1. 方法 總共分為4類 基于歐式距離的聚類 Supervoxel 聚類 深度(Depth) 聚類 Scanline Run 聚類 1.1 基于歐氏距離的聚類 思路 : 在點云上構(gòu)造kd-tree
2023-06-07 14:38:38 0
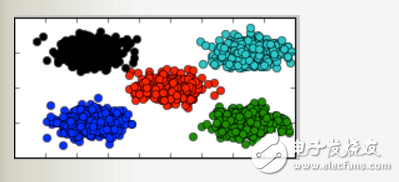
0 在聚類技術(shù)領(lǐng)域中,K-means可能是最常見和經(jīng)常使用的技術(shù)之一。K-means使用迭代細(xì)化方法,基于用戶定義的集群數(shù)量(由變量K表示)和數(shù)據(jù)集來產(chǎn)生其最終聚類。例如,如果將K設(shè)置為3,則數(shù)據(jù)集將分組為3個群集,如果將K設(shè)置為4,則將數(shù)據(jù)分組為4個群集,依此類推。
2022-10-28 14:25:21 499
499 應(yīng)該是什么?你應(yīng)該實驗多少次?你需要中心點嗎?等等,讓我們先來談?wù)?b style="color: red">中心點。 一、什么是中心點 中心點 - 表示所有因子水平都設(shè)置在低設(shè)置和高設(shè)置之間的中間位置時的試驗。 這里有兩個因子,每個因子兩個水平。其中溫度低水平為12
2022-09-27 16:47:591129 K-means 算法是典型的基于距離的聚類算法,采用距離作為相似性的評價指標(biāo),兩個對象的距離越近,其相似度就越大。而簇是由距離靠近的對象組成的,因此算法目的是得到緊湊并且獨立的簇。
2022-07-18 09:19:131438 
K-means 是一種聚類算法,且對于數(shù)據(jù)科學(xué)家而言,是簡單且熱門的無監(jiān)督式機(jī)器學(xué)習(xí)(ML)算法之一。
2022-06-06 11:53:552540 FCM聚類算法以及改進(jìn)模糊聚類算法用于醫(yī)學(xué)圖像分割的matlab源程序
2018-05-11 23:54:19
,形成初始完備數(shù)據(jù)集,針對得到的完整數(shù)據(jù)進(jìn)行聚類,并運用冋類簇的均值修正初始充填值。根據(jù)充填效果誤差判定充填穩(wěn)定性,并進(jìn)行多次遞歸聚類修正充填值,直到前后兩次充填較為穩(wěn)定或迭代次數(shù)超過閾值時停止迭代。實驗
2021-06-11 10:44:216 類算法確定拐點,從而選舉岀聚類中心,根據(jù)聚類中心確定包含的欻據(jù)點;其次將初始的TSP問題分割成較小的簇,這些簇稱為二類TSP問題;再經(jīng)自適應(yīng)信息素更新策略的蟻群算法運算,找岀毎個簇的最優(yōu)解,進(jìn)一步將簇與簇之間相近的節(jié)點構(gòu)
2021-06-04 11:23:173 為構(gòu)建行駛工況,消除K均值算法對初始聚類中心的敏感性及噪聲點的干擾,提岀一種改進(jìn)主成分分析和基于密度的改進(jìn)k-均值聚類組合方法。結(jié)合距離優(yōu)化法和密度法,構(gòu)建一種數(shù)據(jù)集密度度量方法。選取距離較大、密度
2021-05-31 11:16:083 為降低并均衡無線傳感器網(wǎng)絡(luò)(WSN)中傳感器節(jié)點的能量消耗,提出一種基于最優(yōu)傳輸距離和 K-means聚類的WSN分簇算法。根據(jù)層次聚類算法建立聚類特征樹,將聚類特征樹中的葉節(jié)點視為一個簇,并使每個
2021-05-26 14:50:172 SPFCM)與FCPM中使用的初始化聚類中心的策略相結(jié)合,即將先前數(shù)據(jù)塊的聚類中心附近的幾個樣本點添加到下一個數(shù)據(jù)塊進(jìn)行聚類,以避免FCM對噪聲的敏感性。此外,所提出的聚類算法使用一種新的改進(jìn)后的距離度量的同時,使用修正后的約束條件和目
2021-05-12 15:20:511 的DPC圖像分割算法。將圖像像素點的顏色空間 CIE Lab值作為特征數(shù)據(jù),通過計算信息熵求得自適應(yīng)截斷距離以取代經(jīng)驗取值,建立相應(yīng)的決策圖并確定聚類中心總數(shù),歸類非聚類中心點,剔除噪聲點從而完成圖像分割。在Berkeley數(shù)據(jù)集上的實驗
2021-05-11 14:18:046 為了降低K- mediods聚類算法的誤差并提高并行優(yōu)化的性能,將混合蛙跳算法運用于聚類和并行優(yōu)化過程。在Kmediods聚類過程中,將K- mediods與聚類簇思想相結(jié)合,對各個聚類簇進(jìn)行混合
2021-05-08 16:17:184 聚類分析是數(shù)據(jù)挖掘與分析最重要的方法之一。它把相似的數(shù)據(jù)對象歸類到一個簇,把不同的數(shù)據(jù)對象盡可能分到不同的簇。其中k- means聚類算法,由于其簡單性和高效性,被廣泛運用于解決各種現(xiàn)實問題,例如
2021-04-28 16:43:551 為構(gòu)建行駛工況,消除K-均值算法對初始聚類中心的敏感性及噪聲點的干擾,提岀一種改進(jìn)主成分分析和基于密度的改進(jìn)K-均值聚類組合方法。結(jié)合距離優(yōu)化法和密度法,構(gòu)建一種數(shù)據(jù)集密度度量方法。選取距離較大
2021-04-16 15:36:0016 報文聚類是協(xié)議逆向工程的主要步驟之一。針對私有二進(jìn)制協(xié)議報文,目前的報文聚類方法存在報文向量化特征冗余的問題,而且傳統(tǒng)聚類方法存在聚類中心和聚類簇數(shù)難以確定的問題。根據(jù)n-gram序列化的思想,構(gòu)造
2021-04-12 11:04:339 除邊界點和噪聲點對聚類結(jié)果的影響。引入關(guān)聯(lián)度矩陣,通過計算類簇間的關(guān)聯(lián)程度和融合度量,選取最優(yōu)關(guān)聯(lián)簇進(jìn)行融合得到最終聚類結(jié)果。實驗結(jié)果表明,該算法無需人工設(shè)置聚類參數(shù),并且與基于密度的空間聚類算法和K均值聚類算法
2021-04-01 16:16:4913 最小化計算公式設(shè)計概念自動聚類機(jī)制。實驗結(jié)果表明,與K- means算法、基于密度和基于距離的領(lǐng)域概念聚類方法相比,該方法可有效提高査準(zhǔn)率、查全率以及綜合評估指標(biāo)F值。
2021-04-01 15:39:4410 子空間并定義合理的約東函數(shù)指導(dǎo)聚類過程,從而實現(xiàn)類簇的可重疊性與離群點的控制。在此基礎(chǔ)上定義合理的目標(biāo)函數(shù)對傳統(tǒng)K- Means算法進(jìn)行修正,利用熵權(quán)約東分別計算每個類簇中各維度的權(quán)重,使用權(quán)重值標(biāo)識不同類簇中維度的相對重要性,
2021-03-25 14:07:1013 K- means算法初始中心點選擇的隨機(jī)性以及對噪聲點的敏感性,使得聚類結(jié)果易陷亼局部最優(yōu)解,為獲得最佳初始聚類中心,提岀一種基于距離和密度的并行二分K- means算法。計算數(shù)據(jù)集的平均樣本距離
2021-03-22 16:44:2217 針對目前多數(shù)聚類算法需要事先確定網(wǎng)絡(luò)用戶行為數(shù)據(jù)規(guī)模以及生成的簇標(biāo)簽缺乏明確語義的問題,提出一種用于網(wǎng)絡(luò)用戶行為聚類分析的簇標(biāo)簽自動生成方法。應(yīng)用潛在因子模型和矩陣分解方法對原始網(wǎng)絡(luò)用戶行為數(shù)據(jù)補(bǔ)充
2021-03-19 15:53:0215 度推薦算法。采用改進(jìn)的蜂群算法來優(yōu)化K- means++聚類的中心點,使聚類中心在整個數(shù)據(jù)內(nèi)達(dá)到最優(yōu),并對聚類結(jié)果進(jìn)行集成,使得聚類得到進(jìn)一步優(yōu)化。根據(jù)聚類結(jié)果,在同一類中采用改進(jìn)的用戶相似度算法來優(yōu)化傳統(tǒng)相似度算法,
2021-03-18 11:17:1110 核心的概念,設(shè)計軌跡密度計算函數(shù)以獲取聚類簇的致密核心軌跡,同時利用岀租車載客軌跡自身的方向和速度等屬性提取軌跡特征點,減少軌跡數(shù)據(jù)量。在此基礎(chǔ)上,根據(jù)聚類簇中致密核心軌跡與參與聚類軌跡的相似度距離判斷軌跡的匹配程度,進(jìn)而聚合相似軌跡,并將聚類
2021-03-11 17:40:3113 聚類算法,迭代地從數(shù)據(jù)集中篩選出多個中心點,以每個中心點為簇中心進(jìn)行局部聚類,并以中心點為頂點構(gòu)建圖,實現(xiàn)基于LGC的半監(jiān)督學(xué)習(xí)。實驗結(jié)果表明,優(yōu)化后的LGC方法在D31、 Aggregation等數(shù)據(jù)集上具有較好的魯棒性,在標(biāo)注正確率
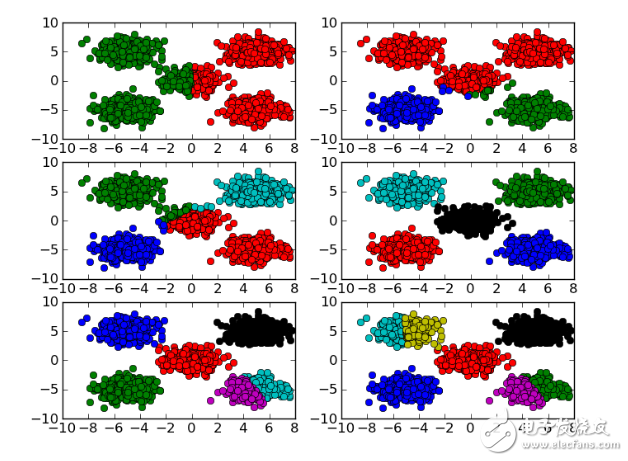
2021-03-11 11:21:5721 幾張GIF理解K-均值聚類原理k均值聚類數(shù)學(xué)推導(dǎo)與python實現(xiàn)前文說了k均值聚類,他是基于中心的聚類方法,通過迭代將樣本分到k個類中,使...
2020-12-10 21:56:09216 這一最著名的聚類算法主要基于數(shù)據(jù)點之間的均值和與聚類中心的聚類迭代而成。它主要的優(yōu)點是十分的高效,由于只需要計算數(shù)據(jù)點與劇類中心的距離,其計算復(fù)雜度只有O(n)。
2020-04-15 15:23:2914904 針對聚類算法的聚類中心選取需要人工參與的問題,提出了一種基于拉普拉斯中心性和密度峰值的無參數(shù)聚類算法( ALPC)。首先,使用拉普拉斯中心性度量對象的中心性;然后,使用正態(tài)分布概率統(tǒng)計方法確定聚類
2019-01-03 15:36:2412 聚類分析是將研究對象分為相對同質(zhì)的群組的統(tǒng)計分析技術(shù),聚類分析的核心就是發(fā)現(xiàn)有用的對象簇。K-means聚類算法由于具有出色的速度和良好的可擴(kuò)展性,一直備受廣大學(xué)者的關(guān)注。然而,傳統(tǒng)的K
2018-12-20 10:28:2910 K-means算法是被廣泛使用的一種聚類算法,傳統(tǒng)的-means算法中初始聚類中心的選擇具有隨機(jī)性,易使算法陷入局部最優(yōu),聚類結(jié)果不穩(wěn)定。針對此問題,引入多維網(wǎng)格空間的思想,首先將樣本集映射到一個
2018-12-13 17:56:551 針對傳統(tǒng)K-means型算法的“均勻效應(yīng)”問題,提出一種基于概率模型的聚類算法。首先,提出一個描述非均勻數(shù)據(jù)簇的高斯混合分布模型,該模型允許數(shù)據(jù)集中同時包含密度和大小存在差異的簇;其次,推導(dǎo)了非均勻
2018-12-13 10:57:5910 )2個步驟,以提高平衡聚類算法的聚類效果與時間性能。首先基于模擬退火在數(shù)據(jù)集中快速定位出K個合適的數(shù)據(jù)點作為平衡聚類初始點,然后每個中心點分階段貪婪地將距離其最近的數(shù)據(jù)點加入簇中直至達(dá)到簇規(guī)模上限。在6個UCI真實數(shù)據(jù)集與2個公開圖
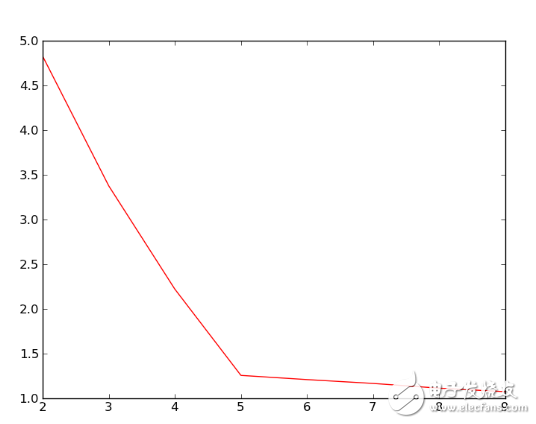
2018-11-28 09:53:067 同時,k值的選取也會直接影響聚類結(jié)果,最優(yōu)聚類的k值應(yīng)與樣本數(shù)據(jù)本身的結(jié)構(gòu)信息相吻合,而這種結(jié)構(gòu)信息是很難去掌握,因此選取最優(yōu)k值是非常困難的。
2018-07-24 17:44:2118293 
模糊c劃分空間為:即有c個類,共N個數(shù)據(jù)(樣本),對于某一樣本,其在所有類的隸屬度值和為1,對于某一個類,所有數(shù)據(jù)的隸屬度值和小于N。
模糊聚類從某種程度上說就是找到聚類中心。
2018-06-15 08:00:0012 無監(jiān)督學(xué)習(xí)是機(jī)器學(xué)習(xí)技術(shù)中的一類,用于發(fā)現(xiàn)數(shù)據(jù)中的模式。本文介紹用Python進(jìn)行無監(jiān)督學(xué)習(xí)的幾種聚類算法,包括K-Means聚類、分層聚類、t-SNE聚類、DBSCAN聚類等。
2018-05-27 09:59:1329359 
與K均值相比最大的優(yōu)點是我們無需指定指定聚類數(shù)目,聚類中心處于最高密度處也是符合直覺認(rèn)知的結(jié)果。但其最大的缺點在于滑窗大小r的選取,對于結(jié)果有著很大的影響。
2018-05-25 17:10:5137147 
本文針對k-medoids算法具有初始點選取復(fù)雜、聚類迭代時間久、中心點選取消耗資源過多等缺點,使用Hadoop平臺下的MapReduce編程框架對算法進(jìn)行初始點的點密度計算選取并行化、非中心點分配并行化和中心點更新并行化等方面的改進(jìn)。
2018-05-18 09:06:394585 
相關(guān)研究領(lǐng)域的廣泛關(guān)注。因此,多位學(xué)者對如何將FCM算法拓展到直覺模糊領(lǐng)域進(jìn)行了研究,賀正洪將聚類對象及聚類中心點用直覺模糊集表示,提出基于直覺模糊集合的模糊c均值算法。申曉勇聚類對象和聚類中心點及兩者間的關(guān)系均推廣到直覺模糊領(lǐng)域,提出了一種基于目標(biāo)函數(shù)的
2018-03-14 10:08:431 的路徑覆蓋為準(zhǔn)則,對每個測試用例進(jìn)行量化,使每個用例變成一個點。以黑盒測試的功能需求數(shù)作為聚類數(shù),在聚類結(jié)果的每一簇中,按照離中心點的距離進(jìn)行排序,依次從每一簇中選擇測試用例,直至滿足所有測試需求,得到約簡的測試用例集
2018-03-12 15:06:230 propa-gation)聚類方法,采取直接關(guān)聯(lián)與簇中心距離較近樣本的方法,減少聚類樣本數(shù)量,降低聚類時空消耗,并依據(jù)關(guān)聯(lián)結(jié)果,不斷調(diào)整聚類參數(shù),精確聚類結(jié)果。2個網(wǎng)絡(luò)安全數(shù)據(jù)集的應(yīng)用結(jié)果表明,該方法可從大規(guī)模樣本中有效聚出代表性子集,在保
2018-03-06 15:15:550 總體的聚類。將該思想應(yīng)用于大文本數(shù)據(jù)集的聚類問題后,過分簇中心之間的相似性度度量方法可以采用常用的余弦距離法。在20-Newgroups大本數(shù)據(jù)上的實驗結(jié)果表明:間接譜聚類算法在聚類準(zhǔn)確性上比K-Means算法平均高出14. 72%;比規(guī)范割譜聚類僅
2018-02-24 14:43:590 函數(shù)的值,以此值的大小來判斷數(shù)據(jù)點屬于某簇的程度;然后,將所提方法運用到數(shù)據(jù)流聚類的在線一離線框架中;最后,采用真實數(shù)據(jù)集KDD-CUP99和隨機(jī)生成的人工數(shù)據(jù)集進(jìn)行算法的測試。實驗結(jié)果表明,所提方法的聚類純度在92%以上
2018-02-10 11:54:340 針對互聯(lián)網(wǎng)流量標(biāo)注困難以及單個聚類器的泛化能力較弱,提出一種基于互信息( MI)理論的選擇聚類集成方法,以提高流量分類的精度。首先計算不同初始簇個數(shù)K的K均值聚類結(jié)果與訓(xùn)練集中流量協(xié)議的真實分布之間
2018-02-09 10:35:560 考慮到無線傳感器網(wǎng)絡(luò)(WSN)負(fù)載不均衡導(dǎo)致節(jié)點存活時間較短、能量消耗量較多的問題,提出一種基于分布式層次化結(jié)構(gòu)的非均勻
聚類負(fù)載均衡算法( DCWSN)。首先,建立了一個WSN的多層分
簇的網(wǎng)絡(luò)拓?fù)?/div>
2018-01-16 17:45:420 識別的聚類算法來彌補(bǔ)這個缺失.利用數(shù)據(jù)對象及其相似度構(gòu)建帶權(quán)重的數(shù)據(jù)對象相似圖,聚類過程中,利用相似圖上重啟式隨機(jī)游走來動態(tài)地計算類簇與結(jié)點的相似度.聚類的基本邏輯是,類簇迭代地吸收離它最近的結(jié)點.提出數(shù)
2018-01-09 15:52:510 通過對基于K-means聚類的缺失值填充算法的改進(jìn),文中提出了基于距離最大化和缺失數(shù)據(jù)聚類的填充算法。首先,針對原填充算法需要提前輸入聚類個數(shù)這一缺點,設(shè)計了改進(jìn)的K-means聚類算法:使用數(shù)據(jù)間
2018-01-09 10:56:560 得出多重桶標(biāo)記,再對數(shù)據(jù)集各桶標(biāo)記進(jìn)行聚類得出多個基劃分,最后對多個基劃分進(jìn)行集成得出最終劃分。實驗結(jié)果表明,在準(zhǔn)確率方面,集成式位置敏感聚類在人工數(shù)據(jù)上與k-means結(jié)合聚類集成的方法相當(dāng),在圖像集上與k-means結(jié)
2018-01-08 16:38:030 。首先,利用主動表觀模型快速、準(zhǔn)確地對人臉特征點進(jìn)行定位,獲取主要人臉信息;然后,對訓(xùn)練樣本進(jìn)行K-means聚類,將相似程度高的圖像分為一類,計算聚類中心,將該中心作為原子構(gòu)造過完備字典并進(jìn)行稀疏分解;最后,計算稀疏系數(shù)和重構(gòu)殘
2018-01-08 14:38:351 分布流形的復(fù)雜性,非線性聚類是最流行和最被廣泛研究的聚類問題之一。本文首先從四個角度對非線性聚類的近期工作做一個簡要的綜述,包括基于核的聚類算法、多中心點聚類算法、基于圖的聚類算法以及基于支持向量的聚類算
2018-01-03 14:31:460 針對傳統(tǒng)模糊C一均值( FCM)聚類算法初始聚類中心不確定,且需要人為預(yù)先設(shè)定聚類類別數(shù),從而導(dǎo)致結(jié)果不準(zhǔn)確的問題,提出了一種基于中點密度函數(shù)的模糊聚類算法。首先,結(jié)合逐步回歸思想作為初始聚類中心
2017-12-26 15:54:200 針對大數(shù)據(jù)環(huán)境下K-means聚類算法聚類精度不足和收斂速度慢的問題,提出一種基于優(yōu)化抽樣聚類的K-means算法(OSCK)。首先,該算法從海量數(shù)據(jù)中概率抽樣多個樣本;其次,基于最佳聚類中心的歐氏
2017-12-22 15:47:180 criteria PAM)算法為基礎(chǔ)給出兩個加速引理。并基于中心點之間距離不等式提出兩個新加速定理.同時,以O(shè)(n+K2)額外內(nèi)存空間開銷輔助引理、定理的結(jié)合而提出加速SPAM(speed up PAM)聚類算法
2017-12-22 15:35:470 基于最近鄰距離分布的空間聚類方法,這個算法是基于這樣一個假設(shè),假設(shè)在數(shù)據(jù)空間的某個特定部分,一個聚類內(nèi)部的點是均勻分布的。實驗分析表明,該方法不僅能發(fā)現(xiàn)任意形狀的簇,而且對于大型空間數(shù)據(jù)庫是高效有用的。
2017-12-19 11:30:290 空間聚類是空間數(shù)據(jù)挖掘和知識發(fā)現(xiàn)領(lǐng)域的主要研究方向之一,但點目標(biāo)空間分布密度的不均勻、分布形狀的多樣化,以及多橋鏈接問題的存在,使得基于距離和密度的聚類算法不能高效且有效地識別聚集性高的點目標(biāo)。提出
2017-12-19 10:47:320 過程進(jìn)行研究,不需要對數(shù)據(jù)集進(jìn)行反復(fù)聚類。首先,掃描數(shù)據(jù)集獲得所有聚類特征的統(tǒng)計值;其次,自底向上地生成不同層次的數(shù)據(jù)劃分,計算每個劃分?jǐn)?shù)據(jù)點的密度,將最大密度點定為中心點,計算中心點距離更高密度點的最小距離,以中
2017-12-17 11:27:400 針對原始K-means聚類算法受初始聚類中心影響過大以及容易陷入局部最優(yōu)的不足,提出一種基于改進(jìn)布谷鳥搜索(cs)的K-means聚類算法(ACS-K-means)。其中,自適應(yīng)CS( ACS)算法
2017-12-13 17:24:063 為了提高在大容量指紋數(shù)據(jù)庫中指紋識別率的速度和正確率,也為了提取出更多的細(xì)節(jié)特征,提出了一種旋正圖像并使用中心點特征進(jìn)行指紋分類的方法。首先,根據(jù)指紋圖像的最小外接橢圓和矩形,獲得旋轉(zhuǎn)角度并對指紋
2017-12-12 18:32:380 的算法。首先,通過各向異性擴(kuò)散處理圖像;然后,使用一維K-均值對像素進(jìn)行聚類;最后,根據(jù)聚類結(jié)果和先驗知識將像素值修改為最佳類中心像素值。理論分析表明該算法可以使圖像的峰值信噪比( PSNR)達(dá)到最大值。實驗結(jié)果表明:所
2017-12-06 16:44:110 局部最優(yōu)出現(xiàn)錯誤的聚類結(jié)果。針對傳統(tǒng)的k-means算法初始聚類中心的缺點,本文提出了p-K-means算法,該算法采用了數(shù)學(xué)幾何距離的方法改進(jìn)k-means算法中初始聚類中心分布不均勻的現(xiàn)象多個聚類中心出現(xiàn)在同一類簇中的現(xiàn)象,這種方法能避免k-m
2017-12-05 18:32:540 。針對這個問題,提出了折半聚類算法(BCA)。該算法結(jié)合了圍繞中心點聚類和基于網(wǎng)格聚類兩類方式,并利用二分法查找思想劃分網(wǎng)格,不需要反復(fù)聚類。先將數(shù)據(jù)用二分法劃分成網(wǎng)格,再根據(jù)網(wǎng)格內(nèi)數(shù)據(jù)密度選出核心網(wǎng)格,接著以核心網(wǎng)格為中心將鄰居網(wǎng)格聚
2017-12-03 10:53:040 K-means算法是最簡單的一種聚類算法。算法的目的是使各個樣本與所在類均值的誤差平方和達(dá)到最小(這也是評價K-means算法最后聚類效果的評價標(biāo)準(zhǔn))
2017-12-01 14:07:3319244 
密度和增加軌跡數(shù)據(jù)關(guān)鍵點密度權(quán)值的方式選取高密度的軌跡數(shù)據(jù)點作為初始聚類中心進(jìn)行K-means聚類,然后結(jié)合聚類有效函數(shù)類內(nèi)類外劃分指標(biāo)對聚類結(jié)果進(jìn)行評價,最后根據(jù)評價確定最佳聚類數(shù)目和最優(yōu)聚類劃分。理論研究與實驗結(jié)果表明,該算法能
2017-11-25 11:35:380 針對受均勻效應(yīng)的影響,當(dāng)前K-means型軟子空間算法不能有效聚類不平衡數(shù)據(jù)的問題,提出一種基于劃分的不平衡數(shù)據(jù)軟子空間聚類新算法。首先,提出一種雙加權(quán)方法,在賦予每個屬性一個特征權(quán)重的同時,賦予
2017-11-25 11:33:370 和Wine數(shù)據(jù)集上將其與FCM、KMEANS算法進(jìn)行比較實驗。實驗結(jié)果表明,SDSCM在評價指標(biāo)語義強(qiáng)度期望上高于FCM、KMEANS l%~5%。SDSCM的SPT指標(biāo)低于FCM、KMEANS,算法的類間分離度有待提高。SDSCM較好地解決了傳統(tǒng)減法聚類人工輸入?yún)?shù)1和2帶來的弊端,并給出了更貼近用戶給定
2017-11-25 10:45:420 挖掘其聚類關(guān)系,選取初始聚類中心,避免了傳統(tǒng)k-means算法對隨機(jī)選取初始聚類中心的敏感性,減少了k-means算法的迭代次數(shù)。又結(jié)合MapReduce框架將算法整體并行化,并通過Partition、Combine等機(jī)制加強(qiáng)了并行化程度和執(zhí)行效率。實驗表明,該算法不僅提高了聚
2017-11-24 14:24:322 算法(FCM)的最終聚類結(jié)果依賴于其初始值的選取,也解決了其容易陷入局部最優(yōu)解的問題。通過將SACA FCM算法和FCM算法聚類數(shù)據(jù)流的實驗結(jié)果進(jìn)行對比,得出采用SACAFCM算法聚類數(shù)據(jù)流會取得較好的效果。
2017-11-22 11:51:139 之間及類簇之間的相似度,采用邊聚類邊提取符合要求類簇的方式,能快速有效地對數(shù)據(jù)幀進(jìn)行聚類;并且該算法能自動地確定聚類的個數(shù),所得的類簇含有相似度評價指標(biāo)。利用林肯實驗室公布的數(shù)據(jù)集進(jìn)行測試,說明該算法能以
2017-11-21 08:58:250 檢測算法檢測斑點,并提取出斑點數(shù)量、大小和分布等特征值生成特征向量,再使用SVM進(jìn)行點刺(瘀點)舌象識別。點刺(瘀點)提取同樣基于斑點檢測算法,提取斑點顏色特征,使用K均值聚類將斑點聚類為多個小類簇,定義基于加權(quán)顏色空間距離的判別函數(shù),將聚類結(jié)果
2017-11-20 11:34:584 傳統(tǒng)kmeans算法由于初始聚類中心的選擇是隨機(jī)的,因此會使聚類結(jié)果不穩(wěn)定。針對這個問題,提出一種基于離散量改進(jìn)k-means初始聚類中心選擇的算法。算法首先將所有對象作為一個大類,然后不斷從對象
2017-11-20 10:03:232 量測誤差和系統(tǒng)誤差設(shè)定不同閡值。并且引入聚類簇的極大極小值作為聚類特征,使用層次樹的方法來構(gòu)建聚類特征模型,實現(xiàn)了雷達(dá)偵察數(shù)據(jù)的快速向下搜索及聚類。實驗結(jié)果表明,該方法是可行、有效的。
2017-11-10 15:52:181 在數(shù)據(jù)挖掘算法中,K均值聚類算法是一種比較常見的無監(jiān)督學(xué)習(xí)方法,簇間數(shù)據(jù)對象越相異,簇內(nèi)數(shù)據(jù)對象越相似,說明該聚類效果越好。然而,簇個數(shù)的選取通常是由有經(jīng)驗的用戶預(yù)先進(jìn)行設(shè)定的參數(shù)。本文提出了一種
2017-11-03 16:13:0512 將物理或抽象對象的集合分成由類似的對象組成的多個類的過程被稱為聚類。由聚類所生成的簇是一組數(shù)據(jù)對象的集合,這些對象與同一個簇中的對象彼此相似,與其他簇中的對象相異。
2017-11-03 09:18:4815137 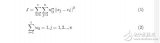
聚類生成的簇看成模糊集合。 從kmeans各個樣本所屬類別 的非此即彼(要么是0要么是1,如果建立一個歸屬矩陣Nk[Math Processing Error],每一行表示樣本的歸屬情況,則會得到,其中一個entry是1,其他是0),到走向模糊(Fuzzy),走向不確定性(此時的歸屬(
2017-08-28 19:53:5114 基于SVD的K_means聚類協(xié)同過濾算法_王偉
2017-03-17 08:00:000 基于聚類中心優(yōu)化的k_means最佳聚類數(shù)確定方法_賈瑞玉
2017-01-07 18:56:130 KUKA機(jī)器人TCP(工具中心點)設(shè)定.
2015-12-23 14:50:4936 介紹了K-means 聚類算法的目標(biāo)函數(shù)、算法流程,并列舉了一個實例,指出了數(shù)據(jù)子集的數(shù)目K、初始聚類中心選取、相似性度量和距離矩陣為K-means聚類算法的3個基本參數(shù)。總結(jié)了K-means聚
2012-05-07 14:09:1427 電壓敏電阻器對中心點不接地單相避雷電路圖
2010-04-02 17:39:241491 
該文針對K 均值聚類算法存在的缺點,提出一種改進(jìn)的粒子群優(yōu)化(PSO)和K 均值混合聚類算法。該算法在運行過程中通過引入小概率隨機(jī)變異操作增強(qiáng)種群的多樣性,提高了混合聚類
2010-02-09 14:21:2610 LEACH 是一種將整個網(wǎng)絡(luò)的能量負(fù)載平均分配到每個節(jié)點,從而降低能耗、延長網(wǎng)絡(luò)生命周期的低功耗自適應(yīng)分簇聚類路由協(xié)議。針對組網(wǎng)過程中存在簇頭分布不均及其選取方法不
2010-01-22 13:52:4825 文本聚類是中文文本挖掘中的一種重要分析方法。K 均值聚類算法是目前最為常用的文本聚類算法之一。但此算法在處理高維、稀疏數(shù)據(jù)集等問題時存在一些不足,且對初始聚類
2010-01-15 14:24:4610 為提高銀行存貸款數(shù)據(jù)集上的聚類質(zhì)量和聚類效率,本文做了下列工作:(1)定義了簇的直徑。(2)提出了利用距離尺度降維的中心距序降維法,證明了新方法在降維時能保持聚類質(zhì)量
2010-01-07 16:23:5712 復(fù)雜網(wǎng)絡(luò)聚類方法:網(wǎng)絡(luò)簇結(jié)構(gòu)是復(fù)雜網(wǎng)絡(luò)最普遍和最重要的拓?fù)鋵傩灾?具有同簇節(jié)點相互連接密集、異簇節(jié)點相互連接稀疏的特點.揭示網(wǎng)絡(luò)簇結(jié)構(gòu)的復(fù)雜網(wǎng)絡(luò)聚類方法對分析復(fù)
2009-10-31 08:58:3914 Web文檔聚類中k-means算法的改進(jìn)
介紹了Web文檔聚類中普遍使用的、基于分割的k-means算法,分析了k-means算法所使用的向量空間模型和基于距離的相似性度量的局限性,從而
2009-09-19 09:17:03913 
提出了一種多密度網(wǎng)格聚類算法GDD。該算法主要采用密度閾值遞減的多階段聚類技術(shù)提取不同密度的聚類,使用邊界點處理技術(shù)提高聚類精度,同時對聚類結(jié)果進(jìn)行了人工干預(yù)。G
2009-08-27 14:35:5811 中心點不解地道單相霹雷電路圖
2009-06-08 15:04:40328 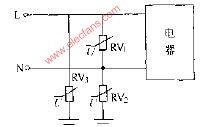
提出一種適用于公交站點聚類的DBSCAN改進(jìn)算法,縮小搜索半徑ε,從而提高聚類正確度,同時通過共享對象判定連接簇的合并,防止簇的過分割,減少噪聲點,有效地屏蔽了算法對輸
2009-04-23 09:26:0330 提出一種基于聚類的無限傳感器網(wǎng)絡(luò)相對定位算法,包括3個步驟,即將網(wǎng)絡(luò)分簇、各簇建立局部坐標(biāo)系并計算簇內(nèi)節(jié)點自身在局部坐標(biāo)系內(nèi)位置以及各局部坐標(biāo)系合并成全局坐標(biāo)系
2009-04-14 09:40:4922 提出了一種新的層次聚類算法,先對數(shù)據(jù)集進(jìn)行采樣,以采樣點為中心吸收鄰域內(nèi)的數(shù)據(jù)點形成子簇,再根據(jù)子簇是否相交實現(xiàn)層次聚類。在層次聚類過程中,重新定義了簇與簇
2009-03-03 11:48:1919  電子發(fā)燒友App
電子發(fā)燒友App










 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論