 電子發(fā)燒友App
電子發(fā)燒友App


Alluxio 是一個開源的數(shù)據(jù)編排系統(tǒng),致力于解決解決大數(shù)據(jù)分析及 AI 場景下的一些痛點問題,它可以加速數(shù)據(jù)查詢和AI模型訓(xùn)練的速度,提升系統(tǒng)在高并發(fā)場景下的高可用能力。這些應(yīng)用場景決定了 Alluxio 需要具備大吞吐量特性,本文首先介紹 Alluxio Master 的線程池結(jié)構(gòu),基于線程池分析結(jié)果提出 Alluxio 吞吐量調(diào)優(yōu)方案。
作者簡介
?
劉堯龍
騰訊Alluxio Oteam 研發(fā)工程師,Alluxio Committer。主要負(fù)責(zé)Alluxio及分布式一致性相關(guān)的開發(fā)工作。
業(yè)務(wù)背景?
本次線程池結(jié)構(gòu)分析與調(diào)優(yōu)的對象是 Alluxio 的開源版本,且 Alluxio 的配置項均為默認(rèn)配置項,分析的場景是游戲 AI 的特征計算階段。特征計算需要大量讀取用戶數(shù)據(jù)分析用戶操作,然后針對計算結(jié)果進(jìn)行游戲環(huán)境的還原。特征計算任務(wù)初期會有數(shù)千至上萬的進(jìn)程同時對底層分布式存儲節(jié)點發(fā)起訪問,產(chǎn)生流量洪峰。在這種讀密集場景下,Alluxio 的高吞吐可以有效緩解存儲端壓力。
Alluxio 默認(rèn)線程池結(jié)構(gòu)與 JVM 參數(shù)
在業(yè)務(wù)運行過程中,通過 jstack 生成系統(tǒng)線程信息,導(dǎo)入FastThread(https://fastthread.io/)分析。分析結(jié)果如下:
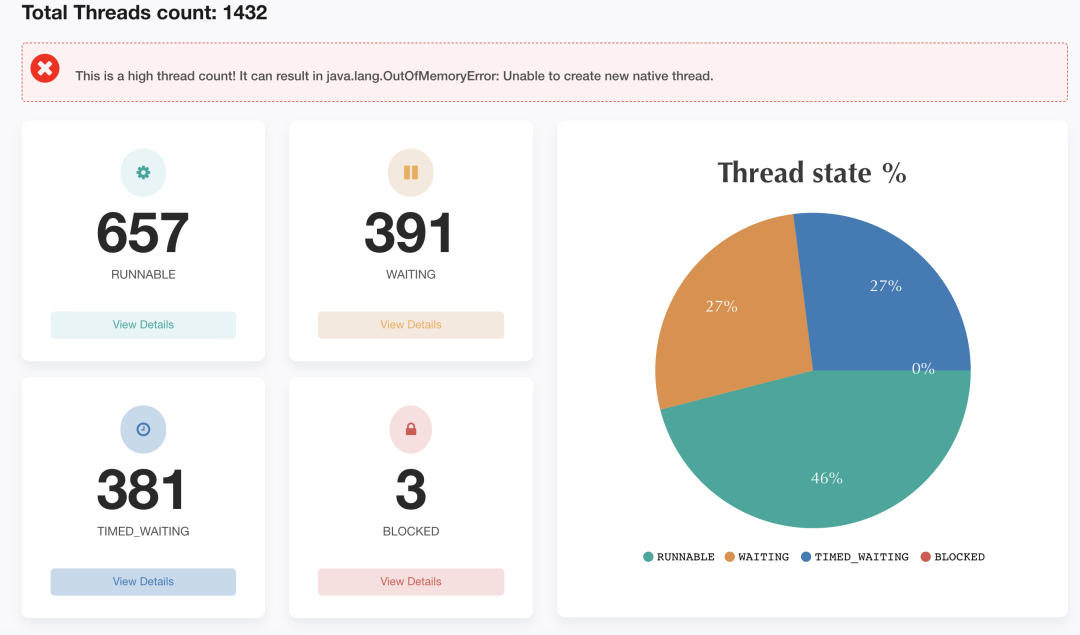
?
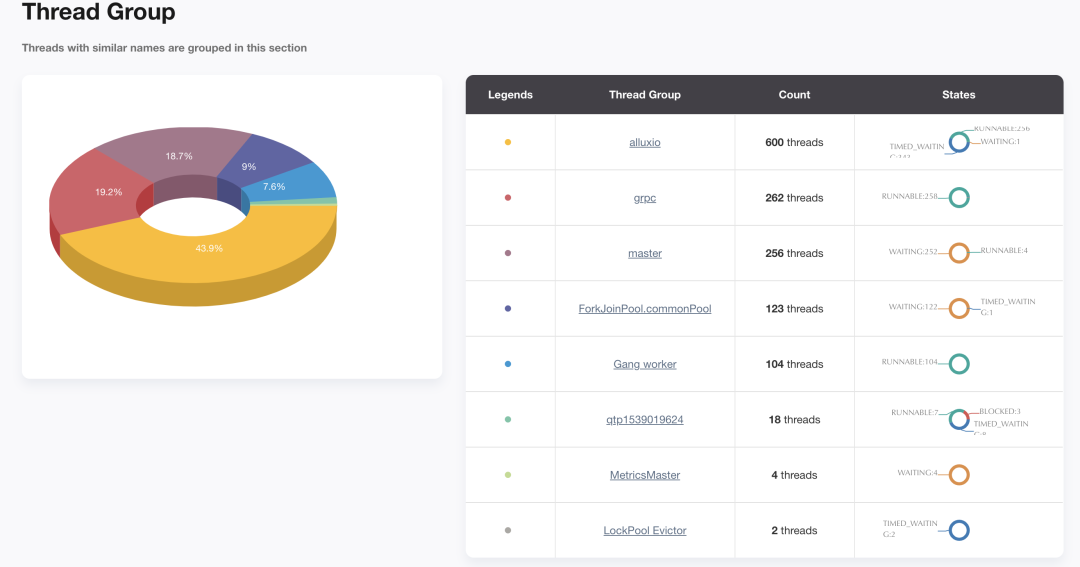
Alluxio Master 節(jié)點有 1432 個線程,其中 RUNABLE 狀態(tài)的線程數(shù)僅占46%,有大量線程處于 WATING ?和? TIME_WAITING ?狀態(tài),Master 節(jié)點線程數(shù)較多,容易發(fā)生 OOM,需要根據(jù)線程池工作與線程間的調(diào)用關(guān)系,適當(dāng)調(diào)整線程數(shù)量。Alluxio Master 上有八個線程組,分別為:Alluxio、master、grpc、ForkJoinPool.commonPool、Gang.worker、qtpXXX、MetricsMaster、LockPool Evictor。它們之間的工作與線程調(diào)用關(guān)系如下圖所示。接下來將結(jié)合線程模型和 Alluxio 源碼分析這些線程組的作用及調(diào)優(yōu)方向。
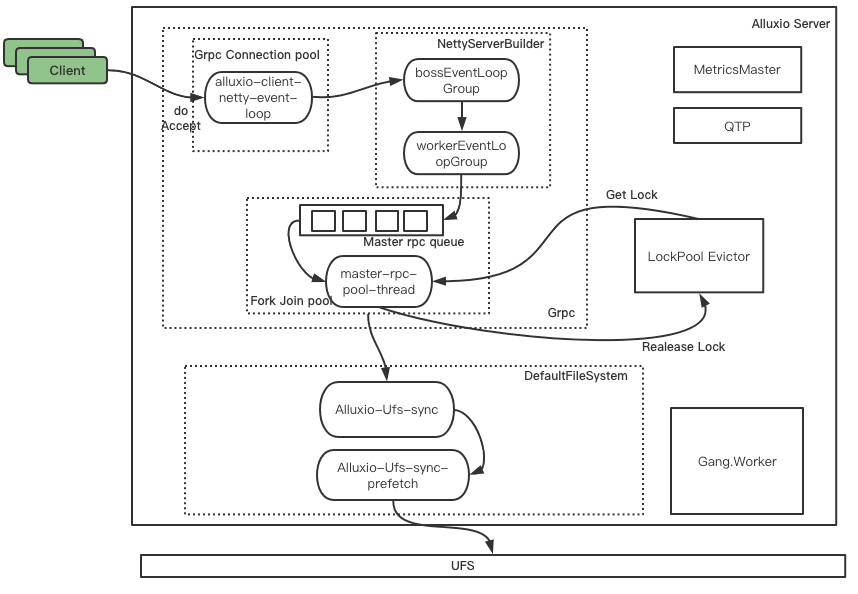
Alluxio 線程組
Alluxio 線程組共600個線程,它們的狀態(tài)如下:
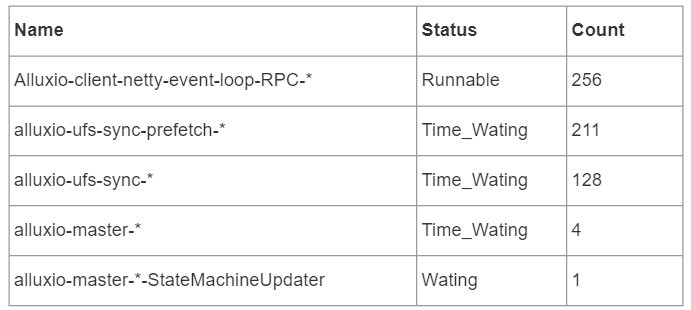
由上表可知,Alluxio 線程組中共有5種線程,其中,負(fù)責(zé)client的線程均處于 RUNNABLE 狀態(tài),其余線程處于 TIME_WATING 和 WATING 狀態(tài),下面將介紹每個線程的功能。
Alluxio-client-netty-event-loop-RPC
這是 Netty 框架的線程池,屬于 NioEventLoopGroup 類型。在這次采樣數(shù)據(jù)中,該線程池256個線程均處于 RUNNABLE 狀態(tài),該線程用于 client 端與 server 端建立連接時使用,可以通過下列配置項進(jìn)行配置,它的默認(rèn)值為0。
?
?
alluxio.user.network.netty.worker.threads
?
?
Alluxio-ufs-sync
該線程池主要用于并發(fā)地執(zhí)行元數(shù)據(jù)同步操作,它是 ThreadPoolExecutor 類型。具體的元數(shù)據(jù)同步操作由 Alluxio-ufs-sync-prefetch 線程組完成。在本次采樣中,線程全部處于 TIME_WATING 狀態(tài)。該線程池的核心線程數(shù)與最大線程數(shù)相等,它的默認(rèn)值為系統(tǒng)當(dāng)前的核心數(shù),可以通過下列配置項修改。
?
?
alluxio.master.metadata.sync.executor.pool.size
?
?
Alluxio-ufs-sync-prefetch
該線程池主要在一個元數(shù)據(jù)同步操作內(nèi),并發(fā)地從 UFS 中獲取元數(shù)據(jù)。在本次采樣中,線程全部處于 TIME_WAITING 狀態(tài)。該線程池的核心線程數(shù)與最大線程數(shù)相等,默認(rèn)值為系統(tǒng)當(dāng)前的線程數(shù)的 10 倍,可以通過下列配置項修改。
?
?
alluxio.master.metadata.sync.ufs.prefetch.pool.size
?
?
Alluxio-master
這個線程組有5個線程:
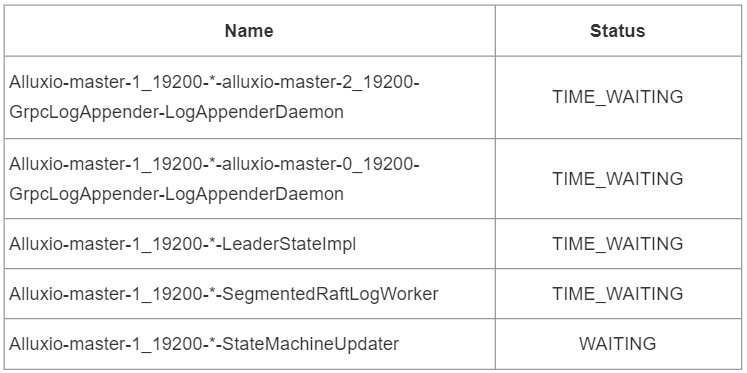
本次提取的堆棧信息是從 Alluxio-master-1 節(jié)點中取出的,它是 Leader 節(jié)點。這五個線程用于支持 Alluxio-master 的具體工作:上表的前兩個線程是 master-1 與兩個 raft follower 節(jié)點進(jìn)行通信的守護(hù)線程,用于 raft 集群中追加日志時進(jìn)行通信。第三個線程為 Leader 節(jié)點特有的,主要用于 Leader 選舉的相關(guān)操作。第四個線程為 RaftLog 相關(guān)的線程,這個線程會處理與 Raft log 相關(guān)的 I/O OPS 相關(guān)的操作。第五個線程與 StateMachine 相關(guān),它是 Ratis 用于狀態(tài)機更新的線程。
master 線程組
Master 線程組共256個線程,均處于 WATING 狀態(tài)。它們組成了一個 ForkJoinPool 類型的線程池,F(xiàn)orkJoinPool 是ExecutorService 的補充,它采用分而治之的思想,比較適合計算密集型任務(wù)。Alluxio 用該線程池處理 RPC 請求,它從 RPC Queue 不斷取出積壓的任務(wù),然后進(jìn)行處理,這個線程池的創(chuàng)建源碼為:
?
?
ExecutorServiceBuilder#executorService = new ForkJoinPool(parallelism, ? ?ThreadFactoryUtils.buildFjp(threadNameFormat, true), null, isAsync, corePoolSize, ? ?maxPoolSize, minRunnable, null, keepAliveMs, TimeUnit.MILLISECONDS);
?
?
GRPC 線程組
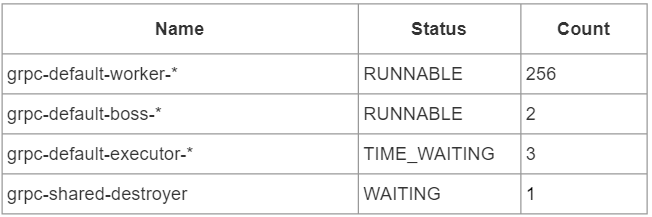
GRPC 線程組由4種線程構(gòu)成,在本次采樣中共262個線程。這四種線程屬于 GRPC 框架,它們?yōu)?Alluxio 提供 RPC 通信服務(wù)。
MetricsMaster 線程組
該線程組共4個線程,它們是一個 FixedThreadPool 類型的線程池,即該線程池的核心線程數(shù)與最大線程數(shù)相等。該線程池主要用于并行獲取從 worker 或者 client 提交的 Metric 數(shù)據(jù),并根據(jù)數(shù)據(jù)更新集群的指標(biāo)信息,這些信息可以通過 Grafana 與Prometheus 相結(jié)合地方式直觀地檢查系統(tǒng)狀態(tài)。該線程池的核心線程數(shù)是可配置的,通過下列配置項完成。
?
?
alluxio.master.metrics.service.threads=5(默認(rèn)值)
?
?
LockPool Evictor 線程組
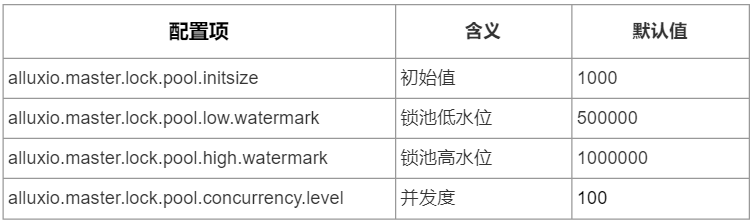
LocakPool Evictor 線程組由2個 SingleThreadExecutor 類型的線程池組成,它們作為鎖池使用。該線程池的源碼如下:
?
?
private final LockPoolmInodeLocks = ? ?new LockPool<>((key) -> new ReentrantReadWriteLock(), ? ? ? ?ServerConfiguration.getInt(PropertyKey.MASTER_LOCK_POOL_INITSIZE), ? ? ? ?ServerConfiguration.getInt(PropertyKey.MASTER_LOCK_POOL_LOW_WATERMARK), ? ? ? ?ServerConfiguration.getInt(PropertyKey.MASTER_LOCK_POOL_HIGH_WATERMARK), ? ? ? ?ServerConfiguration.getInt(PropertyKey.MASTER_LOCK_POOL_CONCURRENCY_LEVEL)); private final LockPool mEdgeLocks = ? ?new LockPool<>((key) -> new ReentrantReadWriteLock(), ? ? ? ?ServerConfiguration.getInt(PropertyKey.MASTER_LOCK_POOL_INITSIZE), ? ? ? ?ServerConfiguration.getInt(PropertyKey.MASTER_LOCK_POOL_LOW_WATERMARK), ? ? ? ?ServerConfiguration.getInt(PropertyKey.MASTER_LOCK_POOL_HIGH_WATERMARK), ? ? ? ?ServerConfiguration.getInt(PropertyKey.MASTER_LOCK_POOL_CONCURRENCY_LEVEL));
?
?
其中,mInodeLocks 用于提供 inode 鎖:要鎖定一個 inode,必須在該池中得它的id然后獲取它的讀鎖;mEdgeLocks 用于提供邊鎖,這里的邊指的是 inode 樹中的一條邊,邊從父 inode id 指向子 inode id。
這兩種鎖池中的鎖均為可重入的讀寫鎖,鎖池的初始數(shù)量、最小鎖數(shù)量、最大鎖數(shù)量、并發(fā)度均可以配置。
qtpXXX 線程組
該線程組用于提供 Jetty 服務(wù),Jetty 是一個開源的 Servlet 容器,對外提供 web 服務(wù)。它們屬于 QueueThreadPool 類型的線程池。在本次采樣結(jié)果中共14個線程,這個線程池的最大線程數(shù)為254個,最小線程數(shù)為8。
Gang.worker 線程組
Gang worker 線程組用于 JVM 的垃圾回收。該線程組的線程數(shù)可以通過修改 JVM 參數(shù)進(jìn)行 -XX:ParallelGCThreads 進(jìn)行修改。
調(diào)優(yōu)原理與結(jié)果
審計日志
在吞吐量測試過程中,我們在編譯器研發(fā)團隊的幫助下,通過 Kona Profile 采樣,并對采樣結(jié)果進(jìn)行分析,發(fā)現(xiàn) Alluxio 在運行過程中,生成審計日志時存在明顯的鎖競爭,blocking queue 的 size 成為了瓶頸點。
基于這種現(xiàn)象,我們選擇在非生產(chǎn)環(huán)境下關(guān)閉審計日志,在生產(chǎn)環(huán)境下調(diào)高審計日志的 blocking queue size 的方式調(diào)優(yōu)性能。在調(diào)整后發(fā)現(xiàn),系統(tǒng)吞吐量明顯提升。
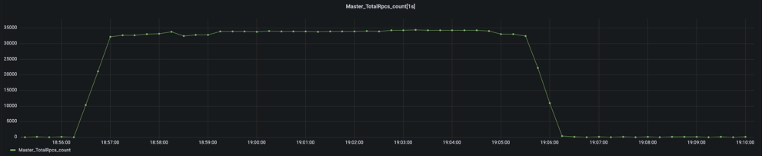
?
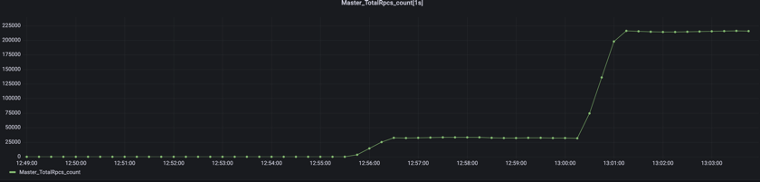
調(diào)整 UFS-SYNC-PREFETCH 線程池
在 Alluxio Master 運行業(yè)務(wù)時,大量的任務(wù)積壓在 master rpc queue 中,F(xiàn)orkJoinPool 線程池的處理速度受限于物理機的資源成為了瓶頸點。Alluxio-UFS-SYNC-PREFETCH 線程池用于執(zhí)行元數(shù)據(jù)的同步工作,這個線程數(shù)默認(rèn)為系統(tǒng) CPU 核數(shù)的10倍,在實際系統(tǒng)中并不需要這么多的線程數(shù),因此這種配置存在線程浪費情況。因此,我們將該線程數(shù)調(diào)整為2倍的 CPU 核數(shù),調(diào)整后發(fā)現(xiàn)沒有出現(xiàn)性能下降的情況。
JVM GC 線程數(shù)調(diào)優(yōu)
Alluxio 在騰訊自研的 KonaJDK 11 上作測試,使用 JDK 默認(rèn)參數(shù)會出現(xiàn)集群 Full GC 時間過長的情況,Master 停頓時間過長會導(dǎo)致 Leader 切換,這種切換的成本很高。通過分析 GC 日志,我們發(fā)現(xiàn)默認(rèn)的 GC 并行線程數(shù)較小,僅為30。考慮到我們使用的為64服務(wù)器,我們將 GC 并行線程數(shù)調(diào)整為40,發(fā)現(xiàn) GC 停頓時間明顯降低,系統(tǒng)的穩(wěn)定性增強。
后續(xù)調(diào)優(yōu)方向展望
Alluxio 作為存儲引擎和計算框架之間的中間件,承載著數(shù)據(jù)緩存、訪問加速、緩解存儲壓力等任務(wù),這些功能都對 Alluxio 系統(tǒng)的吞吐量提出了較高的要求。在接下來工作中,我們將繼續(xù)改進(jìn)方案,不斷提升系統(tǒng)吞吐量性能。為此,我們設(shè)計了幾種方案。
將 Follower Master 開啟讀服務(wù)
現(xiàn)階段,Alluxio 僅有 Leader Master 接受 Client 端的讀寫請求,這限制了 Alluxio 吞吐量的提升。這會產(chǎn)生單點瓶頸效應(yīng),我們計劃在后續(xù)將 Follower Master 接受 Client 端的讀請求,這樣會有效提升系統(tǒng)吞吐量。
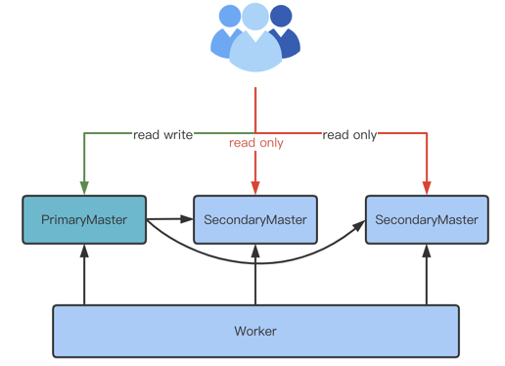
這種架構(gòu)的優(yōu)勢在于可以充分利用現(xiàn)有的節(jié)點,不需要有非常大的代碼改動,但缺點為系統(tǒng)提升仍會有瓶頸,不具備無限擴展能力。
開發(fā) Observer Master
為了使集群在理論上擁有無限擴展能力,可以借鑒 Zookeeper 的 Observer Node 思想,開發(fā) Oberserver Master 節(jié)點,系統(tǒng)模型如下:
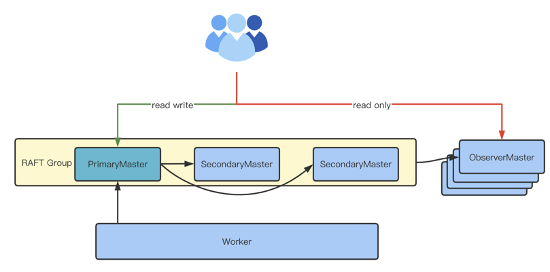
這種模型可以添加多個 Observer Master 節(jié)點,它們的元數(shù)據(jù)同步可以主動 tail raft group 中的 log,并回放到本地狀態(tài)機上,worker 的 block 信息可以周期性地進(jìn)行同步。這種架構(gòu)的優(yōu)勢為理論上可以無限擴展,但劣勢是需要額外的節(jié)點資源。且這種方案代碼改動較多、開發(fā)難度大,block 位置信息的同步開銷也比較大。
總結(jié)
本次初衷是基于線程池結(jié)構(gòu)對 Alluxio 吞吐量性能進(jìn)行調(diào)優(yōu),根據(jù)本次測試采樣結(jié)果分析了性能瓶頸點,調(diào)優(yōu)相關(guān)瓶頸點后得到性能提升。
基于 Alluxio Master 的源碼,本文介紹了 Alluxio Master 的線程池結(jié)構(gòu)與每個線程的功能。在調(diào)優(yōu)過程中,利用分析結(jié)果調(diào)整審計日志的 blocking queue,調(diào)整 UFS-SYNC-PREFETCH 線程數(shù),調(diào)優(yōu) JVM 參數(shù)。通過實驗證明,Alluxio 吞吐量提升7倍。
最后,本文提出了 Alluxio 吞吐量提升的未來優(yōu)化方向。
編輯:黃飛










 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論