS算法
采用LS算法時,每個路由器必須遵循以下步驟:
- 確認在物理上與之相連的路由器并獲得它們的IP地址。
當一個路由器開始工作后,它首先向整個網絡發送一個“HELLO”分組數據包。每個接收到數據包的路由器都將返回一條消息,其中包含它自身的IP地址。
- 測量相鄰路由器的延時(或者其他重要的網絡參數,比如平均流量)。
為做到這一點,路由器向整個網絡發送響應分組數據包。每個接收到數據包的路由器返回一個應答分組數據包。將路程往返時間除以2,路由器便可以計算出延時。(路程往返時間是網絡當前延遲的量度,通過一個分組數據包從遠程主機返回的時間來測量。)請注意,該時間包括了傳輸和處理兩部分的時間——也就是將分組數據包發送到目的地的時間以及接收方處理分組數據包和應答的時間。
- 向網絡中的其他路由器廣播自己的信息,同時也接收其他路由器的信息。
在這一步中,所有的路由器共享它們的知識并且將自身的信息廣播給其他每一個路由器。這樣,每一個路由器都能夠知道網絡的結構以及狀態。
- 使用一個合適的算法,確定網絡中兩個節點之間的最佳路由。
在這一步中,路由器選擇通往每一個節點的最佳路由。它們使用一個算法來實現這一點,如Dijkstra最短路徑算法。在這個算法中,一個路由器通過收集到的其他路由器的信息,建立一個網絡圖。這個圖描述網絡中的路由器的位置以及它們之間的鏈接關系。每個鏈接都有一個數字標注,稱為權值或成本。這個數字是延時和平均流量的函數,有時它僅僅表示節點間的躍點數。例如,如果一個節點與目的地之間有兩條鏈路,路由器將選擇權值最低的鏈路。
Dijkstra算法執行下列步驟:
- 路由器建立一張網絡圖,并且確定源節點和目的節點,在這個例子里我們設為V1和V2。然后路由器建立一個矩陣,稱為“鄰接矩陣”。在這個矩陣中,各矩陣元素表示權值。例如,[i, j]是節點Vi與Vj之間的鏈路權值。如果節點Vi與Vj之間沒有鏈路直接相連,它們的權值設為“無窮大”。
- 路由器為網路中的每一個節點建立一組狀態記錄。此記錄包括三個字段:
- 前序字段——表示當前節點之前的節點。
- 長度字段——表示從源節點到當前節點的權值之和。
- 標號字段——表示節點的狀態。每個節點都處于一個狀態模式:“永久”或“暫時”。
- 路由器初始化(所有節點的)狀態記錄集參數,將它們的長度設為“無窮大”,標號設為“暫時”。
- 路由器設置一個T節點。例如,如果設V1是源T節點,路由器將V1的標號更改為“永久”。當一個標號更改為“永久”后,它將不再改變。一個T節點僅僅是一個代理而已。
- 路由器更新與源T節點直接相連的所有暫時性節點的狀態記錄集。
- 路由器在所有的暫時性節點中選擇距離V1的權值最低的節點。這個節點將是新的T節點。
- 如果這個節點不是V2(目的節點),路由器則返回到步驟5。
- 如果節點是V2,路由器則向前回溯,將它的前序節點從狀態記錄集中提取出來,如此循環,直到提取到V1為止。這個節點列表便是從V1到V2的最佳路由。
這些步驟的流程圖如下:
|
|
示例:Dijkstra算法
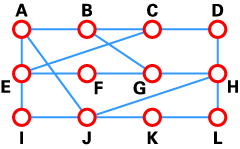
我們想找到A與E(下圖)之間的最佳路由。可以看到A與E之間有六條可能路徑(ABE、ACE、ABDE、ACDE、ABDCE、ACDBE),很明顯ABDE是最佳路由,因為它的權值最小。但是實際情況并非總是如此簡單,有很多復雜的情形需要使用算法來找到最佳路由。
- 如下圖所示,源節點(A)被選為T節點,所以它的標號是永久(我們將永久性節點以實圈標注,T節點以-->符號標注)。
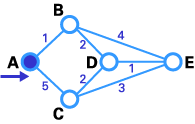
- 在這一步中,直接鏈接到T節點的暫時性節點(B, C)的狀態記錄集已經被修改。同時,由于B有更小的權值,所以它被選作T節點,其標號被改為永久(如下圖所示)。
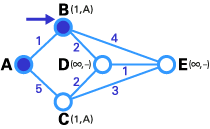
- 與步驟2類似,在這一步中,直接鏈接到T節點的暫時性節點(D, E)的狀態記錄集已經被修改。同時,由于D有更小的權值,所以它被選作T節點,其標號被改為永久(如下圖所示)。
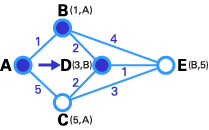
- 在這一步中,已經沒有任何暫時性節點,所以我們僅僅需要確認下一個T節點。因為E有最小權值,所以它被選作T節點。
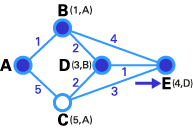
- E是目的節點,所以我們在這里停止。
我們已經到達了終點!現在,我們需要確定路由。E的前序節點是D,D的前序節點是B,B的前序節點是A。所以最佳路由是ABDE。在這個案例中,權值和為4(1+2+1)。
雖然這個算法工作良好,但是它非常復雜,以致于路由器需要花費大量時間進行處理,網絡的性能因此下降了。同樣,如果一個路由器將錯誤的信息發送給其他路由器,那么所有的路由決定都將是無效的。為了更好的理解這個算法,下面給出由C語言編寫的源代碼:
#define MAX_NODES 1024??????? /*最大節點數 */
#define INFINITY 1000000000????? /*比所有最大路徑都大的數 */
int n,dist[MAX_NODES][MAX_NODES];???? /*dist[I][j] 是從 i 到 j 的距離*/
void shortest_path(int s,int t,int path[ ])
{struct state {????????????????????????? /*當前計算的路徑 */
int predecessor ;???????????????????? /*前序節點 */
int length??????????????????????????????? /*從源節點到當前節點的長度*/
enum {permanent, tentative} label??? /*標號狀態*/
}state[MAX_NODES];
int I, k, min;
struct state *
???????????????????? p;
for (p=andstate[0];p < andstate[n];p++){?????? /*初始化狀態*/
p->predecessor=-1
p->length=INFINITY
p->label=tentative;
}
state[t].length=0; state[t].label=permanent ;
k=t ;????????????????????????????????????????????????????????? /* k 是初始工作節點 */
do{??????????????????????????????????????????????????????????? /*是從 k 開始的一條更好路徑么?*/
for I=0; I < n; I++)?????????????????????????????????????? /*圖有 n 個節點 */
if (dist[k][I] !=0 andand state[I].label==tentative){
??????????? if (state[k].length+dist[k][I] < state[I].length){
???????? state[I].predecessor=k;
???????? state[I].length=state[k].length + dist[k][I]
????? }
}
/*找到具有最小權值的暫時性節點。*/
k=0;min=INFINITY;
for (I=0;I < n;I++)
???? if(state[I].label==tentative andand state[I].length <
min)=state[I].length;
???? k=I;
?}
state[k].label=permanent
}while (k!=s);
/*將路徑復制到輸出數組*/
I=0;k=0
Do{path[I++]=k;k=state[k].predecessor;} while (k > =0);
}
DV算法
DV算法也被稱為Bellman-Ford路由算法和Ford-Fulkerson路由算法。在這些算法中,每個路由器都有一個路由表,用來表示到任何目的地的最佳路由。一個典型的路由器J的網絡圖以及路由表如下所示。
 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
如表格所示,如果路由器J想發送分組數據包到路由器D,它應該將分組數據包先發送到路由器H。分組數據包到達路由器H后,它將檢查自己的路由表來決定怎樣將分組數據包發送到路由器D。
在DV算法中,每個路由器遵循以下步驟:
- 計算所有與本身直接相連的鏈接的權值并且將信息保存到路由器的路由表中。
- 一段時間后,路由器將其路由表發送給相鄰路由器(不是所有的路由器),同時也收到每個相鄰路由器的路由表。
- 根據其相鄰路由器的路由表信息,路由器更新自己的路由表。
DV算法的一個最主要的問題是“無窮計數”。讓我們通過一個例子來研究一下這個問題:
假設一個網絡圖如下所示。如圖所示,A與網絡的其他部分只有一條鏈路。所有節點的路由表以及網絡圖如下所示:
 |
|
|
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
網絡圖和路由表
現在假設A 、 B之間的鏈路被剪斷了。在這個時候,B修正了自己的路由表。經過一段時間后,路由器交換它們的路由表,因此B接收到了C的路由表。因為C不知道A 、B之間的鏈路上發生了什么事,所以它說它有一條權值為2的到A的鏈路(從C到B權值為1,從B到A權值為1——它不知道B已經沒有到A的鏈路了)。B接收到路由表之后認為有另外一條鏈路從C到A,所以它修正了自己的路由表,即將無窮大更改為3(C認為,B到C權值為1,C到A權值為2)。路由器然后再一次交換它們的路由表。當C接收到B的路由表后,它發現B到A的鏈路權值從1更改為3,所以C更新了它的路由表,即將它到A的鏈路權值更改為4(根據B的描述,C到B權值為1,B到A權值為3)。
這個循環過程到最后,所有的節點發現到A的鏈路權值變成無窮大。這個情形如下表所示。因此,專家稱DV算法具有低收斂率。
|
|
|
| |
| 鏈接剪斷之后到A的權值之和 |
|
|
|
| 第一次更新后到B的權值之和 |
|
|
|
| 第二次更新后到A的權值之和 |
|
|
|
| 第三次更新后到A的權值之和 |
|
|
|
| 第四次更新后到A的權值之和 |
|
|
|
| 第五次更新后到A的權值之和 |
|
|
|
| 第n次更新后到A的權值之和 |
|
|
|
|
|
|
|
“無窮計數”問題
解決這個問題的一種方法是,路由器只發送信息給相鄰路由器,且該相鄰路由器不是通往目的地的唯一鏈接。比如在這個例子中,C就不應該發送任何關于A的信息給B,因為B是通往A的唯一路徑。










 工商網監
工商網監
評論