 電子發燒友App
電子發燒友App


NFS 文件系統概述
NFS(Network File System,網絡文件系統)是一種基于網絡的文件系統。它可以將遠端服務器文件系統的目錄掛載到本地文件系統的目錄上,允許用戶或者應用程序像訪問本地文件系統的目錄結構一樣,訪問遠端服務器文件系統的目錄結構,而無需理會遠端服務器文件系統和本地文件系統的具體類型,非常方便地實現了目錄和文件在不同機器上進行共享。雖然 NFS 不是唯一實現這個功能的文件系統,但它無疑是最成功一個。
NFS 的第一個版本是 SUN Microsystems 在 20 世紀 80 年代開發出來的,至今為止,NFS 經歷了 NFS,NFSv2,NFSv3 和 NFSv4 共四個版本。現在,NFS 最新的版本是 4.1,也被稱為 pNFS(parallel NFS,并行網絡文件系統)。
前四個版本的 NFS,作為一個文件系統,它幾乎具備了一個傳統桌面文件系統最基本的結構特征和訪問特征,不同之處在于它的數據存儲于遠端服務器上,而不是本地設備上,因此不存在磁盤布局的處理。NFS 需要將本地操作轉換為網絡操作,并在遠端服務器上實現,最后返回操作的結果。因此,NFS 更像是遠端服務器文件系統在本地的一個文件系統代理,用戶或者應用程序通過訪問文件系統代理來訪問真實的文件系統。
眾所周知的是,NFS 的客戶端在訪問遠端服務器文件系統時,既需要通過服務器獲得文件的屬性信息,還需要通過服務器獲得文件的數據信息,這使得 NFS 天然地具備將文件的屬性信息和數據信息分離在不同服務器上進行訪問的特性,于是最后一個版本 NFS4.1/pNFS,將 Lustre/CephFS/GFS 等集群文件系統的設計思想引入到自身中,成為一個具有里程碑意義的 NFS 版本。它使得 NFS 的數據吞吐的速度和規模都得到了極大提高,為 NFS 的應用帶了更為廣闊的空間。
NFS 之所以備受矚目,除了它在文件共享領域上的優異表現外,還有一個關鍵原因在于它在 NAS 存儲系統上應用。NAS 與 DAS 和 SAN 在存儲領域的競爭中,NFS 發揮了積極的作用,這更使得 NFS 越來越值得關注。
NFSv3 源代碼結構
相比之前的兩個版本,NFSv3 是一個較為穩定和成熟的 NFS 版本,而之后的 NFSv4 除了在安全和性能上有所提高外,還在網絡連接中加入了狀態屬性,因此顯得復雜一些。在此,本文以 NFSv3 為例來剖析 NFS 文件系統的源代碼結構,所用源碼來自 Linux 2.4.9 內核。
按照?NFS 文件系統的設計與實現,NFS 文件系統主要分為三個部分:The Protocol(網絡協議),Client Side(NFS 客戶端)和 Server Side(NFS 服務器)。NFS 客戶端提供了接口,保證用戶或者應用程序能像訪問本地文件系統一樣訪問 NFS 文件系統,NFS 服務器作為數據源,為 NFS 客戶端提供真實的文件系統服務,而網絡協議則使得 NFS 客戶端和 NFS 服務器能夠高效和可靠地進行通信。NFS 網絡協議使用的是 RPC(Remote Procedure Call,遠程過程調用)/XDR(External Data Representation,外部數據表示)機制,因此本文將剖析的重點放在 NFS 客戶端和 NFS 服務器上。
Client Side 源代碼
Client Side 的頭文件在 include/linux/ 下面,C 文件在 fs/nfs 下面。
dir.c/file.c/inode.c/symlink.c/unlink.c:與文件操作相關的系統調用
read.c/write.c/flushd.c:文件讀寫
mount_clnt.c/nfs_root.c:將 NFS 文件系統作為 root 目錄的相關實現
proc.c/nfs2xdr.c/nfs3proc.c/nfs3xdr.c:網絡數據交換
與文件操作相關的系統調用都在 struct file_operations,struct inode_operations 這兩個數據結構里面定義。文件的讀操作 nfs_file_read 和寫操作 nfs_file_write 被單獨提出來,因為文件讀寫性能將直接關系到文件系統的成敗,本文在后面會重點闡述其實現。
Server Side 源代碼
Server Side 的頭文件在 include/linux/nfsd 下面,C 文件在 fs/nfsd 下面。
auth.c/lockd.c/export.c/nfsctl.c/nfscache.c/nfsfh.c/stats.c:導出目錄的訪問管理
nfssvc.c:NFS 服務 deamon 的實現
vfs.c:將 NFS 文件系統的操作轉換成具體文件系統的操作
nfsproc.c/nfsxdr.c/nfs3proc.c/nfs3xdr.c:網絡數據交換
導出目錄的訪問管理主要解決網絡文件系統實現面臨的幾個重要問題,包括目錄導出服務,外部訪問的權限控制,多客戶端以及客戶端與服務器的文件并發操作等。
一個典型例子:rename 的調用過程
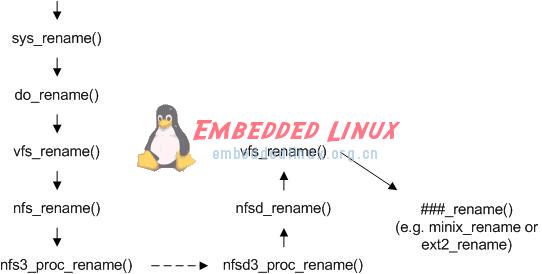
在 NFS 文件系統的文件操作中,除了 read 和 write 操作考慮到性能因素,專門使用了緩存機制外,其它的操作基本上都是同步完成的。本文以 rename 為例來進行說明,如下圖所示。首先用戶或者應用程序開始調用文件操作,經過系統調用 sys_rename,到達虛擬文件系統層 vfs_rename,然后交給 NFS 文件系統 nfs_rename 來處理。NFS 文件系統無法操作存儲介質,它調用 NFS 客戶端函數 nfs3_proc_rename 和 NFS 服務器函數 nfsd3_proc_rename 進行通信,把文件操作轉發到 NFS 服務器的虛擬文件系統層 vfs_rename,最后調用具體的文件系統如 ext2 的函數 ext2_raname,完成文件重命名。
圖 1. rename 調用過程
與傳統文件系統相同點
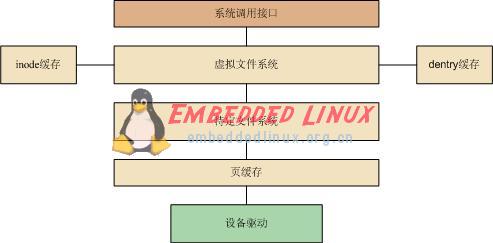
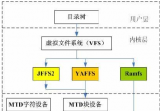
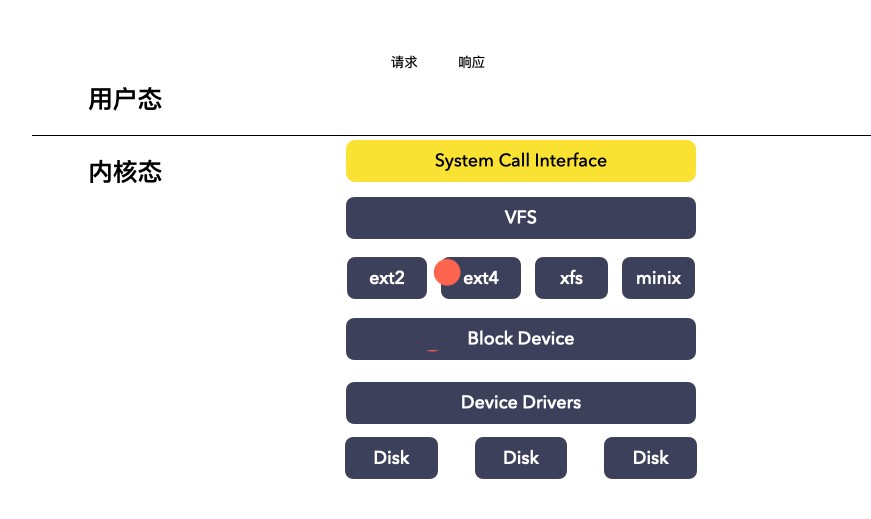
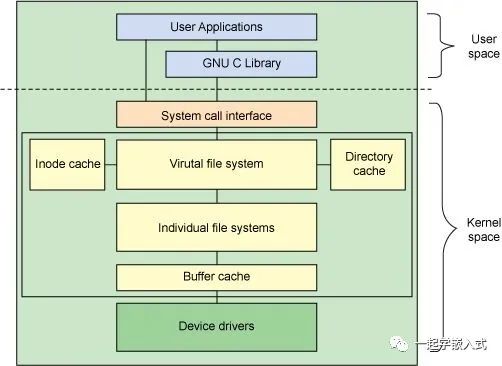
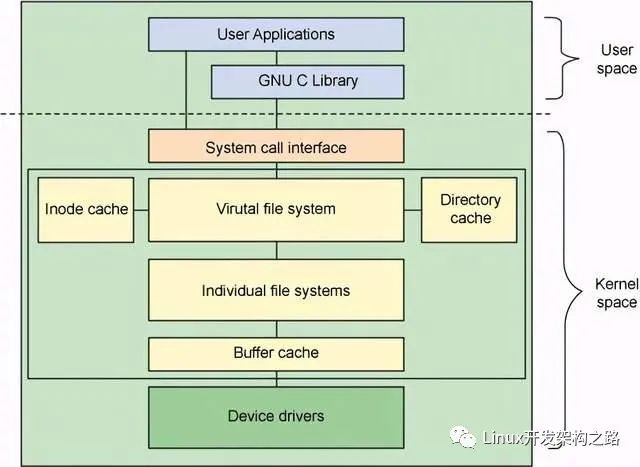
在闡述 NFS 文件系統與傳統桌面文件系統的相同點之前,我們首先簡要回顧一下 Linux 操作系統上文件系統的體系結構。按照?Linux 文件系統剖析的劃分,Linux 文件系統從上至下主要由虛擬文件系統層,特定文件系統層和頁高速緩存層三部分組成,如下圖所示。當然,這種劃分并不是一定的,例如在執行直接 I/O 調用時,是不需要進行頁高速緩存的,另外,對于塊設備的讀寫,進行頁高速緩存之后還會有通用塊層和 I/O 調度層的處理。
圖 2. 文件系統體系結構
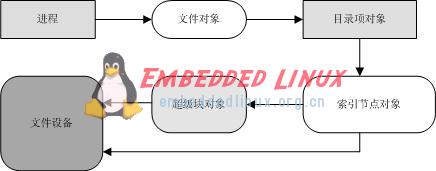
用戶或者應用程序通過統一的系統調用接口對文件系統進行操作,然后系統調用進入虛擬文件系統層,虛擬文件系統根據文件系統類型,調用特定文件系統的操作函數。對用戶和應用程序來說,由于接口完全相同,因此用戶感覺不到差異,應用程序也可以無縫地移植到 NFS 文件系統上。Linux 通過一組對象對文件系統的操作,這組對象是 superblock(超級塊對象),inode(索引節點對象),dentry(目錄項對象)和 file(文件對象),如下圖所示。所有文件系統都支持這些對象,正是因為它們,VFS 層可以對 NFS 和其它文件系統一視同仁,只管調用這些對象的數據和函數指針,把具體的文件系統數據布局和操作都留給特定的文件系統來完成。
圖 3. VFS 對象
NFS 與其它文件系統一樣,向內核聲明和注冊自己的文件系統類型。
static DECLARE_FSTYPE(nfs_fs_type, "nfs", nfs_read_super, FS_ODD_RENAME); ... ... module_init(init_nfs_fs) module_exit(exit_nfs_fs)
同樣,NFS 也需要根據自己的文件類型設置相應的文件操作函數。如果是正規文件,需要設置 inode 操作函數,file 操作函數,以及 address_space 操作函數;如果是目錄文件,需要設置 inode 操作函數,file 操作函數;如果是鏈接,則只需設置 inode 操作函數。
static void nfs_fill_inode(struct inode *inode, struct nfs_fh *fh, struct nfs_fattr *fattr) { ... ... inode->i_op = &nfs_file_inode_operations; if (S_ISREG(inode->i_mode)) { inode->i_fop = &nfs_file_operations; inode->i_data.a_ops = &nfs_file_aops; } else if (S_ISDIR(inode->i_mode)) { inode->i_op = &nfs_dir_inode_operations; inode->i_fop = &nfs_dir_operations; } else if (S_ISLNK(inode->i_mode)) inode->i_op = &nfs_symlink_inode_operations; else init_special_inode(inode, inode->i_mode, fattr->rdev); ... ... }
與傳統文件系統不同點
與內存文件系統,閃存文件系統和磁盤文件系統這些本地文件系統最大的不同在于,NFS 文件系統的數據是基于網絡,而不是基于存儲設備的,因此 NFS 文件系統在設計自己的 inode 和 superblock 數據結構,以及實現文件操作函數時,無需考慮數據布局情況。同樣是因為基于網絡,NFS 文件系統的權限控制和并發訪問的要求比本地文件系統更高,讀寫的緩存機制也大大有別于本地文件系統。
superblock 和 inode
清單 1. NFS 的 superblock 定義
struct rpc_clnt * client; /* RPC 客戶端句柄 */ struct nfs_rpc_ops * rpc_ops; /* RPC 客戶端函數向量表 */ int flags; /* 標識信息 */ unsigned int rsize; /* 每次讀請求的最小數據量 */ unsigned int rpages; /* 每次讀請求的最小數據量(以頁為單位)*/ unsigned int wsize; /* 每次寫請求的最小數據量 */ unsigned int wpages; /* 每次寫請求的最小數據量(以頁為單位)*/ unsigned int dtsize; /* 每次讀目錄信息的最小數據量 */ unsigned int bsize; /* NFS 服務器端的塊大小 */ unsigned int acregmin; /* 正規文件在緩存中駐留的最小允許時間 */ unsigned int acregmax; /* 正規文件在緩存中駐留的最大允許時間 */ unsigned int acdirmin; /* 目錄文件在緩存中駐留的最小允許時間 */ unsigned int acdirmax; /* 目錄文件在緩存中駐留的最大允許時間 */ unsigned int namelen; /* NFS 服務器端的主機名稱最大長度 */ char * hostname; /* NFS 服務器端的主機名稱 */ struct nfs_reqlist * rw_requests; /* 異步讀寫請求隊列信息 */
清單 2. NFS 的 inode 定義
__u64 fsid; /* 根目錄(導出目錄)信息 */ __u64 fileid; /* 當前文件信息 */ struct nfs_fh fh; /* 文件句柄 */ ... ... struct list_head read; /* 讀數據頁隊列 */ struct list_head dirty; /* 臟數據頁隊列 */ struct list_head commit; /* 提交數據頁隊列 */ struct list_head writeback; /* 寫回數據頁隊列 */ unsigned int nread, /* 讀數據頁數量 */ ndirty, /* 臟數據頁數量 */ ncommit, /* 提交數據頁數量 */ npages; /* 寫回數據頁數量 */ ... ...
以上省略了 superblock 和 inode 定義的公共部分,列出的僅是 NFS 文件系統 superblock 和 inode 定義的私有部分,因為只有這些私有定義才能體現出文件系統的設計原則。從這些定義可以看出,私有部分數據結構里面主要包含網絡連接和讀寫請求兩個方面相關的信息。superblock 里 client 定義了 RPC 協議的客戶端連接狀態,rpc_ops 定義了 RPC 協議的客戶端入口函數,如 nfs3_proc_read,nfs3_proc_write,nfs3_proc_create 等。inode 里 fh 是 NFS 客戶端和 NFS 服務器相互傳遞的關鍵參數,4 個頁隊列用于進行讀寫緩存,隨后兩小節將分別予以介紹。
file handle
file handle(fh 或者 fhandle)在 NFS 客戶端和 NFS 服務器之間相互傳遞,建立 NFS 客戶端的 inode 和 NFS 服務器的 inode 的關聯關系。它主要表征的是 NFS 服務器上 inode 和物理設備的信息。file handle 對于 NFS 客戶端來說是透明的,NFS 客戶端不需要知道它的具體內容。file handle 在 NFS 客戶端的定義是 66 個字節,前兩個字節組成一個無符號 short 型,表示 file handle 的大小,后 64 個字節組成數據區,存儲 file handle 的內容。
#define NFS_MAXFHSIZE 64 struct nfs_fh { unsigned short size; unsigned char data[NFS_MAXFHSIZE]; };
file handle 在 NFS 服務器的定義由 knfsd_fh 數據結構表示,fh_size 表示 file handle 的大小,數據區 fh_base 是一個聯合體,有 fh_old,fh_pad,fh_new 三種定義,最大也是 64 個字節。考慮到當前的 NFS 版本是 v3,只看 fh_new 的定義。fh_version 表示 fh_new 定義的版本,當前版本是 1。fh_auth_type 表示認證方式,0 表示不認證。fh_fsid_type 表示根目錄(即導出目錄)的信息存儲方式,如果是 0,那么從 fh_auth 開始前 2 個字節表示根目錄所在設備的 major 號,后 2 個字節表示根目錄所在設備的 minor 號,隨后的 4 個字節表示根目錄的 inode 索引號。fh_fileid_type 表示當前文件的信息存儲方式,如果是 1,那么在表示完 fh_fsid 后,緊接著 4 個字節表示當前文件的 inode 索引號,之后 4 個字節表示當前文件的 inode generation 號。
struct nfs_fhbase_new { __u8 fb_version; /* == 1, even => nfs_fhbase_old */ __u8 fb_auth_type; __u8 fb_fsid_type; __u8 fb_fileid_type; __u32 fb_auth[1]; };
read 和 write
前面介紹文件系統體系結構的時候,將它分為了虛擬文件系統,特定文件系統和頁高速緩存三個層次。NFS 文件系統使用了這三個層次的功能,它本身完成了特定文件系統的功能,同時既為虛擬文件系統提供了完整的調用接口,也用到了頁高速緩存來提高讀寫性能。就層次劃分而言,與傳統桌面文件系統相比,NFS 文件系統的讀寫操作不再需要通用塊層和 I/O 調度層,而是使用了多個列表以及相關操作來進一步緩存數據,增強讀寫效率。當然 NFS 文件系統也不再使用存儲設備驅動,而是通過網絡協議來獲取和提交數據。
圖 4. 讀寫緩存機制
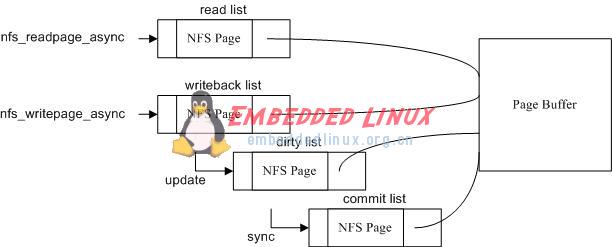
如上圖所示,NFS 文件系統使用 read,writeback,dirty 和 commit 四個隊列,每個隊列的單元數據結構都是 nfs_page,每個 nfs_page 都有一個 page 變量指向頁高速緩存。讀方法 nfs_readpage 首先使用異步方式讀取數據,如果異步方式失效,才使用同步方式,nfs_readpage_async 所讀的數據都進入 read 隊列中。寫方法 nfs_writepage 如果寫數據超過一頁(缺省是 4096 字節),使用異步方式提交數據,否則使用同步方式。nfs_writepage_async 所寫的數據首先進入 writeback 隊列,如果數據發生更改,則進入 dirty 隊列,如果將更改的數據提交到 NFS 服務器上,則進入 commit 隊列。這些隊列或者因為超時,或者因為單元數量多于最大值,將被釋放掉。
權限認證和并發鎖
NFSv3 版本使用 nfs_permission 做用戶權限認證,用 nfs_revalidate 做文件合法性檢查。前者調用 access 系統調用同步完成,后者調用 getattr 同步完成。為了使多個 NFS 客戶端或者 NFS 客戶端與 NFS 服務器對相同文件可以實現并發操作,NFS 使用 NLM(network lock management,網絡鎖管理)協議在 NFS 服務器上對文件進行打開,讀寫和移除,使不同的訪問都有及時和同一的語義理解。
總結
本文分析了 NFS 文件系統的設計,主要分為三個部分,NFS 客戶端,NFS 服務器和網絡協議,并闡述了三者的功能劃分,介紹了它們是如何組織起來,為用戶或者應用程序提供文件服務。進一步的,本文使用 Linux 2.4.9 內核剖析了 NFSv3 的源代碼實現,從源代碼層次說明了 NFS 文件系統的實現細節,重點介紹了它與傳統桌面文件系統的相同和不同之處,使讀者能夠深入理解 NFS 文件系統的本質。pNFS 是 NFS 文件系統從桌面型文件系統到集群型文件系統的一個轉折性版本,讀者可自行閱讀 pNFS 的源代碼實現。在閱讀之前,推薦讀者首先閱讀 Luster/CephFS/GFS 等文件系統相關的論文和資料,以便對集群文件系統的設計架構有個基本的認識。
?
















 工商網監
工商網監
評論