 電子發燒友App
電子發燒友App


函數式編程是一種歷史悠久的編程范式。作為演算法,它的歷史可以追溯到現代計算機誕生之前的λ演算,本文希望帶大家快速了解函數式編程的歷史、基礎技術、重要特性和實踐法則。
在內容層面,主要使用JavaScript語言來描述函數式編程的特性,并以演算規則、語言特性、范式特性、副作用處理等方面作為切入點,通過大量演示示例來講解這種編程范式。同時,文末列舉比較一些此范式的優缺點,供讀者參考。
本文分為上下兩篇,上篇講述函數式編程的基礎概念和特性,下篇講述函數式編程的進階概念、應用及優缺點。函數式編程既不是簡單的堆砌函數,也不是語言范式的終極之道。我們將深入淺出地討論它的特性,以期在日常工作中能在對應場景中進行靈活應用。
1. 先覽:代碼組合和復用
在前端代碼中,我們現有一些可行的模塊復用方式,比如:
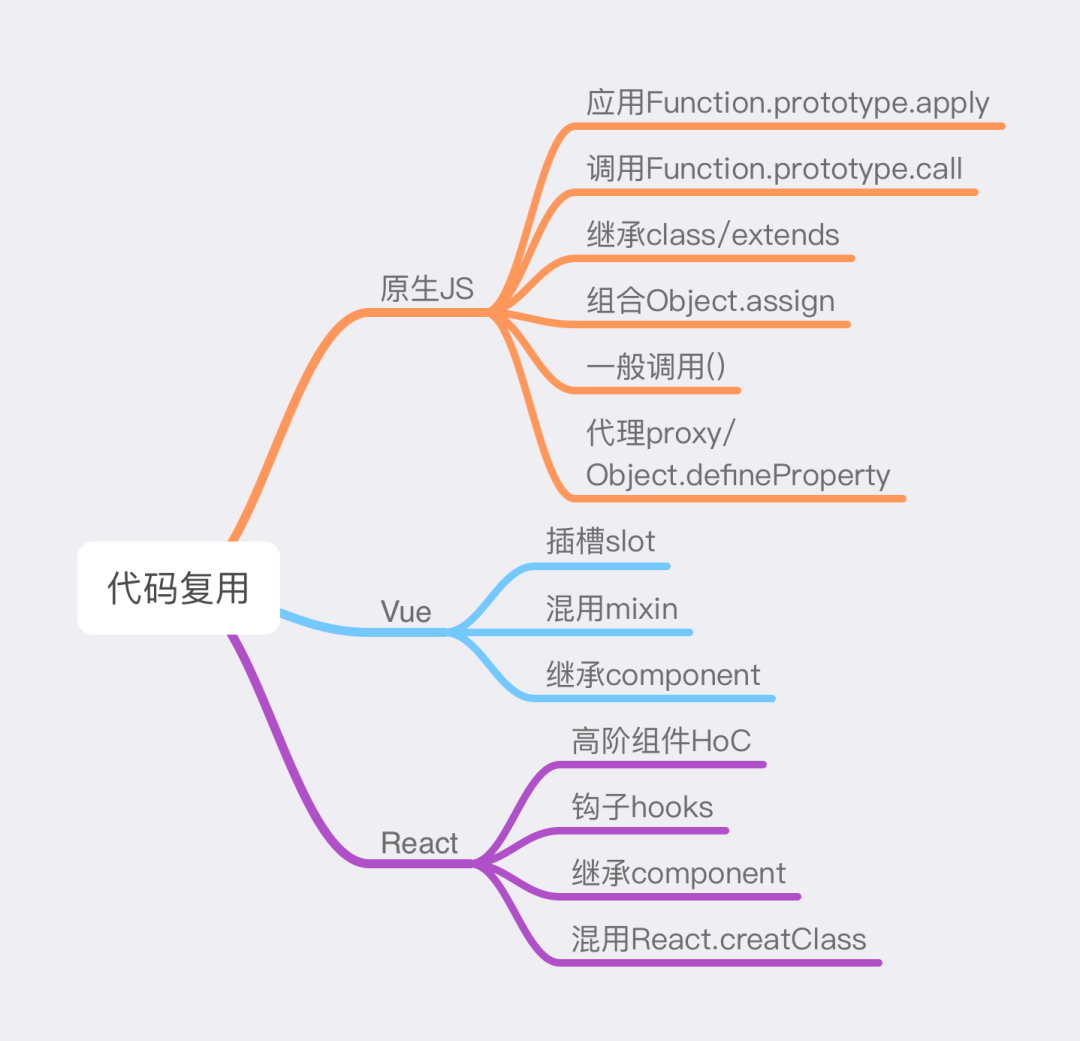
圖 1
除了上面提到的組件和功能級別的代碼復用,我們也可以在軟件架構層面上,通過選擇一些合理的架構設計來減少重復開發的工作量,比如說很多公司在中后臺場景中大量使用的低代碼平臺。
可以說,在大部分軟件項目中,我們都要去探索代碼組合和復用。
函數式編程,曾經有過一段黃金時代,后來又因面向對象范式的崛起而逐步變為小眾范式。但是,函數式編程目前又開始在不同的語言中流行起來了,像Java 8、JS、Rust等語言都有對函數式編程的支持。
今天我們就來探討JavaScript的函數,并進一步探討JavaScript中的函數式編程(關于函數式編程風格軟件的組織、組合和復用)。

圖 2
2. 什么是函數式編程?
2.1 定義
函數式編程是一種風格范式,沒有一個標準的教條式定義。我們來看一下維基百科的定義:
函數式編程是一種編程范式,它將電腦運算視為函數運算,并且避免使用程序狀態以及易變對象。其中,λ演算是該語言最重要的基礎。而且λ演算的函數可以接受函數作為輸入的參數和輸出的返回值。
我們可以直接讀出以下信息:
避免狀態變更
函數作為輸入輸出
和λ演算有關
那什么是λ演算呢?
2.2 函數式編程起源:λ演算
λ演算(讀作lambda演算)由數學家阿隆佐·邱奇在20世紀30年代首次發表,它從數理邏輯(Mathematical logic)中發展而來,使用變量綁定(binding)和代換規則(substitution)來研究函數如何抽象化定義(define)、函數如何被應用(apply)以及遞歸(recursion)的形式系統。
λ演算和圖靈機等價(圖靈完備,作為一種研究語言又很方便)。
通常用這個定義形式來表示一個λ演算。

圖 3
所以λ演算式就三個要點:
綁定關系。變量任意性,x、y和z都行,它僅僅是具體數據的代稱。
遞歸定義。λ項遞歸定義,M可以是一個λ項。
替換歸約。λ項可應用,空格分隔表示對M應用N,N可以是一個λ項。
比如這樣的演算式:

圖 4
通過變量代換(substitution)和歸約(reduction),我們可以像化簡方程一樣處理我們的演算。
λ演算有很多方式進行,數學家們也總結了許多和它相關的規律和定律(可查看維基百科)。
舉個例子,小時候我們學習整數就是學會幾個數字,然后用加法/減法來推演其他數字。在函數式編程中,我們可以用函數來定義自然數,有很多定義方式,這里我們講一種實現方式:

圖 5
上面的演算式表示有一個函數f和一個參數x。令0為x,1為f x,2為f f x...
什么意思呢?這是不是很像我們數學中的冪:a^x(a的x次冪表示a對自身乘x次)。相應的,我們理解上面的演算式就是數字n就是f對x作用的次數。有了這個數字的定義之后,我們就可以在這個基礎上定義運算。

圖 6 其中SUCC表示后繼函數(+1操作),PLUS表示加法。現在我們來推導這個正確性。 ?

圖 7
這樣,進行λ演算就像是方程的代換和化簡,在一個已知前提(公理,比如0/1,加法)下,進行規則推演。
2.2.1 演算:變量的含義
在λ演算中我們的表達式只有一個參數,那它怎么實現兩個數字的二元操作呢?比如加法a + b,需要兩個參數。
這時,我們要把函數本身也視為值,可以通過把一個變量綁定到上下文,然后返回一個新的函數,來實現數據(或者說是狀態)的保存和傳遞,被綁定的變量可以在需要實際使用的時候從上下文中引用到。
比如下面這個簡單的演算式:
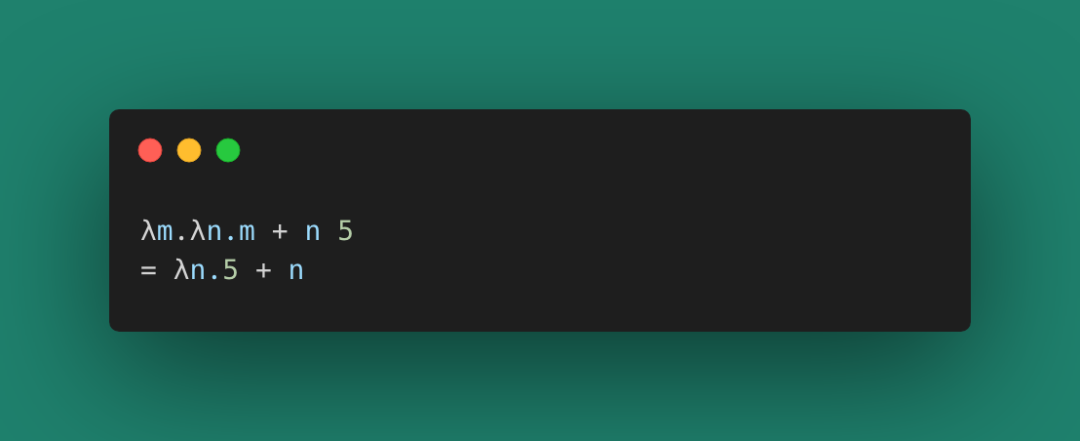
圖 8
第一次函數調用傳入m=5,返回一個新函數,這個新函數接收一個參數n,并返回m + n的結果。像這種情況產生的上下文,就是Closure(閉包,函數式編程常用的狀態保存和引用手段),我們稱變量m是被綁定(binding)到了第二個函數的上下文。
除了綁定的變量,λ演算也支持自由的變量,比如下面這個y:
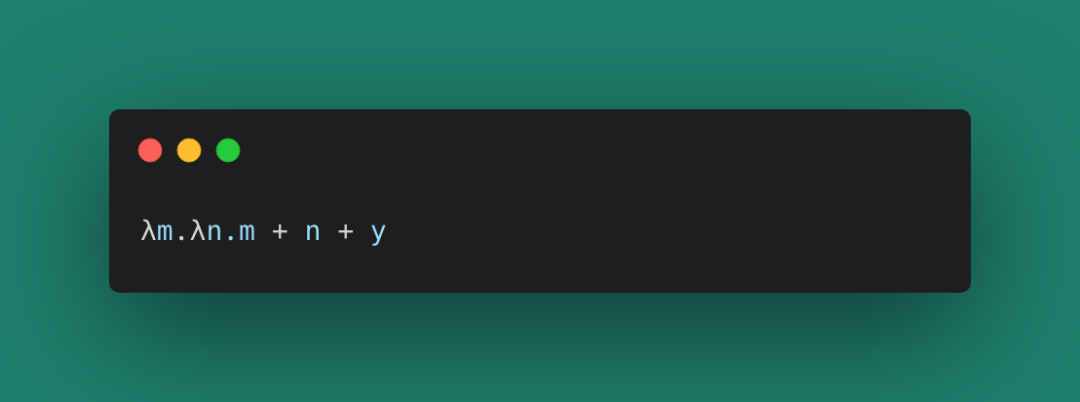
圖 9
這里的y是一個沒有綁定到參數位置的變量,被稱為一個自由變量。
綁定變量和自由變量是函數的兩種狀態來源,一個可以被代換,另一個不能。實際程序中,通常把綁定變量實現為局部變量或者參數,自由變量實現為全局變量或者環境變量。
2.2.2 演算:代換和歸約
演算分為Alpha代換和Beta歸約。前面章節我們實際上已經涉及這兩個概念,下面來介紹一下它們。
Alpha代換指的是變量的名稱是不重要的,你可以寫λm.λn.m + n,也可以寫λx.λy.x + y,在演算過程中它們表示同一個函數。也就是說我們只關心計算的形式,而不關心細節用什么變量去實現。這方便我們不改變運算結果的前提下去修改變量命名,以方便在函數比較復雜的情況下進行化簡操作。實際上,連整個lambda演算式的名字也是不重要的,我們只需要這種形式的計算,而不在乎這個形式的命名。
Beta歸約指的是如果你有一個函數應用(函數調用),那么你可以對這個函數體中與標識符對應的部分做代換(substitution),方式為使用參數(可能是另一個演算式)去替換標識符。聽起來有點繞口,但是它實際上就是函數調用的參數替換。比如:

圖 10
可以使用1替換m,3替換n,那么整個表達式可以化簡為4。這也是函數式編程里面的引用透明性的由來。需要注意的是,這里的1和3表示表達式運算值,可以替換為其他表達式。比如把1替換為(λm.λn.m + n 1 3),這里就需要做兩次歸約來得到下面的最終結果:

圖 11
2.3 JavaScript中的λ表達式:箭頭函數
ECMAScript 2015規范引入了箭頭函數,它沒有this,沒有arguments。只能作為一個表達式(expression)而不能作為一個聲明式(statement),表達式產生一個箭頭函數引用,該箭頭函數引用仍然有name和length屬性,分別表示箭頭函數的名字、形參(parameters)長度。一個箭頭函數就是一個單純的運算式,箭頭函數我們也可以稱為lambda函數,它在書寫形式上就像是一個λ演算式。

圖 12
可以利用箭頭函數做一些簡單的運算,下例比較了四種箭頭函數的使用方式:

圖 13
這是直接針對數字(基本數據類型)的情況,如果是針對函數做運算(引用數據類型),事情就變得有趣起來了。我們看一下下面的示例:

圖 14
fn_x類型,表明我們可以利用函數內的函數,當函數被當作數據傳遞的時候,就可以對函數進行應用(apply),生成更高階的操作。并且x => y => x(y)可以有兩種理解,一種是x => y函數傳入X => x(y),另一種是x傳入y => x(y)。
add_x類型表明,一個運算式可以有很多不同的路徑來實現。
上面的add_1/add_2/add_3我們用到了JavaScript的立即運算表達式IIFE。
λ演算是一種抽象的數學表達方式,我們不關心真實的運算情況,我們只關心這種運算形式。因此上一節的演算可以用JavaScript來模擬。下面我們來實現λ演算的JavaScript表示。
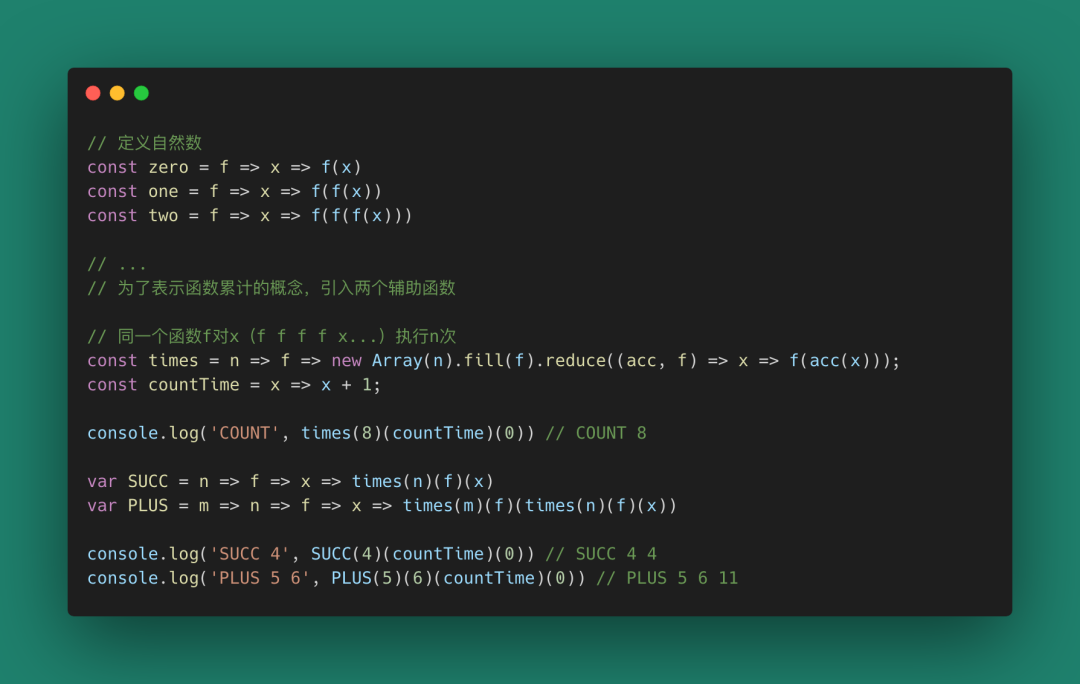
圖 15
我們把λ演算中的f和x分別取為countTime和x,代入運算就得到了我們的自然數。
這也說明了不管你使用符號系統還是JavaScript語言,你想要表達的自然數是等價的。這也側面說明λ演算是一種形式上的抽象(和具體語言表述無關的抽象表達)。
2.4 函數式編程基礎:函數的元、柯里化和Point-Free
回到JavaScript本身,我們要探究函數本身能不能帶給我們更多的東西?我們在JavaScript中有很多創建函數的方式:
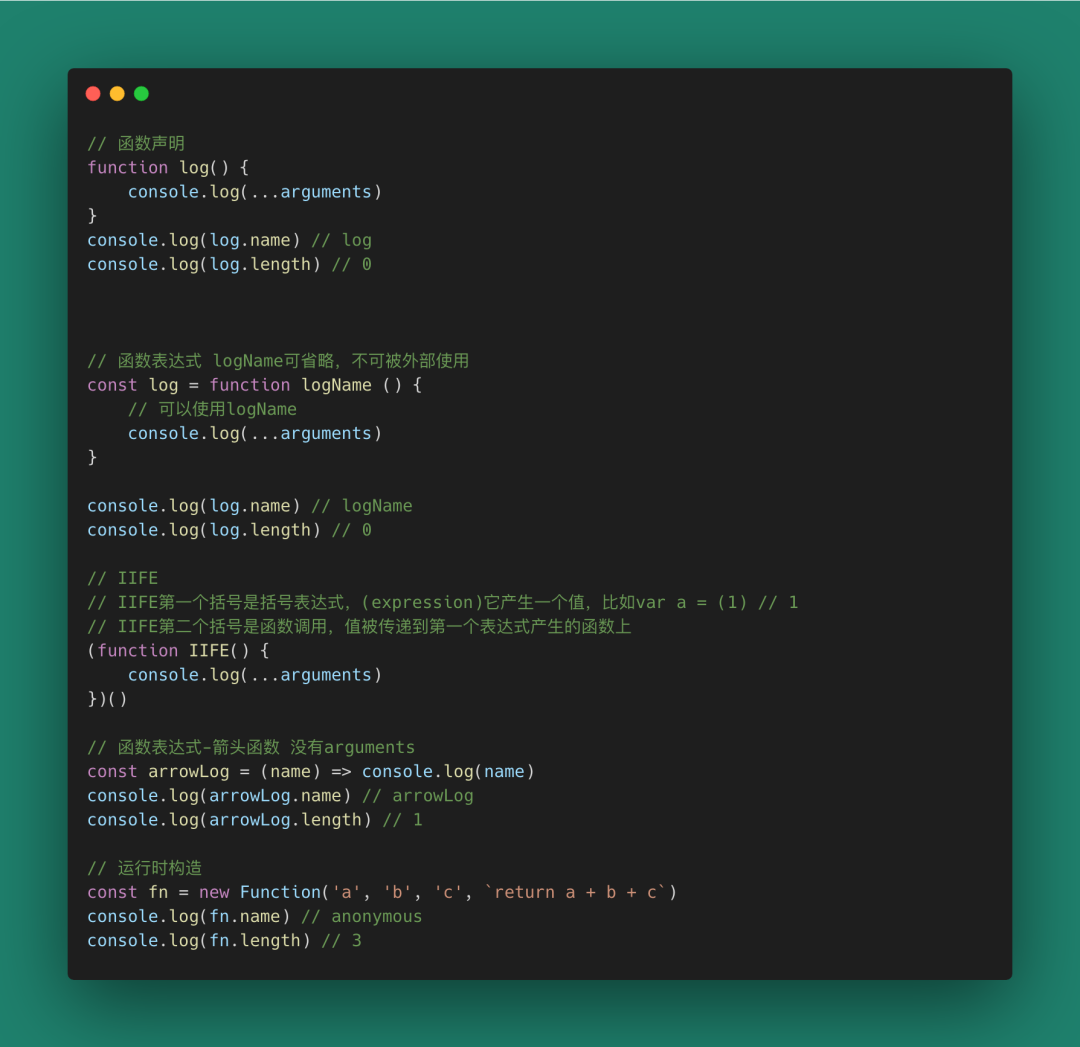
圖 16
雖然函數有這么多定義,但function關鍵字聲明的函數帶有arguments和this關鍵字,這讓他們看起來更像是對象方法(method),而不是函數(function) 。
況且function定義的函數大多數還能被構造(比如new Array)。
接下來我們將只研究箭頭函數,因為它更像是數學意義上的函數(僅執行計算過程)。
沒有arguments和this。
不可以被構造new。
2.4.1 函數的元:完全調用和不完全調用
不論使用何種方式去構造一個函數,這個函數都有兩個固定的信息可以獲取:
name 表示當前標識符指向的函數的名字。
length 表示當前標識符指向的函數定義時的參數列表長度。
在數學上,我們定義f(x) = x是一個一元函數,而f(x, y) = x + y是一個二元函數。在JavaScript中我們可以使用函數定義時的length來定義它的元。
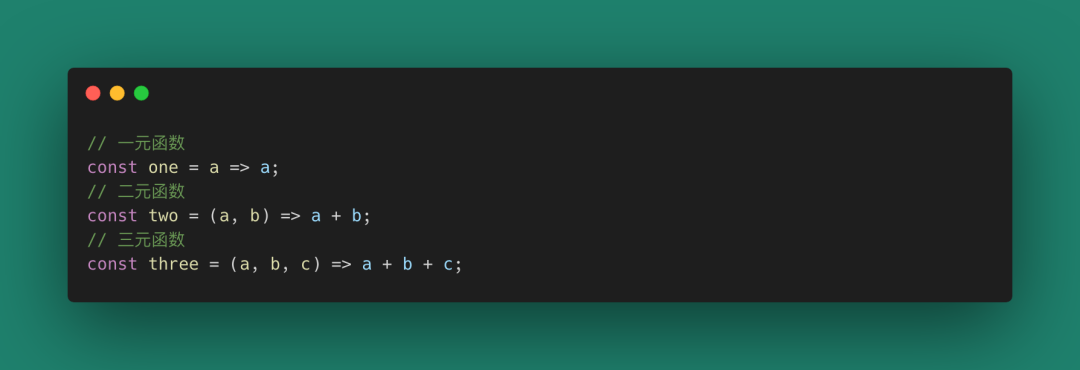
圖 17
定義函數的元的意義在于,我們可以對函數進行歸類,并且可以明確一個函數需要的確切參數個數。函數的元在編譯期(類型檢查、重載)和運行時(異常處理、動態生成代碼)都有重要作用。
如果我給你一個二元函數,你就知道需要傳遞兩個參數。比如+就可以看成是一個二元函數,它的左邊接受一個參數,右邊接受一個參數,返回它們的和(或字符串連接)。
在一些其他語言中,+確實也是由抽象類來定義實現的,比如Rust語言的trait Add
但我們上面看到的λ演算,每個函數都只有一個元。為什么呢?
只有一個元的函數方便我們進行代數運算。λ演算的參數列表使用λx.λy.λz的格式進行分割,返回值一般都是函數,如果一個二元函數,調用時只使用了一個參數,則返回一個“不完全調用函數”。這里用三個例子解釋“不完全調用”。
第一個,不完全調用,代換參數后產生了一個不完全調用函數 λz.3 + z。
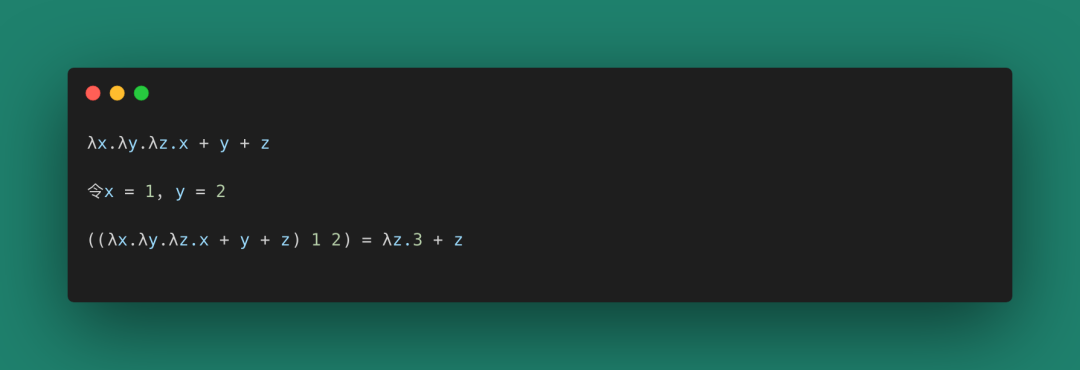
圖 18
第二個,Haskell代碼,調用一個函數add(類型為a -> a -> a),得到另一個函數add 1(類型為a -> a)。

圖 19
第三個,上一個例子的JavaScript版本。

圖 20
“不完全調用”在JavaScript中也成立。實際上它就是JavaScript中閉包(Closure,上面我們已經提到過)產生的原因,一個函數還沒有被銷毀(調用沒有完全結束),你可以在子環境內使用父環境的變量。
注意,上面我們使用到的是一元函數,如果使用三元函數來表示addThree,那么函數一次性就調用完畢了,不會產生不完全調用。
函數的元還有一個著名的例子(面試題):
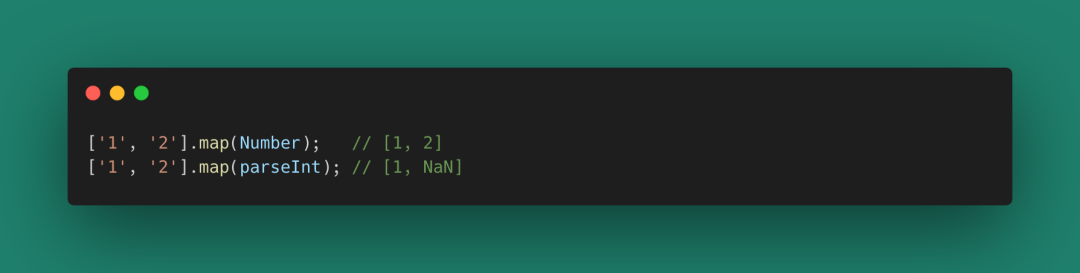
圖 21
造成上述結果的原因就是,Number是一元的,接受map第一個參數就轉換得到返回值;而parseInt是二元的,第二個參數拿到進制為1(map函數為三元函數,第二個參數返回元素索引),無法輸出正確的轉換,只能返回NaN。這個例子里面涉及到了一元、二元、三元函數,多一個元,函數體就多一個狀態。如果世界上只有一元函數就好了!我們可以全通過一元函數和不完全調用來生成新的函數處理新的問題。
認識到函數是有元的,這是函數式編程的重要一步,多一個元就多一種復雜度。
2.4.2 柯里化函數:函數元降維技術
柯里化(curry)函數是一種把函數的元降維的技術,這個名詞是為了紀念我們上文提到的數學家阿隆佐·邱奇。
首先,函數的幾種寫法是等價的(最終計算結果一致)。

圖 22
這里列一個簡單的把普通函數變為柯里化函數的方式(柯里化函數Curry)。
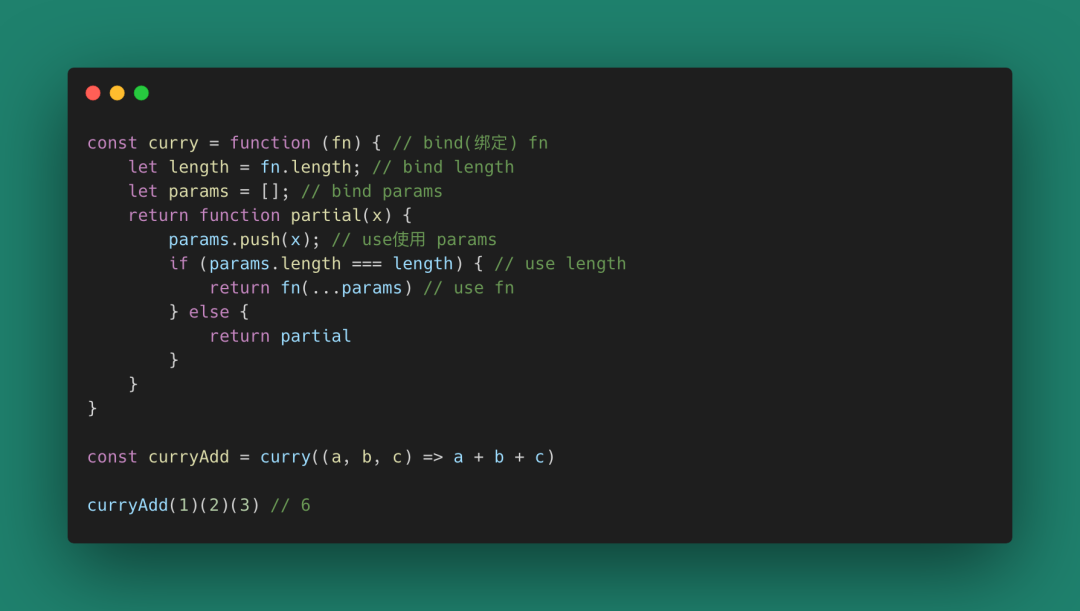
圖 23
柯里化函數幫助我們把一個多元函數變成一個不完全調用,利用Closure的魔法,把函數調用變成延遲的偏函數(不完全調用函數)調用。這在函數組合、復用等場景非常有用。比如:
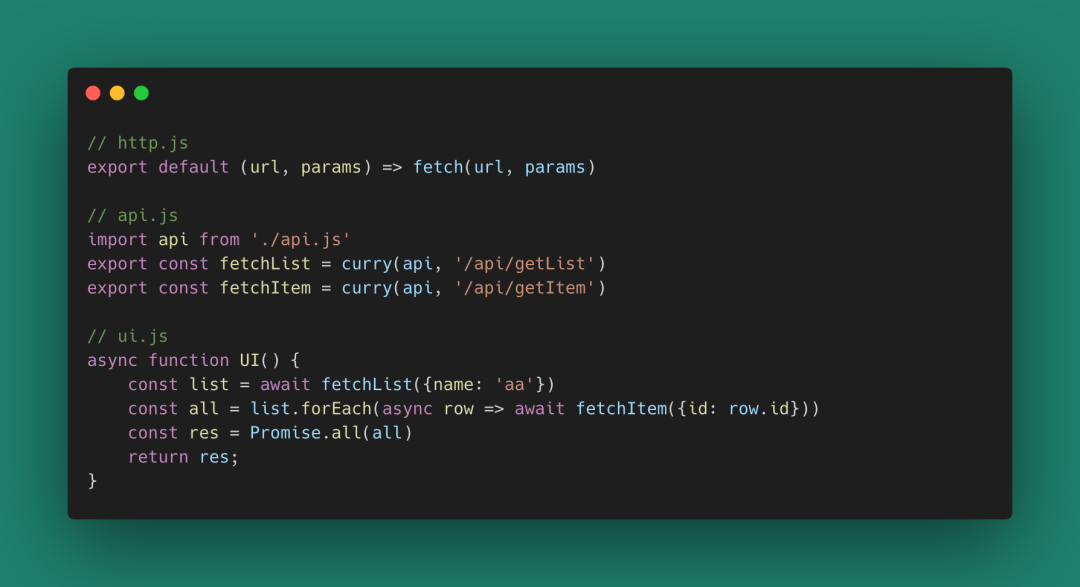
圖 24 雖然你可以用其他閉包方式來實現函數的延遲調用,但Curry函數絕對是其中形式最美的幾種方式之一。
2.4.3 Point-Free|無參風格:函數的高階組合
函數式編程中有一種Point-Free風格,中文語境大概可以把point認為是參數點,對應λ演算中的函數應用(Function Apply),或者JavaScript中的函數調用(Function Call),所以可以理解Point-Free就指的是無參調用。
來看一個日常的例子,把二進制數據轉換為八進制數據:
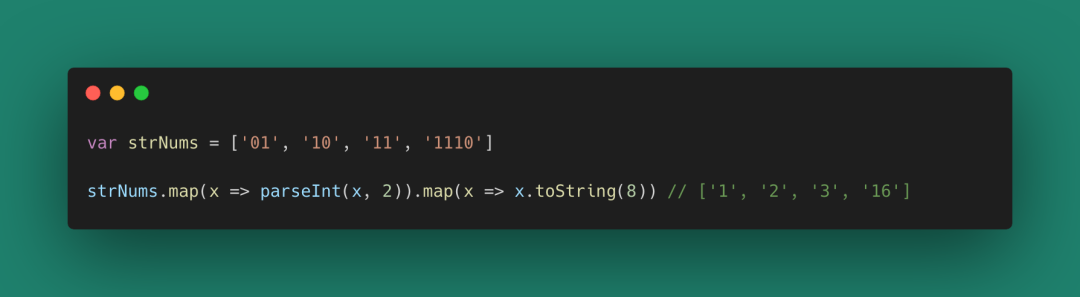
圖 25
這段代碼運行起來沒有問題,但我們為了處理這個轉換,需要了解 parseInt(x, 2) 和 toString(8) 這兩個函數(為什么有魔法數字2和魔法數字8),并且要關心數據(函數類型a -> b)在每個節點的形態(關心數據的流向)。有沒有一種方式,可以讓我們只關心入參和出參,不關心數據流動過程呢?
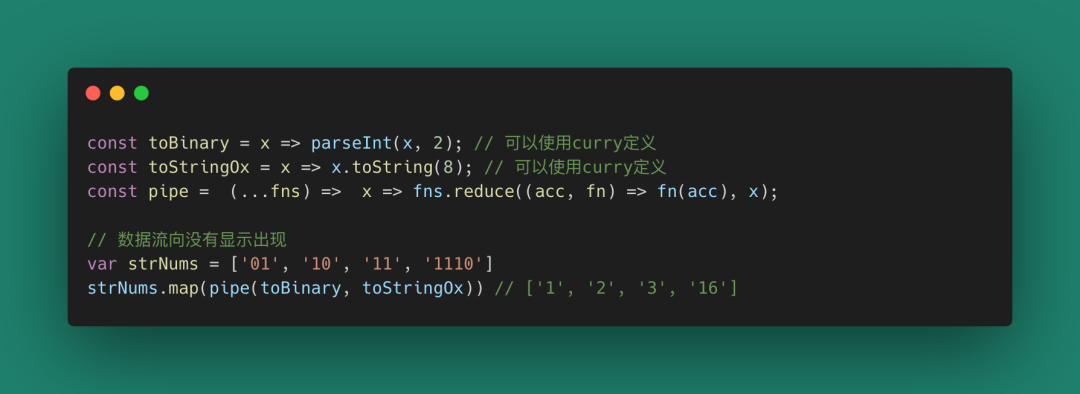
圖 26
上面的方法假設我們已經有了一些基礎函數toBinary(語義化,消除魔法數字2)和toStringOx(語義化,消除魔法數字8),并且有一種方式(pipe)把基礎函數組合(Composition)起來。如果用Typescript表示我們的數據流動就是:
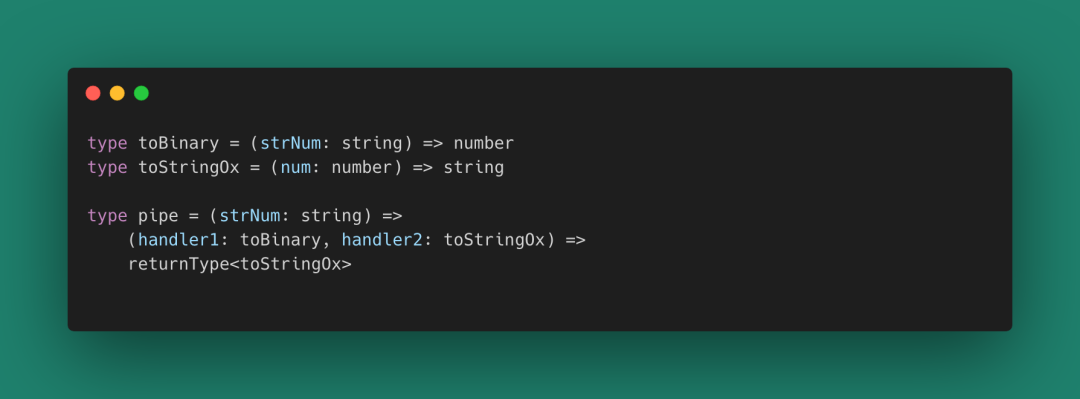
圖 27
用Haskell表示更簡潔,后面都用Haskell類型表示方式,作為我們的符號語言。

圖 28
值得注意的是,這里的x-> [int] ->y我們不用關心,因為pipe(..)函數幫我們處理了它們。pipe就像一個盒子。

圖 29
BOX內容不需要我們理解。而為了達成這個目的,我們需要做這些事:
utils 一些特定的工具函數。
curry 柯里化并使得函數可以被復用。
composition 一個組合函數,像膠水一樣粘合所有的操作。
name 給每個函數定義一個見名知意的名字。
綜上,Point-Free風格是粘合一些基礎函數,最終讓我們的數據操作不再關心中間態的方式。這是函數式編程,或者說函數式編程語言中我們會一直遇到的風格,表明我們的基礎函數是值得信賴的,我們僅關心數據轉換這種形式,而不是過程。JavaScript中有很多實現這種基礎函數工具的庫,最出名的是Lodash。
可以說函數式編程范式就是在不停地組合函數。
2.5 函數式編程特性
說了這么久,都是在講函數,那么究竟什么是函數式編程呢?在網上你可以看到很多定義,但大都離不開這些特性。
First Class 函數:函數可以被應用,也可以被當作數據。
Pure 純函數,無副作用:任意時刻以相同參數調用函數任意次數得到的結果都一樣。
Referential Transparency 引用透明:可以被表達式替代。
Expression 基于表達式:表達式可以被計算,促進數據流動,狀態聲明就像是一個暫停,好像數據到這里就會停滯了一下。
Immutable 不可變性:參數不可被修改、變量不可被修改---寧可犧牲性能,也要產生新的數據(Rust內存模型例外)。
High Order Function 大量使用高階函數:變量存儲、閉包應用、函數高度可組合。
Curry 柯里化:對函數進行降維,方便進行組合。
Composition 函數組合:將多個單函數進行組合,像流水線一樣工作。
另外還有一些特性,有的會提到,有的一筆帶過,但實際也是一個特性(以Haskell為例)。
Type Inference 類型推導:如果無法確定數據的類型,那函數怎么去組合?(常見,但非必需)
Lazy Evaluation 惰性求值:函數天然就是一個執行環境,惰性求值是很自然的選擇。
Side Effect IO:一種類型,用于處理副作用。一個不能執行打印文字、修改文件等操作的程序,是沒有意義的,總要有位置處理副作用。(邊緣)
數學上,我們定義函數為集合A到集合B的映射。在函數式編程中,我們也是這么認為的。函數就是把數據從某種形態映射到另一種形態。注意理解“映射”,后面我們還會講到。

圖 30
2.5.1 First Class:函數也是一種數據
函數本身也是數據的一種,可以是參數,也可以是返回值。

圖 31 通過這種方式,我們可以讓函數作為一種可以保存狀態的值進行流動,也可以充分利用不完全調用函數來進行函數組合。把函數作為數據,實際上就讓我們有能力獲取函數內部的狀態,這樣也產生了閉包。但函數式編程不強調狀態,大部分情況下,我們的“狀態”就是一個函數的元(我們從元獲取外部狀態)。
2.5.2 純函數:無狀態的世界
通常我們定義輸入輸出(IO)是不純的,因為IO操作不僅操作了數據,還操作了這個數據范疇外部的世界,比如打印、播放聲音、修改變量狀態、網絡請求等。這些操作并不是說對程序造成了破壞,相反,一個完整的程序一定是需要它們的,不然我們的所有計算都將毫無意義。
但純函數是可預測的,引用透明的,我們希望代碼中更多地出現純函數式的代碼,這樣的代碼可以被預測,可以被表達式替換,而更多地把IO操作放到一個統一的位置做處理。
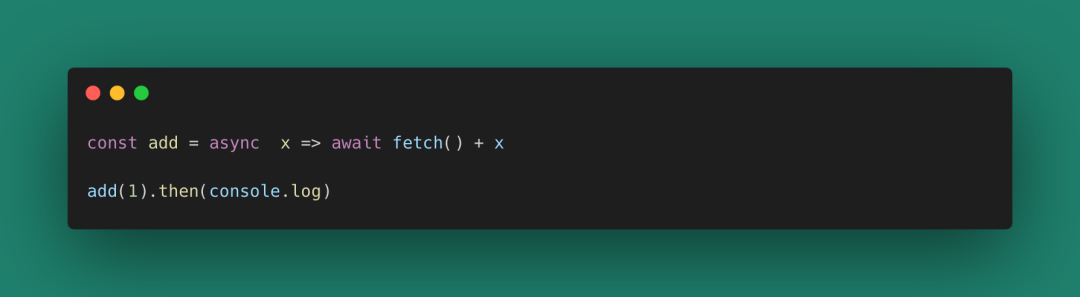
圖 32
這個add函數是不純的,但我們把副作用都放到它里面了。任意使用這個add函數的位置,都將變成不純的(就像是async/await的傳遞性一樣)。需要說明的是拋開實際應用來談論函數的純粹性是毫無意義的,我們的程序需要和終端、網絡等設備進行交互,不然一個計算的運行結果將毫無意義。但對于函數的元來說,這種純粹性就很有意義,比如:
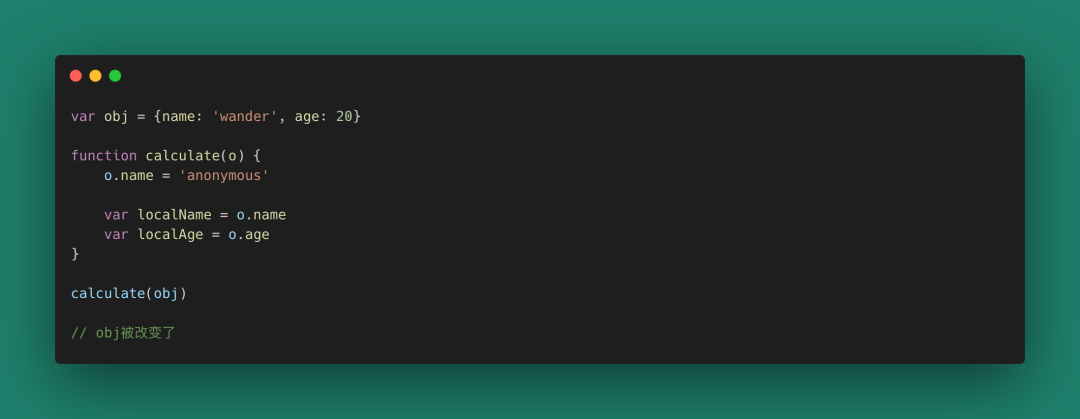
圖 33
當函數的元像上面那樣是一個引用值,如果一個函數的調用不去控制自己的純粹性,對別人來說,可能會造成毀滅性打擊。因此我們需要對引用值特別小心。
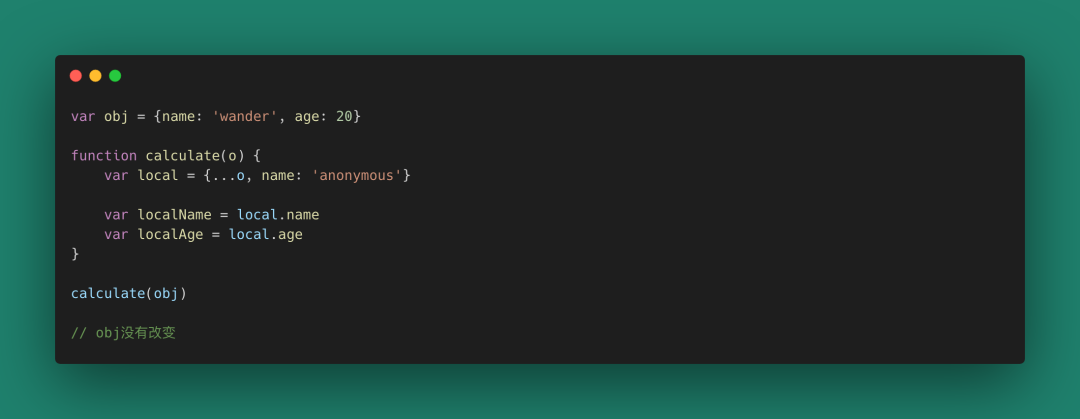
圖 34
上面這種解構賦值的方式僅解決了第一層的引用值,很多其他情況下,我們要處理一個引用樹、或者返回一個引用樹,這需要更深層次的解引用操作。請小心對待你的引用。
函數的純粹性要求我們時刻提醒自己降低狀態數量,把變化留在函數外部。
2.5.3 引用透明:代換
通過表達式替代(也就是λ演算中講的歸約),可以得到最終數據形態。

圖 35
也就是說,調用一個函數的位置,我們可以使用函數的調用結果來替代此函數調用,產生的結果不變。
一個引用透明的函數調用鏈永遠是可以被合并式代換的。
2.5.4 不可變性:把簡單留給自己
一個函數不應該去改變原有的引用值,避免對運算的其他部分造成影響。
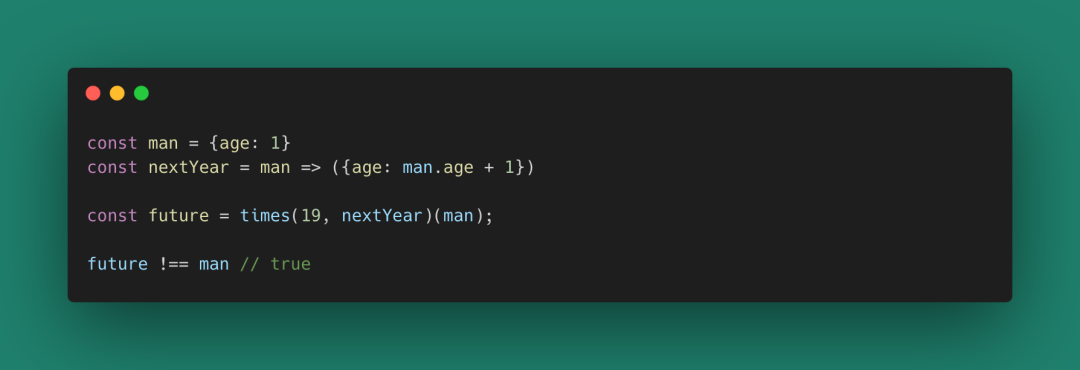
圖 36
一個充滿變化的世界是混沌的,在函數式編程世界,我們需要強調參數和值的不可變性,甚至在很多時候我們可以為了不改變原來的引用值,犧牲性能以產生新的對象來進行運算。犧牲一部分性能來保證我們程序的每個部分都是可預測的,任意一個對象從創建到消失,它的值應該是固定的。
一個元如果是引用值,請使用一個副本(克隆、復制、替代等方式)來得到狀態變更。
2.5.5 高階:函數抽象和組合
JS中用的最多的就是Array相關的高階函數。實際上Array是一種Monad(后面講解)。

圖 37
通過高階函數傳遞和修改變量:

圖 38
高階函數實際上為我們提供了注入環境變量(或者說綁定環境變量)提供了更多可能。React的高階組件就從這個思想上借用而來。一個高階函數就是使用或者產生另一個函數的函數。高階函數是函數組合(Composition)的一種方式。
高階函數讓我們可以更好地組合業務。常見的高階函數有:
map
compose
fold
pipe
curry
....
2.5.6 惰性計算:降低運行時開銷
惰性計算的含義就是在真正調用到的時候才執行,中間步驟不真實執行程序。這樣可以讓我們在運行時創建很多基礎函數,但并不影響實際業務運行速度,唯有業務代碼真實調用時才產生開銷。

圖 39
map(addOne)并不會真實執行+1,只有真實調用exec才執行。當然這個只是一個簡單的例子,強大的惰性計算在函數式編程語言中還有很多其他例子。比如:

圖 40
“無窮”只是一個字面定義,我們知道計算機是無法定義無窮的數據的,因此數據在take的時候才真實產生。
惰性計算讓我們可以無限使用函數組合,在寫這些函數組合的過程中并不產生調用。但這種形式,可能會有一個嚴重的問題,那就是產生一個非常長的調用棧,而虛擬機或者解釋器的函數調用棧一般都是有上限的,比如2000個,超過這個限制,函數調用就會棧溢出。雖然函數調用棧過長會引起這個嚴重的問題,但這個問題其實不是函數式語言設計的邏輯問題,因為調用棧溢出的問題在任何設計不良的程序中都有可能出現,惰性計算只是利用了函數調用棧的特性,而不是一種缺陷。
記住,任何時候我們都可以重構代碼,通過良好的設計來解決棧溢出的問題。
2.5.7 類型推導
當前的JS有TypeScript的加持,也可以算是有類型推導了。
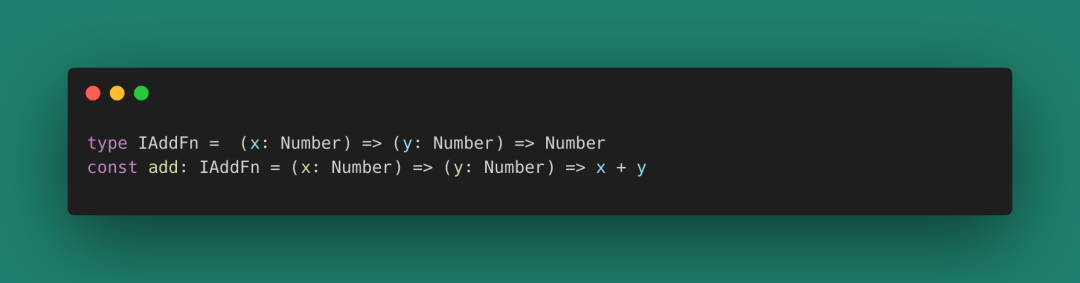
圖 41
沒有類型推導的函數式編程,在使用的時候會很不方便,所有的工具函數都要查表查示例,開發中效率會比較低下,也容易造成錯誤。
但并不是說一門函數式語言必須要類型推導,這不是強制的。像Lisp就沒有強制類型推導,JavaScript也沒有強制的類型推導,這不影響他們的成功。只是說,有了類型推導,我們的編譯器可以在編譯器期間提前捕獲錯誤,甚至在編譯之前,寫代碼的時候就可以發現錯誤。類型推導是一些語言強調的優秀特性,它確實可以幫助我們提前發現更多的代碼問題。像Rust、Haskell等。
2.5.8 其他
你現在也可以總結一些其他的風格或者定義。比如強調函數的組合、強調Point-Free的風格等等。

圖 42
3. 小結
函數式有很多基礎的特性,熟練地使用這些特性,并加以巧妙地組合,就形成了我們的“函數式編程范式”。這些基礎特性讓我們對待一個function,更多地看作函數,而不是一個方法。在許多場景下,使用這種范式進行編程,就像是在做數學推導(或者說是類型推導),它讓我們像學習數學一樣,把一個個復雜的問題簡單化,再進行累加/累積,從而得到結果。
同時,函數式編程還有一塊大的領域需要進入,即副作用處理。不處理副作用的程序是毫無意義的(僅在內存中進行計算),下篇我們將深入函數式編程的應用,為我們的工程應用發掘出更多的特性。
4. 作者簡介
俊杰,美團到家研發平臺/醫藥技術部前端工程師。
編輯:黃飛
?












 工商網監
工商網監
評論