 電子發(fā)燒友App
電子發(fā)燒友App


【1】8位、16位、32位、64位
除了 CISC與 RISC 之分,處理器指令集架構(gòu)的位數(shù)也是一個重要的概念。通俗來講處理器架構(gòu)的位數(shù)是指通用寄存器的寬度,其決定了尋址范圍的大小、數(shù)據(jù)運算能力的強弱譬如32位架構(gòu)的處理器,其通用寄存器的寬度為 32位,能夠?qū)ぶ返姆秶鸀?232Byte,即4GB的尋址空間,運算指令可以操作的操作數(shù)為 32 位。
注意:處理器指令集架構(gòu)的寬度和指令的編碼長度無任何關(guān)系。并不是說 64 位架構(gòu)的指令長度為 64位(這是一個常見的誤區(qū))。從理論上來講,指令本身的編碼長度越短越好因為可以節(jié)省代碼的存儲空間。因此即便在64 位的架構(gòu)中,也大量存在16位編碼的指
且基本上很少出現(xiàn)過 64 位長的指令編碼。
綜上所述,在不考慮任何實際成本和實現(xiàn)技術(shù)的前提下,理論上來講:。通用寄存器的寬度,即指令集架構(gòu)的位數(shù)越多越好,因為這樣可以帶來更大的尋址范圍和更強的運算能力。
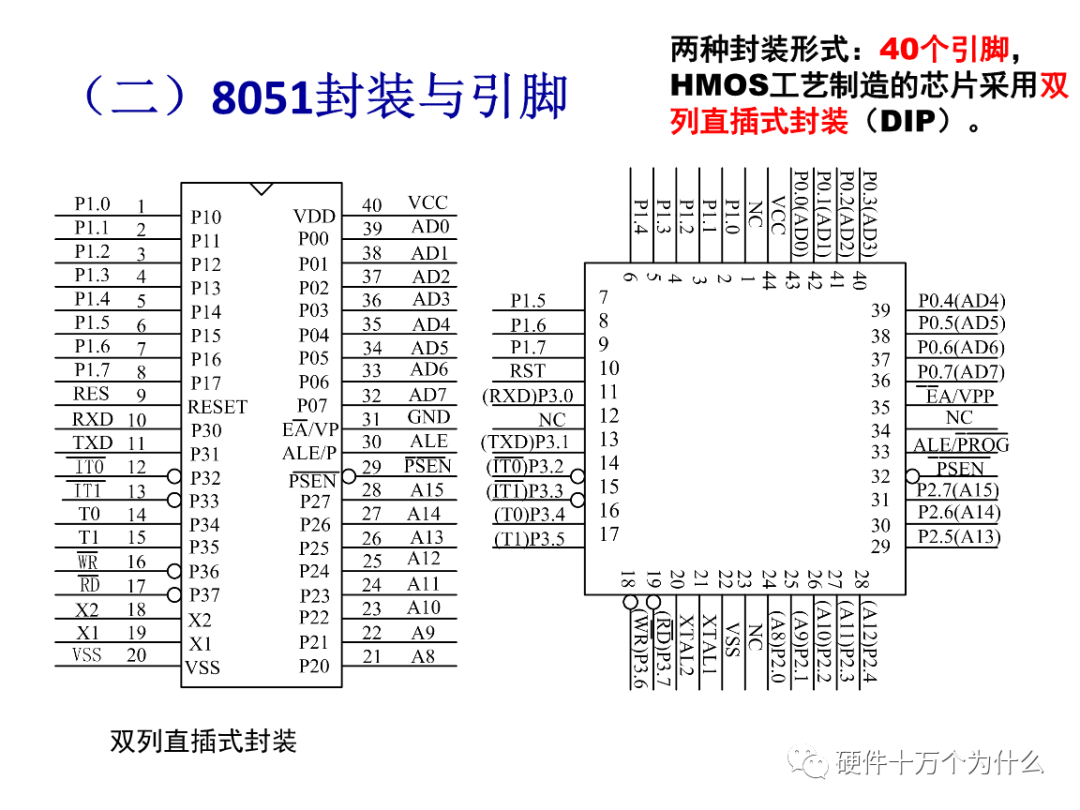
指令編碼的長度越短越好,因為這樣可以更加節(jié)省代碼的存儲空間常見的架構(gòu)位數(shù)分為8位、16位、32位和64位。早期的單片機以8位和 16 位為主,知名的 8051 單片機是使用廣泛的8位架構(gòu)。
?
?
目前主流的嵌入式微處理器均在向 32 位架構(gòu)轉(zhuǎn)移。
目前主流的移動手持、個人計算機和服務(wù)器領(lǐng)域,均使用 64 位架構(gòu)。
【2】CISC、RISC
常見的指令集架構(gòu)大體上可以分為兩大類:復雜指令集體系(CISC)和精簡指令集體系(RISC)。
RISC全稱Reduced Instruction Set Compute,精簡指令集計算機。
CISC全稱Complex Instruction Set Computers,復雜指令集計算機。
CISC既有簡單指令也有復雜指令,后來人們發(fā)現(xiàn)典型程序中80%的語句都是使用計算機中20%的指令,而這20%的指令都屬于簡單指令;因此花再多時間去研究復雜指令,也僅僅只有20%的使用概率,并且復雜指令會影響計算機的執(zhí)行速度。既然典型程序的80%都是使用簡單指令完成,那剩下的20%語句用簡單語句來重新組合一下模擬這些復雜指令就行了,而不需要使用這些復雜指令,于是RISC就出現(xiàn)了。
RISC的主要特點:
1)選取使用頻率較高的一些簡單指令以及一些很有用但不復雜的指令,讓復雜指令的功能由使用頻率高的簡單指令的組合來實現(xiàn)。
2)指令長度固定,指令格式種類少,尋址方式種類少。
3)只有取數(shù)/存數(shù)指令訪問存儲器,其余指令的操作都在寄存器內(nèi)完成。
4)CPU中有多個通用寄存器(比CICS的多)
5)采用流水線技術(shù)(RISC一定采用流水線),大部分指令在一個時鐘周期內(nèi)完成。采用超標量超流水線技術(shù),可使每條指令的平均時間小于一個時鐘周期。
6)控制器采用組合邏輯控制,不用微程序控制。
7)采用優(yōu)化的編譯程序
CICS的主要特點:
1)指令系統(tǒng)復雜龐大,指令數(shù)目一般多達200~300條。
2)指令長度不固定,指令格式種類多,尋址方式種類多。
3)可以訪存的指令不受限制(RISC只有取數(shù)/存數(shù)指令訪問存儲器)
4)各種指令執(zhí)行時間相差很大,大多數(shù)指令需多個時鐘周期才能完成。
5)控制器大多數(shù)采用微程序控制。
6)難以用優(yōu)化編譯生成高效的目標代碼程序
RISC與CICS的比較
1.RISC比CICS更能提高計算機運算速度;RISC寄存器多,就可以減少訪存次數(shù),指令數(shù)和尋址方式少,因此指令譯碼較快。
2.RISC比CISC更便于設(shè)計,可降低成本,提高可靠性。
3.RISC能有效支持高級語言程序。
4.CICS的指令系統(tǒng)比較豐富,有專用指令來完成特定的功能,因此處理特殊任務(wù)效率高。
復雜指令集最常見的例子是現(xiàn)在絕大多數(shù)家用計算機和網(wǎng)絡(luò)服務(wù)器所使用的 AMD64 指令集(也叫 x86-64、x86_64、Intel 64、EM64T 等等,本文以發(fā)明人為基準稱為 AMD64。)除此以外有一定使用量,和有歷史意義的復雜指令集還有 IA-32、MC68000、MOS6502、Intel 8051、Intel 8080 等等。復雜指令集其復雜在于指令種類數(shù)量巨大,非常多次常用到不常用的功能都會被整合進處理器指令集中。同時復雜指令集系統(tǒng)每條指令的操作數(shù)尋址方式復雜,幾乎所有指令都可以直接訪問內(nèi)存;相應(yīng)的指令的機器碼編碼方式復雜,普遍使用不定長指令等。同時,復雜指令集系統(tǒng)一般沒有獨立的專用內(nèi)存訪問指令,處理器內(nèi)所設(shè)置的通用寄存器數(shù)量也偏少。(例如 IA-32 沒有嚴格意義上的通用整數(shù)寄存器,到了 AMD64 也才勉強設(shè)置了八個通用整數(shù)寄存器。)
精簡指令集最常見的例子則是常見于智能設(shè)備和嵌入式平臺的 ARM 指令集家族。除此以外除此以外有一定使用量,和有歷史意義的精簡指令集還有龍芯 LoongArch、MIPS、RISC-V、PowerPC、AVR 等等。精簡指令集其精簡在于指保留最基本最必要的指令,將復雜功能完全交給上層的軟件算法和下層的專用外設(shè)去解決。同時精簡指令集系統(tǒng)指令尋址方式往往非常單一,除了專門的訪存指令以外所有指令都只能在寄存器范圍內(nèi)操作,相應(yīng)的精簡指令集系統(tǒng)普遍使用固定長度指令,也會配備相對比較多的通用寄存器。(例如上個世紀的 ARMv4T、MIPS32 就都已經(jīng)有 29~31 個通用寄存器了,相比于同時期 IA-32 的 0 個。)
實際到了應(yīng)用層面上,對于高級語言程序來說,對于處理器設(shè)計來說,兩種指令集架構(gòu)分類的實際差異已經(jīng)不大了。Intel 和 AMD 的 AMD64 實現(xiàn)都使用了微代碼,而從復雜指令翻譯出來的微代碼普遍都用了類 RISC 設(shè)計。本世紀初的時候還普遍認為復雜指令集處理器速度更快,到了現(xiàn)在精簡指令集已經(jīng)很強大了,完全比CISC更快。有些CISC最終也是轉(zhuǎn)化為RISC進行執(zhí)行了。
【3】8位的CISC——8051
8位和CISC兩個似乎是矛盾的,但是8051活生生的輝煌了40年。
說起 8051 內(nèi)核,幾乎無人不知無人不曉。8051 作為一款生了數(shù)十年之久的微處理器內(nèi)核,在8位入式微處理器內(nèi)核領(lǐng)域,它是當之無愧的傳“前輩”
自從Inlel于1980年為入式系統(tǒng)開發(fā)Intel MCS-51(通常簡稱 8051)單芯片微控制(單片機)至今,8051 內(nèi)核架構(gòu)已經(jīng)走過將近 40個年頭。Intel 還以專利轉(zhuǎn)讓的形式8051內(nèi)核轉(zhuǎn)讓給了許多其他半導體公司,這些公司進一步發(fā)展出不同型號基于 8051內(nèi)核微控制器芯片,因此形成了一個龐大的 8051 家族。
幾十年發(fā)展下來的龐大的用戶群和生態(tài)環(huán)境,以及多年來眾多備受肯定的成功產(chǎn)品,可以說 8051內(nèi)核幾乎成為8 位微處理器內(nèi)核的業(yè)界標桿。8051 內(nèi)核架構(gòu)在 1998 年失去專利保護,久經(jīng)沙場的它再次進發(fā)出強大的二次生命力,各種形式的 8051 架構(gòu) MCU(微控制器Microcontroller Unit)進一步涌入市場,各種基于 8051內(nèi)核的芯片產(chǎn)品層出不窮,各種免費版本的 8051 內(nèi)核IP 也可以從各種渠道獲取。
當然由于 8051 內(nèi)核并沒有一個統(tǒng)一的組織和標準進行管理,所以也存在著體系結(jié)構(gòu)浪亂,各種增強型復雜多樣的問題。雖然時常也都自稱為 8051 內(nèi)核,但是其實各有差別,瑯滿目讓人難以分辨。但是這絲毫不影響 8051 內(nèi)核的經(jīng)典地位,時至今日,雖然目前微處理器內(nèi)核正在經(jīng)歷著向32位架構(gòu)遷移的大趨勢,但是 8051內(nèi)核仍然有著舉足輕重的地位在大量的MCU、數(shù)模混合信號芯片、SoC 芯片中仍能看到 8051 內(nèi)核的身影,并且在相當長的時間內(nèi),在適合8位架構(gòu)處理器內(nèi)核的應(yīng)用領(lǐng)域中都將繼續(xù)使用 8051 內(nèi)核,可以說是“廉頗雖老,尚能飯也”。
8051 內(nèi)核能在嵌入式領(lǐng)域取得如此成功的地位,可以歸功于如下幾個方面的原因。
廣泛的被認知度,簡單的體系結(jié)構(gòu)。
沒有知識產(chǎn)權(quán)的限制,商業(yè)和開源的版本眾多,非常適合中小型芯片公司采用。
用龐大的用戶群以及相應(yīng)的生態(tài)系統(tǒng)。
成熟且免費的軟件工具鏈支持。
——你似乎感受到RISC-V從其一誕生就符合以上幾條的氣質(zhì)。
盡管如此,8051作為一款誕生了接近 40 年的8位CISC(復雜指令集)架構(gòu)內(nèi)核,雖然是“老驥伏析,壯心不已”,但是由于其性能低下,尋址范圍受限,已經(jīng)難以適應(yīng)更多的新興應(yīng)用領(lǐng)域。隨著IoT的發(fā)展和崛起,雖然嵌入式領(lǐng)域?qū)τ谔幚砥鲀?nèi)核的需求更加井噴,但是更多的是開始采用 32 位架構(gòu),且很多傳統(tǒng)的 8 位應(yīng)用領(lǐng)域也在開始向著32位架構(gòu)遷移。這樣ARM的Cortex-M系列有了成長的機會。
然而在20世紀80年代該單片機剛剛問世時,半導體的制造工藝還只能達到um 級,處理器所能達到的時鐘頻率偏低。而且當時硬件設(shè)計語言還處于起步階段也缺乏自動設(shè)計的工具,軟件多以手工匯編編程為主。這就導致流水線設(shè)計的優(yōu)勢無法得到發(fā)揮,并且每條指令需要多個時鐘周期才能完成。由于上述原因,當時的指令集設(shè)計往往具有以下特點:
(1)盡量在每條指令中實現(xiàn)更多的功能。例如 8051的CJNE 指令,就需要在一條指令中依次實現(xiàn):
①與累加器做減法
②修改進位標示
③將結(jié)果做相等比較
④根據(jù)比較結(jié)果決定是否跳轉(zhuǎn)
(2)指令集龐大,以實現(xiàn)更多的復雜功能。例如 8051 雖然是 8 位單片機其指令集卻包含高達 255 種不同的指令和格式
(3)由于以上兩點,導致變長指令的出現(xiàn),以提高內(nèi)存利用率。8051的指令就有單字節(jié)、雙字節(jié)與三字節(jié)三種不同的種類,而且除了對指令解碼以外,沒有其他的手段幫助判定指令長度。
(4)尋址方式眾多。例如在 8051 指令集中,對數(shù)值的操作包括如下方式
①立即數(shù)尋址。將常數(shù)包含在指令中。
②?直接尋址。將內(nèi)存地址包含在指令中。
③間接尋址。將內(nèi)存地址放入寄存器中,然后將寄存器地址包含在指令中.
④寄存器尋址。將操作數(shù)放入寄存器中,然后將寄存器地址包含在指令中
【4】8051具備CISC的所有缺點
1)盡量在每條指今中實現(xiàn)更多的功能
為了在實現(xiàn)這些復雜功能的同時保持高吞吐率,流水線的設(shè)計者不得不花更多的時間規(guī)劃流水線的各級。即便如此,有些指令依然無法實現(xiàn)單周期吞吐,例如上文提到的CJNE 指令,就需要兩個時鐘周期。
另外,現(xiàn)代的8051 處理器開發(fā),早已經(jīng)采用C語言代替了早期的匯編語言而高級語言的編譯器往往很難把這類復雜、多功能機器指令的威力全部發(fā)揮出來有違當初指令集的設(shè)計初衷。
當然,指令集復雜這個特點也并非一無是處。由于 CISC 指令集的指令復雜也使得其代碼密度(Code Density)一般要優(yōu)于同等字寬的RISC處理器
2)龐大的指令集浪費邏輯資源
龐大的指令集必然導致指令的解碼階段變得更為復雜,需要耗費更多的邏輯資源。指令集被分為兩部分對它們各自的解碼分別占用了流水線的一級。這樣設(shè)計的原因之一就是為了在龐大指令集下實現(xiàn)高吞吐率、高時鐘頻率,而不得不做出的妥協(xié)。同樣時鐘頻率的RISC-V處理器,由于指今集比較精簡,就無須做這樣的妥協(xié),從而大大節(jié)省了邏輯資源,簡化了流水線設(shè)計。
3)變長指令的出現(xiàn),以提高內(nèi)存利用率
8051的指令有單字節(jié)、雙字節(jié)和三字節(jié)三種不同的種類,除解碼(Decode)外沒有其他的手段幫助判定指令長度。這種變長的指令結(jié)構(gòu),導致指令之間的邊界很難判定,甚至有可能導致內(nèi)存的非對齊讀取(Unaligned Memory Access),從而對流水線的取指器(Instruction Fetch)設(shè)計帶來挑戰(zhàn)。
8051的內(nèi)存架構(gòu)是哈佛架構(gòu),其代碼與數(shù)據(jù)在不同的地址空間中分開存放。這就使得代碼存儲部分可以單獨做一些優(yōu)化設(shè)計。
由于8051指令集沒有其他輔助手段來幫助判定指令長度,為了確定指令的邊界,8051的取指器不得不為此花費比 RISC-V 更多的邏輯資源
4)眾多的尋址方式
由于8051存在眾多的尋址方式,使得指令集中的許多指令都可以訪間內(nèi)存這導致流水線的數(shù)據(jù)沖突(Data Hazard)很難判斷,有時不得不通過硬件自動插入空操作(Null Operation,NOP)來保持數(shù)據(jù)的正確和完整。這樣既消耗了邏輯資源,又降低了流水線的效率,從而對功耗和性能造成雙重打擊。
審核編輯:湯梓紅











 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論