 電子發(fā)燒友App
電子發(fā)燒友App


Pandas 是針對(duì) Python 編程語(yǔ)言進(jìn)行數(shù)據(jù)操作和數(shù)據(jù)分析的熱門(mén)軟件庫(kù)。
什么是 PANDAS?
Pandas 是一個(gè)基于 Python 構(gòu)建的專(zhuān)門(mén)進(jìn)行數(shù)據(jù)操作和分析的開(kāi)源軟件庫(kù),可提供數(shù)據(jù)結(jié)構(gòu)和運(yùn)算,進(jìn)行功能現(xiàn)強(qiáng)大、靈活且易于使用的數(shù)據(jù)分析和操作。Pandas 為熱門(mén)編程語(yǔ)言賦予了處理類(lèi)似電子表格的數(shù)據(jù)的能力,從而增強(qiáng)了 Python 功能,除其他關(guān)鍵功能外,加快了加載、對(duì)齊、操作和合并的速度。后端源代碼以 C 或 Python 編寫(xiě)時(shí),Pandas 可提供高度優(yōu)化的性能,這一點(diǎn)備受贊賞。
“Pandas”的名稱(chēng)源自計(jì)量經(jīng)濟(jì)學(xué)術(shù)語(yǔ)“panel data”,用于描述包含多個(gè)時(shí)間段觀察結(jié)果的數(shù)據(jù)集。Pandas 庫(kù)是在 Python 中執(zhí)行非常實(shí)用的現(xiàn)實(shí)分析的高級(jí)工具或構(gòu)建塊。未來(lái),其創(chuàng)作者計(jì)劃將 Pandas 發(fā)展為適用于任何編程語(yǔ)言的功能更加強(qiáng)大、更靈活的開(kāi)源數(shù)據(jù)分析和數(shù)據(jù)操作工具。
有人稱(chēng) Pandas 使用 Python 分析數(shù)據(jù),“顛覆了游戲規(guī)則”;當(dāng)前,它已躋身于最熱門(mén)、廣泛使用的數(shù)據(jù)整理工具之列。其中描述了將數(shù)據(jù)從不可用或錯(cuò)誤的形式中提取到現(xiàn)代分析處理所需的結(jié)構(gòu)和質(zhì)量級(jí)別時(shí)使用的一組概念和一種方法。Pandas 的優(yōu)勢(shì)在于可輕松處理表格、矩陣和時(shí)間序列數(shù)據(jù)等結(jié)構(gòu)化數(shù)據(jù)格式。此外,它還可以與其他 Python 科學(xué)庫(kù)結(jié)合使用,且效果良好。
PANDAS 的工作原理
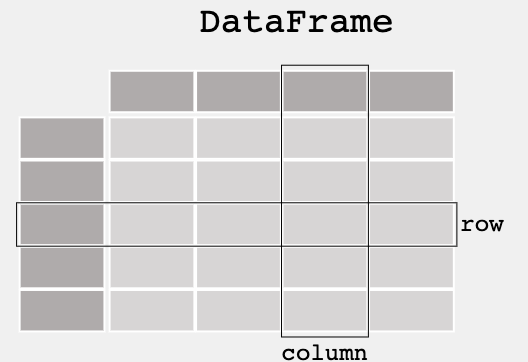
Pandas 開(kāi)源庫(kù)內(nèi)提供了 DataFrame。DataFrame 是二維數(shù)組式數(shù)據(jù)表,其中每列包含一個(gè)變量的值,每行包含一組每列的值。DataFrame 中存儲(chǔ)的數(shù)據(jù)可以是數(shù)字、系數(shù),也可以是字符類(lèi)型。也可以將 Pandas DataFrame 視作系列對(duì)象的詞典或集合。
對(duì) R 編程語(yǔ)言熟悉的數(shù)據(jù)科學(xué)家和編程人員都知道,可以使用 DataFrame 將數(shù)據(jù)存儲(chǔ)在易于概述的網(wǎng)格中。這表明 Pandas 主要用于 DataFrame 形式的機(jī)器學(xué)習(xí)。
Pandas 支持導(dǎo)入和導(dǎo)出不同格式的表格數(shù)據(jù),如 CSV 或 JSON 文件。

此外,Pandas 還支持各種數(shù)據(jù)操作運(yùn)算和數(shù)據(jù)清理功能,包括選擇子集、創(chuàng)建衍生列、排序、連接、填充、替換、匯總統(tǒng)計(jì)數(shù)據(jù)和繪圖。

?
?
Python 軟件包索引(Python 編程語(yǔ)言軟件庫(kù))的編制者表示,Pandas 非常適合處理多種數(shù)據(jù),包括:
包含異構(gòu)類(lèi)型列的表格數(shù)據(jù),如 SQL 表或 Excel 電子表格
有序和無(wú)序(可能并非固定頻率)時(shí)間序列數(shù)據(jù)
具有行和列標(biāo)簽的任意矩陣數(shù)據(jù)(同構(gòu)類(lèi)型或異構(gòu)類(lèi)型)
其他任何形式的可觀察/統(tǒng)計(jì)數(shù)據(jù)集。實(shí)際上,數(shù)據(jù)完全無(wú)需標(biāo)記即可放入 pandas 數(shù)據(jù)結(jié)構(gòu)中。
PANDAS 的優(yōu)勢(shì)
此外,Python 軟件包索引的編制者還表示,Pandas 為數(shù)據(jù)科學(xué)家和開(kāi)發(fā)者提供了幾個(gè)關(guān)鍵優(yōu)勢(shì),包括:
輕松處理浮點(diǎn)和非浮點(diǎn)數(shù)據(jù)中的缺失數(shù)據(jù)(表示為 NaN)
大小易變性:可以從 DataFrame 和更高維度的對(duì)象中插入和刪除列
自動(dòng)和顯式數(shù)據(jù)對(duì)齊:可以將對(duì)象顯式對(duì)齊到一組標(biāo)簽;或者用戶只需忽略標(biāo)簽,讓序列、DataFrame 等在計(jì)算中自動(dòng)調(diào)整數(shù)據(jù)
強(qiáng)大、靈活的分組功能,對(duì)數(shù)據(jù)集執(zhí)行分割-應(yīng)用-組合操作,進(jìn)行數(shù)據(jù)聚合和轉(zhuǎn)換
可輕松將其他 Python 和 Numpy 數(shù)據(jù)結(jié)構(gòu)中參差不齊、索引不同的數(shù)據(jù)轉(zhuǎn)換為 DataFrame 對(duì)象
大型數(shù)據(jù)集基于標(biāo)簽的智能切片、精美索引和子集構(gòu)建
直觀的數(shù)據(jù)集合并與連接
靈活的數(shù)據(jù)集重塑和旋轉(zhuǎn)
坐標(biāo)軸的分層標(biāo)記(每個(gè)記號(hào)可能具有多個(gè)標(biāo)簽)
強(qiáng)大的 I/O 工具,用于加載平面文件(CSV 和分隔文件)、Excel 文件和數(shù)據(jù)庫(kù)中的數(shù)據(jù),以及保存/加載超快速 HDF5 格式的數(shù)據(jù)
特定于時(shí)間序列的功能:日期范圍生成和頻率轉(zhuǎn)換、窗口統(tǒng)計(jì)數(shù)據(jù)遷移、日期調(diào)整和延遲
Pandas 庫(kù)的其他優(yōu)勢(shì)還包括:缺失數(shù)據(jù)的數(shù)據(jù)對(duì)齊和集成處理;數(shù)據(jù)集合并與連接;數(shù)據(jù)集重塑和旋轉(zhuǎn);分層軸索引(以便在低維數(shù)據(jù)結(jié)構(gòu)中處理高維數(shù)據(jù))以及基于標(biāo)簽的切片。
PYTHON 和 PANDAS
由于 Pandas 是基于 Python 編程語(yǔ)言構(gòu)建的,因此讓我們簡(jiǎn)要回顧一下 Python 編程語(yǔ)言。
Python 因其易用性深受數(shù)據(jù)科學(xué)家喜愛(ài),自 1991 年發(fā)布首個(gè)版本以來(lái)不斷演進(jìn),已成為網(wǎng)絡(luò)應(yīng)用程序、數(shù)據(jù)分析和機(jī)器學(xué)習(xí)領(lǐng)域的熱門(mén)編程語(yǔ)言之一。
Python 具有出色的易用性,它采用高度可讀的語(yǔ)法,即使是初學(xué)者也無(wú)需花費(fèi)多少時(shí)間學(xué)習(xí)即可生成程序。這樣,開(kāi)發(fā)者和數(shù)據(jù)科學(xué)家可以將更多時(shí)間用在解決業(yè)務(wù)問(wèn)題上,同時(shí)也減少了處理語(yǔ)言復(fù)雜性的時(shí)間。
Python 可在當(dāng)今使用的所有重要操作系統(tǒng)以及除 Pandas 之外的主要庫(kù)上運(yùn)行。API 服務(wù)還提供了 Python 鏈接或包裝器。這樣,Python 即可與其他服務(wù)和庫(kù)交互。
除了易于使用之外,Python 深受數(shù)據(jù)科學(xué)家和機(jī)器學(xué)習(xí)開(kāi)發(fā)者喜愛(ài)還有一個(gè)重要原因。隨著 Pandas 和 Numpy 等數(shù)據(jù)處理庫(kù)以及 Seaborn 和 Matplotlib 等數(shù)據(jù)可視化工具的推出,Python 成為了機(jī)器學(xué)習(xí)和數(shù)據(jù)科學(xué)家以及構(gòu)建機(jī)器學(xué)習(xí)系統(tǒng)的開(kāi)發(fā)者的通用語(yǔ)言。
PANDAS 與數(shù)據(jù)科學(xué)家
Pandas 解決了數(shù)據(jù)科學(xué)家在使用與科學(xué)和商業(yè)研究環(huán)境相關(guān)的語(yǔ)言時(shí)經(jīng)常遇到的許多問(wèn)題。在數(shù)據(jù)科學(xué)中,通常會(huì)將處理數(shù)據(jù)細(xì)分為多個(gè)階段,包括之前所述的整理和數(shù)據(jù)清理;數(shù)據(jù)分析和建模;將分析整理成適合繪圖的形式或以表格形式顯示出來(lái)。在處理這些任務(wù)及其他任務(wù)關(guān)鍵型數(shù)據(jù)科學(xué)任務(wù)時(shí),Pandas 表現(xiàn)卓越。
GPU 加速的 DATAFRAMES
CPU 由專(zhuān)為按序串行處理優(yōu)化的幾個(gè)核心組成,而 GPU 則擁有一個(gè)大規(guī)模并行架構(gòu),當(dāng)中包含數(shù)千個(gè)更小、更高效的核心,專(zhuān)為同時(shí)處理多重任務(wù)而設(shè)計(jì)。與僅包含 CPU 的配置相比,GPU 的數(shù)據(jù)處理速度快得多。它們還因其超低浮點(diǎn)運(yùn)算(性能)單價(jià)深受歡迎,其還可通過(guò)加快多核服務(wù)器的并行處理速度,解決當(dāng)前的計(jì)算性能瓶頸問(wèn)題。?

過(guò)去幾年 GPU 一直肩負(fù)著推動(dòng)深度學(xué)習(xí)發(fā)展的重任,而 ETL 和傳統(tǒng)機(jī)器學(xué)習(xí)工作負(fù)載依然是采用 Python 進(jìn)行編寫(xiě),并且通常是使用 Scikit-Learn 等單線程工具或通過(guò) Spark 等大型多 CPU 分布式解決方案進(jìn)行編寫(xiě)。
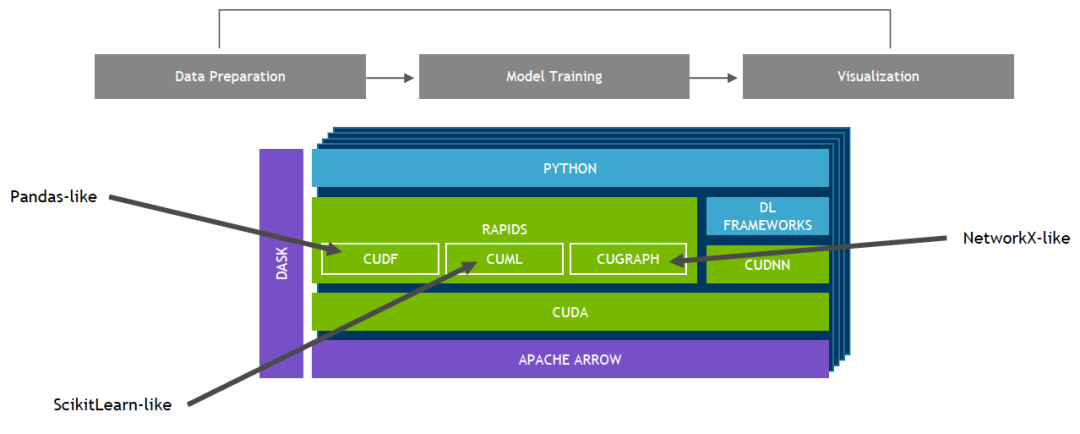
NVIDIA 開(kāi)發(fā)了 RAPIDS,這是一個(gè)開(kāi)源的數(shù)據(jù)分析和機(jī)器學(xué)習(xí)加速平臺(tái),用于完全在 GPU 中執(zhí)行端到端數(shù)據(jù)科學(xué)訓(xùn)練管線。它依賴(lài)于 NVIDIA CUDA?基元進(jìn)行低級(jí)別計(jì)算優(yōu)化,但通過(guò)用戶友好型 Python 界面實(shí)現(xiàn) GPU 并行結(jié)構(gòu)和極高的顯存帶寬。
RAPIDS 側(cè)重于有關(guān)分析和數(shù)據(jù)科學(xué)的通用數(shù)據(jù)準(zhǔn)備任務(wù),可提供 GPU 加速的 DataFrame。DataFrame 模仿 pandas API,且構(gòu)建在 Apache Arrow 之上。它集成了 scikit-learn 和各種機(jī)器學(xué)習(xí)算法,無(wú)需支付典型的序列化成本即可更大限度實(shí)現(xiàn)互操作性和高性能。這可加速端到端流程(從數(shù)據(jù)準(zhǔn)備到機(jī)器學(xué)習(xí),再到深度學(xué)習(xí))。? RAPIDS 還包括對(duì)多節(jié)點(diǎn)、多 GPU 部署的支持,大大加快了對(duì)更大規(guī)模數(shù)據(jù)集的處理和訓(xùn)練。
審核編輯:湯梓紅










 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論