 電子發燒友App
電子發燒友App


前言
內存作為計算機系統的組成部分,跟開發人員的日常開發活動有著密切的聯系,我們平時遇到的Segment Fault、OutOfMemory、Memory Leak、GC等都與它有關。本文所說的內存,指的是計算機系統中的主存(Main Memory),它位于存儲金字塔中CPU緩存和磁盤之間,是程序運行不可或缺的一部分。
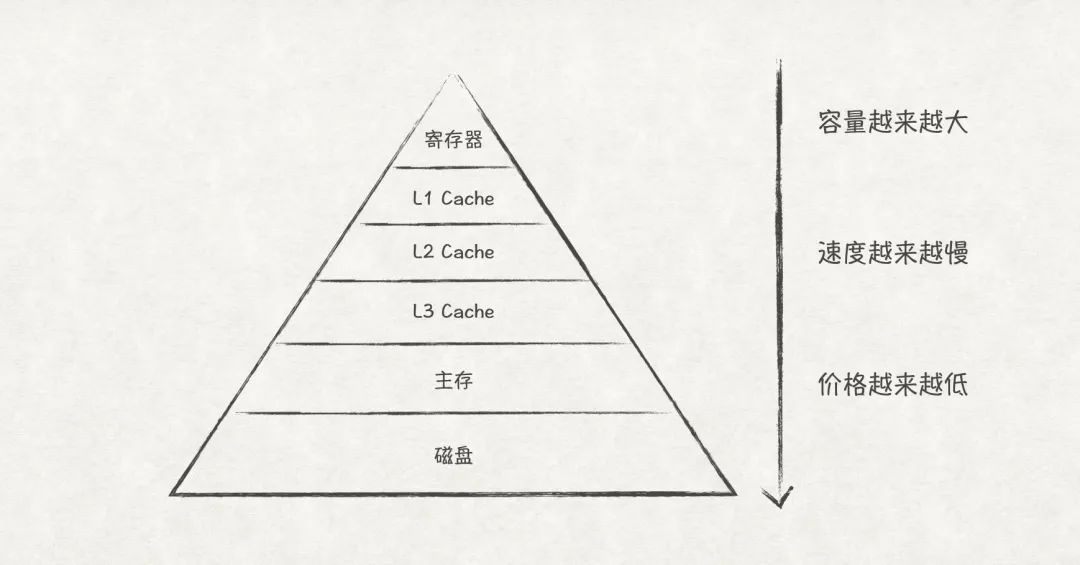 圖1
圖1
在計算機系統中,主存通常都是由操作系統(OS)來管理,而內存管理的細則對開發者來說是無感的。對于一個普通的開發者,他只需懂得如何調用編程語言的接口來進行內存申請和釋放,即可寫出一個可用的應用程序。如果你使用的是帶有垃圾回收機制的語言,如Java和Go,甚至都不用主動釋放內存。但如果你想寫出高效應用程序,熟悉OS的內存管理原理就變得很有必要了。
下面,我們將從最簡單的內存管理原理說起,帶大家一起窺探OS的內存管理機制,由此熟悉底層的內存管理機制,寫出高效的應用程序。
獨占式內存管理
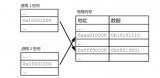
早期的單任務系統中,同一時刻只能有一個應用程序獨享所有的內存(除開OS占用的內存),因此,內存管理可以很簡單,只需在內存上劃分兩個區域:
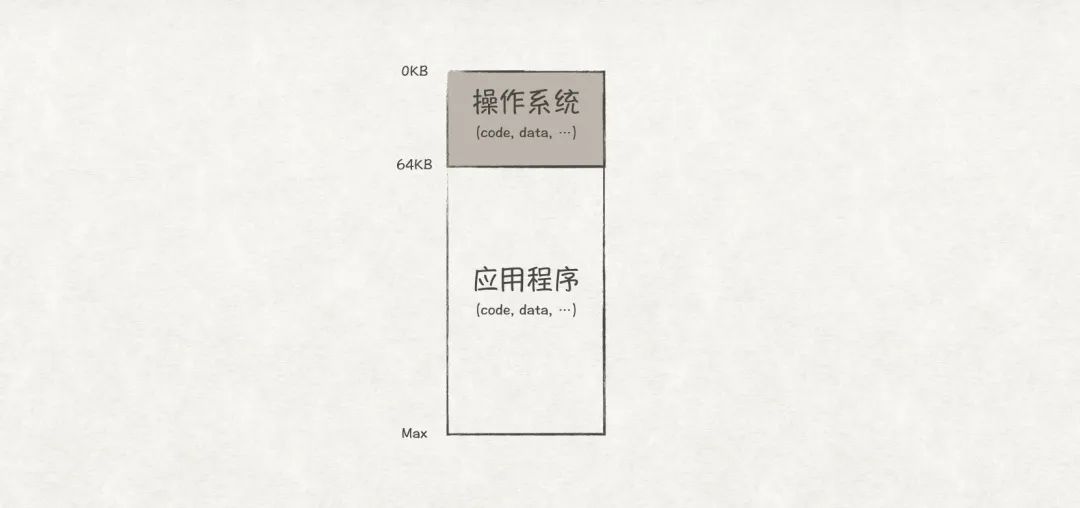 圖2
圖2
在多任務系統中,計算機系統已經可以做到多個任務并發運行。如果還是按照獨占式的管理方式,那么每次任務切換時,都會涉及多次內存和磁盤之間的數據拷貝,效率極其低下:
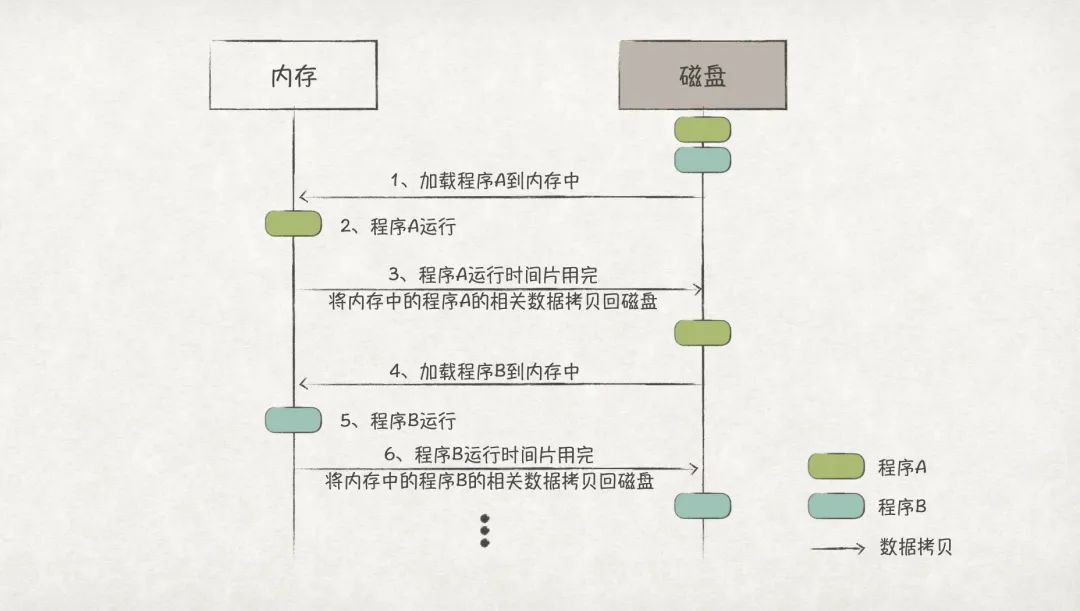 圖3
圖3
最直觀的解決方法就是讓所有程序的數據都常駐在內存中(假設內存足夠大),這樣就能避免數據拷貝了:
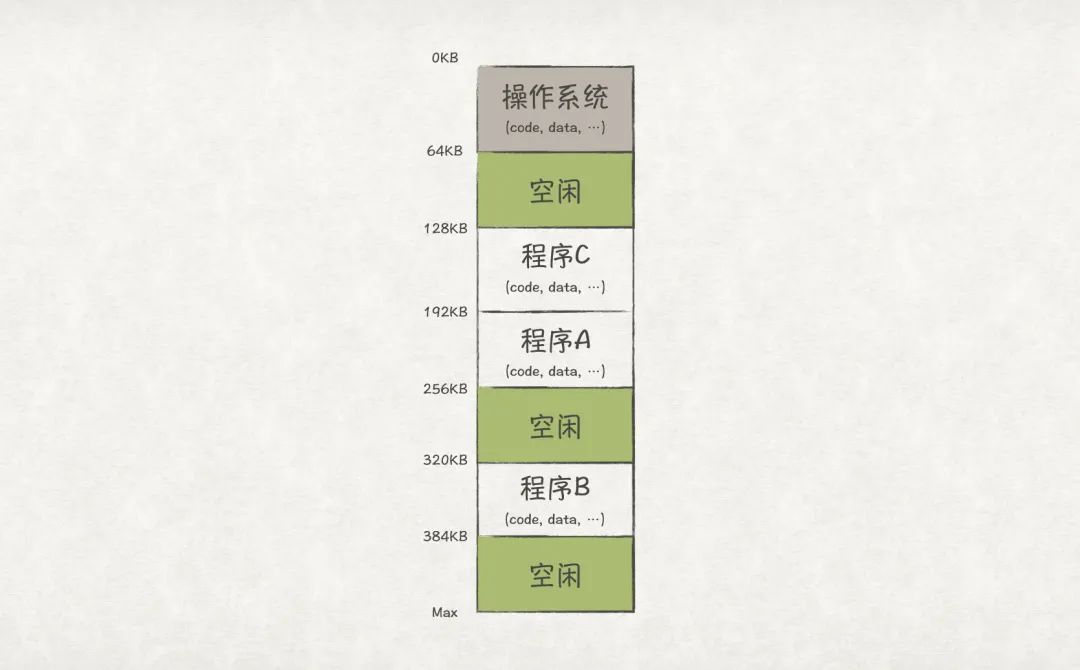 圖4
圖4
但這樣又會帶來另一個問題,程序之間的內存地址空間是沒有隔離的,也就是程序A可以修改程序B的內存數據。這樣的一個重大的安全問題是用戶所無法接受的,要解決該問題,就要借助虛擬化的力量了。
虛擬地址空間
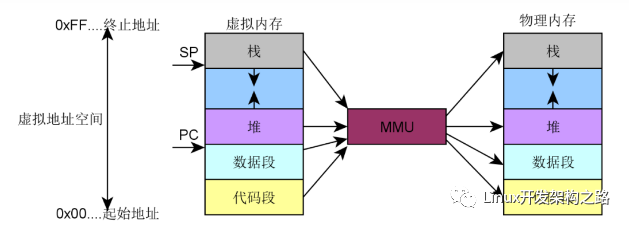
為了實現程序間內存的隔離,OS對物理內存做了一層虛擬化。OS為每個程序都虛擬化出一段內存空間,這段虛擬內存空間會映射到一段物理內存上。但對程序自身而言,它只能看到自己的虛擬地址空間,也就有獨占整個內存的錯覺了。
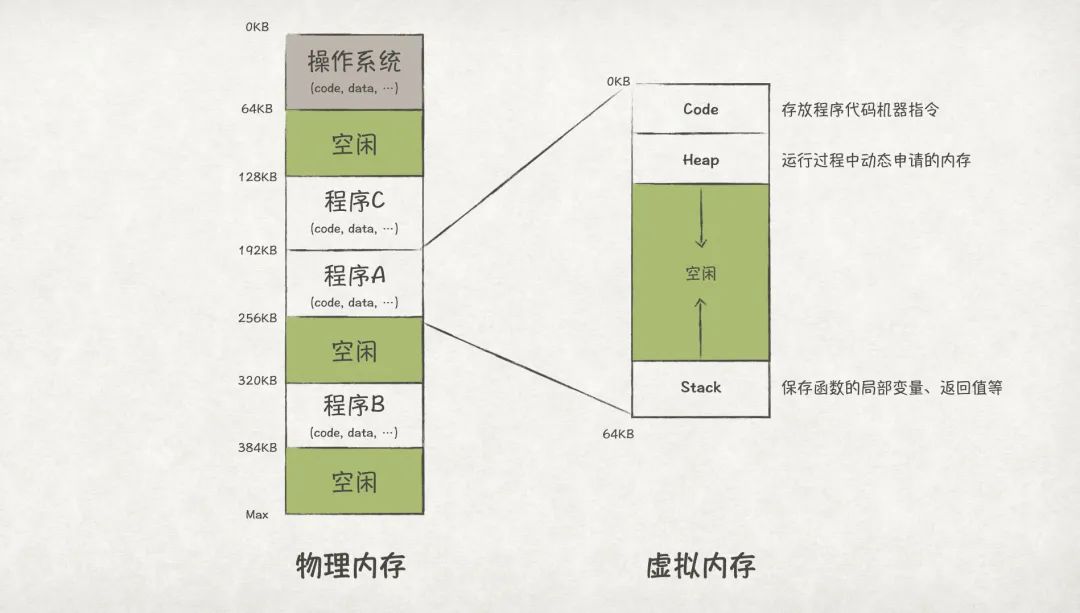 圖5
圖5
上圖中,虛擬內存空間分成了三個區域,其中Code區域存儲的是程序代碼的機器指令;Heap區域存儲程序運行過程中動態申請的內存;Stack區域則是存儲函數入參、局部變量、返回值等。Heap和Stack會在程序運行過程中不斷增長,分別放置在虛擬內存空間的上方和下方,并往相反方向增長。
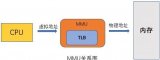
從虛擬地址空間到物理地址空間的映射,需要一個轉換的過程,完成這個轉換運算的部件就是MMU(memory management unit),也即內存管理單元,它位于CPU芯片之內。
要完成從虛擬地址到物理地址到轉換,MMU需要base和bound兩個寄存器。其中base寄存器用來存儲程序在物理內存上的基地址,比如在圖5中,程序A的基地址就是192KB;bound寄存器(有時候也叫limit寄存器)則保存虛擬地址空間的Size,主要用來避免越界訪問,比如圖5中程序A的size值為64K。那么,基于這種方式的地址轉換公式是這樣的:
物理地址 = 虛擬地址 + 基地址
以圖5中程序A的地址轉換為例,當程序A嘗試訪問超過其bound范圍的地址時,物理地址會轉換失敗:
 圖6
圖6
現在,我們再次仔細看下程序A的物理內存分布,如下圖7所示,中間有很大的一段空閑內存是“已申請,未使用”的空閑狀態。這也意味著即使這部分是空閑的,也無法再次分配給其他程序使用,這是一種巨大的空間浪費!為了解決這個內存利用率低下的問題,我們熟悉的段式內存管理出現了。
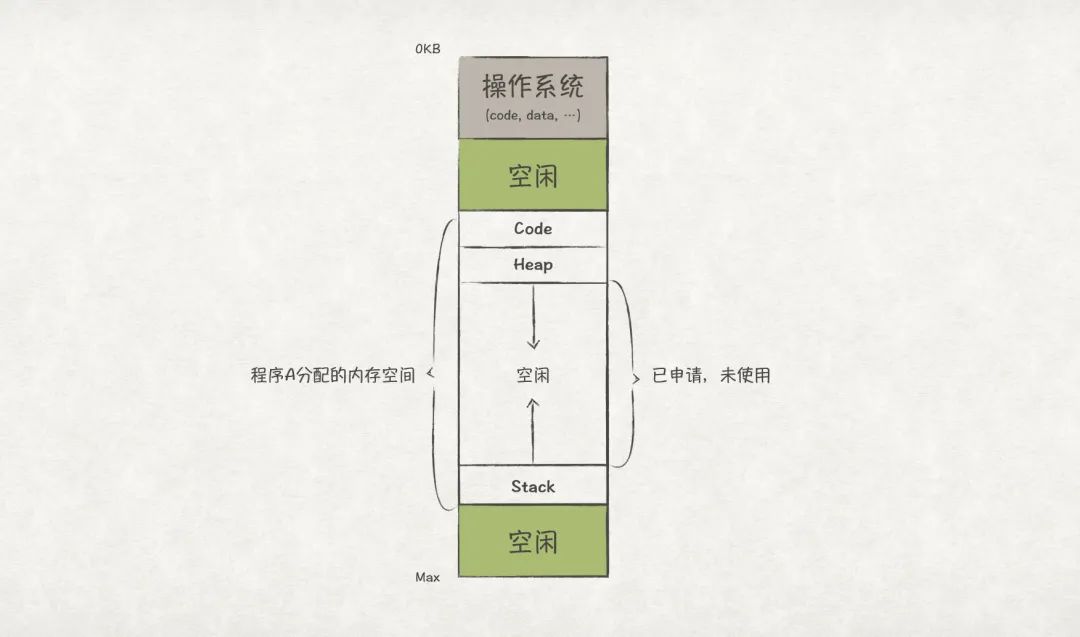 圖7
圖7
段式內存管理
在上一節中,我們發現如果以程序為單位去做內存管理,會存在內存利用率不足的問題。為了解決該問題,段式內存管理被引入。段(Segment)是邏輯上的概念,本質上是一塊連續的、有一定大小限制的內存區域,前文中,我們一共提到過3個段:Code、Heap和Stack。
段式內存管理以段為單位進行管理,它允許OS將每個段靈活地放置在物理內存的空閑位置上,因此也避免了“已申請,未使用”的內存區域出現:
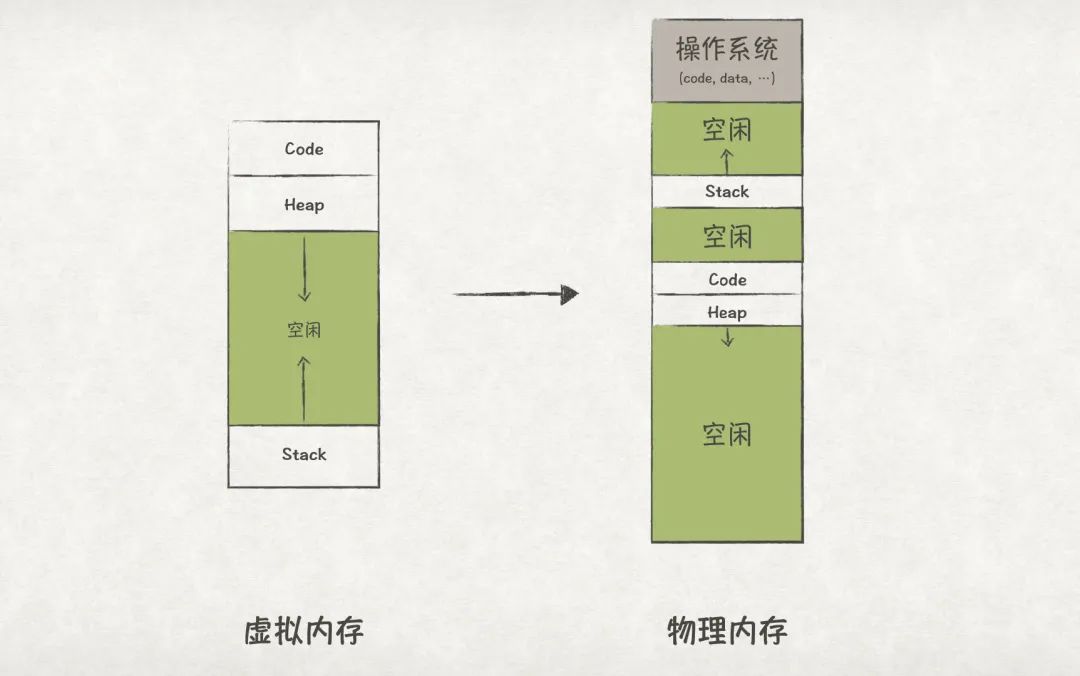 圖8
圖8
地址轉換
從上圖8可知,段式內存管理中程序的物理內存空間可能不再連續了,因此為了實現從虛擬地址到物理地址到轉換,MMU需要為每個段都提供一對base-bound寄存器,比如:
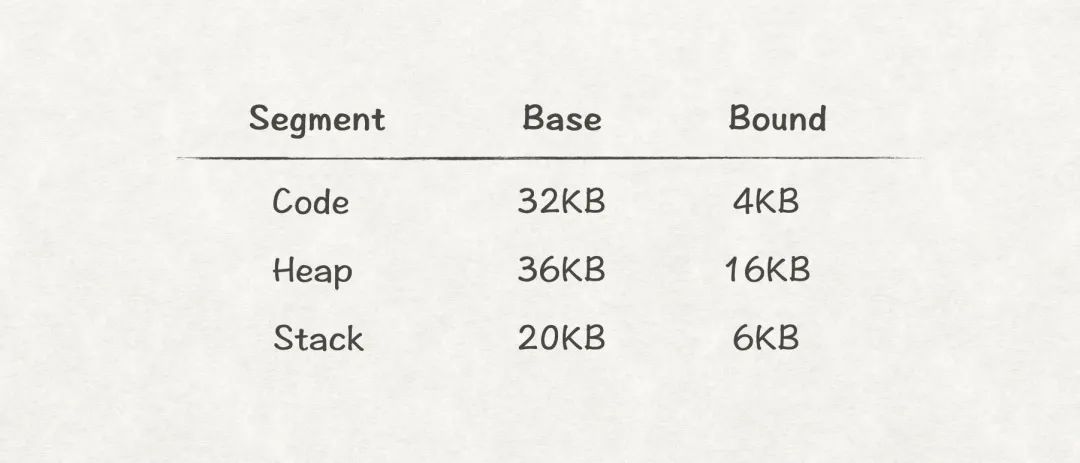 圖9
圖9
給一個虛擬地址,MMU是如何知道該地址屬于哪個段,從而根據對應的base-bound寄存器轉換為對應的物理地址呢?
假設虛擬地址有16位,因為只有3個段,因此,我們可以使用虛擬地址的高2位來作為段標識,比如00表示Code段,01表示Heap段,11表示Stack段。這樣MMU就能根據虛擬地址來找到對應段的base-bound寄存器了:
 圖10
圖10
但這樣還不是能夠順利的將虛擬地址轉換為物理地址,我們忽略了重要的一點:Heap段和Stack段的增長方向是相反的,這也意味著兩者的地址轉換方式是不一樣的。因此,我們還必須在虛擬地址中多使用一位來標識段的增長方向,比如0表示向上(低地址方向)增長,1表示向下(高地址方向)增長:
 圖11
圖11
下面,看一組段式內存管理地址轉換的例子:
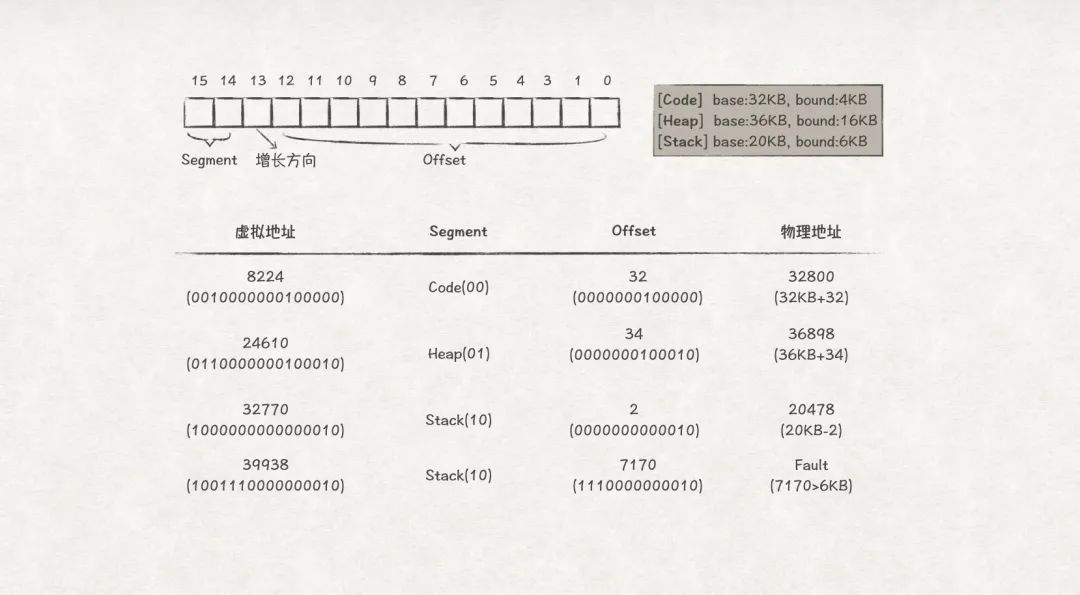 圖12
圖12
那么,總結段式內存管理的地址轉換算法如下:
?
//?獲取當前虛擬地址屬于哪個段 Segment?=?(VirtualAddress?&?SEG_MASK)?>>?SEG_SHIFT //?得到段內偏移量 Offset??=?VirtualAddress?&?OFFSET_MASK //?獲得內存增長的方向 GrowsDirection?=?VirtualAddress?&?GROWS_DIRECTION_MASK //?有效性校驗 if?(Offset?>=?Bounds[Segment]) ????RaiseException(PROTECTION_FAULT) else ????if?(GrowsDirection?==?0)?{ ??????PhysAddr?=?Base[Segment]?+?Offset ????}?else?{ ??????PhysAddr?=?Base[Segment]?-?Offset ????}
?
內存共享和保護
段式內存管理還可以很方便地支持內存共享,從而達到節省內存的目的。比如,如果存在多個程序都是同一個可執行文件運行起來的,那么這些程序是可以共享Code段的。為了實現這個功能,我們可以在虛擬地址上設置保護位,當保護位為只讀時,表示該段可以共享。另外,如果程序修改了只讀的段,則轉換地址失敗,因此也可以達到內存保護的目的。
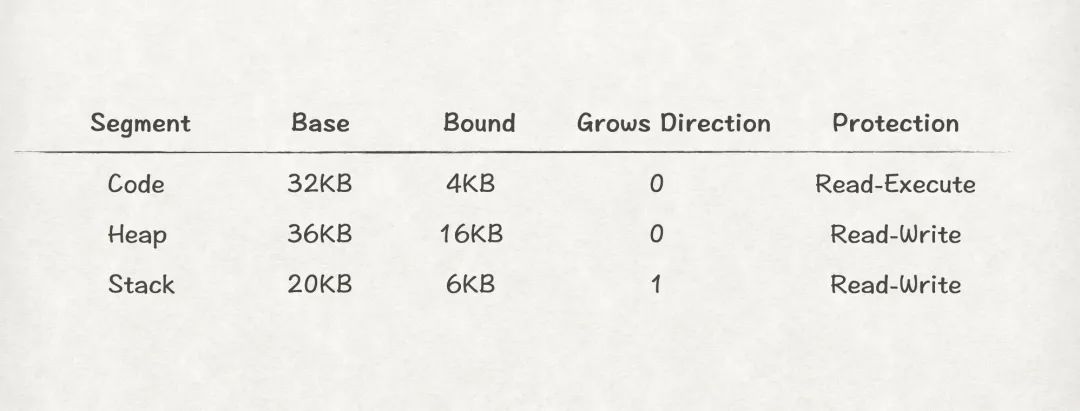 圖13
圖13
內存碎片
段式內存管理的最明顯的缺點就是容易產生內存碎片,這是因為在系統上運行的程序的各個段的大小往往都不是固定的,而且段的分布也不是連續的。當系統的內存碎片很多時,內存的利用率也會急劇下降,對外表現就是雖然系統看起來還有很多內存,卻無法再運行起一個程序。
解決內存碎片的方法之一是定時進行碎片整理:
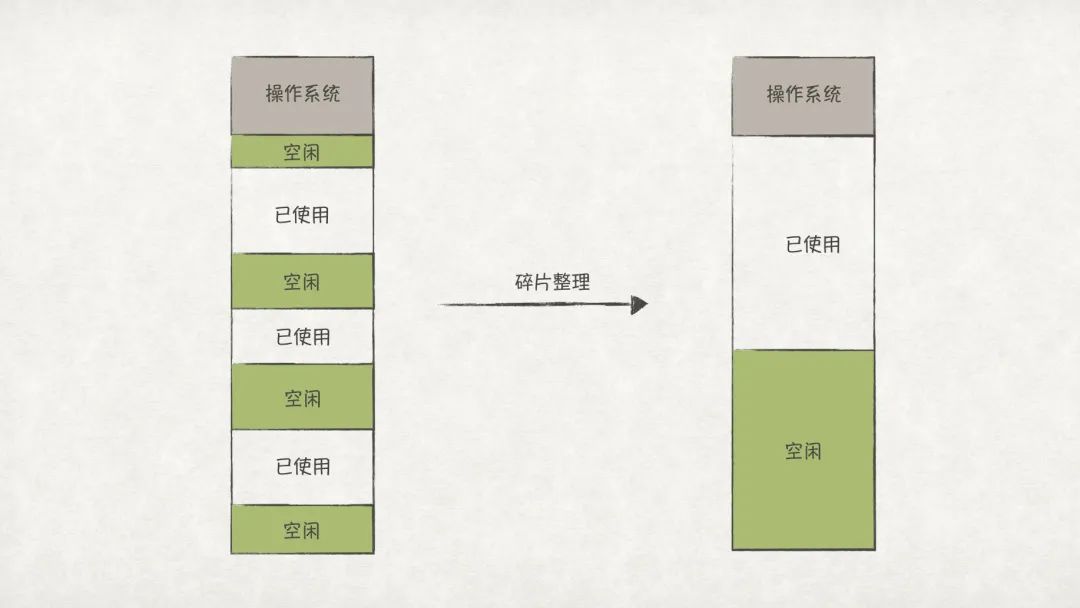 圖14
圖14
但是碎片整理的代價極大,一方面需要進行多次內存拷貝;另一方面,在拷貝過程中,正在運行的程序必須停止,這對于一些以人機交互任務為主的應用程序,將會極大影響用戶體驗。
另一個解決方法就是接下來要介紹的頁式內存管理。
頁式內存管理
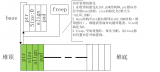
頁式內存管理的思路,是將虛擬內存和物理內存都劃分為多個固定大小的區域,這些區域我們稱之為頁(Page)。頁是內存的最小分配單位,一個應用程序的虛擬頁可以存放在任意一個空閑的物理頁中。
物理內存中的頁,我們通常稱之為頁幀(Page Frame)
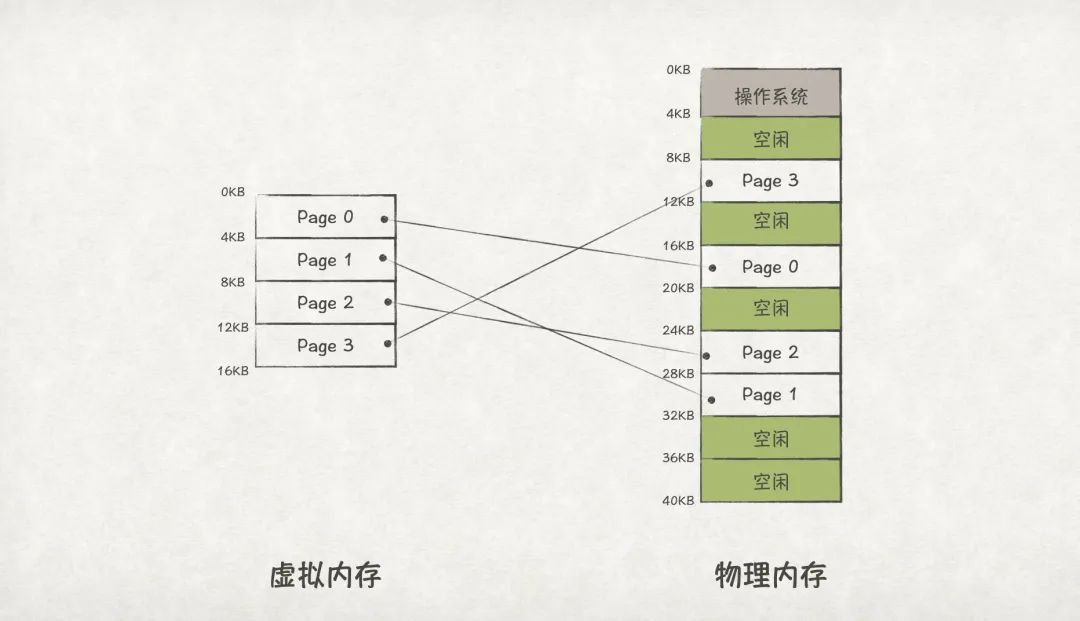 圖15
圖15
因為頁的大小是固定的,而且作為最小的分配單位,這樣就可以解決段式內存管理中內存碎片的問題了。
但頁內仍然有可能存在內存碎片。
地址轉換
頁式內存管理使用頁表(Page Table)來進行虛擬地址到物理地址到轉換,地址轉換的關鍵步驟如下:
1)根據虛擬頁找到對應的物理頁幀
每個虛擬頁都有一個編號,叫做VPN(Virtual Page Number);相應的,每個物理頁幀也有一個編號,叫做PFN(Physical Frame Number)。頁表存儲的就是VPN到PFN的映射關系。
2)找到地址在物理頁幀內的偏移(Offset)
地址在物理頁幀內的偏移與在虛擬頁內的偏移保持一致。
我們可以將虛擬地址劃分成兩部分,分別存儲VPN和Offset,這樣就能通過VPN找到PFN,從而得到PFN+Offset的實際物理地址了。
比如,假設虛擬內存空間大小為64Byte(6位地址),頁的大小為16Byte,那么整個虛擬內存空間一共有4個頁。因此我們可以使用高2位來存儲VPN,低4位存儲Offset:
 圖16
圖16
下面看一個轉換例子,VPN(01)通過頁表找到對應的PFN(111),虛擬地址和物理地址的頁內偏移都是0100,那么虛擬地址010100對應的物理地址就是1110100了。
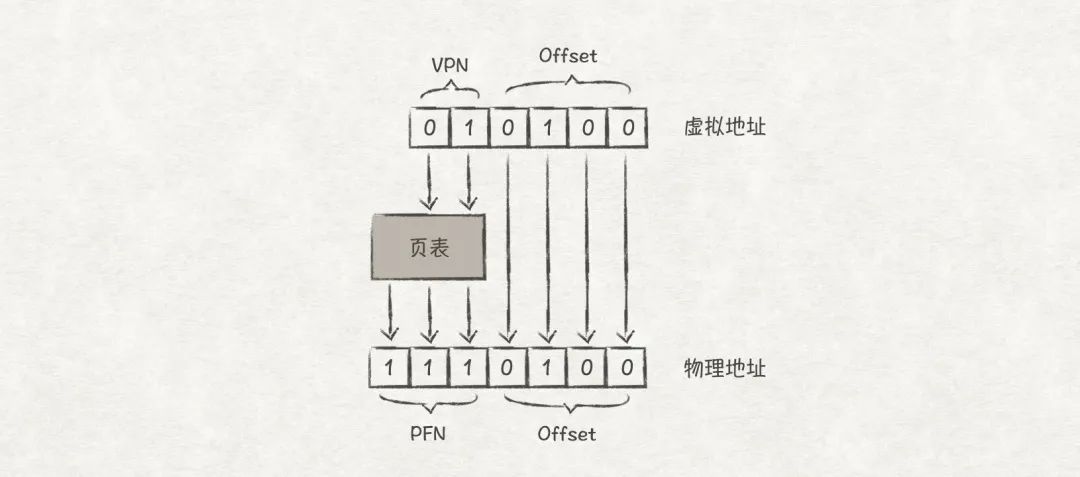 圖17
圖17
頁表和頁表項
OS為每個程序都分配了一個頁表,存儲在內存當中,頁表里由多個頁表項(PTE,Page Table Entry)組成。我們可以把頁表看成是一個數組,數組的元素為PTE:
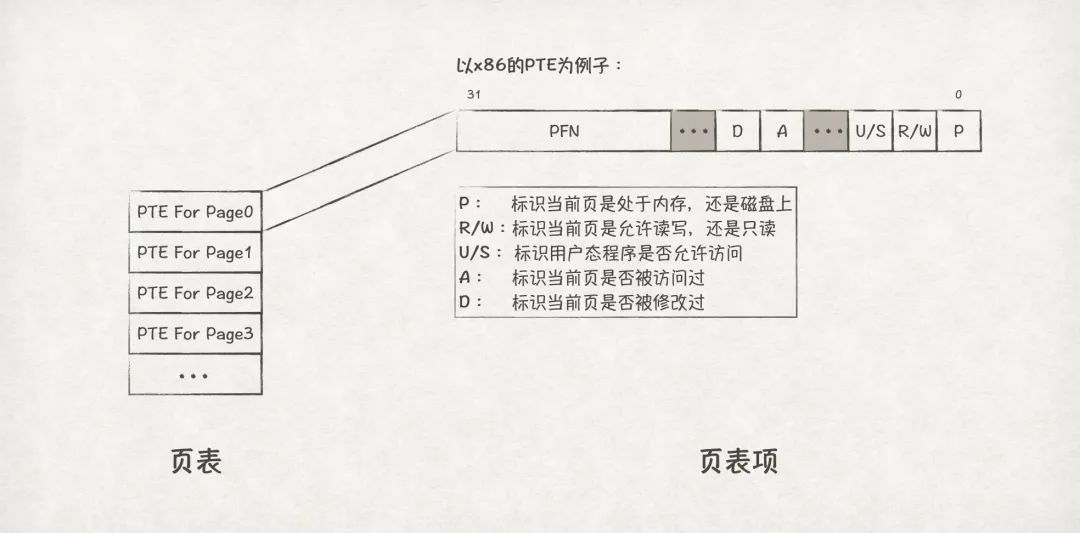 圖18
圖18
以x86系統下的PTE組成為例,PTE一共占32位,除了PFN之外,還有一些比較重要的信息,比如P(Present)標識當前頁是否位于內存上(或是磁盤上);R/W(Read/Write)標識當前頁是否允許讀寫(或是只讀);U/S(User/Supervisor)標識當前頁是否允許用戶態訪問;A(Access)標識當前頁是否被訪問過,在判斷當前頁是否為熱點數據、頁換出時特別有用;D(Dirty)標識當前頁是否被修改過。
頁式內存管理的缺點
地址轉換效率低
根據前文介紹,我們可以總結頁式內存管理機制下地址轉換的算法如下:
?
//?從虛擬地址上得到VPN VPN?=?(VirtualAddress?&?VPN_MASK)?>>?SHIFT //?找到VPN對應的PTE的內存地址 PTEAddr?=?PTBR?+?(VPN?*?sizeof(PTE)) //?訪問主存,獲取PTE PTE?=?AccessMemory(PTEAddr) //?有效性校驗 if?(PTE.Valid?==?False) ????RaiseException(INVALID_ACCESS) else ????//?獲取頁內偏移量 ????offset?=?VirtualAddress?&?OFFSET_MASK ????//?計算得出物理地址 ????PhysAddr?=?(PTE.PFN?<?
我們發現,每次地址轉換都會訪問一次主存來獲取頁表,比段式內存管理(無主存訪問)低效很多。
占用空間大
假設地址空間為32-bit,頁的大小固定為4KB,那么整個地址空間一共有個頁表,也即頁表一共有個PTE。現假設每個PTE大小為4-byte,那么每個頁表占用4MB的內存。如果整個系統中有100個程序在運行,那么光是頁表就占用了400MB的內存,這同樣是用戶無法接受的。
接下來,我們將介紹如何去優化頁式內存管理的這兩個顯著缺點。
讓頁式管理的地址轉換更快
TLB:Translation-Lookaside Buffer
根據前文所述,頁式內存管理地址轉換因為多了一次主存訪問,導致效率很低。如果能夠避免或者減少對主存的訪問,那么就能讓地址轉換更快了。
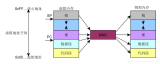
很多人應該都可以想到通過增加緩存的方式提升效率,比如為避免頻繁查詢磁盤,我們一般在內存中增加一層緩存來提升數據訪問效率。那么為了提升訪問主存中數據的效率,自然應該在離CPU更近的地方增加一層緩存。這個離CPU更近的地方,就是前文提到的位于CPU芯片之內的MMU。而這個高速緩存,就是TLB(Translation-Lookaside Buffer),它緩存了VPN到PFN到映射關系,類似于這樣:
圖19
增加TLB之后,地址轉換的算法如下:
?
VPN?=?(VirtualAddress?&?VPN_MASK)?>>?SHIFT (Success,?TlbEntry)?=?TLB_Lookup(VPN) if?(Success?==?True)???//?TLB?Hit ????if?(CanAccess(TlbEntry.ProtectBits)?==?True) ????????Offset???=?VirtualAddress?&?OFFSET_MASK ????????PhysAddr?=?(TlbEntry.PFN?<?
從上述算法可以發現,在TLB緩存命中(TLB Hit)時,能夠避免直接訪問主存,從而提升了地址轉換的效率;但是在TLB緩存不命中(TLB Miss)時,仍然需要訪問一次主存,而且還要往TLB中插入從主存中查詢到的PFN,效率變得更低了。因此,我們必須盡量避免TLB Miss的出現。
更好地利用TLB
下面,我們通過一個數組遍歷的例子來介紹如何更好地利用TLB。
假設我們要進行如下的一次數組遍歷:
?
int?sum?=?0; for?(i?=?0;?i??
數組的內存的分布如下:
圖20
a[0]~a[2]位于Page 5上,a[3]~a[6]位于Page 6上,a[7]~a[8]位于Page 7上。當我們首先訪問a[0]時,由于Page 5并未在TLB緩存里,所以會先出現一次TLB Miss,接下來的a[1]和a[2]都是TLB Hit;同理,訪問a[3]和a[7]時都是TLB Miss,a[4]~a[6]和a[8]~a[9]都是TLB Hit。所以,整個數組遍歷下來,TLB的緩存命中情況為:Miss,Hit,Hit,Miss,Hit,Hit,Hit,Miss,Hit,Hit,TLB緩存命中率為70%。我們發現,訪問同一頁上的數據TLB的緩存更易命中,這就是空間局部性的原理。
接下來,我們再次重新遍歷一次數組,由于經過上一次之后Page 5 ~ Page 7的轉換信息已經在TLB緩存里里,所以第二次遍歷的TLB命中情況為:Hit,Hit,Hit,Hit,Hit,Hit,Hit,Hit,Hit,Hit,TLB緩存命中率為100%!這就是時間局部性的原理,短時間內訪問同一內存數據也能夠提升TLB緩存命中率。
TLB的上下文切換
因為TLB緩存的是當前正在運行程序的上下文信息,當出現程序切換時,TLB里面的上下文信息也必須更新,否則地址轉換就會異常。解決方法主要有2種:
方法1:每次程序切換都清空TLB緩存(Flush TLB),讓程序在運行過程中重新建立緩存。
方法2:允許TLB緩存多個程序的上下文信息,并通過ASID(address space identifier,地址空間標識符,可以理解為程序的PID)做區分。
方法1實現簡單,但是每次程序切換都需要重新預熱一遍緩存,效率較低,主流的做法是采用方法2。
需要注意的是TLB是嵌入到CPU芯片之內的,對于多核系統而言,如果程序在CPU之間來回切換,也是需要重新建立TLB緩存!因此,把一個程序綁定在一個固定的核上有助于提升性能。
讓頁表更小
大頁內存
降低頁表大小最簡單的方法就是讓頁更大。前文的例子中,地址空間為32-bit,頁的大小為4KB,PTE的大小為4-byte,那么每個頁表需要4MB的內存空間。現在,我們把頁的大小增加到16KB,其他保持不變,那么每個頁表只需要個PTE,也即1MB內存,內存占用降低了4倍。
大頁內存對TLB的使用也有優化效果,因TLB能夠緩存的上下文數量是固定的,當頁的數量更少時,上下文換出的頻率會降低,TLB的緩存命中率也就增加了,從而讓地址轉換的效率更高。
段頁式內存管理
根據前文所述,程序的地址空間中,堆與棧之間的空間很多時候都是處于未使用狀態。對應到頁表里,就是有很大一部分的PTE是invalid狀態。但因為頁表要涵蓋整個地址空間的范圍,這部分invalid的PTE只能留在頁表中,從而造成了很大的空間浪費。
圖21
前文中,我們通過段式內存管理解決了堆與棧之間內存空間的浪費問題。對應到頁表中,我們也可以為頁式內存管理引入段式管理的方式,也即段頁式內存管理,解決頁表空間浪費的問題。
具體的方法是,為程序的地址空間劃分出多個段,比如Code、Heap、Stack等。然后,在每個段內單獨進行頁式管理,也即為每個段引入一個頁表:
圖22
從上圖可知,將頁表分段之后,頁表不再需要記錄那些處于空閑狀態的頁的PTE,從而節省了內存空間的消耗。
多級頁表
降低頁表大小另一個常見的方法就是多級頁表(Multi-level Page Table),多級頁表的思路也是減少處于空閑狀態的頁的PTE數量,但方法與段頁式內存管理不同。如果說段頁式內存管理可以看成是將頁表分段,那么多級頁表則可以看成是將頁表分頁。
具體的做法是將頁表按照一定大小分成多個部分(頁目錄,Page Directory,PD),如果某個頁目錄下所有的頁都是處于空閑狀態,則無須為該頁目錄下的頁申請PTE。
以二級頁表為例,下圖對比了普通頁表和多級頁表的構成差異:
圖23
下面,我們再對比一下普通頁表和多級頁表的空間消耗。還是假設地址空間為32-bit,頁的大小為4KB,PTE的大小為4-byte,一共有個頁,那么普通頁表需要4MB的內存空間。現在,我們將個頁切分為份,也即有個頁目錄,每個頁目錄下管理個頁,也即有個PDE(Page Directory Entry)。假設PDE也占4-byte內存,且根據20/80定律假設有80%的頁處于空閑狀態,那么二級頁表只需要0.804MB!()
由此可見,多級頁表能夠有效降低頁表的內存消耗。多級頁表在實際運用中還是較為常見的,比如Linux系統采用的就是4級頁表的結構。
Swap Sapce: 磁盤交換區
到目前為止,我們都是假設物理內存足夠大,可以容納所有程序的虛擬內存空間。然而,這往往是不切實際的,以32-bit地址空間為例,一個程序的虛擬內存為4G,假設有100個程序,那么一共需要400G的物理內存(忽略共享部分)!另外,程序運行過程中,并不是一直都需要所有的頁,很多時候只需要其中的一小部分。
因此,如果我們可以先把那些暫時用不到的頁先存在磁盤上,等需要用到時再加載到內存上,那么就可以節省很多物理內存。磁盤中用來存放這些頁的區域,被稱作Swap Sapce,也即交換區。
圖24
在這種機制之下,當程序訪問某一個地址,而這個地址所在的頁又不在內存上時,就會觸發缺頁(Page Fault)中斷。就像TLB緩存不命中時會帶來額外的開銷一樣,缺頁也會導致內存的訪問效率降低。因為在處理缺頁中斷時,OS必須從磁盤交換區上把數據加載到內存上;而且當空閑內存不足時,OS還必須將內存上的某些頁換出到交換區中。這一進一出的磁盤IO訪問也直接導致缺頁發生時,內存訪問的效率下降許多。
因此,在空閑內存不足時,頁的換出策略顯得極為重要。如果把一個即將要被訪問的頁換出到交換區上,就會帶來本可避免的無謂消耗。頁的換出策略很多,常見的有FIFO(先進先出)、Random(隨機)、LRU(最近最少使用)、LFU(最近最不經常使用)等。在常見的工作負載下,FIFO和Random算法的效果較差,實際用的不多;LRU和LFU算法都是建立在歷史內存訪問統計的基礎上,因此表現較前兩者好些,實際應用也多一些。目前很多主流的操作系統的頁換出算法都是在LRU或LFU的基礎上進行優化改進的結果。
最后
本文主要介紹了OS內存管理的一些基本原理,從獨占式內存管理,到頁式內存管理,這過程中經歷了許多次優化。這其中的每一種優化手段,都朝著如下3個目標前進:
1、透明化(transparency)。內存管理的細節對程序不可見,換句話說,程序可以自認為獨占整個內存空間。
2、效率(efficiency )。地址轉換和內存訪問的效率要高,不能讓程序運行太慢;空間利用效率也要高,不能占用太多空閑內存。
3、保護(protection)。保證OS自身不受應用程序的影響;應用程序之間也不能相互影響。
當然,目前主流的操作系統(如Linux、MacOS等)的內存管理機制要比本文介紹的原理復雜許多,但本質原理依然離不開本文所描述的幾種基礎的內存管理原理。
審核編輯:湯梓紅













 工商網監
工商網監
評論