 電子發燒友App
電子發燒友App


對于程序員來說,整個計算機系統由四個重要的模塊組成,分別是:CPU,網絡,磁盤,內存。在我們的程序或者系統出現問題時,我們應該分別有一定先后順序的對這四塊進行排查。而在Linux系統下,有很多高效的工具,可以幫助我們分析定位問題。本文對于Linux下常用的一些工具進行一些簡單的介紹,幫助讀者能對這些工具有一個初步的了解。如果有不對的地方,歡迎隨時指正交流。
1.CPU
對于cpu我們主要介紹top,strace,perf,vmstat。
1.1 top
top命令可以實時動態地查看系統的整體運行情況,是一個綜合了多方信息監測系統性能和運行信息的實用工具。
Top常用的可選參數和其對應的含義如下:
(1)-c:顯示完整的命令;
(2)-d:屏幕刷新間隔時間;
(3)-i<時間>:設置間隔時間;
(4)-u<用戶名>:指定用戶名;
(5)-p<進程號>:指定進程;
(6)-n<次數>:循環顯示的次數。
top執行起來的效果如下:

前五行是系統整體的統計信息。第一行是任務隊列信息,第二行和第三行為進程和CPU的信息,最后兩行為內存信息。下面對一些比較重要的參數進行說明。
Load average:0.60,0.94,1.04。load average表示系統在過去1分鐘5分鐘15分鐘的任務隊列的平均長度。這個值越大就表示系統CPU越繁忙。
Cpu(s):5.0%us(用戶空間占用的cpu百分百),3.9%sy(系統空間占用的cpu百分比),0.0%ni(用戶進程空間內改變過優先級的用戶占用的cpu百分比),90.9%id(空閑cpu的百分比),0.2%wa(等待輸入輸出cpu的百分比)。
Mem:817280k buffers(用作內核緩存的內存量)。
Swap:磁盤交換區容量。
1.2 strace
strace可以跟蹤到一個進程產生的系統調用,包含參數、返回值、執行消耗的時間。
strace的常用的選項以及選項對應的含義如下:
(1)-c 統計每一系統調用的所執行的時間,次數和出錯的次數等
(2)-f 跟蹤由fork調用所產生的子進程
(3)-t 在輸出中的每一行前加上時間信息
(4)-tt 在輸出中的每一行前加上時間信息(微妙級)
(5)-T 顯示每一調用所耗的時間
(6)-e trace=set 只跟蹤指定的系統調用。例如:-e trace=open,close,read,write表示只跟蹤這四個系統調用。默認的為set=all
(7)-e trace=file 只跟蹤有關文件操作的系統調用
(8)-e trace=process 只跟蹤有關進程控制的系統調用
(9)-e trace=network 跟蹤與網絡有關的所有系統調用
(10)-e strace=signal 跟蹤所有與系統信號有關的 系統調用
(11)-e trace=ipc 跟蹤所有與進程通訊有關的系統調用
(12)-o filename 將strace的輸出寫入文件filename -p pid 跟蹤指定的進程pid
例如執行 strace cat /dev/null,會得到如下輸出:
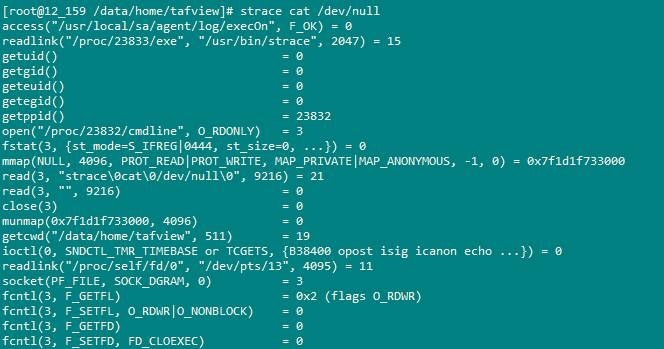
每一行都是一條系統調用,等號左邊是系統調用的函數名及其參數,右邊是該調用的返回值。如果你知道你要找的是什么,你可以讓strace只跟蹤一些類型的系統調用。例如你需要看看在loadconfigure腳本里面執行的程序里面系統調用ececve的調用情況,則只需要輸入這樣一條shell命令:strace -f -o loadconfigure-strace.txt -e execve ./loadconfigure
再例如,我們知道ActLogicSvr的進程號是16789,則可以執行strace -p 16789 -c來統計ActLogicSvr在某一段時間系統調用的統計情況。結果如下所示:

這里很清楚的告訴你調用了那些系統函數,調用次數多少,消耗了多少時間等等這些信息,這個對我們分析一個程序來說是非常有用的。
1.3 Perf
perf是Linux的性能調優工具。perf工具的常用命令包括top,record,report等。
perf top命令用來顯示程序運行的整體狀況。該命令主要用來觀察整個系統當前的狀態,比如可以通過查看該命令的輸出來查看當前系統最耗時的內核函數或某個用戶進程。Perf stat的運行效果如下:
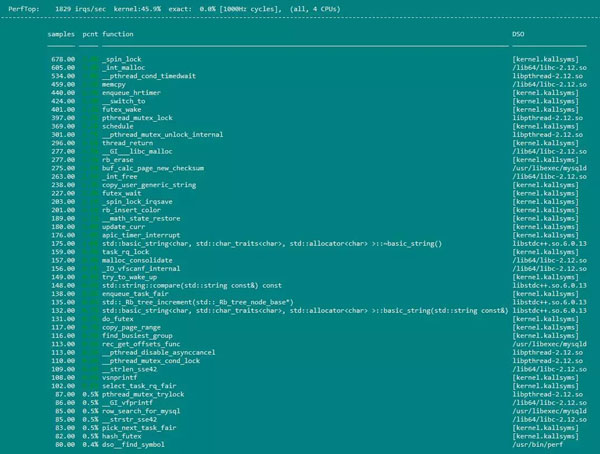
perf record命令則用來記錄指定事件在程序運行過程中的信息,而Perf report命令則用來報告基于前面record命令記錄的事件信息生成的程序運行狀況報告。我們通常用命令perf record -g -p pid將進程在命令運行期間的各項指令運行所占CPU的比例存在perf.data里面(-g表示記錄函數之間的調用關系)。再用perf report --call-graph --stdio將剛剛的統計結果展示出來。
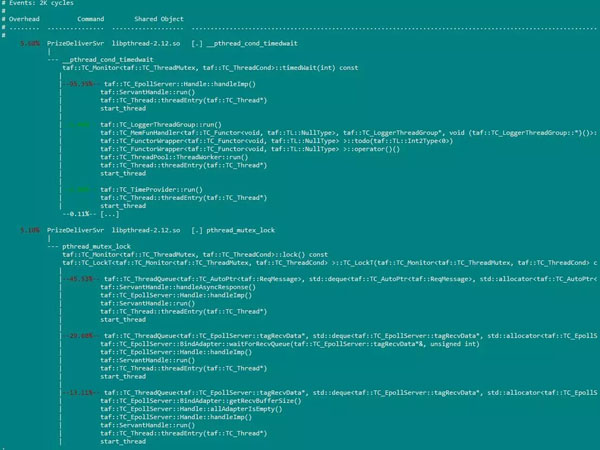
perf record帶-g選項時,perf report的運行效果:
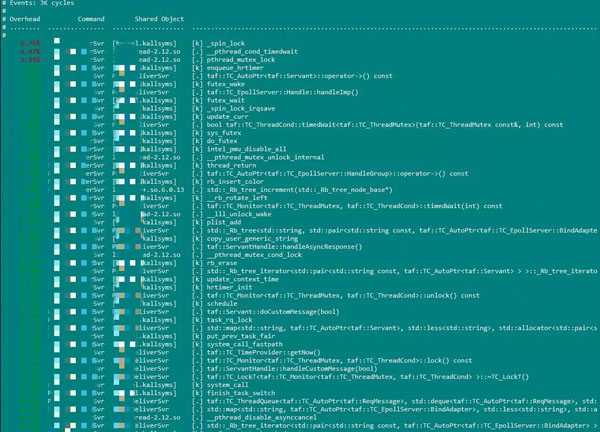
perf record不帶-g選項時,perf report的運行效果:
1.4 vmstat
vmstat是一個很全面的性能分析工具,可以觀察到系統的進程狀態、內存使用、虛擬內存使用、磁盤的 IO、中斷、上下問切換、CPU使用等。
vmstat的輸出如下:

procs:
- r:運行隊列中進程數量,這個值也可以判斷是否需要增加CPU。(長期大于1)
- b:因為io處于阻塞狀態的進程數。
memory:
-swap:使用虛擬內存大小
-free:空閑物理內存大小
-buff:用作緩沖的內存大小
-cache:用作緩存的內存大小
swap:
si:每秒從交換區寫到內存的大小,由磁盤調入內存
so:每秒寫入交換區的內存大小,由內存調入磁盤
io:
- bi:從塊設備讀入的數據總量(讀磁盤)(KB/s)
- bo:寫入到塊設備的數據總量(寫磁盤)(KB/s)
system:
- in:每秒產生的中斷次數
- cs:每秒產生的上下文切換次數
cpu:
- us:用戶進程消耗的CPU時間百分比
- sy:內核進程消耗的CPU時間百分比
- wa:IO等待消耗的CPU時間百分比
- id:CPU處在空閑狀態時間百分比
2.網絡
2.1 netstat命令
netstat命令用來打印Linux中網絡系統的狀態信息,可讓你得知整個Linux系統的網絡情況。
netstat的常用的選項如下:
(1)-a(all)顯示所有選項
(2)-t(tcp)僅顯示tcp相關選項
(3)-u(udp)僅顯示udp相關選項
(4)-l(listen)僅列出有在Listen(監聽)的服務狀態
(5)-p(program)顯示建立相關鏈接的程序名
(6)-r(route)顯示路由信息,路由表
(7)-e(extend)顯示擴展信息
(8)-c 每隔一個固定時間,執行該netstat命令。
在這里我們簡單復習一下TCP三次握手和四次揮手的過程,便于下面解釋netstat中tcp的各種狀態。
TCP三次握手的過程如下:
(1)主動連接端發送一個SYN包給被動連接端;
(2)被動連接端收到SYN包后,發送一個帶ACK的SYN包給主動連接端。
(3)主動連接端發送一個帶ACK標志的包給被動連接端,握手動作完成。
TCP的四次揮手過程如下:
(1)主動關閉端發送一個FIN包給被動關閉端。
(2)被動關閉端收到FIN包后,發送一個ACK包給主動關閉端。
(3)被動關閉端發送了ACK包后,再發送一個FIN包給主動關閉端。
(4)主動關閉端收到FIN包后,發送一個ACK包。當被動關閉端收到ACK后,四次揮手動作完成,連接斷開。
下面我們解釋一下netstat中tcp連接對應的各種狀態。
(1)LISTEN:偵聽狀態,等待遠程機器的連接請求。
(2)SYN_SEND:在TCP三次握手期間,主動連接端發送了SYN包后,進入SYN_SEND狀態,等待對方的ACK包。
(3)SYN_RECV:在TCP三次握手期間,主動接收端收到SYN包后,進入SYN_RECV狀態。
(4)ESTABLISHED:完成TCP三次握手后,主動連接端進入ESTABLISHED狀態。此時,TCP連接已經建立,可以進行通信。
(5)FIN_WAIT_1:在TCP四次揮手時,主動關閉端發送FIN包后,進入FIN_WAIT_1狀態。
(6)FIN_WAIT_2:在TCP四次揮手時,主動關閉端收到ACK包后,進入FIN_WAIT_2狀態。
(7)TIME_WAIT:在TCP四次揮手時,主動關閉端發送了ACK包之后,進入TIME_WAIT狀態,等待最多2MSL時間,讓被動關閉端收到ACK包。
(8)CLOSING:在TCP四次揮手期間,主動關閉端發送了FIN包后,沒有收到對應的ACK包,卻收到了對方的FIN包,此時進入CLOSING狀態。
(9)CLOSE_WAIT:在TCP四次揮手期間,被動關閉端收到FIN包后,進入CLOSE_WAIT狀態。
(10)LAST_ACK:在TCP四次揮手時,被動關閉端發送FIN包后,進入LAST_ACK狀態,等待對方的ACK包。
netstat -te(顯示出所有的tcp連接)執行起來的效果如下:

netstat的常用方法:
(1)netstat -p | grep 19626:得到進程號19626的進程所打開的所有端口
(2)netstat -tpl:查看當前tcp監聽端口, 需要顯示監聽的程序名。
(3)netstat -c 2:隔兩秒執行一次netstat,持續輸出
2.2 lsof
lsof命令用于查看進程開打的文件,打開文件的進程,進程打開的端口(TCP、UDP)。在linux環境下,任何事物都以文件的形式存在,通過文件不僅僅可以訪問常規數據,還可以訪問網絡連接和硬件。在使用TCP的UDP的時候,系統在后臺都為該應用程序分配了一個文件描述符。無論這個文件的本質如何,該文件描述符為應用程序與基礎操作系統之間的交互提供了通用接口。
lsof的使用示例如下:
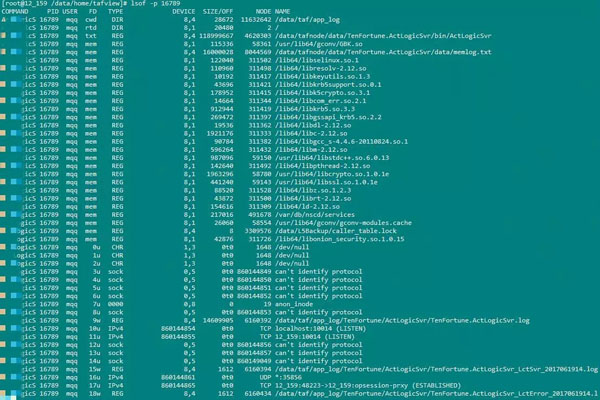
輸出的各項的含義如下:
COMMAND:進程的名稱
PID:進程標識符
USER:進程所有者
FD:文件描述符,應用程序通過文件描述符識別該文件。如cwd、txt等
TYPE:文件類型,如DIR、REG等
DEVICE:指定磁盤的名稱
SIZE:文件的大小
NODE:索引節點(文件在磁盤上的標識)
NAME:打開文件的確切名稱
Lsof的常用方法:
(1)lsof abc.txt:查看所有打開了文件abc.txt的進程。
(2)lsof -p pid:顯示進程打開的所有的文件。
2.3 tcpdump
tcpdump可以將網絡中傳送的數據包完全截獲下來提供分析。它支持針對網絡層、協議、主機、網絡或端口的過濾,并提供and、or、not等邏輯語句來幫助你去掉無用的信息。
tcpdump的常用參數:
(1)-nn,直接以 IP 及 Port Number 顯示,而非主機名與服務名稱。
(2)-i,后面接要「監聽」的網絡接口,例如 eth0, lo, ppp0 等等的接口。
(3)-w,如果你要將監聽所得的數據包數據儲存下來,用這個參數就對了。后面接文件名。
(4)-c,監聽的數據包數,如果沒有這個參數, tcpdump 會持續不斷的監聽,直到用戶輸入 [ctrl]-c 為止。
(5)-A,數據包的內容以 ASCII 顯示,通常用來捉取 WWW 的網頁數據包資料。
(6)-e,使用資料連接層 (OSI 第二層) 的 MAC 數據包數據來顯示。
(7)-q,僅列出較為簡短的數據包信息,每一行的內容比較精簡。
(8)-X,可以列出十六進制 (hex) 以及 ASCII 的數據包內容,對于監聽數據包內容很有用。
(9)-r,從后面接的文件將數據包數據讀出來。那個「文件」是已經存在的文件,并且這個「文件」是由 -w 所制作出來的。
tcpdump的常見用法:
(1)tcpdump -i eth1 host ***.***.***.***:抓取所有經過 eth1,目的或源地址是***.***.***.***的網絡數據。
(2)tcpdump -i eth1 dst host ***.***.***.***:抓取所有經過 eth1,目的地址是***.***.***.***的網絡數據。
(3)tcpdump -i eth1 src host ***.***.***.***:抓取所有經過 eth1,源地址是***.***.***.***的網絡數據。
(4)tcpdump -i eth1 port 36000:抓取所有經過 eth1,目的端口或源端口是36000的網絡數據。
(5)tcpdump -i eth1 src port 36000:抓取所有經過 eth1,源端口是36000的網絡數據。
(6)tcpdump -i eth1 dst port 36000:抓取所有經過 eth1,目的端口是36000的網絡數據。
(7)tcpdump -i eth1 'src host ***.***.***.*** && src port 36000':抓取所有經過 eth1,目的地址是10.136.12.1且目的端口是36000的網絡數據。
(8)在10.136.12.1機器上我們通過top知道了ActLogicSvr的進程id為16789。然后通過netstat -ap | grep 16789得到ActLogicSvr監聽的端口是10014。如下圖所示:

然后我們通過 tcpdump -i eth1 'port 10014' -xxx抓取通過10014端口的所有的包。我們通過模擬接口測試的方法給ActLogicSvr發一條請求。抓到的包結果如下:

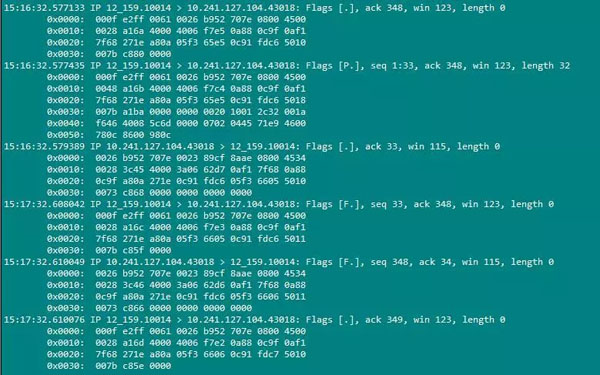
從抓到的包上我們可以清楚的看到tcp連接建立的三次握手到數據傳輸到tcp連接斷開四次揮手的過程(前三個數據包是三次握手的過程,最后四個數據包是四次揮手的過程,中間的為數據傳輸所產生的網絡數據包)。
3 內存
3.1 valgrind
valgrind 是在Linux程序中廣泛使用的調試應用程序。它尤其擅長發現內存管理的問題,可以檢查程序運行時的內存泄漏問題等。我們在使用valgrind時也主要用到它的內存泄漏檢測功能,即memcheck功能。它檢查所有對內存的讀/寫操作,并截取所有的malloc/new/free/delete調用。因此memcheck工具能夠探測到以下問題:
(1)使用未初始化的內存
(2)讀/寫已經被釋放的內存
(3)讀/寫內存越界
(4)讀/寫不恰當的內存棧空間
(5)內存泄漏
(6)使用malloc/new/new[]和free/delete/delete[]不匹配。
(7)src和dst的重疊valgrind的可選的參數以及對應的含義如下所示:
(1)-version 顯示valgrind內核的版本,每個工具都有各自的版本。
(2)q –quiet 安靜地運行,只打印錯誤信。
(3)v –verbose 更詳細的信息, 增加錯誤數統計。
(4)-trace-children=no|yes 跟蹤子線程
(5)-track-fds=no|yes 跟蹤打開的文件描述
(6)-time-stamp=no|yes 增加時間戳到LOG信息
(7)-log-fd= 輸出LOG到描述符文
(8)-log-file= 將輸出的信息寫入到filename.PID的文件里,PID是運行程序的進行ID
(9)-log-file-exactly= 輸出LOG信息到 file
(10)-log-file-qualifier= 取得環境變量的值來做為輸出信息的文件名。
(11)-log-socket=ipaddr:port 輸出LOG到socket ,ipaddr:port
LOG信息輸出:
(1)-xml=yes 將信息以xml格式輸出,只有memcheck可用
(2)-num-callers= show callers in stack traces [12]
(3)-error-limit=no|yes 如果太多錯誤,則停止顯示新錯誤? [yes]
(4)-error-exitcode= 如果發現錯誤則返回錯誤代碼 [0=disable]
(5)-db-attach=no|yes 當出現錯誤,valgrind會自動啟動調試器gdb。[no]
(6)-db-command=
啟動調試器的命令行選項[gdb -nw %f %p]適用于Memcheck工具的相關選項:
(1)--leak-check=no|summary|full 要求對leak給出詳細信息? [summary]
(2)--leak-resolution=low|med|high how much bt merging in leak check [low]
(3)--show-reachable=no|yes show reachable blocks in leak check? [no]
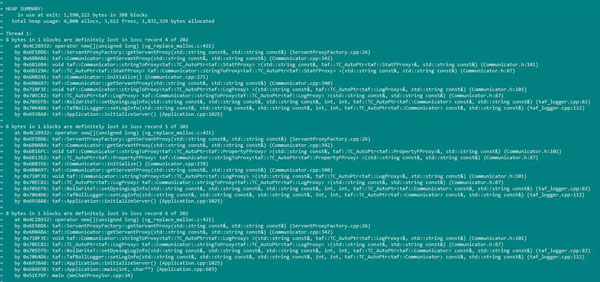
示例:valgrind --leak-check=full /usr/local/app/taf/tafnode/data/TenFortune.WeChatProxySvr/bin/WeChatProxySvr --config=/usr/local/app/taf/tafnode/data/TenFortune.WeChatProxySvr/conf/TenFortune.WeChatProxySvr.config.conf -trace-child=yes。執行的結果:
4 磁盤
4.1 iotop
iotop命令是一個用來監視磁盤I/O使用狀況的top類工具。iotop具有與top相似的UI,其中包括PID、用戶、I/O、進程等相關信息。Linux下的IO統計工具如iostat,nmon等大多數是只能統計到per設備的讀寫情況,如果你想知道每個進程是如何使用IO的就比較麻煩,使用iotop命令可以很方便的查看。
iostat命令選項:
-o:只顯示有io操作的進程
-n NUM:顯示NUM次,主要用于非交互式模式。
-d SEC:間隔SEC秒顯示一次。
-p PID:監控的進程pid。
-u USER:監控的進程用戶。
iotop的執行效果:

?










 工商網監
工商網監
評論