 電子發(fā)燒友App
電子發(fā)燒友App


?
一、前言
大家都知道游戲文字、文章等一些風控場景都實現(xiàn)了敏感詞檢測,一些敏感詞會被屏蔽掉或者文章無法發(fā)布。今天我就分享用Go實現(xiàn)敏感詞前綴樹來達到文本的敏感詞檢測,讓我們一探究竟!
二、敏感詞檢測
實現(xiàn)敏感詞檢測都很多種方法,例如暴力、正則、前綴樹等。例如一個游戲的文字交流的場景,敏感詞會被和諧成 * ,該如何實現(xiàn)呢?首先我們先準備一些敏感詞如下:
?
sensitiveWords?:=?[]string{ ???"傻逼", ???"傻叉", ???"垃圾", ???"媽的", ???"sb", }
?
由于文章審核原因敏感詞就換成別的了,大家能理解意思就行。
當在游戲中輸入 什么垃圾打野,傻逼一樣,叫你來開龍不來,sb, 該如何檢測其中的敏感詞并和諧掉
暴力匹配
?
sensitiveWords?:=?[]string{
???"傻逼",
???"傻叉",
???"垃圾",
???"媽的",
???"sb",
}
text?:=?"什么垃圾打野,傻逼一樣,叫你來開龍不來,sb"
for?_,?word?:=?range?sensitiveWords?{
???text?=?strings.Replace(text,?word,?"*",?-1)
}
println("text?->?",?text)
?
這樣采用的Go的內(nèi)置的字符串替換的方法來進行暴力替換結(jié)果如下:
?
text -> 什么*打野,*一樣,叫你來開龍不來,*
?
但暴力替換的時間復雜度太高了O(N^2),不建議這樣,而且和諧的字符只有一個 *,感覺像屏蔽了一個字一樣,因此改造一下并引出go中的 rune 類型。
?
sensitiveWords?:=?[]string{
???"傻逼",
???"傻叉",
???"垃圾",
???"媽的",
???"sb",
}
text?:=?"什么垃&圾打野,傻&逼一樣,叫你來開龍不來,s&b"
for?_,?word?:=?range?sensitiveWords?{
???replaceChar?:=?""
???for?i,?wordLen?:=?0,?len(word);?i??",?text)
>>>out
text?->??什么******打野,******一樣,叫你來開龍不來,**
?
為什么中文的和諧字符多了這么*?
因為Go中默認采用utf-8來進行中文字符編碼,因此一個中文字符要占3個字節(jié)
因此引出 Go 中的 rune 類型,它可以代表一個字符編碼的int32的表現(xiàn)形式,就是說一個字符用一個數(shù)字唯一標識。有點像 ASCII 碼一樣 a => 97, A => 65
源碼解釋如下
// rune is an alias for int32 and is equivalent to int32 in all ways. It is used, by convention, to distinguish character values from integer values.
type rune = int32
?
fmt.Println("a?->?",?rune('a'))
fmt.Println("A?->?",?rune('A'))
fmt.Println("暉?->?",?rune('暉'))
fmt.Println("霞?->?",?rune('霞'))
fmt.Println("暉霞?->?",?[]rune("暉霞"))
>>>out
a?->??97
A?->??65???????????????????????????????????????????????
暉?->??26198???????????????????????????????????????????
霞?->??38686???????????????????????????????????????????
暉霞?->??[26198?38686]???
?
因此將敏感詞字符串轉(zhuǎn)換成rune類型的數(shù)組然后來計算其字符個數(shù)
?
sensitiveWords?:=?[]string{
???"傻逼",
???"傻叉",
???"垃圾",
???"媽的",
???"sb",
}
text?:=?"什么垃圾打野,傻逼一樣,叫你來開龍不來,sb"
for?_,?word?:=?range?sensitiveWords?{
???replaceChar?:=?""
???for?i,?wordLen?:=?0,?len([]rune(word));?i??",?text)
>>>out
text?->??什么**打野,**一樣,叫你來開龍不來,**
?
正則匹配
?
//?正則匹配
func?regDemo()?{
???sensitiveWords?:=?[]string{
??????"傻逼",
??????"傻叉",
??????"垃圾",
??????"媽的",
??????"sb",
???}
???text?:=?"什么垃圾打野,傻逼一樣,叫你來開龍不來,sb"
???//?構(gòu)造正則匹配字符
???regStr?:=?strings.Join(sensitiveWords,?"|")
???println("regStr?->?",?regStr)
???wordReg?:=?regexp.MustCompile(regStr)
???text?=?wordReg.ReplaceAllString(text,?"*")
???println("text?->?",?text)
}
>>>out
regStr?->??傻逼|傻叉|垃圾|媽的|sb???????????
text???->??什么*打野,*一樣,叫你來開龍不來,*
?
再優(yōu)化下:
?
//?正則匹配敏感詞
func?regDemo(sensitiveWords?[]string,?matchContents?[]string)?{
???banWords?:=?make([]string,?0)?//?收集匹配到的敏感詞
???//?構(gòu)造正則匹配字符
???regStr?:=?strings.Join(sensitiveWords,?"|")
???wordReg?:=?regexp.MustCompile(regStr)
???println("regStr?->?",?regStr)
???for?_,?text?:=?range?matchContents?{
??????textBytes?:=?wordReg.ReplaceAllFunc([]byte(text),?func(bytes?[]byte)?[]byte?{
?????????banWords?=?append(banWords,?string(bytes))
?????????textRunes?:=?[]rune(string(bytes))
?????????replaceBytes?:=?make([]byte,?0)
?????????for?i,?runeLen?:=?0,?len(textRunes);?i??",?text)
??????fmt.Println("replaceText????->?",?string(textBytes))
??????fmt.Println("sensitiveWords?->?",?banWords)
???}
}
func?main()?{
???sensitiveWords?:=?[]string{
??????"傻逼",
??????"傻叉",
??????"垃圾",
??????"媽的",
??????"sb",
???}
???matchContents?:=?[]string{
??????"什么垃圾打野,傻逼一樣,叫你來開龍不來,sb",
???}
???regDemo(sensitiveWords,?matchContents)
}
>>>out
regStr?->??傻逼|傻叉|垃圾|媽的|sb????????????????????????????
srcText????????->??什么垃圾打野,傻逼一樣,叫你來開龍不來,sb
replaceText????->??什么**打野,**一樣,叫你來開龍不來,**????
sensitiveWords?->??[垃圾?傻逼?sb]???
?
這里是通過敏感詞去構(gòu)造正則表達式然后再去匹配。
本文重點是使用Go實現(xiàn)前綴樹完成敏感詞的匹配,具體細節(jié)都在這里實現(xiàn)。
三、Go 語言實現(xiàn)敏感詞前綴樹
前綴樹結(jié)構(gòu)
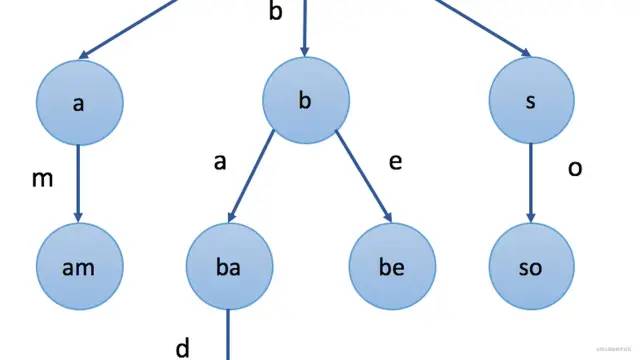
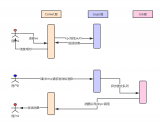
前綴樹、也稱字典樹(Trie),是N叉樹的一種特殊形式,前綴樹的每一個節(jié)點代表一個字符串(前綴)。每一個節(jié)點會有多個子節(jié)點,通往不同子節(jié)點的路徑上有著不同的字符。子節(jié)點代表的字符串是由節(jié)點本身的原始字符串,以及通往該子節(jié)點路徑上所有的字符組成的。
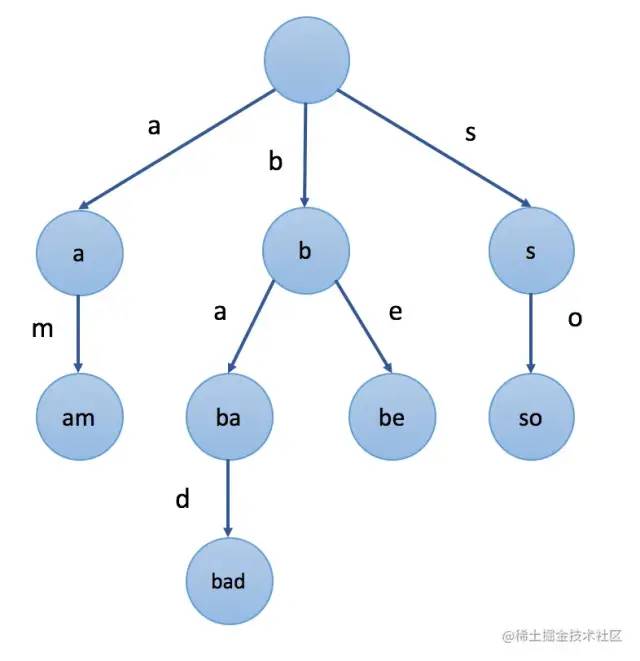
如上圖所示,就是一顆前綴樹,注意前綴樹的根節(jié)點不存數(shù)據(jù)。那么我們該如何表示一顆前綴樹呢?
可以參考一下二叉樹的節(jié)點結(jié)構(gòu)
?
type?BinTreeNode?struct?{
???Val????????string
???LeftChild??*BinTreeNode
???RightChild?*BinTreeNode
}
?
二叉樹,一個節(jié)點最多只能有兩個孩子節(jié)點,非常明確,而前綴是一顆多叉樹,一個節(jié)點不確定有多少子節(jié)點,因此可以用 切片Slice、Map 來存儲子節(jié)點,然后一般會設(shè)置標志位 End 來標識是否是字符串的最后一個節(jié)點。結(jié)構(gòu)如下
?
//?TrieNode?敏感詞前綴樹節(jié)點
type?TrieNode?struct?{
???childMap?map[rune]*TrieNode?//?本節(jié)點下的所有子節(jié)點
???Data?????string?????????????//?在最后一個節(jié)點保存完整的一個內(nèi)容
???End??????bool???????????????//?標識是否最后一個節(jié)點
}
?
這里采用 Map 來存儲子節(jié)點,更方便找字節(jié)點。key是rune類型(字符),value是子節(jié)點。Data則是在最后一個節(jié)點保存完整的一個內(nèi)容。
?
//?SensitiveTrie?敏感詞前綴樹
type?SensitiveTrie?struct?{
???replaceChar?rune?//?敏感詞替換的字符
???root????????*TrieNode
}
?
這里再用另一個結(jié)構(gòu)體來代表整個敏感詞前綴樹。
添加敏感詞
添加敏感詞用于構(gòu)造一顆敏感詞前綴樹。
相對每個節(jié)點來說 childMap 都是保存相同前綴字符的子節(jié)點
?
//?AddChild?前綴樹添加 func?(tn?*TrieNode)?AddChild(c?rune)?*TrieNode?{ ???if?tn.childMap?==?nil?{ ??????tn.childMap?=?make(map[rune]*TrieNode) ???} ???if?trieNode,?ok?:=?tn.childMap[c];?ok?{ ??????//?存在不添加了 ??????return?trieNode ???}?else?{ ??????//?不存在 ??????tn.childMap[c]?=?&TrieNode{ ?????????childMap:?nil, ?????????End:??????false, ??????} ??????return?tn.childMap[c] ???} }
?
敏感詞前綴樹則是一個完整的敏感詞的粒度來添加
?
//?AddWord?添加敏感詞
func?(st?*SensitiveTrie)?AddWord(sensitiveWord?string)?{
???//?將敏感詞轉(zhuǎn)換成rune類型(int32)
???tireNode?:=?st.root
???sensitiveChars?:=?[]rune(sensitiveWord)
???for?_,?charInt?:=?range?sensitiveChars?{
??????//?添加敏感詞到前綴樹中
??????tireNode?=?tireNode.AddChild(charInt)
???}
???tireNode.End?=?true
???tireNode.Data?=?sensitiveWord
}
?
具體是把敏感詞轉(zhuǎn)換成 []rune 類型來代表敏感詞中的一個個字符,添加完后再將最后一個字符節(jié)點的End設(shè)置True,Data為完整的敏感詞數(shù)據(jù)。
可能這樣還不好理解,舉個例子:
?
//?SensitiveTrie?敏感詞前綴樹
type?SensitiveTrie?struct?{
???replaceChar?rune?//?敏感詞替換的字符
???root????????*TrieNode
}
//?TrieNode?敏感詞前綴樹節(jié)點
type?TrieNode?struct?{
???childMap?map[rune]*TrieNode?//?本節(jié)點下的所有子節(jié)點
???Data?????string?????????????//?在最后一個節(jié)點保存完整的一個內(nèi)容
???End??????bool???????????????//?標識是否最后一個節(jié)點
}
//?NewSensitiveTrie?構(gòu)造敏感詞前綴樹實例
func?NewSensitiveTrie()?*SensitiveTrie?{
???return?&SensitiveTrie{
??????replaceChar:?'*',
??????root:????????&TrieNode{End:?false},
???}
}
//?AddWord?添加敏感詞
func?(st?*SensitiveTrie)?AddWord(sensitiveWord?string)?{
???//?將敏感詞轉(zhuǎn)換成utf-8編碼后的rune類型(int32)
???tireNode?:=?st.root
???sensitiveChars?:=?[]rune(sensitiveWord)
???for?_,?charInt?:=?range?sensitiveChars?{
??????//?添加敏感詞到前綴樹中
??????tireNode?=?tireNode.AddChild(charInt)
???}
???tireNode.End?=?true
???tireNode.Data?=?sensitiveWord
}
//?AddChild?前綴樹添加子節(jié)點
func?(tn?*TrieNode)?AddChild(c?rune)?*TrieNode?{
???if?tn.childMap?==?nil?{
??????tn.childMap?=?make(map[rune]*TrieNode)
???}
???if?trieNode,?ok?:=?tn.childMap[c];?ok?{
??????//?存在不添加了
??????return?trieNode
???}?else?{
??????//?不存在
??????tn.childMap[c]?=?&TrieNode{
?????????childMap:?nil,
?????????End:??????false,
??????}
??????return?tn.childMap[c]
???}
}
func?main()?{
????sensitiveWords?:=?[]string{
???????"傻逼",
???????"傻叉",
???????"垃圾",
????}
????
????st?:=?NewSensitiveTrie()
????for?_,?word?:=?range?sensitiveWords?{
???????fmt.Println(word,?[]rune(word))
???????st.AddWord(word)
????}
}
>>>out
傻逼?[20667?36924]
傻叉?[20667?21449]
垃圾?[22403?22334]
?
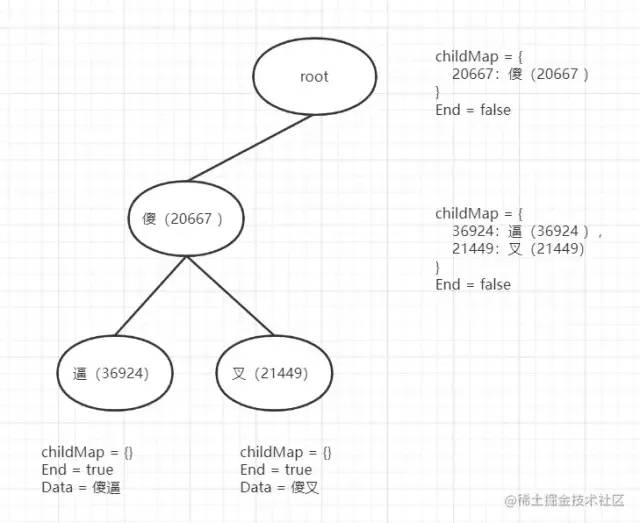
添加前兩個敏感詞傻逼、傻叉,有一個共同的前綴 傻、rune-> 200667
前綴的root是沒有孩子節(jié)點,添加第一個敏感詞時先轉(zhuǎn)換成 []rune(可以想象成字符數(shù)組)
遍歷rune字符數(shù)組,先判斷有沒有孩子節(jié)點(一開始root是沒有的),沒有就先構(gòu)造,然后把 傻(200667) 存到 childMap中 key 為 傻(200667),value 為 TrieNode 但沒有任何數(shù)據(jù)然后返回當前新增的節(jié)點
?
TrieNode{
????childMap:?nil
????End:??????false,
}
?
此時添加 逼(36924) ,同樣做2的步驟,傻逼這個敏感詞添加完成走出for循環(huán),然后將End=true、Data=傻逼。
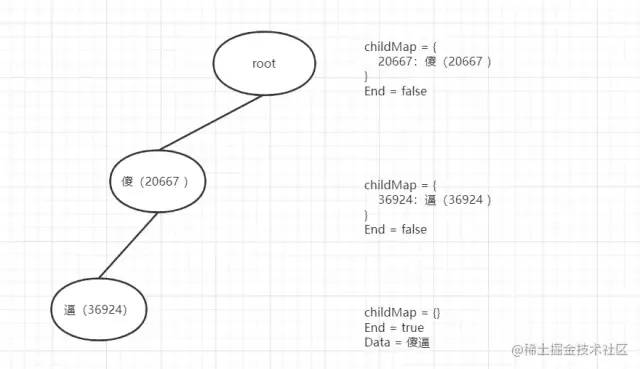
添加第二個敏感詞傻叉的時候又是從根節(jié)點開始,此時root有childMap,也存在傻(20667)節(jié)點,則是直接不添加把傻(20667)節(jié)點返回,然后再此節(jié)點上繼續(xù)添加 叉(21449),不存在添加到傻節(jié)點的childMap中。
添加第三個敏感詞垃 圾,又從根節(jié)點開始,垃(22403) ,根節(jié)點不存在該子節(jié)點,故添加到根節(jié)點的childMap中,然后返回新增的 垃(22403)節(jié)點
在垃節(jié)點基礎(chǔ)上添加 圾(22334) 節(jié)點,不存在子節(jié)點則添加并返回。
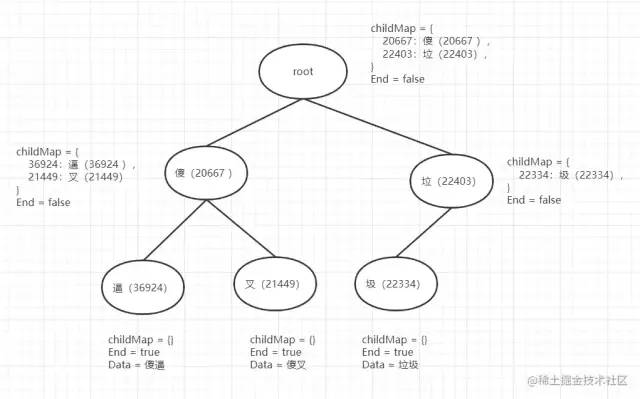
由此一顆敏感詞前綴樹就構(gòu)造出來了。
總結(jié):添加敏感詞字符節(jié)點存在不添加返回存在的節(jié)點,不存在添加新字符節(jié)點并返回新添節(jié)點,當敏感詞的所有字符都添加完畢后,讓最后一個節(jié)點,End=true,存儲一個完整的敏感詞。
匹配敏感詞
將待匹配的內(nèi)容轉(zhuǎn)換成 []rune 類型,然后遍歷尋找前綴樹種第一個匹對的前綴節(jié)點,然后從后一個位置繼續(xù),直到完整匹配到了敏感詞,將匹配文本的敏感詞替換成 *
?
//?FindChild?前綴樹尋找字節(jié)點
func?(tn?*TrieNode)?FindChild(c?rune)?*TrieNode?{
???if?tn.childMap?==?nil?{
??????return?nil
???}
???if?trieNode,?ok?:=?tn.childMap[c];?ok?{
??????return?trieNode
???}
???return?nil
}
//?replaceRune?字符替換
func?(st?*SensitiveTrie)?replaceRune(chars?[]rune,?begin?int,?end?int)?{
???for?i?:=?begin;?i??0?{
??????//?有敏感詞
??????replaceText?=?string(textCharsCopy)
???}?else?{
??????//?沒有則返回原來的文本
??????replaceText?=?text
???}
???return?sensitiveWords,?replaceText
}
?
這樣需要注意的是在內(nèi)容的末尾匹配到了的敏感詞處理,因為j+1后,會等于textLen的從而不進入for循環(huán)從而沒有處理末尾,因此需要特殊處理下末尾情況。具體測試如下
?
//?AddWords?批量添加敏感詞
func?(st?*SensitiveTrie)?AddWords(sensitiveWords?[]string)?{
???for?_,?sensitiveWord?:=?range?sensitiveWords?{
??????st.AddWord(sensitiveWord)
???}
}
//?前綴樹匹配敏感詞
func?trieDemo(sensitiveWords?[]string,?matchContents?[]string)?{
???trie?:=?NewSensitiveTrie()
???trie.AddWords(sensitiveWords)
???for?_,?srcText?:=?range?matchContents?{
??????matchSensitiveWords,?replaceText?:=?trie.Match(srcText)
??????fmt.Println("srcText????????->?",?srcText)
??????fmt.Println("replaceText????->?",?replaceText)
??????fmt.Println("sensitiveWords?->?",?matchSensitiveWords)
??????fmt.Println()
???}
???//?動態(tài)添加
???trie.AddWord("牛大大")
???content?:=?"今天,牛大大去挑戰(zhàn)灰大大了"
???matchSensitiveWords,?replaceText?:=?trie.Match(content)
???fmt.Println("srcText????????->?",?content)
???fmt.Println("replaceText????->?",?replaceText)
???fmt.Println("sensitiveWords?->?",?matchSensitiveWords)
}
func?main()?{
???sensitiveWords?:=?[]string{
??????"傻逼",
??????"傻叉",
??????"垃圾",
??????"媽的",
??????"sb",
???}
???matchContents?:=?[]string{
??????"你是一個大傻逼,大傻叉",
??????"你是傻叉",
??????"shabi東西",
??????"他made東西",
??????"什么垃圾打野,傻逼一樣,叫你來開龍不來,SB",
??????"正常的內(nèi)容",
???}
???//fmt.Println("---------?普通暴力匹配敏感詞?---------")
???//normalDemo(sensitiveWords,?matchContents)
???//
???//fmt.Println("
---------?正則匹配敏感詞?---------")
???//regDemo(sensitiveWords,?matchContents)
???fmt.Println("
---------?前綴樹匹配敏感詞?---------")
???trieDemo(sensitiveWords,?matchContents)
}
?
結(jié)果如下:
?
---------?前綴樹匹配敏感詞?--------- srcText????????->??你是一個大傻&逼,大傻?叉 replaceText????->??你是一個大傻&逼,大傻?叉 sensitiveWords?->??[] srcText????????->??你是傻叉 replaceText????->??你是傻叉 sensitiveWords?->??[] srcText????????->??shabi東西 replaceText????->??shabi東西 sensitiveWords?->??[] srcText????????->??他made東西 replaceText????->??他made東西 sensitiveWords?->??[] srcText????????->??什么垃?圾打野,傻?逼一樣,叫你來開龍不來,傻?逼東西,S?B replaceText????->??什么**打野,**一樣,叫你來開龍不來,** sensitiveWords?->??[垃圾?傻逼] srcText????????->??正常的內(nèi)容 replaceText????->??正常的內(nèi)容 sensitiveWords?->??[]
?
過濾特殊字符
可以發(fā)現(xiàn)在敏感詞內(nèi)容的中間添加一些空格、字符、表情都不能正確的在前綴樹中匹配到。因此我們在進行匹配的時候應(yīng)該過濾一些特殊的字符,只保留漢字、數(shù)字、字母,然后全部以小寫來進行匹配。
?
//?FilterSpecialChar?過濾特殊字符 func?(st?*SensitiveTrie)?FilterSpecialChar(text?string)?string?{ ???text?=?strings.ToLower(text) ???text?=?strings.Replace(text,?"?",?"",?-1)?//?去除空格 ???//?過濾除中英文及數(shù)字以外的其他字符 ???otherCharReg?:=?regexp.MustCompile("[^u4e00-u9fa5a-zA-Z0-9]") ???text?=?otherCharReg.ReplaceAllString(text,?"") ???return?text }
?
感覺這里去除空格是多余的步驟,正則以已經(jīng)幫你排除了。
u4e00-u9fa5a 代表所有的中文
a-zA-Z 代表大小寫字母
0-9 數(shù)字
連起來在最前面加上一個 ^ 就是進行一個取反
添加拼音檢測
最后就是添加中文的拼音檢測,讓輸入的拼音也能正確的匹配到,拼音檢測是把我們的敏感詞轉(zhuǎn)換成拼音然后添加到前綴樹中。
實現(xiàn)中文轉(zhuǎn)拼音可以用別人造好的輪子
?
go get github.com/chain-zhang/pinyin
?
查看源碼整體的思路就是用文件把文字的rune和拼音對應(yīng)上,具體細節(jié)自行查看
測試一下
?
//?HansCovertPinyin?中文漢字轉(zhuǎn)拼音
func?HansCovertPinyin(contents?[]string)?[]string?{
???pinyinContents?:=?make([]string,?0)
???for?_,?content?:=?range?contents?{
??????chineseReg?:=?regexp.MustCompile("[u4e00-u9fa5]")
??????if?!chineseReg.Match([]byte(content))?{
?????????continue
??????}
??????//?只有中文才轉(zhuǎn)
??????pin?:=?pinyin.New(content)
??????pinStr,?err?:=?pin.Convert()
??????println(content,?"->",?pinStr)
??????if?err?==?nil?{
?????????pinyinContents?=?append(pinyinContents,?pinStr)
??????}
???}
???return?pinyinContents
}
func?main()?{
???sensitiveWords?:=?[]string{
??????"傻逼",
??????"傻叉",
??????"垃圾",
??????"媽的",
??????"sb",
???}
???
???//?漢字轉(zhuǎn)拼音
???pinyinContents?:=?HansCovertPinyin(sensitiveWords)
???fmt.Println(pinyinContents)
?}
?
?
?>>>out
傻逼?->?sha?bi?????????????????????????????
傻叉?->?sha?cha????????????????????????????
垃圾?->?la?ji??????????????????????????????
媽的?->?ma?de??????????????????????????????
[sha?bi?sha?cha?la?ji?ma?de]?
?
然后再測試敏感詞匹配的效果
?
//?Match?查找替換發(fā)現(xiàn)的敏感詞
func?(st?*SensitiveTrie)?Match(text?string)?(sensitiveWords?[]string,?replaceText?string)?{
???if?st.root?==?nil?{
??????return?nil,?text
???}
???//?過濾特殊字符
???filteredText?:=?st.FilterSpecialChar(text)
???sensitiveMap?:=?make(map[string]*struct{})?//?利用map把相同的敏感詞去重
???textChars?:=?[]rune(filteredText)
???textCharsCopy?:=?make([]rune,?len(textChars))
???copy(textCharsCopy,?textChars)
???for?i,?textLen?:=?0,?len(textChars);?i??0?{
??????//?有敏感詞
??????replaceText?=?string(textCharsCopy)
???}?else?{
??????//?沒有則返回原來的文本
??????replaceText?=?text
???}
???return?sensitiveWords,?replaceText
}
//?前綴樹匹配敏感詞
func?trieDemo(sensitiveWords?[]string,?matchContents?[]string)?{
???//?漢字轉(zhuǎn)拼音
???pinyinContents?:=?HansCovertPinyin(sensitiveWords)
???fmt.Println(pinyinContents)
???trie?:=?NewSensitiveTrie()
???trie.AddWords(sensitiveWords)
???trie.AddWords(pinyinContents)?//?添加拼音敏感詞
???for?_,?srcText?:=?range?matchContents?{
??????matchSensitiveWords,?replaceText?:=?trie.Match(srcText)
??????fmt.Println("srcText????????->?",?srcText)
??????fmt.Println("replaceText????->?",?replaceText)
??????fmt.Println("sensitiveWords?->?",?matchSensitiveWords)
??????fmt.Println()
???}
???//?動態(tài)添加
???trie.AddWord("牛大大")
???content?:=?"今天,牛大大去挑戰(zhàn)灰大大了"
???matchSensitiveWords,?replaceText?:=?trie.Match(content)
???fmt.Println("srcText????????->?",?content)
???fmt.Println("replaceText????->?",?replaceText)
???fmt.Println("sensitiveWords?->?",?matchSensitiveWords)
}
func?main()?{
???sensitiveWords?:=?[]string{
??????"傻逼",
??????"傻叉",
??????"垃圾",
??????"媽的",
??????"sb",
???}
???matchContents?:=?[]string{
??????"你是一個大傻逼,大傻叉",
??????"你是傻叉",
??????"shabi東西",
??????"他made東西",
??????"什么垃?圾打野,傻逼一樣,叫你來開龍不來,SB",
??????"正常的內(nèi)容",
???}
???fmt.Println("
---------?前綴樹匹配敏感詞?---------")
???trieDemo(sensitiveWords,?matchContents)
}
?
結(jié)果如下:
?
---------?前綴樹匹配敏感詞?--------- srcText????????->??你是一個大傻逼,大傻叉?????????????????? replaceText????->??你是一個大**大**?????????????????????????? sensitiveWords?->??[傻逼?傻叉]??????????????????????????????? ????????????????????????????????????????????????????????????? srcText????????->??你是傻叉????????????????????????????????? replaceText????->??你是**???????????????????????????????????? sensitiveWords?->??[傻叉]???????????????????????????????????? ????????????????????????????????????????????????????????????? srcText????????->??shabi東西????????????????????????????????? replaceText????->??*****東西????????????????????????????????? sensitiveWords?->??[shabi]??????????????????????????????????? ????????????????????????????????????????????????????????????? srcText????????->??他made東西???????????????????????????????? replaceText????->??他****東西???????????????????????????????? sensitiveWords?->??[made]???????????????????????????????????? ????????????????????????????????????????????????????????????? srcText????????->??什么垃圾打野,傻逼一樣,叫你來開龍不來,SB replaceText????->??什么**打野**一樣叫你來開龍不來**?????????? sensitiveWords?->??[垃圾?傻逼?sb]???????????????????????????? ????????????????????????????????????????????????????????????? srcText????????->??正常的內(nèi)容??????????????????????????????? replaceText????->??正常的內(nèi)容??????????????????????????????? sensitiveWords?->??[]???????????????????????????????????????? srcText????????->??今天,牛大大挑戰(zhàn)灰大大 replaceText????->??今天***挑戰(zhàn)灰大大 sensitiveWords?->??[牛大大]
?
整體效果還是挺不錯的,但是一些諧音或者全部英文句子時有空格還是不能去除空格不然可能會存在誤判還是不能檢測出,要想充分的進行敏感詞檢測,首先要有完善的敏感詞庫,其次就是特殊情況特殊處理,最后就是先進行敏感詞匹配然后再進行自然語言處理NLP完善,訓練風控模型等檢測效果才更只能。
四、源代碼
敏感詞前綴樹匹配:gitee.com/huiDBK/sens…[1]
審核編輯:湯梓紅









 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論