 電子發燒友App
電子發燒友App


作為一個硬實時操作系統,QNX是一個基于優先級搶占的系統。這也導致其基本調度算法相對比較簡單。因為不需要像別的通用操作系統考慮一些復雜的“公平性”,只需要保證“優先級最高的線程最優先得到 CPU”就可以了。
基本調度算法
調度算法,是基于優先級的。QNX的線程優先級,是一個0-255的數字,數字越大優先級越高。所以,優先級0是內核中的idle線程。同時,優先級64是一個分界嶺。就是說,優先級1 – 63 是非特權優先級,一般用戶都可以用,而64 – 255必須是有root權限的線程才以設。這個“優先級64”分界線,如果有必要,還可以通過啟動Procnto時傳 –P
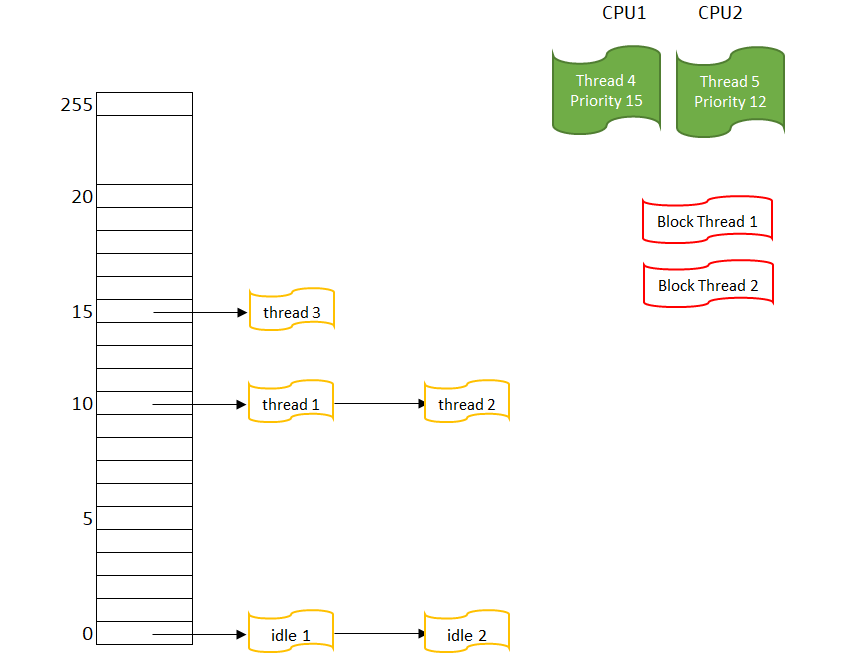
圖 1 有兩個CPU的系統里的線程 這是一個有兩個CPU的系統,所以可以看到有兩個RUNNING線程;對于 BLOCK THREAD,它們不參于調度,所以不需要考慮它們的優先級。
調度策略
在QNX上實質上只有三種基本調度策略,“輪詢”(Round Robin),“先進先出”(First in first out)和"零星調度”(Sporadic) 算法。雖然形式上還有一個“其他”,但“其他”跟“輪詢”是一樣的。這些調度策略,在 /usr/include/sched.h 里有定義。(SCHED_FIFO, SCHED_RR, SCHED_SPORADIC, SCHED_OTHER) 強調一下,調度策略只限于在READY隊列里的線程,優線級最高的線程有不止一個時,才會用到。如果線程不再 READY,或是有別的更高優先級的線程 READY了,那就高優先級線程獲取CPU,沒有什么策略可言。 “輪詢調度”(Round Robin)跟平時生活里排隊的情形差不多,晚到的人排在隊尾,早到的人排在隊首,等到叫號(調度)的時候,隊首的人會被先叫到 。如下圖所示:
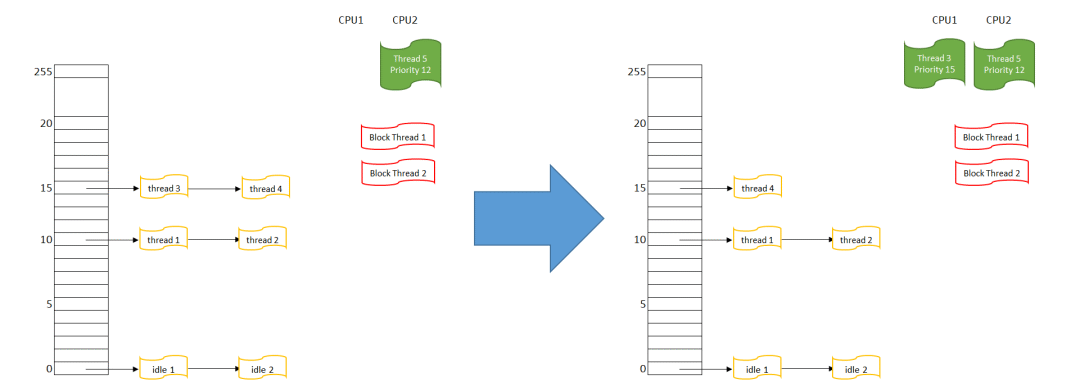
圖 2 論詢調度示意
首先在CPU 1上運行的線程4,被挪入優先級15的隊列末尾
然后重新搜索可執行的最高優先級線程,這里有優先級15隊列上的線程3和4
線程3因為在隊列最前端,它被選擇得到CPU,線程3的狀態變為RUNNING,在CPU1上執行
可以預期,當下一次調度發生時,線程3會被挪入優先級15隊列末尾,而線程4會被調度執行,這樣線程3和4會分別得到CPU1. “先進先出”(First in first out)調度則剛好相反,后來的人插在隊首,然后在叫號的時候被先叫到。看下圖: ?
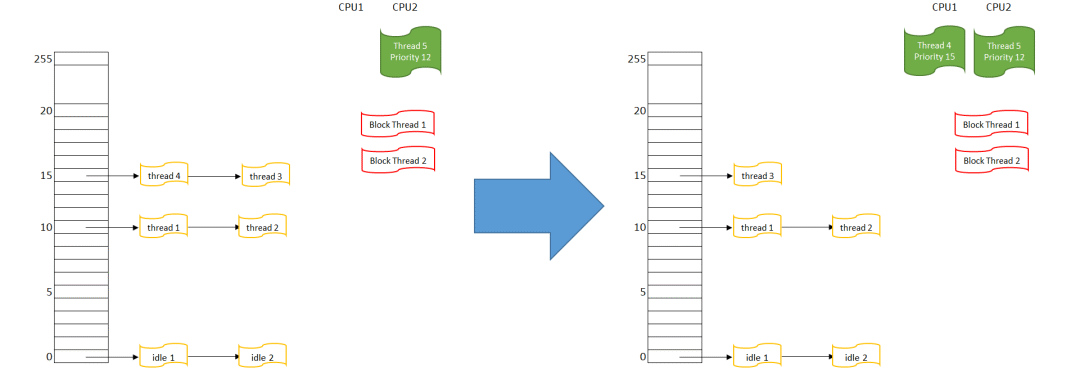
圖 3 先進先出調度示意
首先在CPU 1上運行的線程4,被挪入優先級15的隊列隊首
然后重新搜索可執行的最高優先級線程,這里有優先級15隊列上的線程4和3
線程4因為在隊列最前端,它被選擇得到CPU,線程4的狀態變為RUNNING,在CPU1上執行
可以看到,在這個調度算法下,如果沒有別的狀態發生,事實上線程4就會一直占據CPU1。 如果在優先級15上的線程3和線程4都是FIFO會怎樣?按上面的描述,線程3還是始終無法獲得CPU1,因為線程4每次都會插在3的前面,再調度就又是4獲得CPU1。除非線層4進入了阻塞狀態(從而不在READY隊列里了),那么線程3才能獲得CPU。 “零星調度”(Sporadic)算法比較特殊,它比較適合長時間占用CPU的線程。它的基本設計思想是給一個線程準備兩個優先級,“前臺”優先級比較高,“后臺”優先級稍微底一點。如果線程在高優先級連續占用CPU超過一定時間后,線程會被強行降到“后臺”低優先級上(這時線程能不能占用CPU取決于系統中有沒有比“后臺”優先級高的別的線程了);然后線程在低優先級上經過了一段時間后,會重新被調回高優先級。
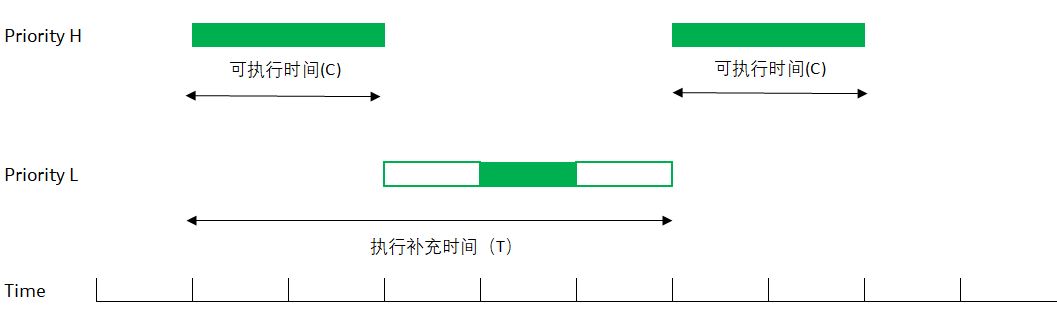
圖 4 零星調度示意 上圖是一個零星調度線程的示意。
開始的時候,線程在比較高的(正常)優先級 H 上運行,一直到把預先分配給零星調度的時間用完(sched_ss_init_budget)
這時,線程會被自動調整為低優先級L(sched_ss_low_priority);一旦被調低,線程也可能運行(如果優先級L依然是系統里最高優先級的線程),也可能無法運行呆在READY隊列里(系統里有比L更高的優先級)
不管線程有沒有執行,從最開始運行時間點算起,當線程“執行補充時間"(sched_ss_repl_period)過了以后,線程的優先級被重新提到優先級H,并試圖取得CPU來。
“零星調度”看上去比較“公平”,但是實際在用QNX的項目中,這個調度算法很少被用戶用到。主要是因為一般來說在QNX上很少有線程能夠“連續占用CPU”的。而且當系統變得復雜,線程數成百上千后,這種上下調優先級的做法,很容易出現別的后遺癥。
什么時候會發生調度?
上面介紹了QNX支持的幾個調度算法。那么,什么時候才會發生調度呢? QNX的設計目標是一個硬實時操作系統,所以,保證最高優先級的線程在第一時間占據CPU是很重要的。考慮到線程的狀態都是在內核中進行變化的(都是因為線程進行了某個內核調用后變化的),所以QNX在每次從內核調用退出時,都會進行一次線程調度,以保證最高優先級的線程可以占據CPU。 得益于微內核結構,QNX的內核調用通常都非常短,或者說,每一個內核調用,都能夠比較確定地知道要花多少時間。而且,因為微內核系統的基本就是進程間通信,所以在QNX上,一段程序非常容易進入內核并進行線程狀態切換,很少能有長時間占滿CPU的,在實際系統上測,現實上很少能有線程執行完整個時間片的。 舉個例子,哪怕程序里只寫一個 printf("Hello World! "); 可是在libc庫里,最后這個會變成一個IO_WRITE消息,MsgSend() 給控制臺驅動;這時,在MsgSend()這個內核調用里,會把printf() 的線程置為阻塞狀態(REPLY BLOCK),同時會把控制臺驅動的信息接收線程(從RECEIVE BLOCK)改到 READY狀態,并放入 READY 隊列。當退出MsgSend() 內核調用時,線程調度發生,通常情況下(如果沒有別的線程READY 的話)控制臺驅動的信息接收線程被激活,并占據CPU. 如果用戶寫了一個既不內核調用,也不放棄CPU的線程會怎么樣?那時候,時鐘中斷會發生,當內核記時到線程占據了一整個時間片(QNX上是4ms)后,內核會強制當前線程進入 READY,并重新調度。如果同一優先級只有這一個線程(這是優先級最高線程),那么調度后,還是這個線程獲取CPU。如果同一優先級有別的線程存在,那么根據調度算法來決定哪個線程獲得CPU。 另一種常見情況是,由于某些別的原因導致高優先級線程被激活,比如網卡驅動中斷導致高優先級驅動線程READY,所設時鐘到達導致高優先級線程從阻塞狀態返回READY狀態了,當前線程開放互斥鎖之類的線程同步對象,導致別的線程返回READY狀態了。這些,都會在從內核調用退出時,進行調度。
中斷與優先級
上面提到如果用戶線程長期占有CPU,時鐘中斷會打斷用戶線程。細心的讀者或許會有疑問,那中斷的優先級是多少呢? 答案是在QNX這樣的實時操作系統里,“硬件中斷”永遠高于任何線程優先級,哪怕你的線程優先級到了255,只要有中斷發生,都要讓路,CPU會跳轉去執行中斷處理程序,執行完了再回歸用戶線程。事實上,能夠快速穩定地響應中斷處理,是一個實時操作系統的硬指標。 我們這里說的是“硬件中斷”,就是說,當外部設備,通過中斷控制器,向CPU發出中斷請求時,無論當時CPU上執行的線程優先級是什么,都會先跳轉到內核的中斷處理程序;中斷處理程序會去中斷控制器找到具體是哪一個源發生了中斷(中斷號),并據此,跳轉到該中斷號的中斷處理程序(通常是硬件驅動程序 通過 InterruptAttach() 掛接的函數)。在這個過程中,如果當前CPU正在處理另一個中斷,那么這時,會根據中斷的優先級來決定是讓CPU繼續處理下去(當前中斷進入等待);或者發生中斷搶占,新中斷的優先級比舊中斷高,所以跳轉新中斷處理。 當然,實際應用中,特別是微內核環境下,考慮中斷其實只是中斷設備給出的一個通知,對這中斷的響應并不需要真的在中斷處理中進行,驅動程序可以選擇在普通線程中處理,QNX上有InterruptAttachEvent() 就是為了這個設計的。通常這里的“事件”會是一個“脈沖”,也就是說,當硬件中斷發生,內核檢查到相應中斷綁定了事件。這時,不會跳轉到用戶中斷處理程序,而是直接發出那個脈沖,以激活一個外部(驅動器中)線程,在這線程中,做設備中斷所需要的處理。這樣做,雖然稍微增加了一些中斷延遲,但也帶來了不少好處。首先,這個外部線程同普通的用戶線程一樣,所以可以調用任何庫函數,而中斷服務程序因為執行環境的不同,有好多限制。其次,因為是普通用戶線程,就可以用線程調度的方法規定其優先級(脈沖事件是帶優先級的),使不同的設備中斷處理,跟正常業務邏輯更好地一起使用。
多CPU上的線程調度
現在同步多處理器(SMP)已經相當普及了。在SMP上,也就是說當有多個CPU時,我們的調度算法有什么變化呢?比如一個有2個CPU的系統,首先肯定,系統上可執行線程中的最高優先級線程,一定在2個CPU上的某一個上執行;那,是不是第二高優先級的線程就在另一個CPU上執行呢? 雖然直覺上我們覺得應該是這樣的(系統里的第一,第二高優先級的線程占據CPU1和CPU2),但事實上,第二高優先級的線程占據CPU2這件事,并不是必要的。實時搶占系統的要求是最高優先級”必須“能夠搶占CPU,但對第二高優先級并沒有規定。拿我們最開始的雙CPU圖再看一眼。
圖 5 有兩個CPU的系統里的線程 線程4以優先級15占據CPU1這是毫無疑問的,但線程5只有優先級12,為什么它可以占據CPU2,而線程3明明也有優先級15,但只能排隊等候,這是不是優先級倒置了?其實并沒有,如上所述,系統確實保證了“最高優先級占據CPU”的要求,但在CPU2上執行什么線程,除了線程本身的優先級以外,還有一些別的因素可以權衡,其中一個在SMP上比較重要的,就是“線程躍遷”。 “線程躍遷”指的是一個線程,一會兒在CPU1上執行,一會兒在CPU2上執行。在SMP系統上,線程躍遷而導致的緩存清除與重置,會給系統性能帶來很大的影響。所以在線程調度時,盡量把線程調度到上次執行時用的CPU,是SMP調度算法里比較重要的一環。上述例子中,很有可能就是線程3上一次是在CPU1上執行的,而線程5雖然優先級比較低,很有可能上一次就是在CPU2上執行的。 實際應用中,因為QNX的易于阻塞的特性,其實大多數情況下,還是符合“第一,第二高優先級線程在CPU上執行”的。只是,如果你觀察到了上述情形,也不需要擔心,設計上確實有可能不是第二高優先級的線程在運行。 另一個多處理器上常見的應用,是線程綁定。在正常情況下,把可執行線程調度到哪一個CPU上,是由操作系統完成的。當然操作系統會考慮“線程躍遷”等情形來做決定。但是,QNX的用戶也可以把線程綁定到某一個(或者某幾個)CPU上,這樣操作系統在調度時,會考慮用戶的要求來進行。綁定是通過ThreadCtl() 修改線程的 “RUNMASK” 來進行的,如果你有0,1,2,3 總共4個CPU,那么 0x00000003意味著線程可以在CPU0和CPU1上執行,具體例子可以參考ThreadCtl()函數說明。更簡單的辦法,是通過QNX特有的 on 命令的 –C 參數來指定,這個指定的 runmask,還會自動繼承。所以你可以簡單的如下執行: # on –C 0x00000003 Navigation &
# on –C 0x00000004 Media &
# on –C 0x00000008 System & 這樣來把不同的系統部署到不同的CPU上。 這樣做的好處當然是可以減少比如因為系統繁忙而對導航帶來的影響,但不要忘了,另一面,如果所有 Media 線程都處于阻塞狀態,上述綁定也限制了導航線程使用CPU2的可能,CPU2這時候就會空轉(執行內核 idle 線程)。
自適應分區調度算法
前面我們提到過,在討論優先級調度時,只是討論當有多個優先級相同的線程時,系統怎樣取舍。優先級不一樣時,肯定是優先級高的贏。但是“高出多少”并不是一個考量因素。兩個線程,一個優先級10,另一個優先級11的情況,和一個10,另一個40的情況是一樣的。并不會因為10和40差距比較大而有什么不同。 假如我們有紅藍兩個線程,它們的優先級一樣,調度策略是RR,兩個線程都不阻塞,那么在10時間片的區間里,我們看到的就是這樣一個執行結果:  也就是說,各占了50%的CPU。但只要把藍色線程提高哪怕1,執行結果就成了下面這樣。
也就是說,各占了50%的CPU。但只要把藍色線程提高哪怕1,執行結果就成了下面這樣。  這種“非黑即白”的情形,是實時系統的基本要求(高優先級搶占CPU)。但是當然,現實情況有時候比較復雜。比如 “HMI渲染” 是需要經常占據CPU的一個任務(這樣畫面才會順暢),但“用戶輸入”也是需要響應比較快的(不然用戶的點擊就會沒有反應)。如果“用戶輸入”的優先級太高的話,那用戶拖拽時,畫面就會卡頓甚至沒有反應?反之,如果”HMI 渲染“的優先級太高,那么有用戶輸入時,因為處理程序優先級低而造成用戶輸入反應慢。通常情況下,需要有經驗的系統工程師不斷調整這兩個任務的優先級(因為優先級繼承與傳統,一個任務可能涉及到多個線程),來達到系統的最優。那么,有沒有別的辦法呢?
這種“非黑即白”的情形,是實時系統的基本要求(高優先級搶占CPU)。但是當然,現實情況有時候比較復雜。比如 “HMI渲染” 是需要經常占據CPU的一個任務(這樣畫面才會順暢),但“用戶輸入”也是需要響應比較快的(不然用戶的點擊就會沒有反應)。如果“用戶輸入”的優先級太高的話,那用戶拖拽時,畫面就會卡頓甚至沒有反應?反之,如果”HMI 渲染“的優先級太高,那么有用戶輸入時,因為處理程序優先級低而造成用戶輸入反應慢。通常情況下,需要有經驗的系統工程師不斷調整這兩個任務的優先級(因為優先級繼承與傳統,一個任務可能涉及到多個線程),來達到系統的最優。那么,有沒有別的辦法呢?
分區調度
傳統上,有一種“分區調度”的方法,今天還有一些Hypervisor采取這個辦法。這個想法很簡單,就是把CPU算力隔成幾個分區,比如70%,30%這樣,然后把不同線程分到這些分區里,當分區里的CPU預算被用完以后,那個分區里所有可執行線程都會被”停住“,直到預算恢復。 假設我們把紅線程放入70%紅色分區,藍線程放入30%藍色分區,然后以10個時間片為預算滑動窗口大小,各線程具體就會如下圖占據CPU:

圖 6 分區調度算力全滿示意 在前6個時間片中,藍紅分區分別占據CPU,注意在第7個時間片時,雖然藍分區中線程跟紅分區中線程有相同的優先級,雖然調度策略是輪回,應該輪到藍線程上了,但是因為藍線程已經用完了10個時間片里的3個,所以系統沒有執行藍線程,而是繼續讓紅線程占據CPU,一直到第8第9和第10個時間片結束。 10個時間片結束后,窗口向右滑動,這時我們等于又多了一個時間片的預算,在新的10個時間片中,藍線程只占了兩個(20%),這樣,新的第11個時間片,就分給了藍分區。 同理再滑動后,第12個時間片,分給紅線程;一直到17個時間片時,同樣的事情再度發生,藍分區線程又用完了10個時間片里的3個,而被迫等待它的預算重新補充進來。 綜上,在任意一個滑動窗口中,藍色分區總是只占30%,而紅色分區卻占了70%。QNX的自適應分區調度,跟上面這個是類似的。只是傳統的分區調度,有一個明顯的弱點。 想一下這個情況,如果紅線程因為某些情況被阻塞了,會發生什么呢?

圖 7 分區調度算力有富余示意 對,藍線程是唯一可執行線程,所以它一直占據CPU。但是,當3個時間片輪轉之后,因為藍分區只有30%的時間預算,它將不再占據CPU,而因為紅線程無法執行,接下來的7個時間片CPU處于空轉狀態(執行Idle線程)。 一直到時間窗口移動,那時,因為藍分區只占用了20%的算力,所以它再次占據CPU…… 所以你也看到了,在傳統的分區調度里,當一個分區的算力有富裕的時候,CPU就被浪費了。
自適應分區調度
QNX在傳統的分區調度上,增加了“自適應”的部份。其基本思想是一樣的,給算力加分區,然后把不同的線程分到分區里。這樣,當所有的線程都忙起來時,你會發現情況跟圖7是一樣的。但是當分區算力有富裕時,“自適應“允許把多出來的算力”借“給需要更多算力的分區。

圖 8 自適就分區算力有富裕示意 如上,當藍色分區里的線程消耗完了他自己的分區預算后,自適應分區會把有富裕算力的紅色分區的預算,借給藍色分區,藍分區內線程得以繼續在CPU上運行。注意,在第8個時間片時,紅色分區需要使用CPU,藍色分區立即讓路,把CPU讓給紅色分區。而當紅色分區里的線程被阻塞住以后,藍色分區線程繼續使用CPU。 自適應分區似乎確實帶來了好處,但是也帶來了一些潛在的問題,需要在系統設計的時候做好決定。
自適應分區調度與線程優先級
你可能會好奇,在分區調度的系統里,線程的優先級代表了什么? 答案取決于各個分區對各自算力的消耗情況。我們假設藍色分區里的線程優先級比較高,紅色的優先級比較低,當兩個分區都有預算時,內核會調度(所有分區里的)最高優先級線程執行。如果系統一直不是很忙,那么不論分區,永遠是有最高優先級的線程得到CPU,這個,跟一個標準的實時操作系統是一致的。 當兩個分區中某一個有預算時(意味著那個分區中所有的線程都不在執行狀態),那么多出來的CPU算力會被分給另一個分區,另一個分區中的最高優先級線程(雖然用完了自己分區的預算,但得到了別的分區的算力),繼續占據CPU。這個,也是跟實時操作系統是一致的。 比較特殊的情況是,當兩個分區都沒有預算,都需要占據CPU時,這時,藍色線程雖然有較高的優先級,但因為分區算力(30%)被用完,面且沒有別的算力可以“借”,所以它被留在READY隊列中,而比它優先級低的紅色線程得以占據CPU。
自適應分區調度富裕算力分配
我們上面的例子只有兩個分區,考慮這樣一個例子。假設我們現在有A (70%),B (20%),C (10%) 三個分區,A分區沒有可執行線程,B分區有個優先級為10的線程,C分區有個優先級為20的線程。我們知道A分區的70%會分配給B和C,但具體是怎么分配的呢? 如上所述,當預算有富裕時,系統挑選所有分區中,優先級最高的線程執行,也就是說C分區中的線程得到運行。在一個窗口以后,你會發現A的CPU使用率是0%,B是20%,C則達到了80%。也就是說A所有的富裕算力,都給了C分區(因為C中的線程優先級高)。 也許,在某些時候,這個不是你所期望的。也許C中有一些第三方程序你無法控制,你也不希望他們偷偷提高優先級而占用全部富裕算力。QNX提供了SchedCtl()函數,可以設SCHED_APS_FREETIME_BY_RATIO 標志。設了這個標志后,富裕算力會按照各分區的預算比例分配給各分區。上面的例子下,最后的CPU使用率會變成 A 是0%, B是65%,而C是35%。A分區富裕的70%算力,按照大約 2: 1的比例,分給了分區B和C。
“關鍵線程”與“關鍵分區”
在實際使用中,有一些重要任務,可能需要響應,不論其所在的分區還有沒有算力。比如一個緊急中斷服務線程,不管分區是不是還有預算,都需要響應。為了解決這種情況,在QNX的自適應分區調度里,除了給分區分配算力預算以外,還允許有權限的用戶為分區分配“關鍵響應時間”,并把特定線程定義為“關鍵線程”。 當一個“關鍵線程”需要執行時,如果線程所在分區有預算,它就直接使用所在分區預算就好,如同普通線程;如果所在分區沒有預算了,但是別的分區還有預算,那么“自適應”部份會把別分區的預算拿過來,并用于關鍵線程,這個跟普通的自適應分區調度一樣。 只有當系統里所有分區都沒有預算了,而有一個關鍵線程需要運行,而且線程所在的分區已經預先分配了關鍵響應預算,那么線程允許“突破”分區的預算,使用“關鍵響應預算”來執行。在QNX里,一個關鍵線程消耗的時間,從退出RECEIVE_BLOCK開始,到下一次進入RECEIVE_BLOCK。而且,關鍵線程的屬性是可傳遞的,如果關鍵線程在執行中,給別的線程發送了消息,那個線程也會變成關鍵線程。 總的來說,關鍵線程是用來保證關鍵任務不會因為系統太忙而無法取得CPU時間。即使所有的分區都被占滿了,至少還有“關鍵響應時間”可供關鍵線程來使用。當然,一個系統里不應該有太多的關鍵線程和關鍵響應時間。理論上,假設所有的線程都是關鍵線程,那么整個系統其實就變成了一個普通的按優先級調度的實時系統,所有的分區和預算都不起作用了。 在最緊急的情況下,關鍵線程可以使用“關鍵響應時間”來完成它的任務。如果“關鍵響應時間”還是不夠,會怎么樣?這個是系統設計問題,在設計系統的時候,你就應該為關鍵線程分配它能夠完成任務所需要的最大時間。如果依然發生“關鍵響應時間”不夠的狀況(被稱為“破產”狀態),這個就是一個設計錯誤了。
關鍵線程的破產
如上所述,關鍵線程的破產是一個設計問題。或者線程完成的任務并不那么“關鍵”,或者設計時給出的預算不夠。這種情況下需要重新審視整個系統設計(因為系統在某些情況下無法保證關鍵任務在預定時間內完成)。QNX在自適應分區里提供了偵測到關鍵線程破產時的多種響應辦法,可以是強行忽視,或者重啟系統,或者由自適應分區系統自動調整分區的預算。
自適應分區繼承
想像這個場景,文件系統在System分區里,但另一個Others分區里的第三方應用拼命調用文件系統,很有可能造成System分區的預算耗盡;這樣,首先可能導致別的應用無法使用文件系統;更嚴重的,可能是System分區里別的系統,比如Audio也無法正常工作。這個,顯然是自適應分區系統帶來的安全隱患。 解決辦法,就是跟優先級在消息傳遞上可以繼承一樣,分區也是可以繼承的。文件系統雖然分配在System系統里,但根據它響應的是誰的請求,時間被記到請求服務的線程分區里。這樣,如果一個第三方應用拼命調用文件系統,最多能做的,也只是消耗它自己的分區,當他自己分區的預算被耗盡時,影響它自己的CPU占用率。
自適應分區的小結
自適應分區有一些有趣的用法,比如我們常常被要求“系統需要保留30%的算力”。有了自適應分區,就可以建一個有30%預算的分區,在里面跑一個 for (;;); 這樣的死循環。這樣,剩下的系統就只有70%的算力了,可以在這個環境下檢驗一下系統的性能和穩定性。 自適應分區的具體操作方法,可以參考QNX的文檔。不同版本的QNX有稍微不同的命令行,但基本設計是一樣的。這篇文章只是介紹了自適應分區的基本概念,實際使用上,還是有許多細節需要考慮的,真的要使用,還是需要詳細參考QNX對應文檔。 ?
編輯:黃飛
?










 工商網監
工商網監
評論