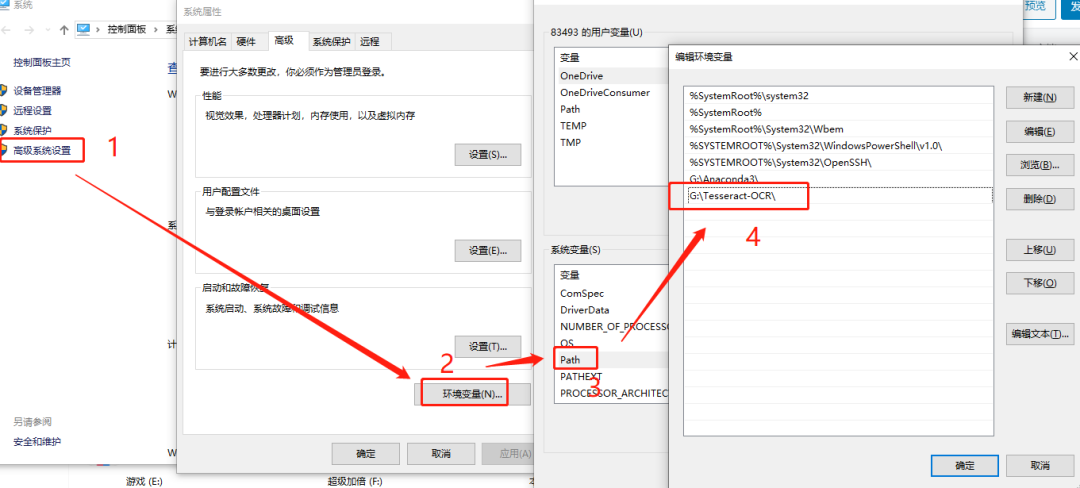
 電子發(fā)燒友App
電子發(fā)燒友App


引言
之前一篇介紹了Tesseract-OCR安裝與測試,已經(jīng)對中文字符的識別支持。大家反饋比較多,所以決定在寫一篇,主要是介紹用它做項目時候需要注意的問題與一些比較重要的函數(shù)使用。主要介紹一下Tesseract-OCR中如何實現(xiàn)結(jié)構(gòu)化的文檔分析以及相關區(qū)域的定位識別。
術語名詞
OEM - OCR Engine Mode
Tesseract-OCR從4.x版本開始支持LSTM,可以通過OEM參數(shù)熟悉設置,oem參數(shù)選項的值與表示分別如下:
0:3.x以前的識別引擎 1:神經(jīng)網(wǎng)絡LSTM的識別引擎 2:混合模式,傳統(tǒng)+LSTM 3:默認,那種支持就用那種
PSM-Page Segmentation Mode
Tesseract-OCR支持對每頁文檔進行結(jié)構(gòu)化分析,并輸出結(jié)構(gòu)化分析的結(jié)果,PSM文檔結(jié)構(gòu)化分析可以獲取很多有用的文檔信息。總計支持13種模式,默認的PSM的選項參數(shù)位PSM_AUTO=3,該選項支持對文檔的結(jié)構(gòu)化輸出信息包括:
dict_keys(['level', 'page_num', 'block_num', 'par_num', 'line_num', 'word_num', 'left', 'top', 'width', 'height', 'conf', 'text']),其中比較重要的包括:
'left', 'top', 'width', 'height' 表示位置信息 'text' 表示每個的外接矩形左上角與右下角坐標 'conf' 表示置信度,值在0~100之間,小于0的應該自動排除
其它有用的選項包括:
0 角度與語言檢測,不識別不分析文檔結(jié)構(gòu) 1 角度 + PSM模式
更多模型,懶得翻譯,請直接看下面:
0 Orientation and script detection (OSD) only. 1 Automatic page segmentation with OSD. 2 Automatic page segmentation, but no OSD, or OCR. 3 Fully automatic page segmentation, but no OSD. (Default) 4 Assume a single column of text of variable sizes. 5 Assume a single uniform block of vertically aligned text. 6 Assume a single uniform block of text. 7 Treat the image as a single text line. 8 Treat the image as a single word. 9 Treat the image as a single word in a circle. 10 Treat the image as a single character. 11 Sparse text. Find as much text as possible in no particular order. 12 Sparse text with OSD. 13 Raw line. Treat the image as a single text line, bypassing hacks that are Tesseract-specific.
03
函數(shù)說明
PSD分析函數(shù)
def image_to_data(
image,
lang=None,
config='',
nice=0,
output_type=Output.STRING,
timeout=0,
pandas_config=None,
)
3.5以上版本支持,分析返回文檔結(jié)構(gòu),完成PSD分析與輸出。
文檔角度與語言檢測
def image_to_osd(
image,
lang='osd',
config='',
nice=0,
output_type=Output.STRING,
timeout=0,
):
OSD檢測,返回文檔的旋轉(zhuǎn)角度與語言檢測信息
代碼演示部分
使用PSD實現(xiàn)文檔結(jié)構(gòu)分析
image?=?cv.imread("D:/images/text_xt.png") h,?w,?c?=?image.shape #?文檔結(jié)構(gòu)分析 config?=?('-l?chi_sim?--oem?1?--psm?6') dict?=?tess.image_to_data(image,?config=config,?output_type=tess.Output.DICT) print(dict.keys()) print(dict['conf']) n_boxes?=?len(dict['text'])
繪制所有BOX框
#?全部文檔結(jié)構(gòu)
text_img?=?np.copy(image)
for?i?in?range(n_boxes):
????(x,?y,?w,?h)?=?(dict['left'][i],?dict['top'][i],?dict['width'][i],?dict['height'][i])
????cv.rectangle(text_img,?(x,?y),?(x?+?w,?y?+?h),?(0,?255,?0),?2)
cv.imwrite('D:/layout-text1.png',?text_img)
顯示如下:
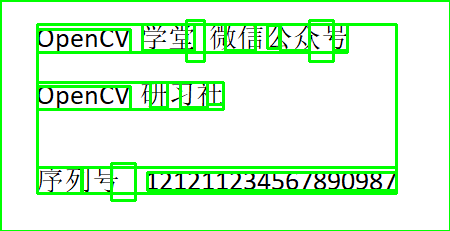
使用conf屬性過濾小于0的BOX框
#?根據(jù)conf>0過濾之后
for?i?in?range(n_boxes):
????if?int(dict['conf'][i])?>?0:
????????(x,?y,?w,?h)?=?(dict['left'][i],?dict['top'][i],?dict['width'][i],?dict['height'][i])
????????cv.rectangle(image,?(x,?y),?(x?+?w,?y?+?h),?(0,?255,?0),?2)
cv.imwrite('D:/layout-text2.png',?image)
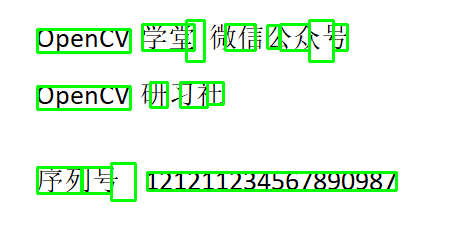
OSD檢測文檔偏斜與語言類別
#?檢測傾斜角度
image?=?cv.imread("D:/images/text_90.png")
cv.imshow("text_90",?image)
osd?=?tess.image_to_osd(image)
print(osd)
osd_array?=?osd.split("
")
angle?=?int(osd_array[2].split(":")[1])
conf?=?float(osd_array[3].split(":")[1])
print("angle:?",?angle)
print("conf:?",?conf)
dst?=?cv.rotate(image,?cv.ROTATE_90_CLOCKWISE)
cv.imshow("text_90_rotate",?dst)
cv.imwrite('D:/layout-text3.png',?dst)
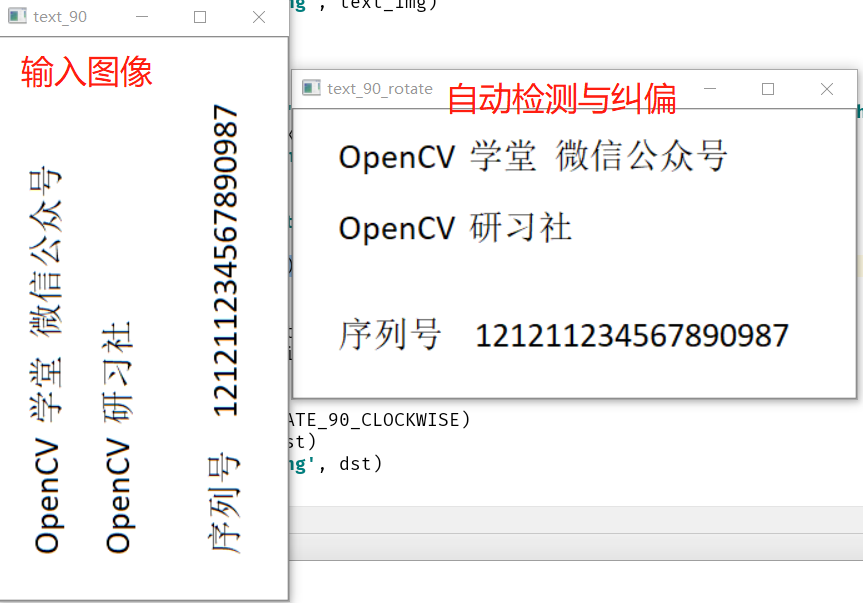
檢測配置與白名單機制過濾
#?只檢測數(shù)字
custom_config?=?r'--oem?1?--psm?6?outputbase?digits'
ocr_result?=?tess.image_to_string(dst,?config=custom_config)
print(ocr_result)
#?采用白名單方式只檢測數(shù)字
custom_config?=?r'-c?tessedit_char_whitelist=0123456789?--psm?6'
ocr_result?=?tess.image_to_string(dst,?config=custom_config)
print("白名單方式數(shù)字檢測
",ocr_result)
#?檢測中文
ocr_result?=?tess.image_to_string(dst,?lang="chi_sim")
print("
中文檢測與輸出:
",?ocr_result.replace("f",?"").split("
"))
#?檢測中文情況下,只輸出數(shù)字
ocr_result?=?tess.image_to_string(dst,?lang="chi_sim",?config=custom_config)
print("
中文檢測+數(shù)字輸出:
",ocr_result.replace("f",?"").split("
"))
cv.waitKey(0)
cv.destroyAllWindows()
運行結(jié)果: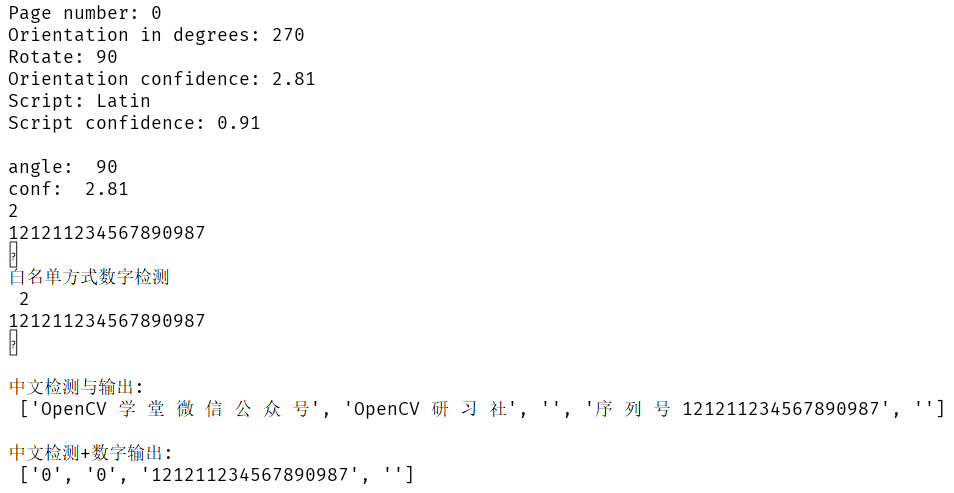
最后一個,可以看出把O檢測成0了,其它OK!這個是OCR的死穴,永遠分不清0跟O。最后還有一句話,Tesseract-OCR如果輸入是二值圖像,背景永遠是白色才是正確之選!
編輯:黃飛
?













 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論