 電子發燒友App
電子發燒友App


一、volatile概念
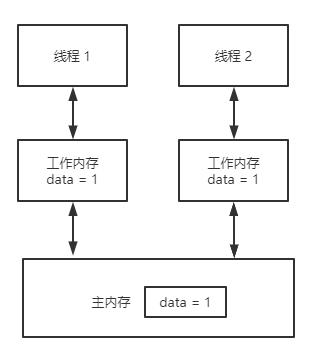
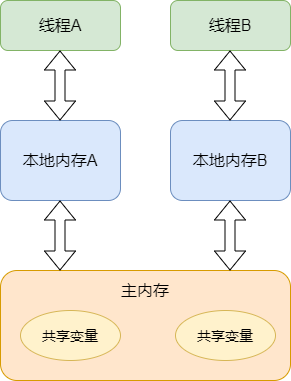
談到volatile,理解原子性和易變性是不同的概念這一點很重要,volatile是輕量級的鎖,它只具備可見性,但沒有原子特性。如果你將一個域聲明為volatile,那么只要對這個域產生了寫操作,所有的讀操作都可以看到這個修改,即便使用了本地緩存也一樣,volatile會被立即寫入到主內存中,而讀的操作就發生在主內存中。在非volatile域上的原子操作不必刷新到主內存中,所以讀操作的任務看不到這個值,如果多個任務在同時訪問某個域,那么這個域就應該是volatile,否則這個域就應該經過同步來訪問,同步也會導致向主內存中刷新。
使用volatile而不是synchronize的唯一安全的情況就是類中只有一個可變的域。個人認為,第一選擇應該是synchronize,這應該最安全的方式 。如果并發水平不高,最好還是不要使用。
二、volatile變量的使用
在使用volatile變量時,應當考慮是否滿足下面這樣的要求:
對變量的寫入操作不依賴變量的當前值
說白了volatile 變量不能用作線程安全計數器,類似于i++這種增量操作。增量操作符++不是原子的。這個操作分解開來看是先從堆內存中獲得i值的副本放到緩存中,然后對副本值加1,最后再將副本值寫回到堆內存的變量i中,是一個由讀取-修改-寫入操作序列組成的組合操作。
沒有用于其它變量的不變式條件中(lower小于upper)
/*
* volatile只保證lower與upper的最后寫入一定會被其它讀取的線程看到
* 但不能保證在lower或upper寫入時,另一個變量的值沒有發生變化
*/
private volatile int lower;
private volatile int upper;
public int getLower() {
return lower;
}
public int getUpper() {
return upper;
}
public void setLower(int lower) {
if (lower 》 upper)
throw new IllegalArgumentException();
this.lower = lower;
}
public void setUpper(int upper) {
if (upper 《 lower)
throw new IllegalArgumentException();
this.upper = upper;
}1234567891011121314151617181920212223242526
volatile變量就不適合用于不變性條件這種情況,以上下限為例,lower必須小于upper,這就是一種不變性條件,你可以理解為這是一種規則限制。它們都只有set與get方法,但在set方法里面加入了約束條件,這時,volatile的可見性就不能保證并發時,lower與upper之間的不變性條件(lower小于upper)一定成立了。
曾經見到過這樣的一個面試題:
volatile 能使得一個非原子操作變成原子操作嗎?
答案是能的,在基本數據類型中long和double是非原子性的,double 和 long 都是64位寬,因此對這兩種類型的讀是分為兩部分的,第一次讀取第一個 32 位,然后再讀剩下的 32 位,如果一個線程正在修改該 long 變量的值,另一個線程可能只能看到該值的一半(前 32 位)。但是將long與double加上volatile ,對變量的讀寫是原子性的
三、volatile的作用
volatile不是保護線程安全的。它保護的是變量安全。主要的功能是保護變量不被主函數和中斷函數反復修改造成讀寫錯誤。
volatile具備兩種特性:
保證此變量對所有線程的可見性,指一條線程修改了這個變量的值,新值對于其他線程來說是可見的,但并不是多線程安全的。
禁止指令重排序優化。
Volatile和Synchronized四個不同點:
1 粒度不同,后者鎖對象和類,前者針對變量
2 syn阻塞,volatile線程不阻塞
3 syn保證三大特性,volatile不保證原子性
4 syn編譯器優化,volatile不優化
四、Volatile變量的使用
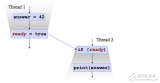
volatile變量的讀寫對所有線程立即可見
只是讀和寫一步,復雜的運算不能保證對其他線程可見,因為復雜的運算可能會被編譯成多條指令,JMM只保證,volatile變量從工作內存寫回到主存是對其他線程可見的。先看一個具體的例子。
static volatile int i = 0;
// -XX:+PrintGC
// -XX:+PrintGCDetails
// -Xms20m
// -Xmn10m
// -Xmx20m
// -XX:+UseSerialGC
// -XX:MaxTenuringThreshold=15
// -XX:-HandlePromotionFailure
// -XX:+PrintHeapAtGC
public static void main(String[] args) {
int a = i++;
}1234567891011121314
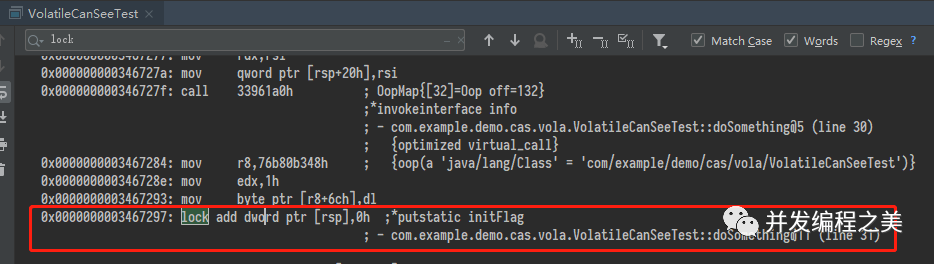
編譯后的指令
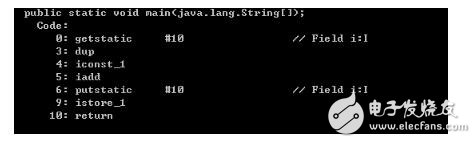
JMM只是能夠保證(并不一定能夠保證,但是一條字節碼的指令也是由若干機器指令完成的,但是能夠說明問題了)getstatic 和 putstatic volatile變量的時候是原子的,至于中間的一些列操作,并不能夠保證再次期間沒有其他線程對i操作生成臟數據。也就是,JMM保證get操作的值是當前內存中最新的,以及put之后內存中i的對其他內存可見。
禁止指令的重排序
這一點,《java并發編程的藝術》一書中講的比較詳細。
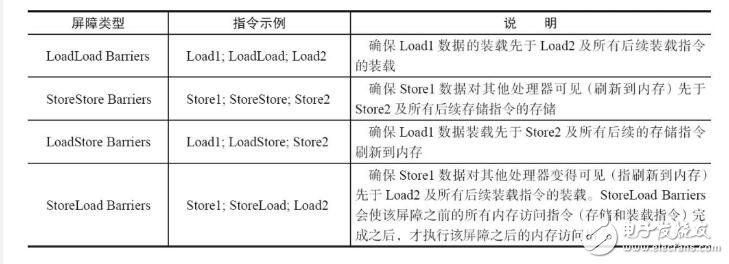
重排序分為編譯器重排序和處理器重排序。為了實現volatile內存語義,JMM會分別限制這兩種類型的重排序類型。JMM針對編譯器制定的volatile重排序規則見下表。
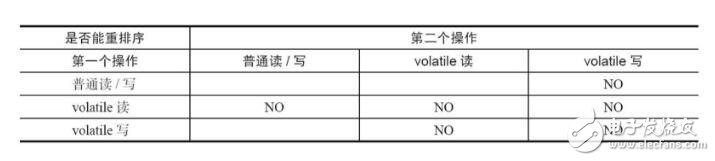
個人總結來說,
volatile的讀下面的任何操作都不能重排序到volatile讀操作的上方,volatile上面的普通讀寫可重排序到下方。
volatile的寫上面的任何操作都不能重排序到volatile寫操作的下方,volatile下面的普通讀寫可重排序到上方。
任何兩個volatile的讀寫順序不能重排。
為了實現上述的volatile的內存語義,編譯器在生成字節碼時,會在指令序列中插入內存屏障來禁止特定類型的處理器重排序。(StoreStore等屏障的介紹見文章最后)
在每個volatile寫操作的前面插入一個StoreStore屏障。
在每個volatile寫操作的后面插入一個StoreLoad屏障。
在每個volatile讀操作的后面插入一個LoadLoad屏障。
在每個volatile讀操作的后面插入一個LoadStore屏障。
插入屏障后的效果見下圖
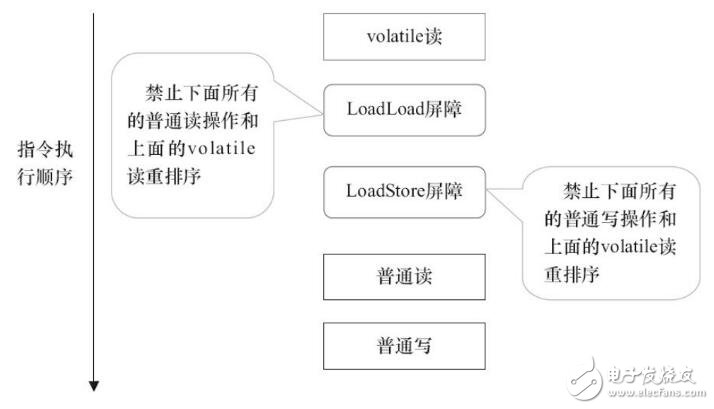
LoadLoad屏障用來禁止處理器把上面的volatile讀與下面的普通讀重排序。LoadStore屏障用來禁止處理器把上面的volatile讀與下面的普通寫重排序。
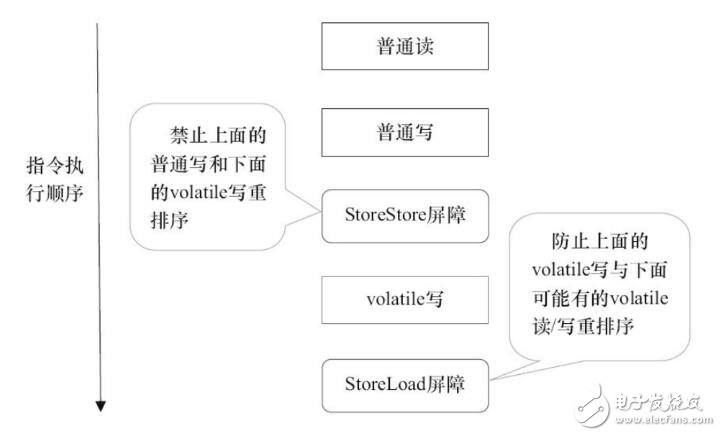
StoreStore屏障可以保證在volatile寫之前,其前面的所有普通寫操作已經對任意處理器可見了。這是因為StoreStore屏障將保障上面所有的普通寫在volatile寫之前刷新到主內存。
這里比較有意思的是,volatile寫后面的StoreLoad屏障。此屏障的作用是避免volatile寫與后面可能有的volatile讀/寫操作重排序。因為編譯器常常無法準確判斷在一個volatile寫的后面是否需要插入一個StoreLoad屏障(比如,一個volatile寫之后方法立即return)。為了保證能正確實現volatile的內存語義,JMM在采取了保守策略:在每個volatile寫的后面,或者在每個volatile讀的前面插入一個StoreLoad屏障。從整體執行效率的角度考慮,JMM最終選擇了在每個volatile寫的后面插入一個StoreLoad屏障。因為volatile寫-讀內存語義的常見使用模式是:一個寫線程寫volatile變量,多個讀線程讀同一個volatile變量。當讀線程的數量大大超過寫線程時,選擇在volatile寫之后插入StoreLoad屏障將帶來可觀的執行效率的提升。從這里可以看到JMM在實現上的一個特點:首先確保正確性,然后再去追求執行效率。
上面這段話引自《java并發編程的藝術》一書,但是不是很明白,volatile的寫前面的所有操作都不得拍到volatile寫之后,為什么這里只加入了Store-Store屏障呢,這樣普通讀不就可以重拍到volatile寫的下方了??????
如果,volatile讀的上面還有volatile讀,因為volatile讀下面都會插入load-load屏障,所以兩者不會重排。如果volatile讀的上面還有volatile寫,volatile寫后面加入了store-load,所以下面的volatile讀不能能與之重排序。
屏障介紹:














 工商網監
工商網監
評論