 電子發燒友App
電子發燒友App


Python 是一種易于學習又功能強大的編程語言。它提供了高效的高級數據結構,還能簡單有效地面向對象編程。Python 優雅的語法和動態類型,以及解釋型語言的本質,使它成為多數平臺上寫腳本和快速開發應用的理想語言。
Python 解釋器及豐富的標準庫,提供了適用于各個主要系統平臺的源碼或機器碼,這些可以到 Python 官網:
?
https://www.python.org/
?
Python 解釋器易于擴展,可以使用 C 或 C++(或者其他可以從 C 調用的語言)擴展新的功能和數據類型。Python 也可用作可定制化軟件中的擴展程序語言。
簡單來說,易用,需要深入理解和記憶的東西不需要很多,其次庫多,可以讓編寫者集中精神研究邏輯。其次就是免費了,使用起來沒有什么成本。最后就是它真的很火,側面的好處就是別人遇到的問題早就被解決,生態良好。
我們經常說,Python一行勝千語:
是因為Python 是一種解釋型語言,在程序開發階段可以為你節省大量時間,因為不需要編譯和鏈接。解釋器可以交互式使用,這樣就可以方便地嘗試語言特性,寫一些一次性的程序,或者在自底向上的程序開發中測試功能。它也是一個順手的桌面計算器。
Python 程序的書寫是緊湊而易讀的。Python 代碼通常比同樣功能的 C,C++,Java 代碼要短很多,有如下幾個原因:
1.高級數據類型允許在一個表達式中表示復雜的操作;
2.代碼塊的劃分是按照縮進而不是成對的花括號;
3.不需要預先定義變量或參數。
也就是說,樣板代碼變少了,一些獨特的語法糖也讓編寫的效率更高。
Python可以以很多的形式被運行,一種是命令行終端,一種是腳本的樣子。
?
python -c command [arg] ...
?
其中 command 要換成想執行的指令,就像命令行的?-c 選項。由于 Python 代碼中經常會包含對終端來說比較特殊的字符,通常情況下都建議用英文單引號把 command 括起來。
有些 Python 模塊也可以作為腳本使用。可以這樣輸入:
?
python -m module [arg] ...
?
這會執行 module 的源文件,就跟你在命令行把路徑寫全了一樣。
在運行腳本的時候,有時可能也會需要在運行后進入交互模式。這種時候在文件參數前,加上選項?-i 就可以了。
如果可能的話,解釋器會讀取命令行參數,轉化為字符串列表存入 sys 模塊中的 argv 變量中。執行命令:
?
import sys
?
你可以導入這個模塊并訪問這個列表。這個列表最少也會有一個元素;如果沒有給定輸入參數,sys.argv[0] 就是個空字符串。如果給定的腳本名是 '-' (表示標準輸入),sys.argv[0] 就是 '-'。使用 -c command 時,sys.argv[0] 就會是 '-c'。如果使用選項 -m module,sys.argv[0] 就是包含目錄的模塊全名。在 -c command 或 -m module 之后的選項不會被解釋器處理,而會直接留在 sys.argv 中給命令或模塊來處理。
有些東西不得不說,因為它時時刻刻存在,所以請原諒我的啰嗦。
最后講一下編碼信息,你看到的程序其實和你看到的小說沒有什么區別,都是一堆0101010,但是為啥0101010就變成了你看到的字符,其實是因為編碼的緣故。
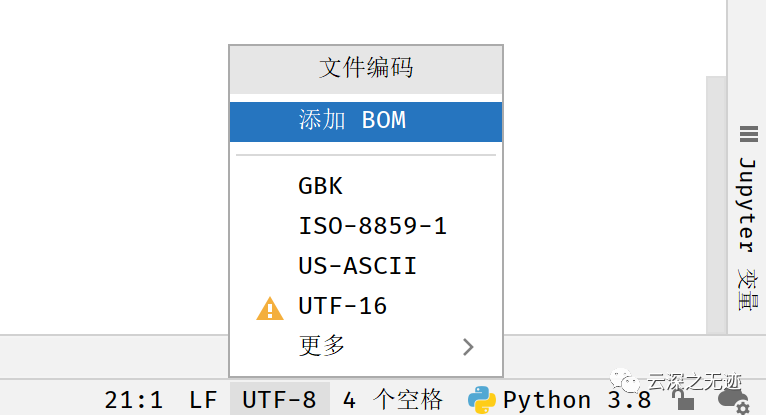
在編輯器的右下角,大概率都會看到這個
默認情況下,Python 源碼文件以 UTF-8 編碼方式處理。在這種編碼方式中,世界上大多數語言的字符都可以同時用于字符串字面值、變量或函數名稱以及注釋中——盡管標準庫中只用常規的 ASCII 字符作為變量或函數名,而且任何可移植的代碼都應該遵守此約定。要正確顯示這些字符,你的編輯器必須能識別 UTF-8 編碼,而且必須使用能支持打開的文件中所有字符的字體。
如果不使用默認編碼,要聲明文件所使用的編碼,文件的 第一 行要寫成特殊的注釋。語法如下所示:
?
# -*- coding: encoding -*-
?
其中 encoding 可以是 Python 支持的任意一種 codecs。
比如,要聲明使用 Windows-1252 編碼,你的源碼文件要寫成:
?
# -*- coding: cp1252 -*-
?
關于 第一行 規則的一種例外情況是,源碼以 UNIX "shebang" 行 開頭。這種情況下,編碼聲明就要寫在文件的第二行。例如:
?
#!/usr/bin/env python3# -*- coding: cp1252 -*-
?
這可能會回答,為什么代碼一開始會有一行奇怪的東西。
本來是想直接給大家寫一些教程的,但是官網寫的真的太好啦!
?
https://docs.python.org/zh-cn/3.8/tutorial/introduction.html
?
大家直接去看。
字符串是可以被 索引 (下標訪問)的,第一個字符索引是 0。單個字符并沒有特殊的類型,只是一個長度為一的字符串:
?
>>>>>> word = 'Python'>>> word[0] # character in position 0'P'>>> word[5] # character in position 5'n'
?
索引也可以用負數,這種會從右邊開始數:
?
>>>>>> word[-1] # last character'n'>>> word[-2] # second-last character'o'>>> word[-6]'P'
?
注意 -0 和 0 是一樣的,所以負數索引從 -1 開始。
除了索引,字符串還支持 切片。索引可以得到單個字符,而 切片 可以獲取子字符串:
?
>>>>>> word[0:2] # characters from position 0 (included) to 2 (excluded)'Py'>>> word[2:5] # characters from position 2 (included) to 5 (excluded)'tho'
?
注意切片的開始總是被包括在結果中,而結束不被包括。這使得 s[:i] + s[i:] 總是等于 s
?
>>>>>> word[:2] + word[2:]'Python'>>> word[:4] + word[4:]'Python'
?
切片的索引有默認值;省略開始索引時默認為0,省略結束索引時默認為到字符串的結束:
?
>>>>>> word[:2] # character from the beginning to position 2 (excluded)'Py'>>> word[4:] # characters from position 4 (included) to the end'on'>>> word[-2:] # characters from the second-last (included) to the end'on'
?
您也可以這么理解切片:將索引視作指向字符 之間 ,第一個字符的左側標為0,最后一個字符的右側標為 n ,其中 n 是字符串長度。例如:
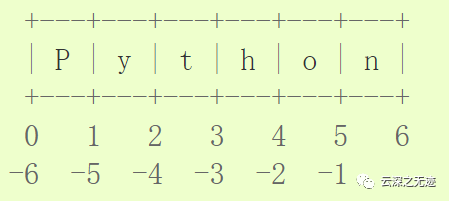
第一行數標注了字符串 0...6 的索引的位置,第二行標注了對應的負的索引。那么從 i 到 j 的切片就包括了標有 i 和 j 的位置之間的所有字符。
對于使用非負索引的切片,如果索引不越界,那么得到的切片長度就是起止索引之差。例如, word[1:3] 的長度為2。
試圖使用過大的索引會產生一個錯誤:
?
>>>>>> word[42] # the word only has 6 charactersTraceback (most recent call last): File "", line 1, inIndexError: string index out of range
?
但是,切片中的越界索引會被自動處理:
?
>>>>>> word[4:42]'on'>>> word[42:]''
?
Python 中的字符串不能被修改,它們是 immutable 的。因此,向字符串的某個索引位置賦值會產生一個錯誤:
?
>>>>>> word[0] = 'J'Traceback (most recent call last): File "", line 1, inTypeError: 'str' object does not support item assignment>>> word[2:] = 'py'Traceback (most recent call last): File "", line 1, inTypeError: 'str' object does not support item assignment
?
如果需要一個不同的字符串,應當新建一個:
?
>>>>>> 'J' + word[1:]'Jython'>>> word[:2] + 'py''Pypy'
?
記不住?string就是個不可變的列表,完事兒了。
老師!等下!
?
什么是列表啊?
Python 中可以通過組合一些值得到多種復合數據類型。其中最常用的列表 ,可以通過方括號括起、逗號分隔的一組值(元素)得到。一個 列表 可以包含不同類型的元素,但通常使用時各個元素類型相同:

粗糙點的話,這就介紹完了
但是為了完整性,這里要補一些,Python 編程語言中有四種集合數據類型:
列表(List)是一種有序和可更改的集合。允許重復的成員。
元組(Tuple)是一種有序且不可更改的集合。允許重復的成員。
集合(Set)是一個無序和無索引的集合。沒有重復的成員。
詞典(Dictionary)是一個無序,可變和有索引的集合。沒有重復的成員。
選擇集合類型時,了解該類型的屬性很有用。為特定數據集選擇正確的類型可能意味著保留含義,并且可能意味著提高效率或安全性。
上面的都可以叫數據容器,也就是放東西的罐子。我們要對它動手動腳的,也就是要操作它。無外乎2種操作:取一些(看看里面有啥),改一些(比如調整順序,刪除)。
再總結一下,就是你做完操作,有沒有對這個原來的東西有副作用的。這樣的抽象模型是理解對數據操作的必由之路。
?
按說看懂了吧?
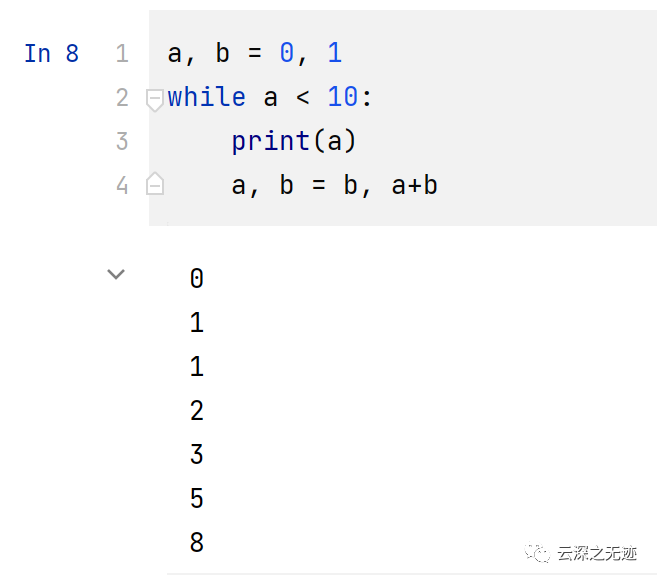
我假定你有其它語言的經驗,這里就直接開始了
我們來想想,上面的代碼做了什么?初始化要使用的變量,開始操作變量,在一個合適的時機輸出結果。
第一行含有一個多重賦值: 變量 a 和 b 同時得到了新值 0 和 1. 最后一行又用了一次多重賦值, 這展示出了右手邊的表達式,在任何賦值發生之前就被求值了。右手邊的表達式是從左到右被求值的。
while 循環只要它的條件(這里指:a < 10)保持為真就會一直執行。Python 和 C 一樣,任何非零整數都為真;零為假。這個條件也可以是字符串或是列表的值,事實上任何序列都可以;長度非零就為真,空序列就為假。在這個例子里,判斷條件是一個簡單的比較。
標準的比較操作符的寫法和 C 語言里是一樣:< (小于)、 > (大于)、 == (等于)、 <= (小于或等于)、 >= (大于或等于)以及 != (不等于)。
循環體是縮進的 :縮進是 Python 組織語句的方式。在交互式命令行里,你得給每個縮進的行敲下 Tab 鍵或者(多個)空格鍵。實際上用文本編輯器的話,你要準備更復雜的輸入方式;所有像樣的文本編輯器都有自動縮進的設置。交互式命令行里,當一個組合的語句輸入時, 需要在最后敲一個空白行表示完成(因為語法分析器猜不出來你什么時候打的是最后一行)。注意,在同一塊語句中的每一行,都要縮進相同的長度。
print() 函數將所有傳進來的參數值打印出來. 它和直接輸入你要顯示的表達式(比如我們之前在計算器的例子里做的)不一樣, print() 能處理多個參數,包括浮點數,字符串。字符串會打印不帶引號的內容, 并且在參數項之間會插入一個空格, 這樣你就可以很好的把東西格式化。
縮進這個事情,其實Python的創始人說,沒有那么夸張,只是必要的縮進會對閱讀代碼有益,現在看到是比較糟糕的設計,最好還是使用括號來匹配。

end參數可以取消輸出
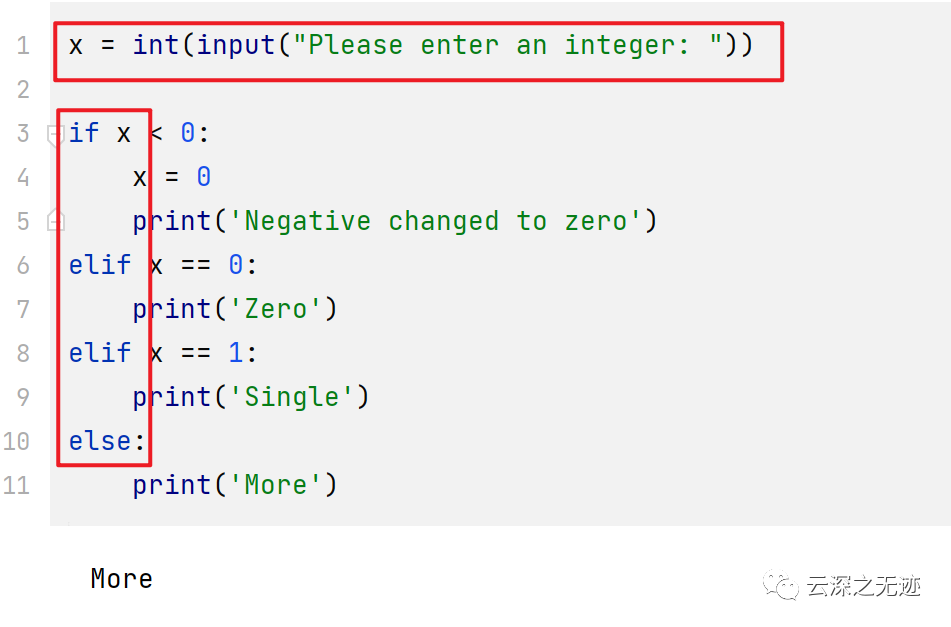
再看看分支結構,分支結構是賦予計算機判斷能力的本源動力
可以有零個或多個 elif 部分,以及一個可選的 else 部分。關鍵字 'elif' 是 'else if' 的縮寫,適合用于避免過多的縮進。一個 if ... elif ... elif ... 序列可以看作是其他語言中的 switch 或 case 語句的替代。再最新的3.10版本已經有了switch語句,但是太新的特性了,不建議使用。
Python 中的 for 語句與你在 C 或 Pascal 中所用到的有所不同。Python 中的 for 語句并不總是對算術遞增的數值進行迭代(如同 Pascal),或是給予用戶定義迭代步驟和暫停條件的能力(如同 C),而是對任意序列進行迭代(例如列表或字符串),條目的迭代順序與它們在序列中出現的順序一致。?
?
words = ['cat', 'window', 'defenestrate']for w in words: print(w, len(w))
?
在遍歷同一個集合時修改該集合的代碼可能很難獲得正確的結果。通常,更直接的做法是循環遍歷該集合的副本或創建新集合:
?
for user, status in users.copy().items(): if status == 'inactive': del users[user]
# Strategy: Create a new collectionactive_users = {}for user, status in users.items(): if status == 'active': active_users[user] = status
?
for 語句用于對序列(例如字符串、元組或列表)或其他可迭代對象中的元素進行迭代:
?
for_stmt ::= "for" target_list "in" expression_list ":" suite ["else" ":" suite]
?
表達式列表會被求值一次;它應該產生一個可迭代對象。系統將為 expression_list 的結果創建一個迭代器,然后將為迭代器所提供的每一項執行一次子句體,具體次序與迭代器的返回順序一致。每一項會按標準賦值規則 (參見 賦值語句) 被依次賦值給目標列表,然后子句體將被執行。當所有項被耗盡時 (這會在序列為空或迭代器引發 StopIteration 異常時立刻發生),else 子句的子句體如果存在將會被執行,并終止循環。
第一個子句體中的 break 語句在執行時將終止循環且不執行 else 子句體。第一個子句體中的 continue 語句在執行時將跳過子句體中的剩余部分并轉往下一項繼續執行,或者在沒有下一項時轉往 else 子句執行。
for 循環會對目標列表中的變量進行賦值。這將覆蓋之前對這些變量的所有賦值,包括在 for 循環體中的賦值:
?
for i in range(10): print(i) i = 5
?
目標列表中的名稱在循環結束時不會被刪除,但如果序列為空,則它們根本不會被循環所賦值。提示:內置函數 range() 會返回一個可迭代的整數序列,適用于模擬 Pascal 中的:
?
for i := a to b do
?
這種效果;例如 list(range(3)) 會返回列表 [0, 1, 2]。
當序列在循環中被修改時會有一個微妙的問題(這只可能發生于可變序列例如列表中)。會有一個內部計數器被用來跟蹤下一個要使用的項,每次迭代都會使計數器遞增。當計數器值達到序列長度時循環就會終止。這意味著如果語句體從序列中刪除了當前(或之前)的一項,下一項就會被跳過(因為其標號將變成已被處理的當前項的標號)。類似地,如果語句體在序列當前項的前面插入一個新項,當前項會在循環的下一輪中再次被處理。這會導致麻煩的程序錯誤,避免此問題的辦法是對整個序列使用切片來創建一個臨時副本:
?
for x in a[:]: if x < 0: a.remove(x)
?
一般重復語句主要有兩種類型的循環:
1)重復一定次數的循環,這個稱謂計數循環。
比如打印1到99之間所有的整數,就是重復99次執行print( )指令。
2)重復直至發生某種情況時結束的循環,成為條件循環。也就是說只有條件為True,循環才會一直持續下去。
比如猜數字,如果沒猜中就繼續猜,如果猜中了就退出。
循環的知識太多了,其實就是簡簡單單的重復,但是最難的就是什么時候停下來再做別的事情。
在C語言里面的循環大多數是小于一個什么數字,也就是變相的輸出了一些算數級數,在Python里面有著更加優雅的寫法。
?
for i in range(5): print(i)
?
給定的終止數值并不在要生成的序列里;range(10) 會生成10個值,并且是以合法的索引生成一個長度為10的序列。range也可以以另一個數字開頭,或者以指定的幅度增加(甚至是負數;有時這也被叫做 '步進')
但是更加的常見一種用法是:
?
a = ['Mary', 'had', 'a', 'little', 'lamb']for i in range(len(a)): print(i, a[i])
?
我相信你一定會看到這個寫法。
當然Python里面還有別的寫法:

函數返回一個枚舉對象。iterable 必須是一個序列,或 iterator,或其他支持迭代的對象。enumerate() 返回的迭代器的 __next__() 方法返回一個元組,里面包含一個計數值(從 start 開始,默認為 0)和通過迭代 iterable 獲得的值。

當然我們這樣也可以實現,但是有現成的干嘛不用
range()?所返回的對象在許多方面表現得像一個列表,但實際上卻并不是。此對象會在你迭代它時基于所希望的序列返回連續的項,但它沒有真正生成列表,這樣就能節省空間。
我們稱這樣對象為?iterable,也就是說,適合作為這樣的目標對象:函數和結構期望從中獲取連續的項直到所提供的項全部耗盡。我們已經看到?for?語句就是這樣一種結構。
關于迭代器就不說了,它就是一種協議而已。












 工商網監
工商網監
評論