 電子發(fā)燒友App
電子發(fā)燒友App


互聯(lián)網(wǎng)搜索引擎工作原理
1. 引言 2. 聚焦萬(wàn)維網(wǎng) 3. 建立索引 4. 建立搜索 5. 未來(lái)的搜索有關(guān)互聯(lián)網(wǎng)和它最引人注目的部分——萬(wàn)維網(wǎng)的好消息是,網(wǎng)上有無(wú)數(shù)網(wǎng)頁(yè)提供主題極為多樣的信息。壞消息是,這些網(wǎng)頁(yè)大都是由制作者隨便命名的,而且?guī)缀跞即鎯?chǔ)在不知何名的服務(wù)器上。當(dāng)你需要了解特定主題時(shí),您怎么知道應(yīng)當(dāng)閱讀哪些網(wǎng)頁(yè)呢?像大多數(shù)人一樣,您要使用互聯(lián)網(wǎng)搜索引擎。
互聯(lián)網(wǎng)搜索引擎是萬(wàn)維網(wǎng)中的特殊站點(diǎn),專門用來(lái)幫助人們查找存儲(chǔ)在其他站點(diǎn)上的信息。盡管各種搜索引擎的工作方-式有所不同,但它們都要完成三個(gè)基本任務(wù):
- 基于關(guān)鍵字來(lái)搜索互聯(lián)網(wǎng)——或其中的一部分。
- 生成一份索引,保存所搜尋的詞語(yǔ),以及相應(yīng)地址。
- 允許用戶在索引中查找詞語(yǔ)或詞語(yǔ)組合
早期搜索引擎的索引僅包括數(shù)十萬(wàn)個(gè)的網(wǎng)頁(yè)或文檔,每天受理的查詢可能只有一兩千次。如今,頂級(jí)搜索引擎的索引列表涵蓋數(shù)億個(gè)網(wǎng)頁(yè),每天響應(yīng)數(shù)千萬(wàn)次查詢。在本文中,我們將會(huì)講解這些基本任務(wù)是如何完成,以及互聯(lián)網(wǎng)搜索引擎是如何整合信息以幫助我們?cè)诰W(wǎng)上找到所需內(nèi)容。
聚焦萬(wàn)維網(wǎng)
大多數(shù)人談及互聯(lián)網(wǎng)搜索引擎時(shí),實(shí)際上指的是萬(wàn)維網(wǎng)搜索引擎。在萬(wàn)維網(wǎng)成為互聯(lián)網(wǎng)最引人注目的部分之前,早就有搜索引擎幫助人們查找網(wǎng)上信息了。如“gopher”和“Archie”等程序可以生成索引,存儲(chǔ)在接入互聯(lián)網(wǎng)的各個(gè)服務(wù)器上的文件信息,極大縮短了查找程序和文檔的時(shí)間。上世紀(jì)八十年代末,要想從互聯(lián)網(wǎng)上獲得有價(jià)值的信息,就必須知道如何使用 gopher、Archie、Veronica以及其它類似程序。
現(xiàn)在,大多數(shù)互聯(lián)網(wǎng)用戶只限于搜索萬(wàn)維網(wǎng),所以本文只討論面向網(wǎng)頁(yè)內(nèi)容的搜索引擎。
小蜘蛛開始行動(dòng)
搜索引擎在有能力告訴你文件或文檔存儲(chǔ)在何處之前,必須先找到它們。為了在現(xiàn)有的數(shù)億網(wǎng)頁(yè)中找到信息,搜索引擎使用了一種特殊的軟件機(jī)器人,稱之為蜘蛛程序,以此生成在網(wǎng)站上查詢到的詞語(yǔ)列表。蜘蛛程序建立詞語(yǔ)列表的過(guò)程被稱為爬網(wǎng)。(將互聯(lián)網(wǎng)的一部分稱為網(wǎng)絡(luò)有些缺點(diǎn)——大量工具以蜘蛛命名就是其一。)為了建立并維護(hù)一份有用的詞語(yǔ)列表,搜索引擎的蜘蛛程序需要游歷大量網(wǎng)頁(yè)。
蜘蛛程序如何開始其網(wǎng)上旅程?通常起點(diǎn)是那些訪問(wèn)量很大的服務(wù)器和熱門網(wǎng)頁(yè)。蜘蛛程序從一個(gè)很受歡迎的網(wǎng)站開始,檢索網(wǎng)頁(yè)上的詞語(yǔ)并追蹤在該網(wǎng)站上找到的每個(gè)鏈接。這樣,蜘蛛程序迅速開始了旅行,爬遍網(wǎng)上絕大多數(shù)經(jīng)常訪問(wèn)的網(wǎng)站。
|
為了方便在線用戶找到所需網(wǎng)頁(yè), 蜘蛛程序提取網(wǎng)頁(yè)內(nèi)容并設(shè)立搜索關(guān)鍵字。 |
Google的前身是一個(gè)學(xué)術(shù)搜索引擎。在介紹該系統(tǒng)開發(fā)過(guò)程的論文中,google創(chuàng)始人塞吉·布林(Sergey Brin)和勞倫斯·佩奇(Lawrence Page)舉例說(shuō)明了他們的蜘蛛程序工作得有多快。他們最初開發(fā)的系統(tǒng)使用多個(gè)蜘蛛程序——通常是三個(gè)。每個(gè)蜘蛛程序可以同時(shí)打開300個(gè)鏈接。最多可以同時(shí)使用四個(gè)蜘蛛程序,此時(shí)該系統(tǒng)每秒可以游歷100多個(gè)網(wǎng)頁(yè),生成大約600KB的數(shù)據(jù)。
要保證一切都快速運(yùn)行,意味著必須開發(fā)一套系統(tǒng)來(lái)為蜘蛛程序提供必要信息。早期Google系統(tǒng)有一個(gè)專門為蜘蛛程序提供鏈接信息的服務(wù)器。為了盡可能減少延時(shí),Google沒(méi)有依靠互聯(lián)網(wǎng)服務(wù)提供商提供的域名服務(wù)器(DNS)來(lái)將服務(wù)器名翻譯為網(wǎng)址,而是準(zhǔn)備了自己的域名服務(wù)器。
當(dāng)Google的蜘蛛程序訪問(wèn)一個(gè)HTML網(wǎng)頁(yè)時(shí),它會(huì)記錄以下兩種信息:
- 網(wǎng)頁(yè)中的詞語(yǔ)
- 詞語(yǔ)所在位置
出現(xiàn)在標(biāo)題、副標(biāo)題、元標(biāo)記以及其他相對(duì)重要的位置的詞語(yǔ),會(huì)被記錄下來(lái),這些詞語(yǔ)往往是日后用戶搜索時(shí)經(jīng)常使用的。Google蜘蛛程序的設(shè)計(jì)旨在檢索網(wǎng)頁(yè)中的每一個(gè)重要單詞(對(duì)于英文來(lái)說(shuō),還要濾掉冠詞a、an和the等)。其他蜘蛛程序采用不同的方法。
這些方法通常是為了盡量加快蜘蛛程序的速度,或使用戶可以更有效地進(jìn)行搜索,或二者兼而有之。例如,有些蜘蛛程序會(huì)追蹤標(biāo)題、副標(biāo)題和鏈接中的詞語(yǔ),以及網(wǎng)頁(yè)中最常用的100個(gè)詞和文章前20行中的每一個(gè)詞。據(jù)說(shuō)Lycos就是使用這種方法爬網(wǎng)的。
其他系統(tǒng),如比AltaVista,則反其道而行之,檢索網(wǎng)頁(yè)中的每一個(gè)字,包括a、an、the以及其他“不重要”的詞。人們完善這種方法的干勁從未減弱,而另一些系統(tǒng)則通過(guò)其它方法與之抗衡。比如關(guān)注網(wǎng)頁(yè)的不可見(jiàn)部分,即元標(biāo)記。
元標(biāo)記
元標(biāo)記允許網(wǎng)頁(yè)所有者來(lái)設(shè)定檢索網(wǎng)頁(yè)的關(guān)鍵字或概念。這很有用,特別是在網(wǎng)頁(yè)中的詞語(yǔ)有多個(gè)含義的時(shí)候——元標(biāo)記可以引導(dǎo)搜索引擎在這些詞的幾種可能含義中選擇正確的一項(xiàng)。但是,過(guò)分依賴元標(biāo)記有一個(gè)危險(xiǎn):粗心或不負(fù)責(zé)任的網(wǎng)頁(yè)所有者會(huì)添加一些對(duì)應(yīng)熱門話題的元標(biāo)記,但是與網(wǎng)頁(yè)實(shí)際內(nèi)容沒(méi)有任何關(guān)系。為了防止此種事情發(fā)生,蜘蛛程序會(huì)比對(duì)元標(biāo)記和網(wǎng)頁(yè)內(nèi)容,剔除那些與網(wǎng)頁(yè)詞語(yǔ)不符的元標(biāo)記。
上述方法均基于一個(gè)假設(shè),也就是網(wǎng)頁(yè)所有者希望自己的網(wǎng)頁(yè)被納入搜索引擎的搜索列表。但有些情況下,網(wǎng)頁(yè)所有者并不希望它們出現(xiàn)在主流搜索引擎中,或是不希望蜘蛛程序訪問(wèn)網(wǎng)頁(yè)。比如,假設(shè)有一款網(wǎng)頁(yè)游戲,每當(dāng)部分頁(yè)面被顯示或者新鏈接被點(diǎn)擊時(shí),游戲就會(huì)生成新的動(dòng)態(tài)頁(yè)面。如果網(wǎng)絡(luò)蜘蛛程序進(jìn)入網(wǎng)頁(yè),繼而開始追蹤所有新網(wǎng)頁(yè)的鏈接,游戲很可能將這些操作錯(cuò)認(rèn)為是由一名操作速度極快的玩家執(zhí)行的,從而失去控制。為了避免此類情況,人們制定了一套拒絕蜘蛛?yún)f(xié)議。該協(xié)議如果嵌入網(wǎng)頁(yè)開頭的元標(biāo)記部分,就會(huì)告訴蜘蛛程序遠(yuǎn)離該頁(yè)面——既不要檢索網(wǎng)頁(yè)上的詞語(yǔ),也不要試圖追蹤網(wǎng)頁(yè)上的鏈接。
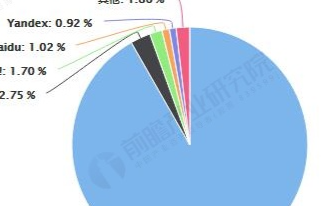
日搜索次數(shù):美國(guó)前五名搜索引擎
- Google:250000000
- Overture:167000000
- Inktomi:80000000
- LookSmart:45000000
- FindWhat:33000000
建立索引
一旦蜘蛛程序完成了網(wǎng)頁(yè)信息收集工作(我們應(yīng)當(dāng)注意,這是一項(xiàng)永遠(yuǎn)不可能真正完成的工作——網(wǎng)頁(yè)不斷更新的特性意味著蜘蛛程序需要不斷爬網(wǎng)),搜索引擎就必須以一種有效方式存儲(chǔ)這些信息。要讓收集到的數(shù)據(jù)可供用戶使用,涉及兩個(gè)關(guān)鍵環(huán)節(jié):
- 以數(shù)據(jù)存儲(chǔ)信息
- 為信息建立索引方法
在最簡(jiǎn)單的情況下,搜索引擎只需存儲(chǔ)詞語(yǔ)和詞語(yǔ)所在地址。實(shí)際上,這樣做會(huì)限制搜索引擎的用途,因?yàn)檫@種方式無(wú)法區(qū)別詞語(yǔ)在網(wǎng)頁(yè)中是被重點(diǎn)使用,還是略一提及,也無(wú)法區(qū)別詞語(yǔ)是使用一次還是多次,或該網(wǎng)頁(yè)上是否含有其它包括該關(guān)鍵字的網(wǎng)頁(yè)的鏈接。換句話說(shuō),這樣做將無(wú)法建立排名表,無(wú)法把最有用的網(wǎng)頁(yè)放在查詢結(jié)果列表的頂端。
為了獲得更多有用信息,大多數(shù)搜索引擎存儲(chǔ)的信息不僅僅是詞語(yǔ)和網(wǎng)址,還可能存儲(chǔ)著該字在網(wǎng)頁(yè)中出現(xiàn)的次數(shù)。搜索引擎可能會(huì)為每個(gè)詞條指定一個(gè)權(quán)重,按照詞語(yǔ)出現(xiàn)在文檔開頭、網(wǎng)頁(yè)副標(biāo)題、鏈接、元標(biāo)記或標(biāo)題的順序,權(quán)重依次增大。各商業(yè)搜索引擎指定索引中詞語(yǔ)權(quán)重的公式有所不同。這從一個(gè)側(cè)面解釋了為什么使用不同搜索引擎來(lái)搜索相同關(guān)鍵字,卻會(huì)產(chǎn)生不同的搜索結(jié)果列表,網(wǎng)頁(yè)排列順序也有所不同。
如果忽略搜索引擎存儲(chǔ)的額外信息的準(zhǔn)確組合,將這些數(shù)據(jù)進(jìn)行編碼可以節(jié)省存儲(chǔ)空間。比如,最初的Google論文描述了使用兩個(gè)字節(jié)(每個(gè)字節(jié)8比特)來(lái)存儲(chǔ)權(quán)重信息——單詞是不是大寫、字號(hào)大小、位置以及其他用來(lái)為數(shù)據(jù)確定級(jí)別的信息。每個(gè)因素大概占據(jù)兩字節(jié)中的兩三個(gè)比特(8比特=1字節(jié))。因此,大量信息便能以一種壓縮率極高的方式存儲(chǔ)下來(lái)。信息被壓縮之后,就可以建立索引了。
索引的唯一目的是盡快找到信息。有好幾種方法可以建立索引,但是最有效的方法是建立散列表。通過(guò)散列法,運(yùn)用公式給每個(gè)詞賦予一個(gè)數(shù)值。該公式可以把詞條平均分配給預(yù)定數(shù)目的分區(qū)。此種數(shù)值分配不同于根據(jù)字母表分配,這是散列表的有效性的關(guān)鍵所在。
在英語(yǔ)中,以某些字母開頭的單詞較多,而以其他字母開頭的單詞較少。例如,您會(huì)發(fā)現(xiàn),字典的M部就比X部厚得多。這種不均衡意味著查找一個(gè)以“常見(jiàn)”字母開頭的單詞,要比查找不常見(jiàn)字母開頭的單詞花費(fèi)更多時(shí)間。散列法平衡了這種區(qū)別,并且縮短了查找某一詞條的平均時(shí)間。它還將索引和實(shí)際詞條分開。散列表中含有經(jīng)過(guò)散列函數(shù)轉(zhuǎn)換生成的數(shù)字和一個(gè)指向?qū)嶋H數(shù)據(jù)的指針,(這樣)不論什么方式,只要它讓實(shí)際數(shù)據(jù)最有效地存儲(chǔ)起來(lái),實(shí)際數(shù)據(jù)都可以用這種方式得到分類排序。通過(guò)高效的索引和有效的存儲(chǔ)方式,即使用戶進(jìn)行了一次復(fù)雜的查詢,也能迅速查找到結(jié)果。
建立搜索
通過(guò)索引進(jìn)行搜索需要用戶進(jìn)行一次查詢,并通過(guò)搜索引擎提交。查詢可以相當(dāng)簡(jiǎn)單,最少僅需一個(gè)詞。建立比較復(fù)雜的查詢則需要使用布爾運(yùn)算符來(lái)細(xì)化和拓展搜索項(xiàng)。
最常見(jiàn)的布爾運(yùn)算符包括:
- AND(與)——以“AND”相連的若干搜索項(xiàng)必須全部出現(xiàn)在網(wǎng)頁(yè)或文檔中。有些搜索引擎使用運(yùn)算符號(hào)“+”來(lái)代替“AND”。
- OR(或)——以“OR”相連的搜索項(xiàng)必須至少有一項(xiàng)出現(xiàn)在網(wǎng)頁(yè)或文檔中。
- NOT(非)——“NOT”之后的搜索項(xiàng)不能出現(xiàn)在網(wǎng)頁(yè)或文檔中。有些搜索引擎使用運(yùn)算符號(hào)“-”來(lái)代替“NOT”。
- FOLLOWED BY(跟隨)——某一搜索項(xiàng)必須緊隨另一搜索項(xiàng)。
- NEAR(臨近)——某一搜索項(xiàng)和另一搜索項(xiàng)的距離必須小于特定詞數(shù)。
- 引號(hào)——引號(hào)內(nèi)的詞語(yǔ)應(yīng)被看作一個(gè)完整短語(yǔ),出現(xiàn)在網(wǎng)頁(yè)或文檔中。
|
這是一個(gè)很難的游戲——您需要選擇兩個(gè)完全不相關(guān)的詞,否則肯定會(huì)得到許多網(wǎng)頁(yè)結(jié)果。另一方面,很多完全不相關(guān)的單詞查詢不到任何結(jié)果。 如果你發(fā)現(xiàn)了一個(gè)純命中,可以把它提交到www.googlewhack.com,他們會(huì)把它公布在命中棧(標(biāo)著您的名字,或者任何您喜歡的稱呼)上,大家都可以瀏覽。 |
未來(lái)的搜索
借助布爾運(yùn)算符定義的搜索是一種文字搜索——搜索引擎按照鍵入的詞語(yǔ)或短語(yǔ)精確搜索。如果鍵入的單詞含有多種意思,就會(huì)有問(wèn)題。例如,“床”(bed),既可以是睡覺(jué)的床,也可以是種植花卉的花床,還可以是卡車的貨艙或魚的產(chǎn)卵地。如果您只對(duì)其中的一個(gè)意思感興趣,也許就不想查看使用其他意思的網(wǎng)頁(yè)。您可以嘗試去除您不感興趣的意思來(lái)建立文字搜索。但是,如果搜索引擎自己可以解決的話就更好了。
基于概念的搜索是搜索引擎的研究領(lǐng)域之一。有些此類搜索引擎應(yīng)用統(tǒng)計(jì)分析來(lái)處理包含您要搜索的單詞或短語(yǔ)的網(wǎng)頁(yè),以此尋找其它您可能感興趣的網(wǎng)頁(yè)。顯然,對(duì)于基于概念的搜索引擎來(lái)說(shuō),為每個(gè)網(wǎng)頁(yè)存儲(chǔ)的信息要更多,而且每次查詢也需要更復(fù)雜的處理過(guò)程。盡管如此,還是有許多團(tuán)隊(duì)致力于改進(jìn)此類搜索引擎的結(jié)果和表現(xiàn)。還有些人轉(zhuǎn)入了另一個(gè)研究領(lǐng)域,名為自然語(yǔ)言查詢。
自然語(yǔ)言查詢的理念是,您可以像詢問(wèn)坐在身邊的人那樣輸入問(wèn)題——不必使用布爾運(yùn)算符或者復(fù)雜的查詢結(jié)構(gòu)。目前最受歡迎的自然語(yǔ)言查詢網(wǎng)站是AskJeeves.com,該網(wǎng)站可以將用戶的查詢解析為關(guān)鍵字,之后再對(duì)已建好的網(wǎng)站索引進(jìn)行搜索。它只能處理簡(jiǎn)單查詢,但在適用于復(fù)雜自然語(yǔ)言的搜索引擎的開發(fā)領(lǐng)域,競(jìng)爭(zhēng)相當(dāng)激烈。










 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論