 電子發燒友App
電子發燒友App


聯機分析處理
聯機分析處理OLAP是一種軟件技術,它使分析人員能夠迅速、一致、交互地從各個方面觀察信息,以達到深入理解數據的目的。它具有FASMI(Fast Analysis of Shared Multidimensional Information),即共享多維信息的快速分析的特征。其中F是快速性(Fast),指系統能在數秒內對用戶的多數分析要求做出反應;A是可分析性(Analysis),指用戶無需編程就可以定義新的專門計算,將其作為分析的一部 分,并以用戶所希望的方式給出報告;M是多維性(Multi—dimensional),指提供對數據分析的多維視圖和分析;I是信息性(Information),指能及時獲得信息,并且管理大容量信息。
數據倉庫和聯機分析處理(OLAP)是決策支持基本要素,已經日益成為數據庫行業的重點。許多商業產品和服務現已推出,并且所有主要的數據庫管理系統供應商現在已經在這些領域提供產品。決策支持,相比于傳統的聯機事務處理應用程序,會有些不同的要求數據庫技術。本文提供的數據概述數據倉庫和OLAP技術,著眼于他們的新的要求。我們描述后端工具來提取,清潔和數據加載到數據倉庫;典型OLAP的多維數據模型;前端客戶端工具用于查詢和數據分析;服務器擴展來高效的查詢處理;用來管理元數據和倉庫工具。此外,勘測技術現狀,本文還指出了一些有前景的研究問題,其中一些涉及數據庫研究界合作多年的研究的問題,但其他一些問題只是剛剛開始被解決。本概述是基于一個教程,有作者們在會議VLDB 1996年提出。
1. 介紹
數據倉庫是決策支持技術的集合,旨在使知識工作者(總裁,經理,分析師)做出更快更好的決策。過去三年已經看到的爆炸性的增長,無論是在所提供的產品和服務的數量,還是在采用這些技術的工業領域。按照META集團說法,數據倉庫市場,包括硬件,數據庫軟件和工具,預計是由1995年的20億美金增長到1998年分80億美金。數據倉庫技術已經成功部署在許多行業:制造業(訂單運輸和客戶支持),零售(用于用戶分析和庫存管理),金融服務(理賠分析,風險分析,信用卡分析和欺詐檢測),交通(車隊管理),電信(呼叫分析和欺詐檢測),公用事業(電力使用分析)和醫療保健(對于結果的分析)。本文介紹了數據倉庫技術的路線圖,著重于有特殊需求的數據倉庫數據庫管理系統(DBMS)。
數據倉庫是一個“面向主題的,集成的,隨時間變化的,非易失性的,主要用于組織決策的數據集合。 ”通常情況下,數據倉庫用來分別維護組織的不同業務的數據庫。有很多原因來這么做。數據倉庫支持在線分析處理(OLAP ),它的功能和性能要求完全不同于由業務數據庫所支持的聯機事務處理( OLTP)應用程序。
OLTP應用程序通常使得文書數據處理任務自動化,如訂單錄入和銀行交易等一些組織的日常運作。這些任務是結構化和重復性,以及由短的,原子,孤立的交易。該交易需要詳細,最新的數據,通常通常訪問他們的主鍵來讀取或更新少數(幾十)記錄。操作數據庫往往是百兆到千兆字節。數據庫的一致性和可恢復性是至關重要的,最大化事務吞吐量是關鍵性能指標。因此,數據庫被設計為反映已知的應用,特別是的操作語義,以盡量減少并發沖突。
數據倉庫,相反的,是有針對性的決策支持。歷史,總結和整合的數據比詳細的,個人記錄更重要。由于數據倉庫包含合并數據,或許可以從幾個業務數據庫,在一段時間可能很長的時期,他們往往要比業務數據庫較大的訂單;企業數據倉庫預計為數百GB到TB級大小。工作負載大多是查詢密集型與臨時性的,復雜查詢可以訪問數以百萬計的記錄,并進行了大量的掃描,聯接和聚合。查詢吞吐量和響應時間比事務吞吐量更重要。
促進復雜的分析和可視化、數據倉庫通常多維建模。例如,在一個銷售數據倉庫,銷售,銷售區域、銷售人員和產品可能是一些感興趣的維度。通常,這些維度是分層次的;銷售時間可能是組織為day-month-quarter-year的層次結構,產品作為product-category-industry的層次結構。典型的OLAP操作包括上鉆(增加聚合的水平)和下鉆(減少聚合的水平或增加細節)以及一個或多個維度層次結構切割(選擇和投影),軸轉(調整的多維視圖的數據)。
由于已有的業務數據庫已經很好的支持已知的OLTP工作負載,所以試圖對業務數據庫執行復雜的OLAP查詢,將導致不可接受的性能。此外,決策支持需求的數據可能從業務數據庫中丟失;例如,了解趨勢或進行預測所需要歷史數據,而業務數據庫只存儲當前的數據。決策支持一般需要從多個不同來源的數據進行整合:這可能包括外部資源,如股票的市場反饋需要額外的幾個業務數據庫。不同的來源可能含有不同質量的數據,或使用不一致的陳述,代碼和格式,需要協調。最后,支持多維數據模型和操作的典型OLAP需要特殊的數據組織,訪問方式和實現方法,不是如一般的商業數據庫管理系統用來針對OLTP。由于這些原因,數據倉庫的實現有別于業務數據庫。
數據倉庫可能會實施在標準的或擴展的關系DBMS 上,就是所謂關系型OLAP(ROLAP )服務器。這些服務器假設數據存儲在關系數據庫,并且支持擴展SQL和特殊訪問及實施方法來有效實現多維數據模型和操作。相比之下,多維OLAP ( MOLAP)服務器直接把多維數據存儲在特定的數據結構(例如,數組),并實現了OLAP在這些特點的數據結構的操作。
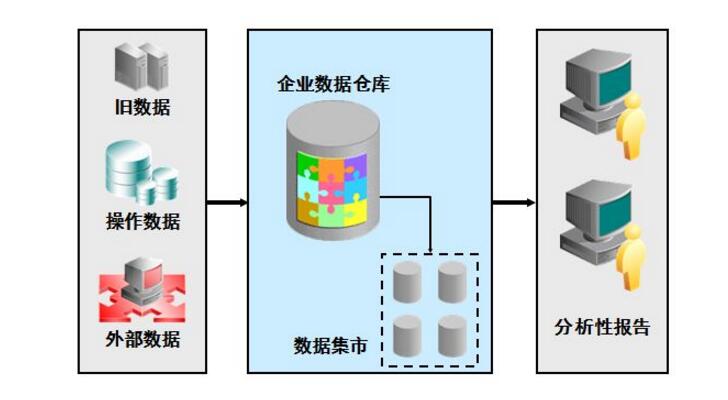
這不僅僅是建設和維護一個數據倉庫,還需要選擇一個OLAP服務器并為倉庫明確模式和一些復雜的查詢。存在著不同結構的替代品。許多組織希望實施綜合性企業的倉庫,收集跨越整個組織的所有科目(例如,客戶,產品信息,銷售,資產,人員)。然而,構建企業級數據倉庫是一個漫長而復雜的過程,需要廣泛的業務建模,可能需要多年才能成功。相反的,一些組織滿足于數據集市,它是針對選定的科目的子集(例如,營銷數據可能包括客戶,產品和銷售信息) 。這些數據集市實現更快的推算,因為它們不需要企業廣泛的共識,但如果一個完整的商業模式并不發達的話,從長遠來看,它們可能會導致復雜的集成問題。
在第2節,我們描述了一個典型的數據倉庫體系結構,和設計和操作數據倉庫的過程。在3-7節,我們回顧了在數據加載相關技術和刷新數據倉庫,倉庫服務器,前端工具和倉庫管理工具。在每一種情況下,我們指出什么是傳統的數據庫技術不同的,我們會提到有代表性的產品。在本文中,我們不打算提供每個類別的所有產品的綜合描述。我們鼓勵有興趣的讀者看看在最近的商業雜志,如Databased Advisor, Database Programming,Design, Datamation,DBMS Magazine, vendors’ Web sites來獲取商業產品,白皮書和案例研究的更多細節。OLAP Council是在整個行業的標準化工作上一個很好的信息源。還有科德等人的論文定義了OLAP產品的12條規則。還有,Data Warehousing Information Center是數據倉庫和OLAP良好的資源。
數據倉庫的研究是相當新的,并一直專注的主要是查詢處理和視圖維護問題。還有很多開放性的研究問題,在第8節,我們會簡要提及的這些問題并得出結論。
2. 架構與端到端流程
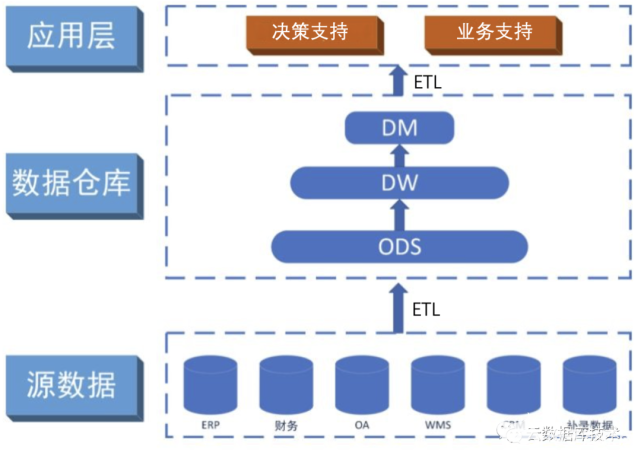
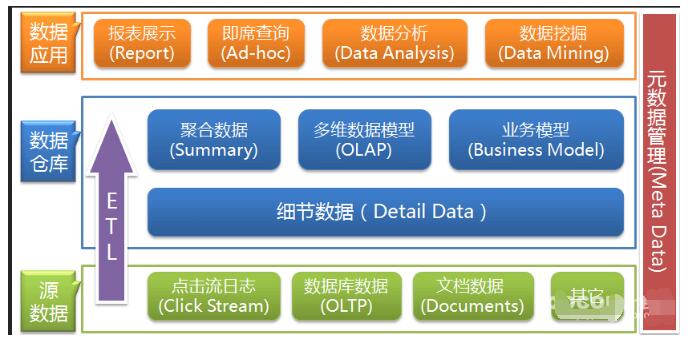
圖1是一個典型的數據倉庫架構。
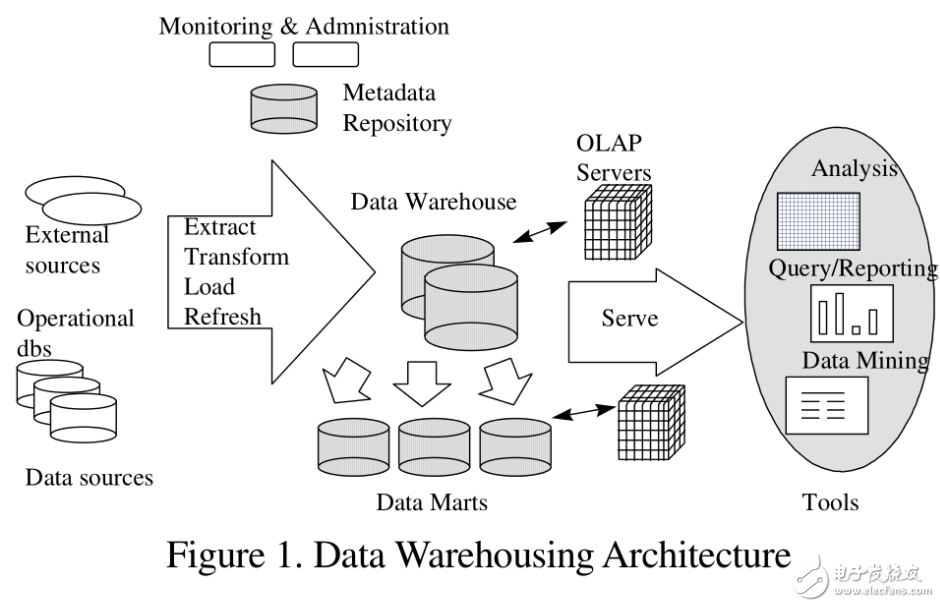
它包括一些工具。這些工具可以用來從多種操作數據庫和外部源中提取數據,并清洗、轉換和整合這些數據,然后把數據加載到數據倉庫;定期刷新倉庫來更新的源和清除倉庫的數據,或者是慢歸檔存儲。除了主倉庫,可能會有好幾個部門數據集市。存儲在數據倉庫和數據集市的數據,由一個或多個倉庫服務器管理,并呈現數據的多維視圖給不同的前端工具,如:查詢工具、報告作者、分析工具和數據挖掘工具。最后,還有一個存儲庫,用于存儲和管理元數據,并為監測和管理倉儲系統。
倉庫可能被設計成分布式,以來得到負載均衡,可伸縮性和高可用性。在這樣一個分布式體系結構,元數據存儲庫通常是在每個節點的倉庫都進行備份的,整個倉庫集中管理的。另一個體系結構,是倉庫或數據集市的聯合,每個倉庫或者數據集市都有自己的貯存和分級管理。該設計實現力求使用方便,所以可能花費過于昂貴的代價來構造一個邏輯集成的企業倉庫。
設計和推出一個數據倉庫是一個復雜的過程,包括以下活動:
定義體系結構,容量規劃,并選擇存儲服務器、數據庫和OLAP服務器和工具。
整合服務器、存儲和客戶端工具。
設計倉庫表和視圖。
定義物理倉庫組織,數據布局、分區和訪問方法。
使用網關、ODBC驅動程序,或其他的包裝器連接數據源,。
設計和實現數據提取、清洗、轉換、加載和刷新的腳本。
貯存表和視圖的定義、腳本和其他元數據。
設計和實現終端用戶應用程序。
推出倉庫和應用程序。
3. 后端工具和實用程序
數據倉庫系統使用各種數據提取和清洗工具,錄入倉庫的加載和更新的實用程序。通常外來源的數據提取的實現需要通過網關和標準接口(如Information Builders EDA/SQL, ODBC, Oracle Open Connect, Sybase Enterprise Connect, Informix Enterprise Gateway)。
數據清洗
由于數據倉庫是用于決策,數據倉庫中的數據正確性的非常重要的。然而,因為大量的數據來自多個參與的數據源,數據中出現錯誤和異常的概率很高。因此,幫助檢測數據的異常和對其改正的工具,可以帶來很高高效益。在一些情況下,數據清洗顯得非常有必要:字段長度不一致,不一致的描述,不一致的價值分配,缺失的條目和違背完整性約束。可想而知,數據錄入表中的可選字段是不一致數據的重要來源。
有三個相關,但不同的類數據清理工具。數據遷移工具可以制定簡單轉換規則,例如,用性別種類來替換性別字符串。Prism的Warehouse Manager是這種類型的工具中比較流行的一個。數據清理工具使用特定領域的知識(如郵政地址)來對數據進行清理。他們經常利用解析和模糊匹配技術來完成來著多個源的清洗。一些工具可以指定源的“相對清洗”。 Integrity和Trillum等工具屬于此類。數據審計工具可以通過掃描數據從而發現規則和關系(或提醒違背了規定的規則)。因此,這樣的工具可以認為是數據挖掘工具的變體。這樣的工具可能會發現一個可疑的樣本(基于統計分析),例如,某汽車經銷商從未收到任何投訴。
加載
提取、清洗和轉換后,數據必須被加載到倉庫。額外的預處理可能仍然被需要:檢查完整性約束;排序;通過總結、聚合和其他計算來建立存儲在倉庫中的派生表;創建目錄和其他訪問路徑;分區實現多個目標存儲區域。通常情況下,批量裝載工具可以用來做這件事。除了填充倉庫,一個負載工具必須允許系統管理員監控狀態,取消、掛起和恢復一個負載,失敗后重啟而沒有損失數據的完整性。
數據倉庫的加載工具必須處理比操作數據庫更大規模的數據量。只有一個小時間窗口中(通常在晚上),倉庫可以離線刷新它。連續加載會花費很長的時間,例如。,可以加載TB級的數據會花幾周和幾個月時間!因此,通常需要利用管線式和分區式的并行性。進行一個滿載的優勢在于它可以被視為一個長的批處理事務,來建立一個新的數據庫。雖然在運行中,但是當前數據庫仍然可以支持查詢;當負載事務提交時,當前數據庫被新的數據庫所取代。使用周期檢查點保證,如果加載過程中發生了失敗,這個進程可以從上個檢查點重啟。
然而,即使使用并行性,一個滿載可能仍然需要太長的時間。大多數商業工具(如,RedBrick Table Management Utility)在刷新過程中使用增量加載,來降低必須被納入倉庫的數據規模。只插入更新的元組。然而,這樣的加載過程更加難以管理了。增量加載會與正在進行的查詢起沖突,所以它被作為一個短事務(定期提交,如,每隔1000個記錄或每隔幾秒),但這樣一來這個事務的序列必須被設計,來確保導出數據與基礎數據的索引的一致性。






















 工商網監
工商網監
評論