 電子發燒友App
電子發燒友App


?
作者簡介
趙亞楠,攜程資深架構師,負責攜程云平臺網絡虛擬化、云原生安全、內核等基礎設施研發工作。
本文嘗試從技術研發與工程實踐(而非純理論學習)角度,在原理與實現、監控告警、 配置調優三方面介紹內核5.10 網絡棧。由于內容非常多,因此分為了幾篇系列文章。
原理與實現
1.Linux 網絡棧原理、監控與調優:前言2.Linux 中斷(IRQ/softirq)基礎:原理及內核實現3.Linux 網絡棧接收數據(RX):原理及內核實現
監控
1.Monitoring Linux Network Stack調優
1.Linux 網絡棧接收數據(RX):配置調優
目錄
1 網絡設備驅動初始化? ? ? 1.1 調整 RX 隊列數量(ethtool -l/-L)? ? ? 1.2 調整 RX 隊列大小(ethtool -g/-G)? ? ? 1.4 調整 RX 隊列權重(ethtool -x/-X)? ? ? 1.5 調整 RSS RX 哈希字段(ethtool -n/-N)? ? ? 1.6 Flow 綁定到 CPU:ntuple filtering(ethtool -k/-K, -u/-U)2 IRQ? ? ?2.1 中斷合并(Interrupt coalescing,ethtool -c/-C)? ? ?
? ? ?2.2 調整硬中斷親和性(IRQ affinities,/proc/irq//smpaffinity)
3 SoftIRQ??
? ? ?3.1 問題討論? ? ? ??? ? ?
? ? ?3.2 調整 softirq 收包預算:sysctl netdevbudget/netdevbudgetusecs4 softirq:從 ring buffer 收包送到協議棧? ? ? ?
? ? ? 4.1 修改 GRO 配置(ethtool -k/-K)? ?
? ? ? 4.2 sysctl gronormalbatch
? ? ? 4.3 RPS 調優?
? ? ? 4.4 調優:打開 RFS
? ? ? 4.5 調優: 啟用 aRFS5 協議棧:L2 處理? ? ? 5.1 調優: 何時給包打時間戳(sysctl net.core.netdevtstampprequeue)? ? ? ? ? ??
? ? ? 5.2 調優(老驅動)? ??
? ?? ?5.3 調優:sysctl net.core.flowlimittablelen
6 協議棧:L3 處理(IPv4)? ? ? 6.1 調優: 打開或關閉 IP 協議的 early demux 選項7 協議棧:L4 處理(UDP)? ??
? ? ? 7.1 調優: socket receive buffer(sysctl net.core.rmemdefault/rmemmax)參考資料
?
網絡棧非常復雜,沒有一種放之四海而皆準的通用配置。如果網絡性能和指標對你們團隊和業務非常重要, 那別無選擇,只能投入大量的時間、精力和資源去深入理解系統的各個部分是如何工作的。理想情況下,應該監控網絡棧各個層級的丟包及其他健康狀態, 這樣遇到問題時就能快速縮小范圍,判斷哪個組件或模塊需要調優。
本文展示一些從下到上的配置調優示例,但注意這些配置并不作為任何特定配置或默認配置的建議。此外,
-
在任何配置變更之前,應該有一個能夠對系統進行監控的框架,以確認調整是否帶來預期的效果;
-
對遠程連接上的機器進行網絡變更是相當危險的,機器很可能失聯;
-
不要在生產環境直接調整配置;盡量先在線下或新機器上驗證效果,然后灰度到生產。本文章號與圖中對應。接下來就從最底層的網卡開始。
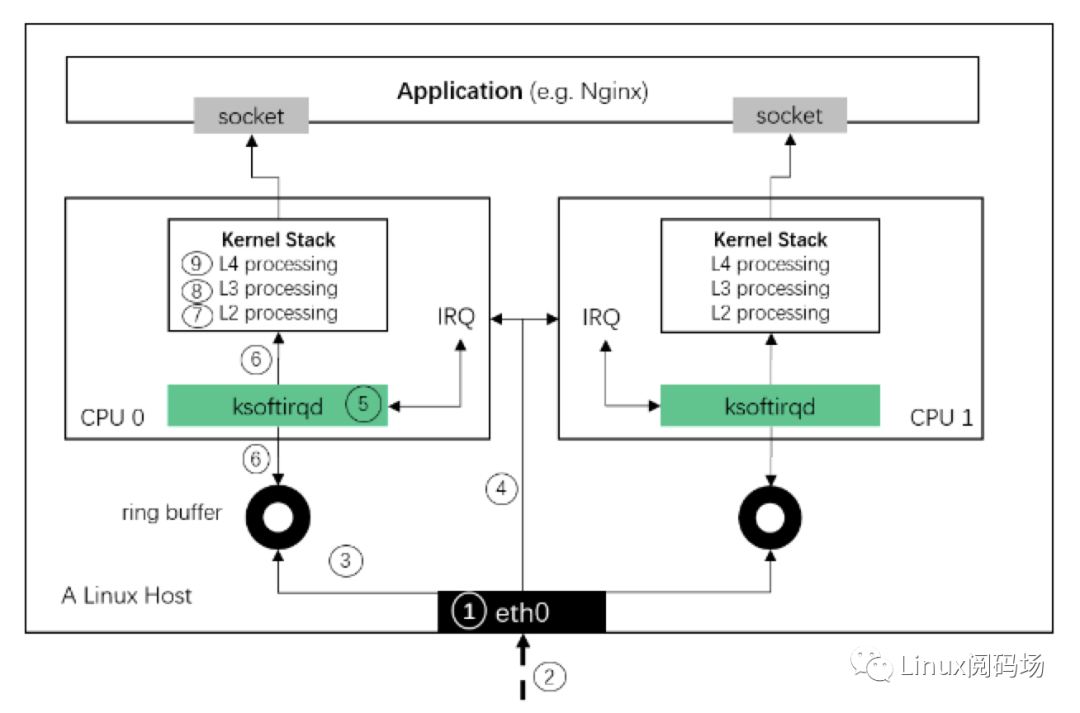
Fig. Steps of Linux kernel receiving data process and the corresponding chapters in this post
?
1?網絡設備驅動初始化
?
1.RX 隊列的數量和大小可以通過 ethtool 進行配置,這兩個參數會對收包或丟包產生顯著影響。
2.網卡通過對 packet 頭(例如源地址、目的地址、端口等)做哈希來決定將 packet 放到 哪個 RX 隊列。對于支持自定義哈希的網卡,可以通過自定義算法將特定 的 flow 發到特定的隊列,甚至可以做到在硬件層面直接將某些包丟棄。
3.一些網卡支持調整 RX 隊列的權重,將流量按指定的比例發到指定的 queue。
1.1 調整 RX 隊列數量(ethtool -l/-L)
如果網卡及其驅動支持 RSS/多隊列,可以調整 RX queue(也叫 RX channel)的數量。
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
$ sudo ethtool -l eth0Channel parameters for eth0:Pre-set maximums:RX: 0TX: 0Other: 0Combined: 40Current hardware settings:RX: 0TX: 0Other: 0Combined: 40
可以看到硬件最多支持 40 個,當前也用滿了 40 個。
注意:不是所有網卡驅動都支持這個操作。不支持的網卡會報如下錯誤:
- ?
- ?
- ?
- ?
$ sudo ethtool -l eth0Channel parameters for eth0:Cannot get device channel parameters: Operation not supported
這意味著驅動沒有實現 ethtool 的 get_channels() 方法。可能原因:該網卡不支持 調整 RX queue 數量,不支持 RSS/multiqueue 等。
ethtool -L 可以修改 RX queue 數量(ethtool 參數 有個慣例,小寫一般都是查詢某個配置,對應的大寫表示修改這個配置)。不過這里需要注意,
-
某些廠商的網卡中,RX 隊列和 TX 隊列是可以獨立調整的,例如修改 RX queue 數量:
- ?
$ sudo ethtool -L eth0 rx 8
-
另一些廠商網卡中,二者是一一綁定的,稱為 combined queue,這種模式下, 調整 RX 隊列的數量也會同時調整 TX queue 的數量,例如
- ?
$ sudo ethtool -L eth0 combined 8 # 將 RX 和 TX queue 數量都設為了 8
注意:對于大部分驅動,修改以上配置會使網卡先 down 再 up,因此會造成丟包!請謹慎操作。
?
1.2 調整 RX 隊列大小(ethtool -g/-G)
?
也就是調整每個 RX 隊列中 descriptor 的數量,一個 descriptor 對應一個包。這個能不能調整也要看具體的網卡和驅動。增大 ring buffer 可以在 PPS(packets per second)很大時緩解丟包問題。
查看 queue 的大小:
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
$ sudo ethtool -g eth0Ring parameters for eth0:Pre-set maximums:RX: 4096RX Mini: 0RX Jumbo: 0TX: 4096Current hardware settings:RX: 512RX Mini: 0RX Jumbo: 0TX: 512
以上輸出顯示網卡最多支持 4096 個 RX/TX descriptor,但是現在只用到了 512 個。ethtool -G 修改 queue 大小:
- ?
$ sudo ethtool -G eth0 rx 4096
注意:對于大部分驅動,修改以上配置會使網卡先 down 再 up,因此會造成丟包。請謹慎操作。
?
1.3?調整 RX 隊列權重(ethtool -x/-X)
?
一些網卡支持給不同的 queue 設置不同的權重(weight),權重越大, 每次網卡 poll() 能處理的包越多。如果網卡支持以下功能,就可以設置權重:
1.支持 flow indirection;
2.驅動實現了 getrxfhindirsize() 和 getrxfh_indir() 方法;檢查 flow indirection 設置:
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
$ sudo ethtool -x eth0RX flow hash indirection table for eth0 with 40 RX ring(s):0: 0 1 2 3 4 5 6 78: 8 9 10 11 12 13 14 1516: 16 17 18 19 20 21 22 2324: 24 25 26 27 28 29 30 3132: 32 33 34 35 36 37 38 3940: 0 1 2 3 4 5 6 748: 8 9 10 11 12 13 14 15...RSS hash key:9ae3ed14a0e5e8ecRSS hash function:toeplitz: offxor: oncrc32: off
第一列是改行的第一個哈希值,冒號后面的每個哈希值對應的 RX queue。例如,
-
第一行的哈希值是 0~7,分別對應 RX queue 0~7;
-
第六行的哈希值是 40~47,分別對應的也是 RX queue 0~7。
?
- ?
- ?
- ?
- ?
- ?
在前兩個 RX queue 之間均勻的分發接收到的包$ sudo ethtool -X eth0 equal 2設置自定義權重:給 rx queue 0 和 1 不同的權重:6 和 2$ sudo ethtool -X eth0 weight 6 2
注意 queue 一般是和 CPU 綁定的,因此這也意味著相應的 CPU 也會花更多的時間片在收包上。一些網卡還支持修改計算 hash 時使用哪些字段。
?
1.4?調整 RSS RX 哈希字段(ethtool -n/-N)
?
可以用 ethtool 調整 RSS 計算哈希時所使用的字段。
例子:查看 UDP RX flow 哈希所使用的字段:
- ?
- ?
- ?
- ?
$ sudo ethtool -n eth0 rx-flow-hash udp4UDP over IPV4 flows use these fields for computing Hash flow key:IP SAIP DA
可以看到只用到了源 IP(SA:Source Address)和目的 IP。
我們修改一下,加入源端口和目的端口:
- ?
$ sudo ethtool -N eth0 rx-flow-hash udp4 sdfn
sdfn 的具體含義解釋起來有點麻煩,請查看 ethtool 的幫助(man page)。
調整 hash 所用字段是有用的,而 ntuple 過濾對于更加細粒度的 flow control 更加有用。
?
1.5 Flow 綁定到 CPU:ntuple filtering(ethtool -k/-K, -u/-U)
一些網卡支持 “ntuple filtering” 特性。該特性允許用戶(通過 ethtool )指定一些參數來 在硬件上過濾收到的包,然后將其直接放到特定的 RX queue。例如,用戶可以指定到特定目 端口的 TCP 包放到 RX queue 1。
Intel 的網卡上這個特性叫 Intel Ethernet Flow Director,其他廠商可能也有他們的名字 ,這些都是出于市場宣傳原因,底層原理是類似的。
ntuple filtering 其實是 Accelerated Receive Flow Steering (aRFS) 功能的核心部分之一, 這個功能在原理篇中已經介紹過了。aRFS 使得 ntuple filtering 的使用更加方便。
適用場景:最大化數據局部性(data locality),提高 CPU 處理網絡數據時的 緩存命中率。例如,考慮運行在 80 口的 web 服務器:
1.webserver 進程運行在 80 口,并綁定到 CPU 22.和某個 RX queue 關聯的硬中斷綁定到 CPU 23.目的端口是 80 的 TCP 流量通過 ntuple filtering 綁定到 CPU 24.接下來所有到 80 口的流量,從數據包進來到數據到達用戶程序的整個過程,都由 CPU 2 處理5.監控系統的緩存命中率、網絡棧的延遲等信息,以驗證以上配置是否生效
?
檢查 ntuple filtering 特性是否打開:
- ?
- ?
- ?
- ?
- ?
$ sudo ethtool -k eth0Offload parameters for eth0:...ntuple-filters: offreceive-hashing: on
可以看到,上面的 ntuple 是關閉的。
打開:
- ?
$ sudo ethtool -K eth0 ntuple on
打開 ntuple filtering 功能,并確認打開之后,可以用 ethtool -u 查看當前的 ntuple rules:
- ?
- ?
- ?
$ sudo ethtool -u eth040 RX rings availableTotal 0 rules
可以看到當前沒有 rules。
我們來加一條:目的端口是 80 的放到 RX queue 2:
- ?
$ sudo ethtool -U eth0 flow-type tcp4 dst-port 80 action 2
也可以用 ntuple filtering 在硬件層面直接 drop 某些 flow 的包。當特定 IP 過來的流量太大時,這種功能可能會派上用場。更多關于 ntuple 的信息,參考 ethtool man page。
ethtool -S的輸出統計里,Intel 的網卡有 fdirmatch 和 fdirmiss 兩項, 是和 ntuple filtering 相關的。關于具體、詳細的統計計數,需要查看相應網卡的設備驅 動和 data sheet。
2?IRQ
?
2.1 中斷合并(Interrupt coalescing,ethtool -c/-C)
中斷合并會將多個中斷事件放到一起,累積到一定閾值后才向 CPU 發起中斷請求。
-
優點:防止中斷風暴,提升吞吐,降低 CPU 使用量
-
缺點:延遲變大
?
查看:
?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
$ ethtool -c eth0Coalesce parameters for eth0:Adaptive RX: on TX: on # 自適應中斷合并stats-block-usecs: 0sample-interval: 0pkt-rate-low: 0pkt-rate-high: 0rx-usecs: 8rx-frames: 128rx-usecs-irq: 0rx-frames-irq: 0tx-usecs: 8tx-frames: 128tx-usecs-irq: 0tx-frames-irq: 0rx-usecs-low: 0rx-frame-low: 0tx-usecs-low: 0tx-frame-low: 0rx-usecs-high: 0rx-frame-high: 0tx-usecs-high: 0tx-frame-high: 0
不是所有網卡都支持這些配置。根據 ethtool 文檔:“驅動沒有實現的接口將會被靜默忽略”。
某些驅動支持“自適應 RX/TX 硬中斷合并”,效果是帶寬比較低時降低延遲,帶寬比較高時 提升吞吐。這個特性一般是在硬件實現的。
用 ethtool -C 打開自適應 RX IRQ 合并:
- ?
$ sudo ethtool -C eth0 adaptive-rx on
還可以用 ethtool -C 更改其他配置。常用的包括:
-
rx-usecs: How many usecs to delay an RX interrupt after a packet arrives.
-
rx-frames: Maximum number of data frames to receive before an RX interrupt.
-
rx-usecs-irq: How many usecs to delay an RX interrupt while an interrupt is being serviced by the host.
-
rx-frames-irq: Maximum number of data frames to receive before an RX interrupt is generated while the system is servicing an interrupt.
?
每個配置項的含義見 include/uapi/linux/ethtool.h。
?
注意:雖然硬中斷合并看起來是個不錯的優化項,但需要網絡棧的其他一些 部分做針對性調整。只合并硬中斷很可能并不會帶來多少收益。
?
2.2 調整硬中斷親和性(IRQ affinities,/proc/irq//smp_affinity)
這種方式能手動配置哪個 CPU 負責處理哪個 IRQ。但在配置之前,需要先確保關閉 irqbalance 進程(或者設置 --banirq 指定不要對那些 CPU 做 balance) 否則它會定期自動平衡 IRQ 和 CPU 映射關系,覆蓋我們的手動配置。
然后,通過 cat /proc/interrupts 查看網卡的每個 RX 隊列對應的 IRQ 編號。
最后,通過設置 /proc/irq//smp_affinity 來指定哪個 CPU 來處理這個 IRQ。注意這里的格式是 16 進制的 bitmask。
例子:指定 CPU 0 來處理 IRQ 8:
- ?
$ sudo bash -c 'echo 1 > /proc/irq/8/smp_affinity'
?
3?SoftIRQ
?
3.1 問題討論
?
關于 NAPI pool 機制
?
-
這是 Linux 內核中的一種通用抽象,任何等待不可搶占狀態發生(wait for a preemptible state to occur)的模塊,都可以使用這種注冊回調函數的方式。
-
驅動注冊的這個 poll 是一個主動式 poll(active poll),一旦執行就會持續處理 ,直到沒有數據可供處理,然后進入 idle 狀態。
-
在這里,執行 poll 方法的是運行在某個或者所有 CPU 上的內核線程(kernel thread)。雖然這個線程沒有數據可處理時會進入 idle 狀態,但如前面討論的,在當前大部分分布 式系統中,這個線程大部分時間內都是在運行的,不斷從驅動的 DMA 區域內接收數據包。
-
poll 會告訴網卡不要再觸發硬件中斷,使用軟件中斷(softirq)就行了。此后這些 內核線程會輪詢網卡的 DMA 區域來收包。之所以會有這種機制,是因為硬件中斷代價太 高了,因為它們比系統上幾乎所有東西的優先級都要高。
?
我們接下來還將多次看到這個廣義的 NAPI 抽象,因為它不僅僅處理驅動,還能處理許多 其他場景。內核用 NAPI 抽象來做驅動讀取(driver reads)、epoll 等等。
NAPI 驅動的 poll 機制將數據從 DMA 區域讀取出來,對數據做一些準備工作,然后交給比 它更上一層的內核協議棧。
軟中斷的信息可以從 /proc/softirqs 讀取:
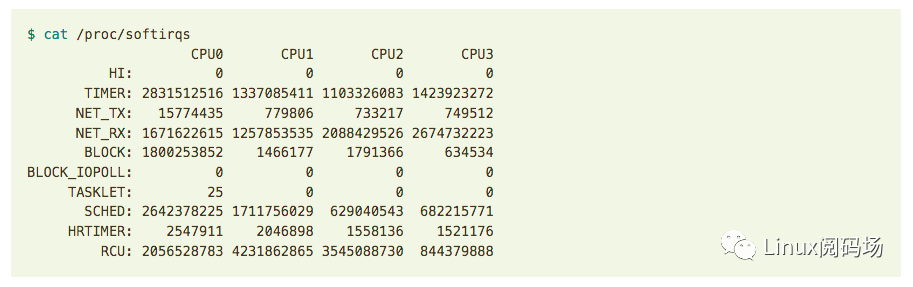
監控這些數據可以得到軟中斷的執行頻率信息。
例如,NETRX 一行顯示的是軟中斷在 CPU 間的分布。如果分布非常不均勻,那某一列的 值就會遠大于其他列,這預示著下面要介紹的 Receive Packet Steering / Receive Flow Steering 可能會派上用場。但也要注意:不要太相信這個數值,NETRX 太高并不一定都 是網卡觸發的,其他地方也有可能觸發。
調整其他網絡配置時,可以留意下這個指標的變動。
perf 跟蹤 IRQ/Softirq 調用
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
$ sudo perf record -a-e irq:irqhandlerentry,irq:irqhandlerexit-e irq:softirqentry --filter="vec == 3"-e irq:softirqexit --filter="vec == 3"-e napi:napi_poll-C 1-- sleep 2$ sudo perf script
?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
$ perf stat -C 1 -e irq:softirq_entry,irq:softirq_exit,irq:softirq_raise -a sleep 10Performance counter stats for 'system wide':1,161 irq:softirq_entry1,161 irq:softirq_exit1,215 irq:softirq_raise10.001100401 seconds time elapsed
?
/proc/net/softnetstat 各字段說明?
前面看到,如果 budget 或者 time limit 到了而仍有包需要處理,那 netrxaction 在退出 循環之前會更新統計信息。這個信息存儲在該 CPU 的 struct softnetdata 變量中。
這些統計信息打到了/proc/net/softnet_stat,但不幸的是,關于這個的文檔很少。每一 列代表什么并沒有標題,而且列的內容會隨著內核版本可能發生變化,所以應該以內核源碼為準, 下面是內核 5.10,可以看到每列分別對應什么:
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
- ?
// https://github.com/torvalds/linux/blob/v5.10/net/core/net-procfs.c#L172static int softnet_seq_show(struct seq_file *seq, void *v){...seq_printf(seq,"%08x %08x %08x %08x %08x %08x %08x %08x %08x %08x %08x %08x %08x ",sd->processed, sd->dropped, sd->time_squeeze, 0,0, 0, 0, 0, /* was fastroute */0, /* was cpu_collision */sd->received_rps, flow_limit_count,softnet_backlog_len(sd), (int)seq->index);}
- ?
- ?
- ?
- ?
- ?
- ?
- ?
cat /proc/net/softnet_stat6dcad223 00000000 00000001 00000000 00000000 00000000 00000000 00000000 00000000 000000006f0e1565 00000000 00000002 00000000 00000000 00000000 00000000 00000000 00000000 00000000660774ec 00000000 00000003 00000000 00000000 00000000 00000000 00000000 00000000 0000000061c99331 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 000000006794b1b3 00000000 00000005 00000000 00000000 00000000 00000000 00000000 00000000 000000006488cb92 00000000 00000001 00000000 00000000 00000000 00000000 00000000 00000000 00000000
每一行代表一個 struct softnet_data 變量。因為每個 CPU 只有一個該變量,所以每行其實代表一個 CPU;數字都是 16 進制表示。字段說明:
-
第一列 sd->processed:處理的網絡幀數量。如果用了 ethernet bonding,那這個值會大于總幀數, 因為 bond 驅動有時會觸發幀的重處理(re-processed);
-
第二列 sd->dropped:因為處理不過來而 drop 的網絡幀數量;具體見原理篇;
-
第三列 sd->timesqueeze:由于 budget 或 time limit 用完而退出 netrxaction() 循環的次數;原理篇中有更多分析;
-
接下來的 5 列全是 0;
-
第九列 sd->cpucollision:為發送包而獲取鎖時沖突的次數;
-
第十列 sd->receivedrps:當前 CPU 被其他 CPU 喚醒去收包的次數;
-
最后一列,flowlimitcount:達到 flow limit 的次數;這是 RPS 特性。
?
?
3.2 調整 softirq 收包預算:sysctl netdevbudget/netdevbudgetusecs
?
權威解釋見 內核文檔。
-
netdevbudget:一個 CPU 單次輪詢所允許的最大收包數量。單次 poll 收包時,所有注冊到這個 CPU 的 NAPI 變量收包數量之和不能大于這個閾值。
-
netdevbudget_usecs:每次 NAPI poll cycle 的最長允許時間,單位是 us。觸發二者中任何一個條件后,都會導致一次輪詢結束。
查看當前配置:
- ?
- ?
- ?
$ sudo sysctl -a | grep netdevbudgetnet.core.netdevbudget = 300 # kernel 5.10 默認值net.core.netdevbudgetusecs = 2000 # kernel 5.10 默認值
修改配置:
- ?
- ?
sudo sysctl -w net.core.netdevbudget=3000sudo sysctl -w net.core.netdevbudget_usecs = 10000
要保證重啟不丟失,需要將這個配置寫到 /etc/sysctl.conf。
?
4?softirq:從ring buffer收包送到協議棧
?
4.1 修改 GRO 配置(ethtool -k/-K)
查看 GRO 配置:
- ?
- ?
ethtool -k eth0 | grep generic-receive-offloadgeneric-receive-offload: on
修改 GRO 配置:
- ?
sudo ethtool -K eth0 gro on
注意:對于大部分驅動,修改 GRO 配置會涉及先 down 再 up 這個網卡,因此這個網卡上的連接都會中斷。
?
4.2 sysctl gronormalbatch
?
- ?
sysctl net.core.gronormalbatchnet.core.gronormalbatch = 8
?
4.3 RPS 調優使用 RPS 需要在內核做配置,而且需要一個掩碼(bitmask)指定哪些 CPU 可以處理那些 RX 隊列。相關信息見 內核文檔。bitmask 配置位于:/sys/class/net/DEVICENAME/queues/QUEUE/rpscpus。
例如,對于 eth0 的 queue 0,需要更改/sys/class/net/eth0/queues/rx-0/rps_cpus。
注意:打開 RPS 之后,原來不需要處理軟中斷(softirq)的 CPU 這時也會參與處理。因此相 應 CPU 的 NET_RX 數量,以及 si 或 sitime 占比都會相應增加。可以對比啟用 RPS 前后的 數據,以此來確定配置是否生效以及是否符合預期(哪個 CPU 處理哪個網卡的哪個中斷)。
4.4 調優:打開 RFS ?RPS 記錄一個全局的 hash table,包含所有 flow 的信息,這個 hash table 的大小是 net.core.rpssockflow_entries:?
- ?
- ?
- ?
- ?
sysctl -a | grep rps_net.core.rpssockflow_entries = 0 # kernel 5.10 默認值如果要修改sudo sysctl -w net.core.rpssockflowentries=32768
其次,可以設置每個 RX queue 的 flow 數量,對應著 rpsflow_cnt:
例如,eth0 的 RX queue0 的 flow 數量調整到 2048:
- ?
sudo bash -c 'echo 2048 > /sys/class/net/eth0/queues/rx-0/rpsflowcnt'
?
4.5 調優: 啟用 aRFS
?
假如網卡支持 aRFS,可以開啟它并做如下配置:
-
打開并配置 RPS
-
打開并配置 RFS
-
內核中編譯期間指定了 CONFIGRFSACCEL 選項
-
打開網卡的 ntuple 支持。可以用 ethtool 查看當前的 ntuple 設置
-
配置 IRQ(硬中斷)中每個 RX 和 CPU 的對應關系
以上配置完成后,aRFS 就會自動將 RX queue 數據移動到指定 CPU 的內存,每個 flow 的包都會 到達同一個 CPU,不需要再通過 ntuple 手動指定每個 flow 的配置了。
?
5 協議棧:L2處理
?
5.1 調優: 何時給包打時間戳(sysctl net.core.netdevtstampprequeue)
?
決定包被收到后,何時給它打時間戳。
- ?
- ?
$ sysctl net.core.netdevtstampprequeue1 # 內核 5.10 默認值
?
5.2 調優(老驅動)
?
netdevmaxbacklog如果啟用了 RPS,或者你的網卡驅動調用了 netifrx()(大部分網卡都不會再調用這個函數了), 那增加 netdevmaxbacklog 可以改善在 enqueueto_backlog 里的丟包:
- ?
sudo sysctl -w net.core.netdevmaxbacklog=3000
默認值是 1000。
NAPI weight of the backlog poll loopnet.core.devweight 決定了 backlog poll loop 可以消耗的整體 budget(參考前面更改 net.core.netdevbudget 的章節):
- ?
sudo sysctl -w net.core.dev_weight=600
默認值是 64。
記住,backlog 處理邏輯和設備驅動的 poll 函數類似,都是在軟中斷(softirq)的上下文 中執行,因此受整體 budget 和處理時間的限制。
5.3 調優:sysctl net.core.flowlimittablelen
?
- ?
sudo sysctl -w net.core.flowlimittablelen=8192
默認值是 4096。
這只會影響新分配的 flow hash table。所以,如果想增加 table size 的話,應該在打開 flow limit 功能之前設置這個值。
打開 flow limit 功能的方式是,在/proc/sys/net/core/flowlimitcpu_bitmap 中指定一 個 bitmask,和通過 bitmask 打開 RPS 的操作類似。
?
6 協議棧:L3處理(IPV4)
?
6.1 調優: 打開或關閉 IP 協議的 early demux 選項
?
查看 early_demux 配置:
- ?
- ?
$ sudo sysctl net.ipv4.ipearlydemux1 # 內核 5.10 默認值
默認是 1,即該功能默認是打開的。
添加這個 sysctl 開關的原因是,一些用戶報告說,在某些場景下 early_demux 優化會導 致 ~5% 左右的吞吐量下降。
?
7?協議棧:L4處理(UDP)
?
7.1 調優: socket receive buffer(sysctl net.core.rmemdefault/rmemmax)
?
判斷 socket 接收隊列是否滿了是和 sk->sk_rcvbuf 做比較。這個值可以通過 sysctl 配置:
- ?
- ?
- ?
- ?
- ?
$ sysctl -a | grep rmem # kernel 5.10 defaultsnet.core.rmemdefault = 212992 # ~200KBnet.core.rmemmax = 212992 # ~200KBnet.ipv4.tcprmem = 4096 131072 6291456net.ipv4.udprmem_min = 4096
默認的 200KB 可能太小了,例如 QUIC 可能需要 MB 級別的配置。
有兩種修改方式:
1.全局:sysctl 或 echo sysfs 方式2.應用程序級別:在應用程序里通過 setsockopt 帶上 SORCVBUF flag 來修改這個值 (sk->skrcvbuf),能設置的最大值不超過 net.core.rmemmax。如果有 CAPNETADMIN 權限,也可以 setsockopt 帶上 SORCVBUFFORCE 來覆蓋 net.core.rmem_max。
實際中比較靈活的方式:
1.rmemdefault 不動,這樣 UDP 應用默認將仍然使用系統預設值;
2.rmemmax 調大(例如 2.5MB),有需要的應用可以自己通過 setsockopt() 來調大自己的 buffer。
參考資料Linux 中斷(IRQ/softirq)基礎:原理及內核實現Linux 網絡棧接收數據(RX):原理及內核實現Monitoring Linux Network Stack
審核編輯:湯梓紅











 工商網監
工商網監
評論