 電子發(fā)燒友App
電子發(fā)燒友App


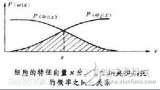
貝葉斯分類器的分類原理是通過某對(duì)象的先驗(yàn)概率,利用貝葉斯公式計(jì)算出其后驗(yàn)概率,即該對(duì)象屬于某一類的概率,選擇具有最大后驗(yàn)概率的類作為該對(duì)象所屬的類。
種類
貝葉斯分類器的分類原理是通過某對(duì)象的先驗(yàn)概率,利用貝葉斯公式計(jì)算出其后驗(yàn)概率,即該對(duì)象屬于某一類的概率,選擇具有最大后驗(yàn)概率的類作為該對(duì)象所屬的類。也就是說,貝葉斯分類器是最小錯(cuò)誤率意義上的優(yōu)化。目前研究較多的貝葉斯分類器主要有四種,分別是:Naive Bayes、TAN、BAN和GBN。
解釋
貝葉斯網(wǎng)絡(luò)是一個(gè)帶有概率注釋的有向無環(huán)圖,圖中的每一個(gè)結(jié)點(diǎn)均表示一個(gè)隨機(jī)變量,圖中兩結(jié)點(diǎn)間若存在著一條弧,則表示這兩結(jié)點(diǎn)相對(duì)應(yīng)的隨機(jī)變量是概率相依的,反之則說明這兩個(gè)隨機(jī)變量是條件獨(dú)立的。網(wǎng)絡(luò)中任意一個(gè)結(jié)點(diǎn)X 均有一個(gè)相應(yīng)的條件概率表(Conditional Probability Table,CPT),用以表示結(jié)點(diǎn)X 在其父結(jié)點(diǎn)取各可能值時(shí)的條件概率。若結(jié)點(diǎn)X 無父結(jié)點(diǎn),則X 的CPT 為其先驗(yàn)概率分布。貝葉斯網(wǎng)絡(luò)的結(jié)構(gòu)及各結(jié)點(diǎn)的CPT 定義了網(wǎng)絡(luò)中各變量的概率分布。
一、分類器的基本概念
經(jīng)過了一個(gè)階段的模式識(shí)別學(xué)習(xí),對(duì)于模式和模式類的概念有一個(gè)基本的了解,并嘗試使用MATLAB實(shí)現(xiàn)一些模式類的生成。而接下來如何對(duì)這些模式進(jìn)行分類成為了學(xué)習(xí)的第二個(gè)重點(diǎn)。這就需要用到分類器。
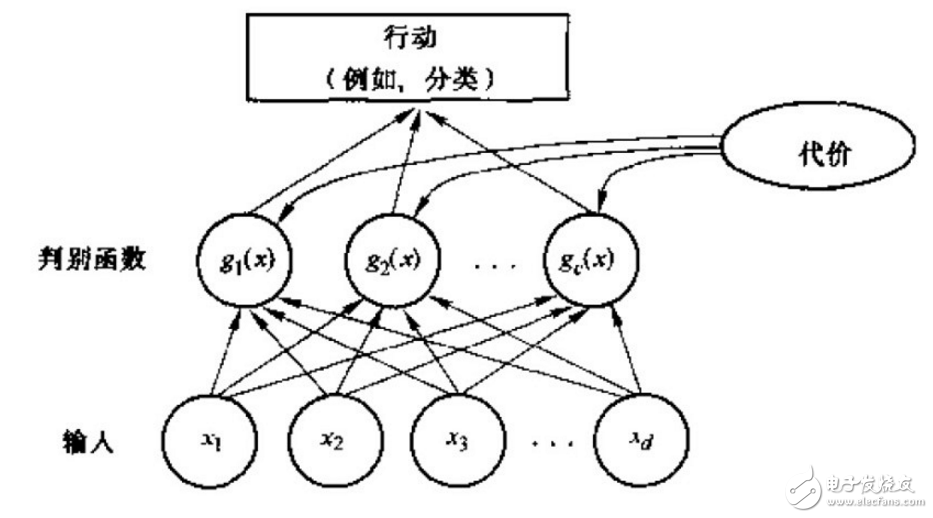
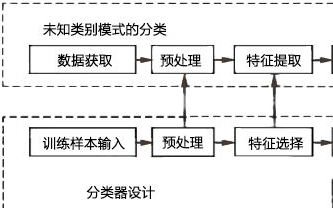
表述模式分類器的方式有很多種,其中用的最多的是一種判別函數(shù)gi(x),i=1,2.。。,c的形式,如果對(duì)于所有的j≠i,有:gi(x)》g(x)
則此分類器將這個(gè)特征向量x判為ωi類。因此,此分類器可視為計(jì)算c個(gè)判別函數(shù)并選取與最大判別值對(duì)應(yīng)的類別的網(wǎng)絡(luò)或機(jī)器。一種分類器的網(wǎng)絡(luò)結(jié)構(gòu)如下圖所示:
二、貝葉斯分類器
一個(gè)貝葉斯分類器可以簡(jiǎn)單自然地表示成以上網(wǎng)絡(luò)結(jié)構(gòu)。貝葉斯分類器的分類原理是通過某對(duì)象的先驗(yàn)概率,利用貝葉斯公式計(jì)算出其后驗(yàn)概率,即該對(duì)象屬于某一類的概率,選擇具有最大后驗(yàn)概率的類作為該對(duì)象所屬的類。在具有模式的完整統(tǒng)計(jì)知識(shí)條件下,按照貝葉斯決策理論進(jìn)行設(shè)計(jì)的一種最優(yōu)分類器。分類器是對(duì)每一個(gè)輸入模式賦予一個(gè)類別名稱的軟件或硬件裝置,而貝葉斯分類器是各種分類器中分類錯(cuò)誤概率最小或者在預(yù)先給定代價(jià)的情況下平均風(fēng)險(xiǎn)最小的分類器。它的設(shè)計(jì)方法是一種最基本的統(tǒng)計(jì)分類方法。
對(duì)于貝葉斯分類器,其判別函數(shù)的選擇并不是唯一的,我們可以將所有的判別函數(shù)乘上相同的正常數(shù)或者加上一個(gè)相同的常量而不影響其判決結(jié)果;在更一般的情況下,如果將每一個(gè)gi (x)替換成f(gi (x)),其中f(?)是一個(gè)單調(diào)遞增函數(shù),其分類的效果不變。特別在對(duì)于最小誤差率分類,選擇下列任何一種函數(shù)都可以得到相同的分類結(jié)果,但是其中一些比另一些計(jì)算更為簡(jiǎn)便:

一個(gè)典型的模式識(shí)別系統(tǒng)是由特征提取和模式分類兩個(gè)階段組成的,而其中模式分類器(Classifier)的性能直接影響整個(gè)識(shí)別系統(tǒng)的性能。 因此有必要探討一下如何評(píng)價(jià)分類器的性能,這是一個(gè)長(zhǎng)期探索的過程。分類器性能評(píng)價(jià)方法見:http://blog.csdn.net/liyuefeilong/article/details/44604001
三、基本的Bayes分類器實(shí)現(xiàn)
這里將在MATLAB中實(shí)現(xiàn)一個(gè)可以對(duì)兩類模式樣本進(jìn)行分類的貝葉斯分類器,假設(shè)兩個(gè)模式類的分布均為高斯分布。模式類1的均值矢量m1 = (1, 3),協(xié)方差矩陣為S1 =(1.5, 0; 0, 1);模式類2的均值矢量m2 = (3, 1),協(xié)方差矩陣為S2 =(1, 0.5; 0.5, 2),兩類的先驗(yàn)概率p1 = p2 = 1/2。詳細(xì)的操作包含以下四個(gè)部分:
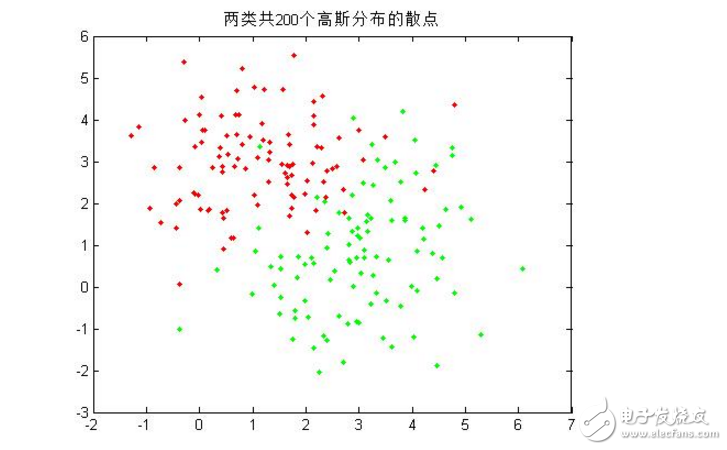
1.首先,編寫一個(gè)函數(shù),其功能是為若干個(gè)模式類生成指定數(shù)目的隨機(jī)樣本,這里為兩個(gè)模式類各生成100個(gè)隨機(jī)樣本,并在一幅圖中畫出這些樣本的二維散點(diǎn)圖;
2.由于每個(gè)隨機(jī)樣本均含有兩個(gè)特征分量,這里先僅僅使用模式集合的其中一個(gè)特征分量作為分類特征,對(duì)第一步中的200個(gè)樣本進(jìn)行分類,統(tǒng)計(jì)正確分類的百分比,并在二維圖上用不同的顏色畫出正確分類和錯(cuò)分的樣本;(注:綠色點(diǎn)代表生成第一類的散點(diǎn),紅色代表第二類;綠色圓圈代表被分到第一類的散點(diǎn),紅色代表被分到第二類的散點(diǎn)! 因此,里外顏色不一樣的點(diǎn)即被錯(cuò)分的樣本。)

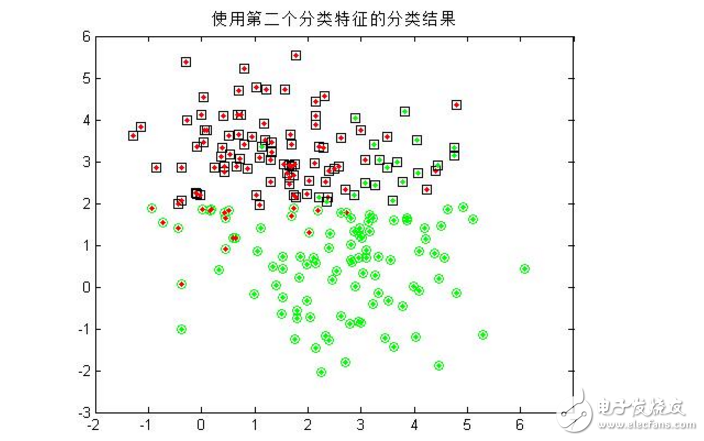
3.僅用模式的第二個(gè)特征分量作為分類特征,重復(fù)第二步的操作;
4.同時(shí)用模式的兩個(gè)分量作為分類特征,對(duì)200個(gè)樣本進(jìn)行分類,統(tǒng)計(jì)正確分類百分比,并在二維圖上用不同的顏色畫出正確分類和錯(cuò)分的樣本;

正確率:
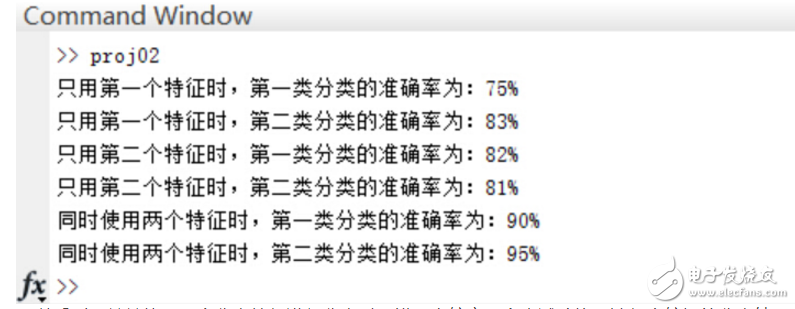
可以看到,單單使用一個(gè)分類特征進(jìn)行分類時(shí),錯(cuò)誤率較高(多次試驗(yàn)均無法得出較好的分類結(jié)果),而增加分類特征的個(gè)數(shù)是提高正確率的有效手段,當(dāng)然,這會(huì)給算法帶來額外的時(shí)間代價(jià)。
四、進(jìn)一步的Bayes分類器
假設(shè)分類數(shù)據(jù)均滿足高斯分布的情況下,設(shè)計(jì)一個(gè)判別分類器,實(shí)驗(yàn)?zāi)康氖菫榱顺醪搅私夂驮O(shè)計(jì)一個(gè)分類器。
1.編寫一個(gè)高斯型的Bayes判別函數(shù)GuassianBayesModel( mu,sigma,p,X ),該函數(shù)輸入為:一給定正態(tài)分布的均值mu、協(xié)方差矩陣sigma,先驗(yàn)概率p以及模式樣本矢量X,輸出判別函數(shù)的值,其代碼如下:
2.以下表格給出了三類樣本各10個(gè)樣本點(diǎn),假設(shè)每一類均為正態(tài)分布,三個(gè)類別的先驗(yàn)概率相等均為P(w1)=P(w2 )=P(w3 )=1/3。計(jì)算每一類樣本的均值矢量和協(xié)方差矩陣,為這三個(gè)類別設(shè)計(jì)一個(gè)分類器。

3.用第二步中設(shè)計(jì)的分類器對(duì)以下測(cè)試點(diǎn)進(jìn)行分類:(1,2,1),(5,3,2),(0,0,0),并且利用以下公式求出各個(gè)測(cè)試點(diǎn)與各個(gè)類別均值之間的Mahalanobis距離。以下是來自百度百科的關(guān)于馬氏距離的解釋:

馬氏距離計(jì)算公式:
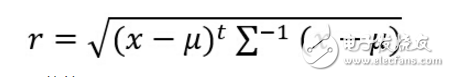
更具體的見: http://baike.baidu.com/link?url=Pcos75ou28q7IukueePCNqf8N7xZifuXOTrwzeWpJULgVrRnytB9Gji6IEhEzlK6q4eTLvx45TAJdXVd7Lnn2q
4.如果P(w1)=0.8, P(w2 )=P(w3 )=0.1,再進(jìn)行第二步和第三步實(shí)驗(yàn)。實(shí)驗(yàn)的結(jié)果如下:
首先是得出三類樣本點(diǎn)各自的均值和協(xié)方差矩陣:


在三個(gè)類別的先驗(yàn)概率均為P(w1)=P(w2 )=P(w3 )=1/3時(shí),使用函數(shù)進(jìn)行分類并給出分類結(jié)果和各個(gè)測(cè)試點(diǎn)與各個(gè)類別均值之間的Mahalanobis距離。



驗(yàn)證當(dāng)三個(gè)類別的先驗(yàn)概率不相等時(shí),同樣使用函數(shù)進(jìn)行分類并給出分類結(jié)果和各個(gè)測(cè)試點(diǎn)與各個(gè)類別均值之間的Mahalanobis距離。

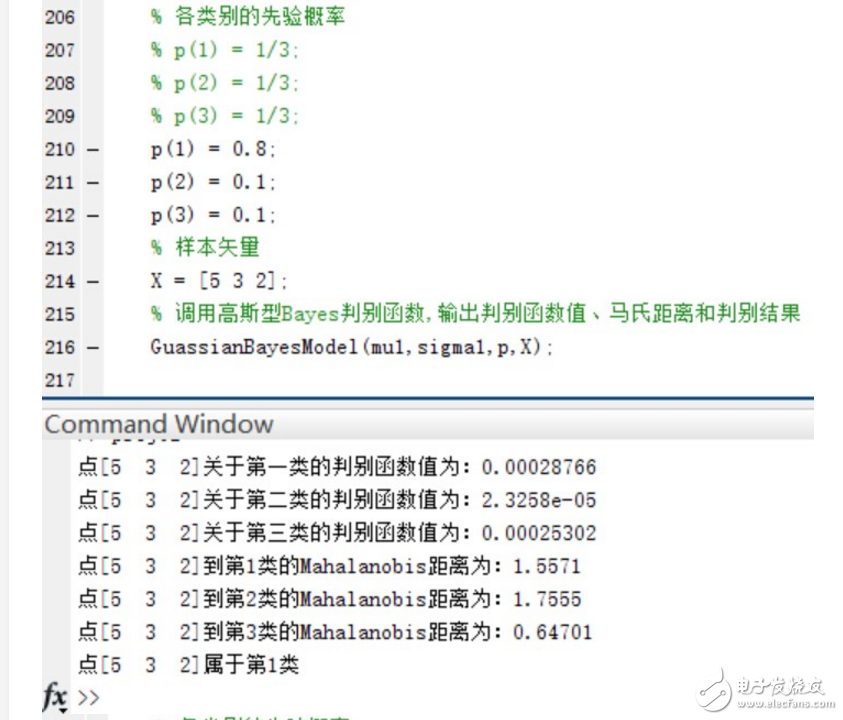

可以看到,在Mahalanobis距離不變的情況下,不同的先驗(yàn)概率對(duì)高斯型Bayes分類器的分類結(jié)果影響很大~ 事實(shí)上,最優(yōu)判決將偏向于先驗(yàn)概率較大的類別。
完整的代碼如下由兩個(gè)函數(shù)和主要的執(zhí)行流程組成:
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 產(chǎn)生模式類函數(shù)
% N:生成散點(diǎn)個(gè)數(shù) C:類別個(gè)數(shù) d:散點(diǎn)的維數(shù)
% mu:各類散點(diǎn)的均值矩陣
% sigma:各類散點(diǎn)的協(xié)方差矩陣
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
function result = MixGaussian(N, C, d, mu, sigma)
color = {‘r.’, ‘g.’, ‘m.’, ‘b.’, ‘k.’, ‘y.’}; % 用于存放不同類數(shù)據(jù)的顏色
% if nargin 《= 3 & N 《 0 & C 《 1 & d 《 1
% error(‘參數(shù)太少或參數(shù)錯(cuò)誤’);
if d == 1
for i = 1 : C
for j = 1 : N/C
r(j,i) = sqrt(sigma(1,i)) * randn() + mu(1,i);
end
X = round(mu(1,i)-5);
Y = round(mu(1,i) + sqrt(sigma(1,i))+5);
b = hist(r(:,i), X:Y);
subplot(1,C,i),bar(X:Y, b,‘b’);
title(‘三類一維隨機(jī)點(diǎn)的分布直方圖’);
grid on
end
elseif d == 2
for i = 1:C
r(:,:,i) = mvnrnd(mu(:,:,i),sigma(:,:,i),round(N/C));
plot(r(:,1,i),r(:,2,i),char(color(i)));
hold on;
end
elseif d == 3
for i = 1:C
r(:,:,i) = mvnrnd(mu(:,:,i),sigma(:,:,i),round(N/C));
plot3(r(:,1,i),r(:,2,i),r(:,3,i),char(color(i)));
hold on;
end
else disp(‘維數(shù)只能設(shè)置為1,2或3’);
end
result = r;
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 高斯型Bayes判別函數(shù)
% mu:輸入正態(tài)分布的均值
% sigma:輸入正態(tài)分布的協(xié)方差矩陣
% p:輸入各類的先驗(yàn)概率
% X:輸入樣本矢量
% 輸出判別函數(shù)值、馬氏距離和判別結(jié)果
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
function GuassianBayesModel( mu,sigma,p,X )
% 構(gòu)建判別函數(shù)
% 計(jì)算點(diǎn)到每個(gè)類的Mahalanobis距離
for i = 1:3;
P(i) = mvnpdf(X, mu(:,:,i), sigma(:,:,i)) * p(i);
r(i) = sqrt((X - mu(:,:,i)) * inv(sigma(:,:,i)) * (X - mu(:,:,i))‘);
end
% 判斷樣本屬于哪個(gè)類的概率最高
% 并顯示點(diǎn)到每個(gè)類的Mahalanobis距離
maxP = max(P);
style = find(P == maxP);
disp([’點(diǎn)[‘,num2str(X),’]關(guān)于第一類的判別函數(shù)值為:‘,num2str(P(1))]);
disp([’點(diǎn)[‘,num2str(X),’]關(guān)于第二類的判別函數(shù)值為:‘,num2str(P(2))]);
disp([’點(diǎn)[‘,num2str(X),’]關(guān)于第三類的判別函數(shù)值為:‘,num2str(P(3))]);
disp([’點(diǎn)[‘,num2str(X),’]到第1類的Mahalanobis距離為:‘,num2str(r(1))]);
disp([’點(diǎn)[‘,num2str(X),’]到第2類的Mahalanobis距離為:‘,num2str(r(2))]);
disp([’點(diǎn)[‘,num2str(X),’]到第3類的Mahalanobis距離為:‘,num2str(r(3))]);
disp([’點(diǎn)[‘,num2str(X),’]屬于第‘,num2str(style),’類‘]);
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%貝葉斯分類器實(shí)驗(yàn)主函數(shù)
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 生成兩類各100個(gè)散點(diǎn)樣本
mu(:,:,1) = [1 3];
sigma(:,:,1) = [1.5 0; 0 1];
p1 = 1/2;
mu(:,:,2) = [3 1];
sigma(:,:,2) = [1 0.5; 0.5 2];
p2 = 1/2;
% 生成200個(gè)二維散點(diǎn),平分為兩類,每類100個(gè)
aa = MixGaussian(200, 2, 2, mu, sigma);
title(’兩類共200個(gè)高斯分布的散點(diǎn)‘);
% 只x分量作為分類特征的分類情況
figure;
% 正確分類的散點(diǎn)個(gè)數(shù)
right1 = 0;
right2 = 0;
% 正確率
rightRate1 = 0;
rightRate2 = 0;
for i = 1:100
x = aa(i,1,1);
plot(aa(:,1,1),aa(:,2,1),’r.‘);
% 計(jì)算后驗(yàn)概率
P1 = normpdf(x, 1, sqrt(1.5));
P2 = normpdf(x, 3, sqrt(1));
if P1 》 P2
plot(aa(i,1,1),aa(i,2,1),’ks‘);
hold on;
right1 = right1 + 1;% 統(tǒng)計(jì)正確個(gè)數(shù)
elseif P1 《 P2
plot(aa(i,1,1),aa(i,2,1),’go‘);
hold on;
end
end
rightRate1 = right1 / 100; % 正確率
for i = 1:100
x = aa(i,1,2);
plot(aa(:,1,2),aa(:,2,2),’g.‘);
% 計(jì)算后驗(yàn)概率
P1 = normpdf(x, 1, sqrt(1.5));
P2 = normpdf(x, 3, sqrt(1));
if P1 》 P2
plot(aa(i,1,2),aa(i,2,2),’ks‘);
hold on;
elseif P1 《 P2
plot(aa(i,1,2),aa(i,2,2),’go‘);
hold on;
right2 = right2 + 1; % 統(tǒng)計(jì)正確個(gè)數(shù)
end
end
rightRate2 = right2 / 100;
title(’使用第一個(gè)分類特征的分類結(jié)果‘);
disp([’只用第一個(gè)特征時(shí),第一類分類的準(zhǔn)確率為:‘,num2str(rightRate1*100),’%‘]);
disp([’只用第一個(gè)特征時(shí),第二類分類的準(zhǔn)確率為:‘,num2str(rightRate2*100),’%‘]);
% 只使用y分量的分類特征的分類情況
figure;
% 正確分類的散點(diǎn)個(gè)數(shù)
right1 = 0;
right2 = 0;
% 正確率
rightRate1 = 0;
rightRate2 = 0;
for i = 1:100
y = aa(i,2,1);
plot(aa(:,1,1),aa(:,2,1),’r.‘);
% 計(jì)算后驗(yàn)概率
P1 = normpdf(y, 3, sqrt(1));
P2 = normpdf(y, 1, sqrt(2));
if P1 》 P2
plot(aa(i,1,1),aa(i,2,1),’ks‘);
hold on;
right1 = right1 + 1; % 統(tǒng)計(jì)正確個(gè)數(shù)
elseif P1 《 P2
plot(aa(i,1,1),aa(i,2,1),’go‘);
hold on;
end
end
rightRate1 = right1 / 100; % 正確率
for i = 1:100
y = aa(i,2,2);
plot(aa(:,1,2),aa(:,2,2),’g.‘);
% 計(jì)算后驗(yàn)概率
P1 = normpdf(y, 3, sqrt(1));
P2 = normpdf(y, 1, sqrt(2));
if P1 》 P2
plot(aa(i,1,2),aa(i,2,2),’ks‘);
hold on;
elseif P1 《 P2
plot(aa(i,1,2),aa(i,2,2),’go‘);
hold on;
right2 = right2 + 1; % 統(tǒng)計(jì)正確個(gè)數(shù)
end
end
rightRate2 = right2 / 100; % 正確率
title(’使用第二個(gè)分類特征的分類結(jié)果‘);
disp([’只用第二個(gè)特征時(shí),第一類分類的準(zhǔn)確率為:‘,num2str(rightRate1*100),’%‘]);
disp([’只用第二個(gè)特征時(shí),第二類分類的準(zhǔn)確率為:‘,num2str(rightRate2*100),’%‘]);
% 同時(shí)使用兩個(gè)分類特征的分類情況
figure;
% 正確分類的散點(diǎn)個(gè)數(shù)
right1 = 0;
right2 = 0;
% 正確率
rightRate1 = 0;
rightRate2 = 0;
for i = 1:100
x = aa(i,1,1);
y = aa(i,2,1);
plot(aa(:,1,1),aa(:,2,1),’r.‘);
% 計(jì)算后驗(yàn)概率
P1 = mvnpdf([x,y], mu(:,:,1), sigma(:,:,1));
P2 = mvnpdf([x,y], mu(:,:,2), sigma(:,:,2));
if P1 》 P2
plot(aa(i,1,1),aa(i,2,1),’ks‘);
hold on;
right1 = right1 + 1;
else if P1 《 P2
plot(aa(i,1,1),aa(i,2,1),’go‘);
hold on;
end
end
end
rightRate1 = right1 / 100;
for i = 1:100
x = aa(i,1,2);
y = aa(i,2,2);
plot(aa(:,1,2),aa(:,2,2),’g.‘);
% 計(jì)算后驗(yàn)概率
P1 = mvnpdf([x,y], mu(:,:,1), sigma(:,:,1));
P2 = mvnpdf([x,y], mu(:,:,2), sigma(:,:,2));
if P1 》 P2
plot(aa(i,1,2),aa(i,2,2),’ks‘);
hold on;
else if P1 《 P2
plot(aa(i,1,2),aa(i,2,2),’go‘);
hold on;
right2 = right2 + 1;
end
end
end
rightRate2 = right2 / 100;
title(’使用兩個(gè)分類特征的分類結(jié)果‘);
disp([’同時(shí)使用兩個(gè)特征時(shí),第一類分類的準(zhǔn)確率為:‘,num2str(rightRate1*100),’%‘]);
disp([’同時(shí)使用兩個(gè)特征時(shí),第二類分類的準(zhǔn)確率為:‘,num2str(rightRate2*100),’%‘]);
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 進(jìn)一步的Bayes分類器
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% w1,w2,w3三類散點(diǎn)
w = zeros(10,3,3);
w(:,:,1) = [-5.01 -8.12 -3.68;。。。
-5.43 -3.48 -3.54;。。。
1.08 -5.52 1.66;。。。
0.86 -3.78 -4.11;。。。
-2.67 0.63 7.39;。。。
4.94 3.29 2.08;。。。
-2.51 2.09 -2.59;。。。
-2.25 -2.13 -6.94;。。。
5.56 2.86 -2.26;。。。
1.03 -3.33 4.33];
w(:,:,2) = [-0.91 -0.18 -0.05;。。。
1.30 -.206 -3.53;。。。
-7.75 -4.54 -0.95;。。。
-5.47 0.50 3.92;。。。
6.14 5.72 -4.85;。。。
3.60 1.26 4.36;。。。
5.37 -4.63 -3.65;。。。
7.18 1.46 -6.66;。。。
-7.39 1.17 6.30;。。。
-7.50 -6.32 -0.31];
w(:,:,3) = [ 5.35 2.26 8.13;。。。
5.12 3.22 -2.66;。。。
-1.34 -5.31 -9.87;。。。
4.48 3.42 5.19;。。。
7.11 2.39 9.21;。。。
7.17 4.33 -0.98;。。。
5.75 3.97 6.65;。。。
0.77 0.27 2.41;。。。
0.90 -0.43 -8.71;。。。
3.52 -0.36 6.43];
% 均值
mu1(:,:,1) = sum(w(:,:,1)) 。/ 10;
mu1(:,:,2) = sum(w(:,:,2)) 。/ 10;
mu1(:,:,3) = sum(w(:,:,3)) 。/ 10;
% 協(xié)方差矩陣
sigma1(:,:,1) = cov(w(:,:,1));
sigma1(:,:,2) = cov(w(:,:,2));
sigma1(:,:,3) = cov(w(:,:,3));
% 各類別的先驗(yàn)概率
% p(1) = 1/3;
% p(2) = 1/3;
% p(3) = 1/3;
p(1) = 0.8;
p(2) = 0.1;
p(3) = 0.1;
% 樣本矢量
X = [1 0 0];
% 調(diào)用高斯型Bayes判別函數(shù),輸出判別函數(shù)值、馬氏距離和判別結(jié)果
GuassianBayesModel(mu1,sigma1,p,X);
















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論