 電子發燒友App
電子發燒友App


自從多線程編程的概念出現在 Linux 中以來,Linux 多線應用的發展總是與兩個問題脫不開干系:兼容性、效率。本文從線程模型入手,通過分析目前 Linux 平臺上最流行的 LinuxThreads 線程庫的實現及其不足,描述了 Linux 社區是如何看待和解決兼容性和效率這兩個問題的。
一。基礎知識:線程和進程
按照教科書上的定義,進程是資源管理的最小單位,線程是程序執行的最小單位。在操作系統設計上,從進程演化出線程,最主要的目的就是更好的支持SMP以及減小(進程/線程)上下文切換開銷。
無論按照怎樣的分法,一個進程至少需要一個線程作為它的指令執行體,進程管理著資源(比如cpu、內存、文件等等),而將線程分配到某個cpu上執行。一個進程當然可以擁有多個線程,此時,如果進程運行在SMP機器上,它就可以同時使用多個cpu來執行各個線程,達到最大程度的并行,以提高效率;同時,即使是在單cpu的機器上,采用多線程模型來設計程序,正如當年采用多進程模型代替單進程模型一樣,使設計更簡潔、功能更完備,程序的執行效率也更高,例如采用多個線程響應多個輸入,而此時多線程模型所實現的功能實際上也可以用多進程模型來實現,而與后者相比,線程的上下文切換開銷就比進程要小多了,從語義上來說,同時響應多個輸入這樣的功能,實際上就是共享了除cpu以外的所有資源的。
針對線程模型的兩大意義,分別開發出了核心級線程和用戶級線程兩種線程模型,分類的標準主要是線程的調度者在核內還是在核外。前者更利于并發使用多處理器的資源,而后者則更多考慮的是上下文切換開銷。在目前的商用系統中,通常都將兩者結合起來使用,既提供核心線程以滿足smp系統的需要,也支持用線程庫的方式在用戶態實現另一套線程機制,此時一個核心線程同時成為多個用戶態線程的調度者。正如很多技術一樣,“混合”通常都能帶來更高的效率,但同時也帶來更大的實現難度,出于“簡單”的設計思路,Linux從一開始就沒有實現混合模型的計劃,但它在實現上采用了另一種思路的“混合”。
在線程機制的具體實現上,可以在操作系統內核上實現線程,也可以在核外實現,后者顯然要求核內至少實現了進程,而前者則一般要求在核內同時也支持進程。核心級線程模型顯然要求前者的支持,而用戶級線程模型則不一定基于后者實現。這種差異,正如前所述,是兩種分類方式的標準不同帶來的。
當核內既支持進程也支持線程時,就可以實現線程-進程的“多對多”模型,即一個進程的某個線程由核內調度,而同時它也可以作為用戶級線程池的調度者,選擇合適的用戶級線程在其空間中運行。這就是前面提到的“混合”線程模型,既可滿足多處理機系統的需要,也可以最大限度的減小調度開銷。絕大多數商業操作系統(如Digital Unix、Solaris、Irix)都采用的這種能夠完全實現POSIX1003.1c標準的線程模型。在核外實現的線程又可以分為“一對一”、“多對一”兩種模型,前者用一個核心進程(也許是輕量進程)對應一個線程,將線程調度等同于進程調度,交給核心完成,而后者則完全在核外實現多線程,調度也在用戶態完成。后者就是前面提到的單純的用戶級線程模型的實現方式,顯然,這種核外的線程調度器實際上只需要完成線程運行棧的切換,調度開銷非常小,但同時因為核心信號(無論是同步的還是異步的)都是以進程為單位的,因而無法定位到線程,所以這種實現方式不能用于多處理器系統,而這個需求正變得越來越大,因此,在現實中,純用戶級線程的實現,除算法研究目的以外,幾乎已經消失了。
Linux內核只提供了輕量進程的支持,限制了更高效的線程模型的實現,但Linux著重優化了進程的調度開銷,一定程度上也彌補了這一缺陷。目前最流行的線程機制LinuxThreads所采用的就是線程-進程“一對一”模型,調度交給核心,而在用戶級實現一個包括信號處理在內的線程管理機制。Linux-LinuxThreads的運行機制正是本文的描述重點。
二.Linux 2.4內核中的輕量進程實現
最初的進程定義都包含程序、資源及其執行三部分,其中程序通常指代碼,資源在操作系統層面上通常包括內存資源、IO資源、信號處理等部分,而程序的執行通常理解為執行上下文,包括對cpu的占用,后來發展為線程。在線程概念出現以前,為了減小進程切換的開銷,操作系統設計者逐漸修正進程的概念,逐漸允許將進程所占有的資源從其主體剝離出來,允許某些進程共享一部分資源,例如文件、信號,數據內存,甚至代碼,這就發展出輕量進程的概念。Linux內核在2.0.x版本就已經實現了輕量進程,應用程序可以通過一個統一的clone()系統調用接口,用不同的參數指定創建輕量進程還是普通進程。在內核中,clone()調用經過參數傳遞和解釋后會調用do_fork(),這個核內函數同時也是fork()、vfork()系統調用的最終實現:
int do_fork(unsigned long clone_flags, unsigned long stack_start, struct pt_regs *regs, unsigned long stack_size)
其中的clone_flags取自以下宏的“或”值:
#define CSIGNAL0x000000ff/* signal mask to be sent at exit */#define CLONE_VM0x00000100/* set if VM shared between processes */#define CLONE_FS 0x00000200/* set if fs info shared between processes */#define CLONE_FILES 0x00000400/* set if open files shared between processes */#define CLONE_SIGHAND0x00000800/* set if signal handlers and blocked signals shared */#define CLONE_PID0x00001000/* set if pid shared */#define CLONE_PTRACE0x00002000/* set if we want to let tracing continue on the child too */#define CLONE_VFORK0x00004000/* set if the parent wants the child to wake it up on mm_release */#define CLONE_PARENT0x00008000/* set if we want to have the same parent as the cloner */#define CLONE_THREAD0x00010000/* Same thread group? */#define CLONE_NEWNS0x00020000/* New namespace group? */#define CLONE_SIGNAL (CLONE_SIGHAND | CLONE_THREAD)
在do_fork()中,不同的clone_flags將導致不同的行為,對于LinuxThreads,它使用(CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGHAND)參數來調用clone()創建“線程”,表示共享內存、共享文件系統訪問計數、共享文件描述符表,以及共享信號處理方式。本節就針對這幾個參數,看看Linux內核是如何實現這些資源的共享的。
1.CLONE_VM
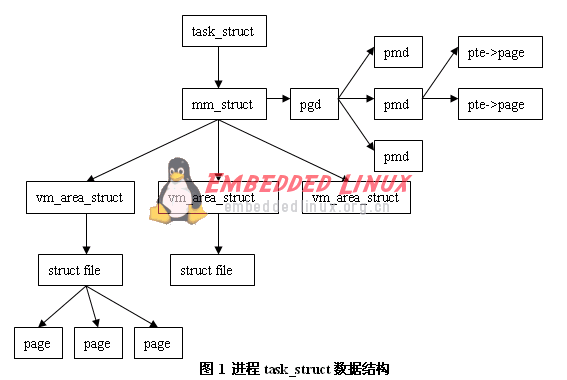
do_fork()需要調用copy_mm()來設置task_struct中的mm和active_mm項,這兩個mm_struct數據與進程所關聯的內存空間相對應。如果do_fork()時指定了CLONE_VM開關,copy_mm()將把新的task_struct中的mm和active_mm設置成與current的相同,同時提高該mm_struct的使用者數目(mm_struct::mm_users)。也就是說,輕量級進程與父進程共享內存地址空間,由下圖示意可以看出mm_struct在進程中的地位:
2.CLONE_FS
task_struct中利用fs(struct fs_struct *)記錄了進程所在文件系統的根目錄和當前目錄信息,do_fork()時調用copy_fs()復制了這個結構;而對于輕量級進程則僅增加fs-》count計數,與父進程共享相同的fs_struct。也就是說,輕量級進程沒有獨立的文件系統相關的信息,進程中任何一個線程改變當前目錄、根目錄等信息都將直接影響到其他線程。
3.CLONE_FILES
一個進程可能打開了一些文件,在進程結構task_struct中利用files(struct files_struct *)來保存進程打開的文件結構(struct file)信息,do_fork()中調用了copy_files()來處理這個進程屬性;輕量級進程與父進程是共享該結構的,copy_files()時僅增加files-》count計數。這一共享使得任何線程都能訪問進程所維護的打開文件,對它們的操作會直接反映到進程中的其他線程。
4.CLONE_SIGHAND
每一個Linux進程都可以自行定義對信號的處理方式,在task_struct中的sig(struct signal_struct)中使用一個struct k_sigaction結構的數組來保存這個配置信息,do_fork()中的copy_sighand()負責復制該信息;輕量級進程不進行復制,而僅僅增加signal_struct::count計數,與父進程共享該結構。也就是說,子進程與父進程的信號處理方式完全相同,而且可以相互更改。
do_fork()中所做的工作很多,在此不詳細描述。對于SMP系統,所有的進程fork出來后,都被分配到與父進程相同的cpu上,一直到該進程被調度時才會進行cpu選擇。
盡管Linux支持輕量級進程,但并不能說它就支持核心級線程,因為Linux的“線程”和“進程”實際上處于一個調度層次,共享一個進程標識符空間,這種限制使得不可能在Linux上實現完全意義上的POSIX線程機制,因此眾多的Linux線程庫實現嘗試都只能盡可能實現POSIX的絕大部分語義,并在功能上盡可能逼近。
三.LinuxThread的線程機制
LinuxThreads是目前Linux平臺上使用最為廣泛的線程庫,由Xavier Leroy (Xavier.Leroy@inria.fr)負責開發完成,并已綁定在GLIBC中發行。它所實現的就是基于核心輕量級進程的“一對一”線程模型,一個線程實體對應一個核心輕量級進程,而線程之間的管理在核外函數庫中實現。
1.線程描述數據結構及實現限制
LinuxThreads定義了一個struct _pthread_descr_struct數據結構來描述線程,并使用全局數組變量__pthread_handles來描述和引用進程所轄線程。在__pthread_handles中的前兩項,LinuxThreads定義了兩個全局的系統線程:__pthread_initial_thread和__pthread_manager_thread,并用__pthread_main_thread表征__pthread_manager_thread的父線程(初始為__pthread_initial_thread)。
struct _pthread_descr_struct是一個雙環鏈表結構,__pthread_manager_thread所在的鏈表僅包括它一個元素,實際上,__pthread_manager_thread是一個特殊線程,LinuxThreads僅使用了其中的errno、p_pid、p_priority等三個域。而__pthread_main_thread所在的鏈則將進程中所有用戶線程串在了一起。經過一系列pthread_create()之后形成的__pthread_handles數組將如下圖所示:
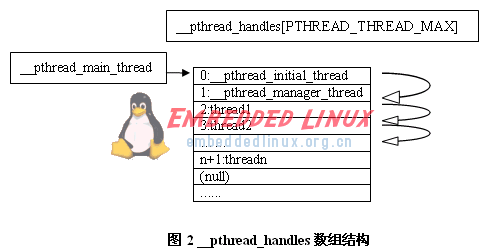
新創建的線程將首先在__pthread_handles數組中占據一項,然后通過數據結構中的鏈指針連入以__pthread_main_thread為首指針的鏈表中。這個鏈表的使用在介紹線程的創建和釋放的時候將提到。
LinuxThreads遵循POSIX1003.1c標準,其中對線程庫的實現進行了一些范圍限制,比如進程最大線程數,線程私有數據區大小等等。在LinuxThreads的實現中,基本遵循這些限制,但也進行了一定的改動,改動的趨勢是放松或者說擴大這些限制,使編程更加方便。這些限定宏主要集中在sysdeps/unix/sysv/linux/bits/local_lim.h(不同平臺使用的文件位置不同)中,包括如下幾個:
每進程的私有數據key數,POSIX定義_POSIX_THREAD_KEYS_MAX為128,LinuxThreads使用PTHREAD_KEYS_MAX,1024;私有數據釋放時允許執行的操作數,LinuxThreads與POSIX一致,定義PTHREAD_DESTRUCTOR_ITERATIONS為4;每進程的線程數,POSIX定義為64,LinuxThreads增大到1024(PTHREAD_THREADS_MAX);線程運行棧最小空間大小,POSIX未指定,LinuxThreads使用PTHREAD_STACK_MIN,16384(字節)。
2.管理線程
“一對一”模型的好處之一是線程的調度由核心完成了,而其他諸如線程取消、線程間的同步等工作,都是在核外線程庫中完成的。在LinuxThreads中,專門為每一個進程構造了一個管理線程,負責處理線程相關的管理工作。當進程第一次調用pthread_create()創建一個線程的時候就會創建(__clone())并啟動管理線程。
在一個進程空間內,管理線程與其他線程之間通過一對“管理管道(manager_pipe[2])”來通訊,該管道在創建管理線程之前創建,在成功啟動了管理線程之后,管理管道的讀端和寫端分別賦給兩個全局變量__pthread_manager_reader和__pthread_manager_request,之后,每個用戶線程都通過__pthread_manager_request向管理線程發請求,但管理線程本身并沒有直接使用__pthread_manager_reader,管道的讀端(manager_pipe[0])是作為__clone()的參數之一傳給管理線程的,管理線程的工作主要就是監聽管道讀端,并對從中取出的請求作出反應。
創建管理線程的流程如下所示:
(全局變量pthread_manager_request初值為-1)
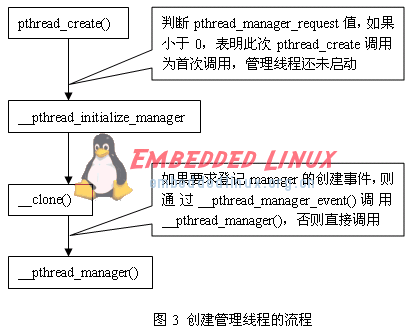
初始化結束后,在__pthread_manager_thread中記錄了輕量級進程號以及核外分配和管理的線程id,2*PTHREAD_THREADS_MAX+1這個數值不會與任何常規用戶線程id沖突。管理線程作為pthread_create()的調用者線程的子線程運行,而pthread_create()所創建的那個用戶線程則是由管理線程來調用clone()創建,因此實際上是管理線程的子線程。(此處子線程的概念應該當作子進程來理解。)
__pthread_manager()就是管理線程的主循環所在,在進行一系列初始化工作后,進入while(1)循環。在循環中,線程以2秒為timeout查詢(__poll())管理管道的讀端。在處理請求前,檢查其父線程(也就是創建manager的主線程)是否已退出,如果已退出就退出整個進程。如果有退出的子線程需要清理,則調用pthread_reap_children()清理。
然后才是讀取管道中的請求,根據請求類型執行相應操作(switch-case)。具體的請求處理,源碼中比較清楚,這里就不贅述了。
3.線程棧
在LinuxThreads中,管理線程的棧和用戶線程的棧是分離的,管理線程在進程堆中通過malloc()分配一個THREAD_MANAGER_STACK_SIZE字節的區域作為自己的運行棧。
用戶線程的棧分配辦法隨著體系結構的不同而不同,主要根據兩個宏定義來區分,一個是NEED_SEPARATE_REGISTER_STACK,這個屬性僅在IA64平臺上使用;另一個是FLOATING_STACK宏,在i386等少數平臺上使用,此時用戶線程棧由系統決定具體位置并提供保護。與此同時,用戶還可以通過線程屬性結構來指定使用用戶自定義的棧。因篇幅所限,這里只能分析i386平臺所使用的兩種棧組織方式:FLOATING_STACK方式和用戶自定義方式。
在FLOATING_STACK方式下,LinuxThreads利用mmap()從內核空間中分配8MB空間(i386系統缺省的最大棧空間大小,如果有運行限制(rlimit),則按照運行限制設置),使用mprotect()設置其中第一頁為非訪問區。該8M空間的功能分配如下圖:
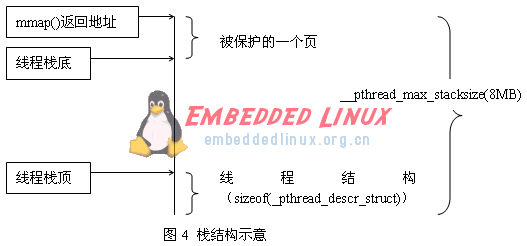
低地址被保護的頁面用來監測棧溢出。
對于用戶指定的棧,在按照指針對界后,設置線程棧頂,并計算出棧底,不做保護,正確性由用戶自己保證。
不論哪種組織方式,線程描述結構總是位于棧頂緊鄰堆棧的位置。
4.線程id和進程id
每個LinuxThreads線程都同時具有線程id和進程id,其中進程id就是內核所維護的進程號,而線程id則由LinuxThreads分配和維護。
__pthread_initial_thread的線程id為PTHREAD_THREADS_MAX,__pthread_manager_thread的是2*PTHREAD_THREADS_MAX+1,第一個用戶線程的線程id為PTHREAD_THREADS_MAX+2,此后第n個用戶線程的線程id遵循以下公式:
tid=n*PTHREAD_THREADS_MAX+n+1
這種分配方式保證了進程中所有的線程(包括已經退出)都不會有相同的線程id,而線程id的類型pthread_t定義為無符號長整型(unsigned long int),也保證了有理由的運行時間內線程id不會重復。
從線程id查找線程數據結構是在pthread_handle()函數中完成的,實際上只是將線程號按PTHREAD_THREADS_MAX取模,得到的就是該線程在__pthread_handles中的索引。
5.線程的創建
在pthread_create()向管理線程發送REQ_CREATE請求之后,管理線程即調用pthread_handle_create()創建新線程。分配棧、設置thread屬性后,以pthread_start_thread()為函數入口調用__clone()創建并啟動新線程。pthread_start_thread()讀取自身的進程id號存入線程描述結構中,并根據其中記錄的調度方法配置調度。一切準備就緒后,再調用真正的線程執行函數,并在此函數返回后調用pthread_exit()清理現場。
6.LinuxThreads的不足
由于Linux內核的限制以及實現難度等等原因,LinuxThreads并不是完全POSIX兼容的,在它的發行README中有說明。
1)進程id問題
這個不足是最關鍵的不足,引起的原因牽涉到LinuxThreads的“一對一”模型。
Linux內核并不支持真正意義上的線程,LinuxThreads是用與普通進程具有同樣內核調度視圖的輕量級進程來實現線程支持的。這些輕量級進程擁有獨立的進程id,在進程調度、信號處理、IO等方面享有與普通進程一樣的能力。在源碼閱讀者看來,就是Linux內核的clone()沒有實現對CLONE_PID參數的支持。
在內核do_fork()中對CLONE_PID的處理是這樣的:
if (clone_flags & CLONE_PID) { if (current-》pid) goto fork_out; }
這段代碼表明,目前的Linux內核僅在pid為0的時候認可CLONE_PID參數,實際上,僅在SMP初始化,手工創建進程的時候才會使用CLONE_PID參數。
按照POSIX定義,同一進程的所有線程應該共享一個進程id和父進程id,這在目前的“一對一”模型下是無法實現的。
2)信號處理問題
由于異步信號是內核以進程為單位分發的,而LinuxThreads的每個線程對內核來說都是一個進程,且沒有實現“線程組”,因此,某些語義不符合POSIX標準,比如沒有實現向進程中所有線程發送信號,README對此作了說明。
如果核心不提供實時信號,LinuxThreads將使用SIGUSR1和SIGUSR2作為內部使用的restart和cancel信號,這樣應用程序就不能使用這兩個原本為用戶保留的信號了。在Linux kernel 2.1.60以后的版本都支持擴展的實時信號(從_SIGRTMIN到_SIGRTMAX),因此不存在這個問題。
某些信號的缺省動作難以在現行體系上實現,比如SIGSTOP和SIGCONT,LinuxThreads只能將一個線程掛起,而無法掛起整個進程。
3)線程總數問題
LinuxThreads將每個進程的線程最大數目定義為1024,但實際上這個數值還受到整個系統的總進程數限制,這又是由于線程其實是核心進程。
在kernel 2.4.x中,采用一套全新的總進程數計算方法,使得總進程數基本上僅受限于物理內存的大小,計算公式在kernel/fork.c的fork_init()函數中:
max_threads = mempages / (THREAD_SIZE/PAGE_SIZE) / 8
在i386上,THREAD_SIZE=2*PAGE_SIZE,PAGE_SIZE=2^12(4KB),mempages=物理內存大小/PAGE_SIZE,對于256M的內存的機器,mempages=256*2^20/2^12=256*2^8,此時最大線程數為4096。
但為了保證每個用戶(除了root)的進程總數不至于占用一半以上物理內存,fork_init()中繼續指定:
init_task.rlim[RLIMIT_NPROC].rlim_cur = max_threads/2; init_task.rlim[RLIMIT_NPROC].rlim_max = max_threads/2;
這些進程數目的檢查都在do_fork()中進行,因此,對于LinuxThreads來說,線程總數同時受這三個因素的限制。
4)管理線程問題
管理線程容易成為瓶頸,這是這種結構的通病;同時,管理線程又負責用戶線程的清理工作,因此,盡管管理線程已經屏蔽了大部分的信號,但一旦管理線程死亡,用戶線程就不得不手工清理了,而且用戶線程并不知道管理線程的狀態,之后的線程創建等請求將無人處理。
5)同步問題
LinuxThreads中的線程同步很大程度上是建立在信號基礎上的,這種通過內核復雜的信號處理機制的同步方式,效率一直是個問題。
6)其他POSIX兼容性問題
Linux中很多系統調用,按照語義都是與進程相關的,比如nice、setuid、setrlimit等,在目前的LinuxThreads中,這些調用都僅僅影響調用者線程。
7)實時性問題
線程的引入有一定的實時性考慮,但LinuxThreads暫時不支持,比如調度選項,目前還沒有實現。不僅LinuxThreads如此,標準的Linux在實時性上考慮都很少。
四。其他的線程實現機制
LinuxThreads的問題,特別是兼容性上的問題,嚴重阻礙了Linux上的跨平臺應用(如Apache)采用多線程設計,從而使得Linux上的線程應用一直保持在比較低的水平。在Linux社區中,已經有很多人在為改進線程性能而努力,其中既包括用戶級線程庫,也包括核心級和用戶級配合改進的線程庫。目前最為人看好的有兩個項目,一個是RedHat公司牽頭研發的NPTL(Native Posix Thread Library),另一個則是IBM投資開發的NGPT(Next Generation Posix Threading),二者都是圍繞完全兼容POSIX 1003.1c,同時在核內和核外做工作以而實現多對多線程模型。這兩種模型都在一定程度上彌補了LinuxThreads的缺點,且都是重起爐灶全新設計的。
1.NPTL
NPTL的設計目標歸納可歸納為以下幾點:
POSIX兼容性
SMP結構的利用
低啟動開銷
低鏈接開銷(即不使用線程的程序不應當受線程庫的影響)
與LinuxThreads應用的二進制兼容性
軟硬件的可擴展能力
多體系結構支持
NUMA支持
與C++集成
在技術實現上,NPTL仍然采用1:1的線程模型,并配合glibc和最新的Linux Kernel2.5.x開發版在信號處理、線程同步、存儲管理等多方面進行了優化。和LinuxThreads不同,NPTL沒有使用管理線程,核心線程的管理直接放在核內進行,這也帶了性能的優化。
主要是因為核心的問題,NPTL仍然不是100%POSIX兼容的,但就性能而言相對LinuxThreads已經有很大程度上的改進了。
2.NGPT
IBM的開放源碼項目NGPT在2003年1月10日推出了穩定的2.2.0版,但相關的文檔工作還差很多。就目前所知,NGPT是基于GNU Pth(GNU Portable Threads)項目而實現的M:N模型,而GNU Pth是一個經典的用戶級線程庫實現。
按照2003年3月NGPT官方網站上的通知,NGPT考慮到NPTL日益廣泛地為人所接受,為避免不同的線程庫版本引起的混亂,今后將不再進行進一步開發,而今進行支持性的維護工作。也就是說,NGPT已經放棄與NPTL競爭下一代Linux POSIX線程庫標準。
3.其他高效線程機制
此處不能不提到Scheduler Activations。這個1991年在ACM上發表的多線程內核結構影響了很多多線程內核的設計,其中包括Mach3.0、NetBSD和商業版本Digital Unix(現在叫Compaq True64 Unix)。它的實質是在使用用戶級線程調度的同時,盡可能地減少用戶級對核心的系統調用請求,而后者往往是運行開銷的重要來源。采用這種結構的線程機制,實際上是結合了用戶級線程的靈活高效和核心級線程的實用性,因此,包括Linux、FreeBSD在內的多個開放源碼操作系統設計社區都在進行相關研究,力圖在本系統中實現Scheduler Activations。










 工商網監
工商網監
評論