 電子發燒友App
電子發燒友App


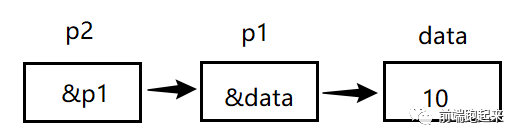
提到指針,我們都知道指針是用來存儲一個變量的地址。所以,當我們定義了一個指向指針的指針的時候(pointer to pointer),我們也稱之為二級指針,那針對于這個二級指針來說,第一級指針存放的是指向的變量的地址,第二級指針存放的是第一級指針的地址。可以用下面這張圖表示他們之間的關系。
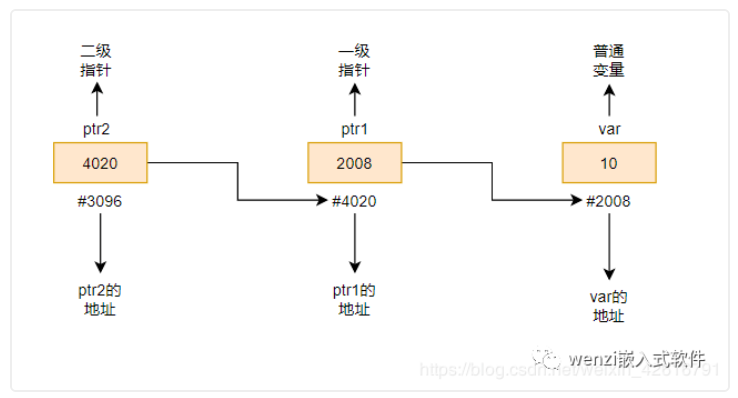
二級指針關系圖
上圖所表達的意思也就是,一級指針變量 ptr1 存放的是 var 變量的地址,二級指針變量 ptr2 存放的是一級指針變量的地址。這也就是關于二級指針的相關概念。
一級指針與二級指針關系示例

下圖是代碼運行的結果:
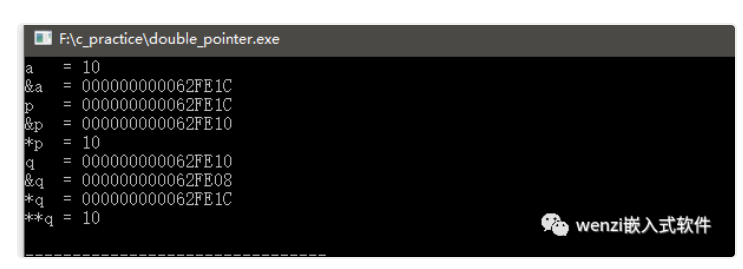
代碼運行結果截圖
結果也很明顯了,一級指針變量 p 存放的是變量 a 的地址,二級指針變量 q 存放的是一級指針變量 p 的地址,所以根據以上結果也能得出下面的等式:
q = &p;*q = p = &a;**q = *p = a;
在了解了上述一級指針和二級指針的一個關系之后,我們再來看另外一個例子:
現在有如下代碼:
int main(void){ int **ipp; int i = 5,j = 6,k = 7; int *ip1 = &i,*ip2 = &j; }
如果這個時候,我們加了這么一句代碼:
ipp = &ip1;
那么上述所涉及到的數據之間的關系是這樣的:
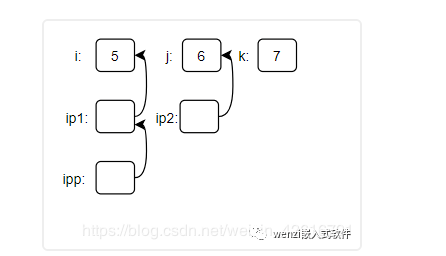
變量關系圖
根據上面這個圖我們也可以知道,對于 ipp 的兩次解引用的結果是 i 的值,也就是說 **ipp = 5,我想對于這個的理解并不困難,如果我繼續在這個基礎上添加代碼,注意,是在上條代碼的基礎上添加如下代碼:
*ipp = ip2;
在這條代碼的作用下,數據關系圖就發生了改變,改變如下所示:
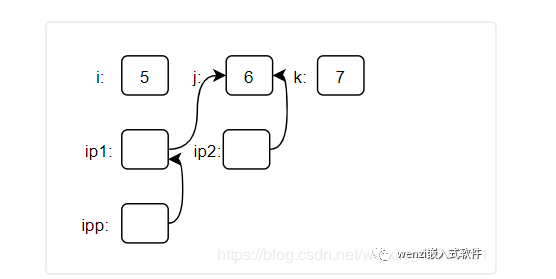
數據關系圖
對于上述的變化來說,我們增加的代碼改變的是 *ipp 的值,也就是說 ipp 的值是不會發生改變的,既然 ipp 的值不會發生改變,那么 ipp 指向 ip1 的關系不會發生改變,我們增加的代碼改變了 *ipp 的值,那么也就是說改變了一級指針指向的值,而 ip2 是指向 j 的,所以也就有了上述的變化。
緊接著我們繼續在第一條增加的代碼的基礎上重新增加一條代碼,增加的代碼如下:
*ipp = &k;
那么這個時候所對應的數據關系圖如下圖所示:
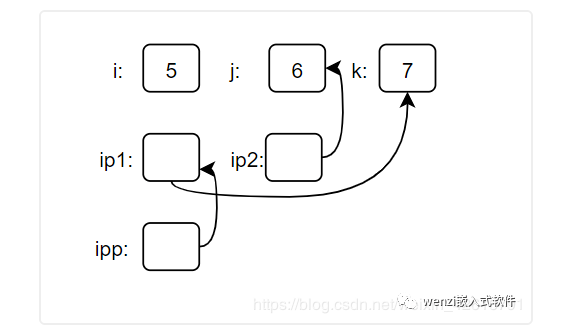
數據關系圖
這個原理和剛才的一樣,不在這里贅述了。
二級指針的應用那再講述了上述的基本概念之后,我們知道二級指針變量是用于存放一級指針變量的地址的,那么在具體的實際應用中,又在什么地方可以用到二級指針呢?下面來看一個 C 語言函數傳址調用的例子。
我們在剛學習指針的時候,都會碰到如下這樣一個例子:
void swap(int *a,int *b){ int temp; temp = *a; *a = *b; *b = temp;}
之所以在定義函數時,把函數的形參定義為指針,而非如下這樣的形式:
void swap(int a,int b);
是因為C 語言在進行函數調用的時候,是將實參的值復制一份,并將其副本傳遞到函數調用里,如果形參定義的不是指針,那么在函數內部改變數值,不會對實參本來的值發生改變。而將形參定義成了指針的話,那么傳到函數里面的值雖然是實參地址的一個副本,但是地址里存的值發生了改變,也就導致實參本來的值也發生了改變。
有了上述分析的基礎上,我們知道,如果要在一個函數內改變一個數的值,那么就需要將形參定義為指針。同樣的,如果我們要在一個函數內改變一個指針的值,我們就需要將形參定義了二級指針,下面來看這樣一個例子:
#include 《stdlib.h》int allocstr(int len,char **retptr){ char *p = malloc(len + 1);/*加 1 是為了 ‘\0’ */ if (p = NULL) return 0; *retptr = p; return 1;}
在調用的時候,是像下面這樣子進行調用的:
char *string = “hello world!”char *copystr;if (allostr(strlen(string),?str)) strcpy(copystr,string);else printf(“out of memory!\n”);
上述這個例子就是涉及到字符串拷貝的一個實際的例子,因為我們要在 allostr 里改變指針變量 copystr 的值(要使用 malloc 分配內存),那么就需要把 copystr 的地址傳到函數里,那么這個時候,所定義的函數形參也就需要是二級指針了。
二級指針在單鏈表中的應用首先,我們有這樣一個單鏈表的數據結構:
typedef struct ListNode{ int data; struct ListNode *next;}ListNode;
依據這樣一個數據結構,假定我們創建了一個如下所示的一個單鏈表:
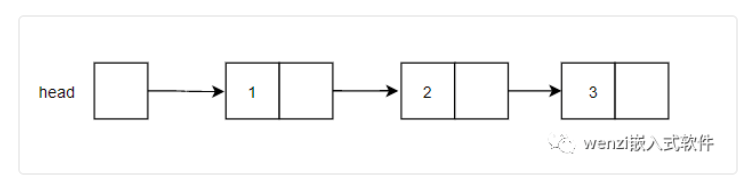
單鏈表
那么我們如果要刪除鏈表中的一個結點的時候,第一時間采用的可能是如下所示的代碼:
ListNode *find_and_delete(ListNode *head,int target){ ListNode *pre = NULL; ListNode *entry; for (entry = head; entry != NULL; entry = entry-》next) { if (entry-》data == target) { /* 判斷刪除的結點是否是第一個結點*/ if (entry == head) head = entry-》next; else pre-》next = entry-》next; free(entry); break; } pre = entry; } return head;}
上述代碼所述的刪除結點的思路遵循如下圖所示的原理,首先是關于當所要刪除的結點是第一個結點的時候,刪除結點示意圖如下所示:
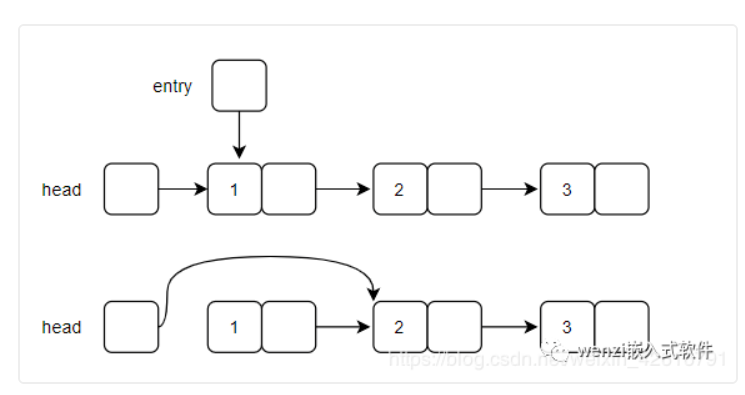
第一個結點刪除原理
如果要刪除的結點不是處在第一個結點的位置,那么刪除結點的原理示意圖如下圖所示:
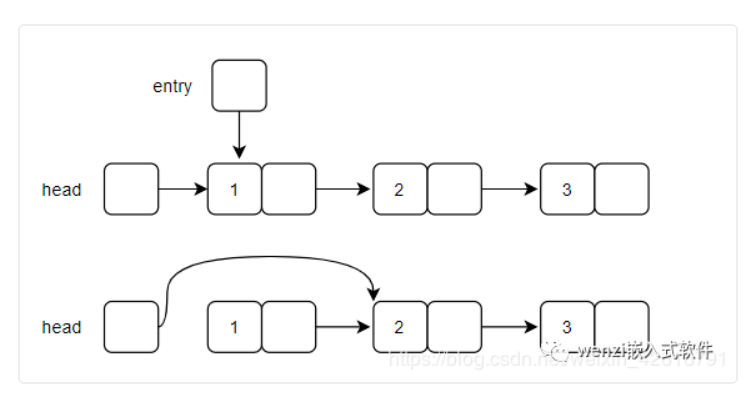
普通結點刪除
上述就是一個使用一級指針操作鏈表的一個簡單地例子,自己在理解這個例子的時候,也存在幾個對我來說的難點,筆者寫下來和大家分享一下,首先,
第一個難點就是頭指針,在圖中畫的頭指針指向了第一個結點,圖中所示的頭指針并沒有數據域,只是單單地指向了第一個結點,在代碼中的 head 指針變量卻有數據域,并且就是第一個結點的數據,這個概念的理解其實是對于指針的理解,head 指向了第一個結點,一定注意在這里的 head 是頭指針,并不是頭結點。(這是筆者個人的理解,如果大家有不同的看法,歡迎各位朋友添加筆者微信共同探討)。
第二個難點就是上述函數中,函數有一個返回值,返回了頭指針。為什么要返回呢?是因為當前傳入函數的形參是一級指針,在函數內部改變 head ,在函數運行結束時,head 值并不會發生改變,所以要返回。
第三個難點,那么為什么鏈表操作中,又能夠刪除中間的結點呢?是因為雖然 傳進去的 head 是一級指針,但是 head 結構體成員內的 next 是一個指針,那這樣的話,對于 next 成員來說它是一個二級指針,對于他的變化,在函數結束時是會產生改變的,所以可以刪除中間的結點。
二級指針在單鏈表結點刪除的應用上面的例子中,在刪除單鏈表的結點的時候,我們形參采用的是一級指針的方式,在這個過程中,還需要引入 pre 指針來解決這個問題,還有一種很巧妙的方法,利用了二級指針的特性解決了結點刪除的問題,在這個過程中,運用二級指針,不需要進行刪除第一個結點的判斷。具體代碼如下:
void find_and_delete2(ListNode **head,int target){ for (; *head != NULL; head = &(*head)-》next) { if ((*head)-》data == target) { (*head) = (*head)-》next; break; } } }
上述的代碼沒有創建任何局部變量,直接利用 head 進行遍歷鏈表,因為其是二級指針,這樣子進行遍歷在函數結束后不會改變其本身的鏈表結構。然后,在進行刪除的時候,(*head) 在函數結束后是會保持其在函數內的變化值的,所以也就完成了結點的刪除。














 工商網監
工商網監
評論