 電子發燒友App
電子發燒友App


Java 語言中的 volatile 變量可以被看作是一種 “程度較輕的 synchronized”;與 synchronized 塊相比,volatile 變量所需的編碼較少,并且運行時開銷也較少,但是它所能實現的功能也僅是 synchronized 的一部分。
一、Volatile變量
volatile 變量具有 synchronized 的可見性特性,但是不具備原子特性。這就是說線程能夠自動發現 volatile 變量的最新值。Volatile 變量可用于提供線程安全,但是只能應用于非常有限的一組用例:多個變量之間或者某個變量的當前值與修改后值之間沒有約束。因此,單獨使用 volatile 還不足以實現計數器、互斥鎖或任何具有與多個變量相關的不變式(Invariants)的類(例如 “start 《=end”)。
出于簡易性或可伸縮性的考慮,您可能傾向于使用 volatile 變量而不是鎖。當使用 volatile 變量而非鎖時,某些習慣用法(idiom)更加易于編碼和閱讀。此外,volatile 變量不會像鎖那樣造成線程阻塞,因此也很少造成可伸縮性問題。在某些情況下,如果讀操作遠遠大于寫操作,volatile 變量還可以提供優于鎖的性能優勢。
二、正確使用volatile變量的條件
您只能在有限的一些情形下使用 volatile 變量替代鎖。要使 volatile 變量提供理想的線程安全,必須同時滿足下面兩個條件:
對變量的寫操作不依賴于當前值。
該變量沒有包含在具有其他變量的不變式中。
實際上,這些條件表明,可以被寫入 volatile 變量的這些有效值獨立于任何程序的狀態,包括變量的當前狀態。
第一個條件的限制使 volatile 變量不能用作線程安全計數器。雖然增量操作(x++)看上去類似一個單獨操作,實際上它是一個由讀取-修改-寫入操作序列組成的組合操作,必須以原子方式執行,而 volatile 不能提供必須的原子特性。實現正確的操作需要使 x 的值在操作期間保持不變,而 volatile 變量無法實現這點。(然而,如果將值調整為只從單個線程寫入,那么可以忽略第一個條件。)
大多數編程情形都會與這兩個條件的其中之一沖突,使得 volatile 變量不能像 synchronized 那樣普遍適用于實現線程安全。清單 1 顯示了一個非線程安全的數值范圍類。它包含了一個不變式 —— 下界總是小于或等于上界。
三、Java中volatile的作用以及用法
volatile讓變量每次在使用的時候,都從主存中取。而不是從各個線程的“工作內存”。
volatile具有synchronized關鍵字的“可見性”,但是沒有synchronized關鍵字的“并發正確性”,也就是說不保證線程執行的有序性。
也就是說,volatile變量對于每次使用,線程都能得到當前volatile變量的最新值。但是volatile變量并不保證并發的正確性。
=========================分割線1=================================
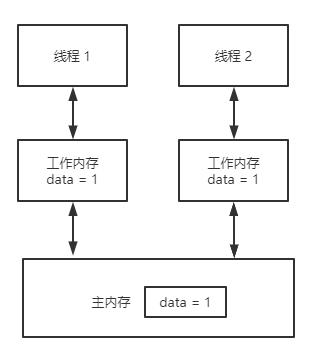
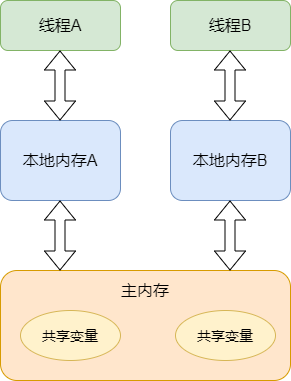
在Java內存模型中,有main memory,每個線程也有自己的memory (例如寄存器)。為了性能,一個線程會在自己的memory中保持要訪問的變量的副本。這樣就會出現同一個變量在某個瞬間,在一個線程的memory中的值可能與另外一個線程memory中的值,或者main memory中的值不一致的情況。
一個變量聲明為volatile,就意味著這個變量是隨時會被其他線程修改的,因此不能將它cache在線程memory中。以下例子展現了volatile的作用:
1 public class StoppableTask extends Thread {
2
3 private volatile boolean pleaseStop;
4
5
6 public void run() {
7
8 while (!pleaseStop) {
9
10 // do some stuff.。。
11
12 }
13
14 }
15
16
17 public void tellMeToStop() {
18
19 pleaseStop = true;
20
21 }
22
23 }
假如pleaseStop沒有被聲明為volatile,線程執行run的時候檢查的是自己的副本,就不能及時得知其他線程已經調用tellMeToStop()修改了pleaseStop的值。
Volatile一般情況下不能代替sychronized,因為volatile不能保證操作的原子性,即使只是i++,實際上也是由多個原子操作組成:read i; inc; write i,假如多個線程同時執行i++,volatile只能保證他們操作的i是同一塊內存,但依然可能出現寫入臟數據的情況。如果配合Java 5增加的atomic wrapper classes,對它們的increase之類的操作就不需要sychronized。
Reference:
http://www.javamex.com/tutorials/synchronization_volatile.shtml
http://www.javamex.com/tutorials/synchronization_volatile_java_5.shtml
http://www.ibm.com/developerworks/cn/java/j-jtp06197.html
=========================分割線2=================================
恐怕比較一下volatile和synchronized的不同是最容易解釋清楚的。volatile是變量修飾符,而synchronized則作用于一段代碼或方法;看如下三句get代碼:
1 int i1;
2 int geti1() {return i1;}
3 volatile int i2;
4 int geti2()
5 {return i2;}
6 int i3;
7 synchronized int geti3() {return i3;}
8 geti1()
得到存儲在當前線程中i1的數值。多個線程有多個i1變量拷貝,而且這些i1之間可以互不相同。換句話說,另一個線程可能已經改變了它線程內的i1值,而這個值可以和當前線程中的i1值不相同。事實上,Java有個思想叫“主”內存區域,這里存放了變量目前的“準確值”。每個線程可以有它自己的變量拷貝,而這個變量拷貝值可以和“主”內存區域里存放的不同。因此實際上存在一種可能:“主”內存區域里的i1值是1,線程1里的i1值是2,線程2里的i1值是3——這在線程1和線程2都改變了它們各自的i1值,而且這個改變還沒來得及傳遞給“主”內存區域或其他線程時就會發生。
而 geti2()得到的是“主”內存區域的i2數值。用volatile修飾后的變量不允許有不同于“主”內存區域的變量拷貝。換句話說,一個變量經 volatile修飾后在所有線程中必須是同步的;任何線程中改變了它的值,所有其他線程立即獲取到了相同的值。理所當然的,volatile修飾的變量存取時比一般變量消耗的資源要多一點,因為線程有它自己的變量拷貝更為高效。
既然volatile關鍵字已經實現了線程間數據同步,又要 synchronized干什么呢?呵呵,它們之間有兩點不同。首先,synchronized獲得并釋放監視器——如果兩個線程使用了同一個對象鎖,監視器能強制保證代碼塊同時只被一個線程所執行——這是眾所周知的事實。但是,synchronized也同步內存:事實上,synchronized在“ 主”內存區域同步整個線程的內存。因此,執行geti3()方法做了如下幾步:
1. 線程請求獲得監視this對象的對象鎖(假設未被鎖,否則線程等待直到鎖釋放)
2. 線程內存的數據被消除,從“主”內存區域中讀入(Java虛擬機能優化此步。。。[后面的不知道怎么表達,汗])
3. 代碼塊被執行
4. 對于變量的任何改變現在可以安全地寫到“主”內存區域中(不過geti3()方法不會改變變量值)
5. 線程釋放監視this對象的對象鎖
因此volatile只是在線程內存和“主”內存間同步某個變量的值,而synchronized通過鎖定和解鎖某個監視器同步所有變量的值。顯然synchronized要比volatile消耗更多資源。
=========================分割線3=================================
volatile關鍵字相信了解Java多線程的讀者都很清楚它的作用。volatile關鍵字用于聲明簡單類型變量,如int、float、 boolean等數據類型。如果這些簡單數據類型聲明為volatile,對它們的操作就會變成原子級別的。但這有一定的限制。例如,下面的例子中的n就不是原子級別的:
1 package mythread;
2
3 public class JoinThread extends Thread
4 {
5 public static volatile int n = 0 ;
6 public void run()
7 {
8 for ( int i = 0 ; i 《 10 ; i ++ )
9 try
10 {
11 n = n + 1 ;
12 sleep( 3 ); // 為了使運行結果更隨機,延遲3毫秒
13
14 }
15 catch (Exception e)
16 {
17 }
18 }
19
20 public static void main(String[] args) throws Exception
21 {
22
23 Thread threads[] = new Thread[ 100 ];
24 for ( int i = 0 ; i 《 threads.length; i ++ )
25 // 建立100個線程
26 threads[i] = new JoinThread();
27 for ( int i = 0 ; i 《 threads.length; i ++ )
28 // 運行剛才建立的100個線程
29 threads[i].start();
30 for ( int i = 0 ; i 《 threads.length; i ++ )
31 // 100個線程都執行完后繼續
32 threads[i].join();
33 System.out.println( “ n= ” + JoinThread.n);
34 }
35 }
如果對n的操作是原子級別的,最后輸出的結果應該為n=1000,而在執行上面積代碼時,很多時侯輸出的n都小于1000,這說明n=n+1不是原子級別的操作。原因是聲明為volatile的簡單變量如果當前值由該變量以前的值相關,那么volatile關鍵字不起作用,也就是說如下的表達式都不是原子操作:
n = n + 1 ;
n ++ ;
如果要想使這種情況變成原子操作,需要使用synchronized關鍵字,如上的代碼可以改成如下的形式:
package mythread;
public class JoinThread extends Thread
{
public static int n = 0 ;
public static synchronized void inc()
{
n ++ ;
}
public void run()
{
for ( int i = 0 ; i 《 10 ; i ++ )
try
{
inc(); // n = n + 1 改成了 inc();
sleep( 3 ); // 為了使運行結果更隨機,延遲3毫秒
}
catch (Exception e)
{
}
}
public static void main(String[] args) throws Exception
{
Thread threads[] = new Thread[ 100 ];
for ( int i = 0 ; i 《 threads.length; i ++ )
// 建立100個線程
threads[i] = new JoinThread();
for ( int i = 0 ; i 《 threads.length; i ++ )
// 運行剛才建立的100個線程
threads[i].start();
for ( int i = 0 ; i 《 threads.length; i ++ )
// 100個線程都執行完后繼續
threads[i].join();
System.out.println( “ n= ” + JoinThread.n);
}
}
上面的代碼將n=n+1改成了inc(),其中inc方法使用了synchronized關鍵字進行方法同步。因此,在使用volatile關鍵字時要慎重,并不是只要簡單類型變量使用volatile修飾,對這個變量的所有操作都是原來操作,當變量的值由自身的上一個決定時,如n=n+1、n++ 等,volatile關鍵字將失效,只有當變量的值和自身上一個值無關時對該變量的操作才是原子級別的,如n = m + 1,這個就是原級別的。所以在使用volatile關鍵時一定要謹慎,如果自己沒有把握,可以使用synchronized來代替volatile。











 工商網監
工商網監
評論