 電子發(fā)燒友App
電子發(fā)燒友App


1. 綜述
本系列文章旨在解構(gòu)內(nèi)核 perf 框架的實(shí)現(xiàn)。perf 是一個(gè)龐大的系統(tǒng),所涉及的邏輯板塊非常多,因此想要把 perf 框架講清楚是不容易的。為了讓讀者能建立起清晰的脈絡(luò),本系列文章會(huì)根據(jù)一定的內(nèi)在邏輯,逐步展開對(duì)各板塊的解構(gòu)。 perf 框架其本身因?yàn)榭紤]了很多 general 的需求,比如子任務(wù)繼承父任務(wù)的 event、perf 框架后端可對(duì)接多種 PMU、既支持 per-cpu 亦支持 per-task 的 event 監(jiān)控、既支持 counting(計(jì)數(shù))模式亦支持 sampling(采樣)模式,等等,這些會(huì)給解構(gòu) perf 框架帶來不必要的麻煩。為強(qiáng)干弱枝我們的解構(gòu)邏輯脈絡(luò),本系列文章以無繼承、per-task、后端只對(duì)接硬件 PMU、counting 模式的 perf 工作流程作為分析切入點(diǎn)。 本文乃系列文章的第一篇。簡(jiǎn)要鋪墊 perf 的前端,并對(duì)前端所確立的 perf 體系基本模型做闡述。 本文語(yǔ)義下,“perf 框架”指的是實(shí)現(xiàn)在內(nèi)核中的 perf 框架系統(tǒng),“perf 前端”指的是用戶態(tài)的系統(tǒng)調(diào)用接口。 本文所涉及 PMU 相關(guān)的知識(shí),請(qǐng)自行參閱本號(hào)《Intel SDM 之 Performance Monitoring》,或 Intel SDM。
2. perf 前端
2.1 是什么
本文所謂的“perf 前端”,并非指“perf”這個(gè)用戶態(tài)程序,而是 perf_event_open 這個(gè)系統(tǒng)調(diào)用的用戶側(cè)接口。實(shí)際上 perf 程序其底層就是基于 perf_event_open。 libc 并未對(duì)此系統(tǒng)調(diào)用做用戶態(tài)封裝,需要用戶自行封裝。有關(guān) perf_event_open 的細(xì)節(jié)請(qǐng)讀者自行 "man perf_event_open",本文默認(rèn)讀者熟悉 perf_event_open 的使用(如果該條件不成立,那么您可能并非本系列文章的潛在受眾),不會(huì)對(duì)該接口的眾多細(xì)節(jié)做展示,而只挑選與內(nèi)核 perf 框架模型有對(duì)應(yīng)關(guān)系的點(diǎn)進(jìn)行展開。
2.2 為什么
perf 框架,前端承接用戶態(tài)的各種事件(event)的屬性配置,后端將 event 嫁接到內(nèi)核的調(diào)度、文件系統(tǒng)等框架中,底層對(duì)接各種 PMU 硬件,所以其必然要建立一個(gè)復(fù)雜、嚴(yán)謹(jǐn)?shù)哪P停ǔ橄螅┫到y(tǒng)。而 perf 前端是整個(gè)模型系統(tǒng)對(duì)接用戶的最外層,所以搞清楚 perf 前端,是理解 perf 框架其模型系統(tǒng)的一個(gè)必要過程。
3. 事件(event)
3.1 是什么
所謂事件,就是用戶所關(guān)心的,在 OS 運(yùn)行過程中所發(fā)生的一個(gè) ... ... 好吧,事件。 比方說,你可能關(guān)心某個(gè)任務(wù)在運(yùn)行中的 ipc(instruction per cycle)指標(biāo),那么你需要監(jiān)控(采樣、計(jì)數(shù))任務(wù)運(yùn)行中的兩個(gè)事件:instructions、cycles。 比如你可以以固定間隔,定期獲取該周期內(nèi)此任務(wù)的 instruction 及 cycle ?數(shù),然后計(jì)算二者的比值即可。 如何獲取這些事件數(shù)呢?其后端需要借助 PMU。
3.2 事件類型
事件有很多類型:
PERF_TYPE_HARDWARE
PERF_TYPE_SOFTWARE
PERF_TYPE_TRACEPOINT
PERF_TYPE_HW_CACHE
PERF_TYPE_RAW
PERF_TYPE_BREAKPOINT
我們關(guān)注 PERF_TYPE_HARDWARE、PERF_TYPE_SOFTWARE、PERF_TYPE_HW_CACHE、PERF_TYPE_RAW 這四種類型。 實(shí)際上,事件類型的本質(zhì),就是其后端 PMU 的類型。
3.2.1 hardware
與硬件相關(guān)的事件。典型事件有:
PERF_COUNT_HW_CPU_CYCLES
PERF_COUNT_HW_INSTRUCTIONS
PERF_COUNT_HW_CACHE_REFERENCES
PERF_COUNT_HW_CACHE_MISSES
特征是其后端必須使用硬件 PMU 來監(jiān)控。比如 PERF_COUNT_HW_INSTRUCTIONS,你要想知道運(yùn)行期間所產(chǎn)生的 instruction 數(shù),就必須借助硬件才能實(shí)現(xiàn)。
3.2.2 software
與軟件相關(guān)的事件。典型事件有:
PERF_COUNT_SW_PAGE_FAULTS
PERF_COUNT_SW_CONTEXT_SWITCHES
PERF_COUNT_SW_CPU_MIGRATIONS
特征是其后端使用的是一個(gè)軟件實(shí)現(xiàn)的 PMU 來監(jiān)控。比如 PERF_COUNT_SW_CONTEXT_SWITCHES,你要想知道運(yùn)行期間的上下文切換次數(shù),就必須借助內(nèi)核中基于調(diào)度系統(tǒng)實(shí)現(xiàn)的軟件 PMU 才能實(shí)現(xiàn)。
3.2.3 hw_cache
與 cache 相關(guān)的事件。該類事件與上述兩類不同。上述兩類,每一種事件,通過一個(gè) id(事件編碼)來描述;而描述一個(gè) cache 相關(guān)的事件,需要三個(gè)維度的信息:
cache id:具體是監(jiān)控哪一級(jí) cache(PERF_COUNT_HW_CACHE_L1D、PERF_COUNT_HW_CACHE_L1I、PERF_COUNT_HW_CACHE_LL 等)。
cache op id:監(jiān)控的是對(duì) cache 的什么操作(PERF_COUNT_HW_CACHE_OP_READ、PERF_COUNT_HW_CACHE_OP_WRITE、PERF_COUNT_HW_CACHE_OP_PREFETCH)。
cache op result id:操作的結(jié)果(PERF_COUNT_HW_CACHE_RESULT_ACCESS、PERF_COUNT_HW_CACHE_RESULT_MISS)。
具體來說,用戶期望監(jiān)控 LLC 讀操作 miss 事件,則組合 PERF_COUNT_HW_CACHE_LL、PERF_COUNT_HW_CACHE_OP_READ、PERF_COUNT_HW_CACHE_RESULT_MISS 這三個(gè)參數(shù),并傳給 perf_event_open 接口。 ? 這類事件,其后端使用的仍然是硬件 PMU(沒錯(cuò),與 hardware 類型一樣)。
3.2.4 raw
實(shí)際上,hardware 事件的編碼,如 PERF_COUNT_HW_CPU_CYCLES,是對(duì)事件編碼的簡(jiǎn)化、抽象。 perf 系統(tǒng)對(duì)常用的硬件事件提供了形似 PERF_COUNT_HW_CPU_CYCLES 的簡(jiǎn)化編碼。一個(gè)事件在 PMU 體系中,原教旨的編碼應(yīng)該是 umask + event select:

圖 1:PERF_COUNT_HW_CPU_CYCLES 事件的 umask + event select 編碼方式
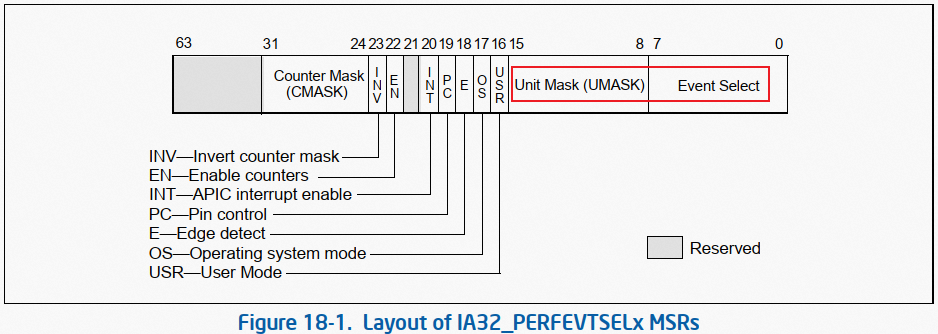
圖 2:IA32_PERFEVTSELx 寄存器格式 更多細(xì)節(jié)參閱本號(hào)《Intel SDM 之 Performance Monitoring》或 Intel SDM。 因?yàn)?PMU 可監(jiān)控的事件非常之多,perf 框架不可能對(duì)所有事件都提供抽象編碼,所以如果要對(duì)抽象編碼范圍覆蓋之外的其他事件做監(jiān)控,需要采用 umask + event select 的方式,告訴 perf(PMU)所要監(jiān)控的事件。 這種采用 umask +event select 方式編碼的事件即是 raw 類型事件。 ? raw 事件的本質(zhì),就是 hardware、hw_cache 事件中無法被抽象編碼所覆蓋的那些漏網(wǎng)之魚事件,也是 SDM 中對(duì)事件的原教旨編碼方式,所以后端也是硬件 PMU。 在后面文章的分析中我們其實(shí)可以看到,hardware、hw_cache 類型事件,其本質(zhì)就是 raw 事件。
3.2.5 事件類型與 PMU 的關(guān)系
這里要注意,PMU 不一定非得是一個(gè)硬件,也有軟件實(shí)現(xiàn)的 PMU。
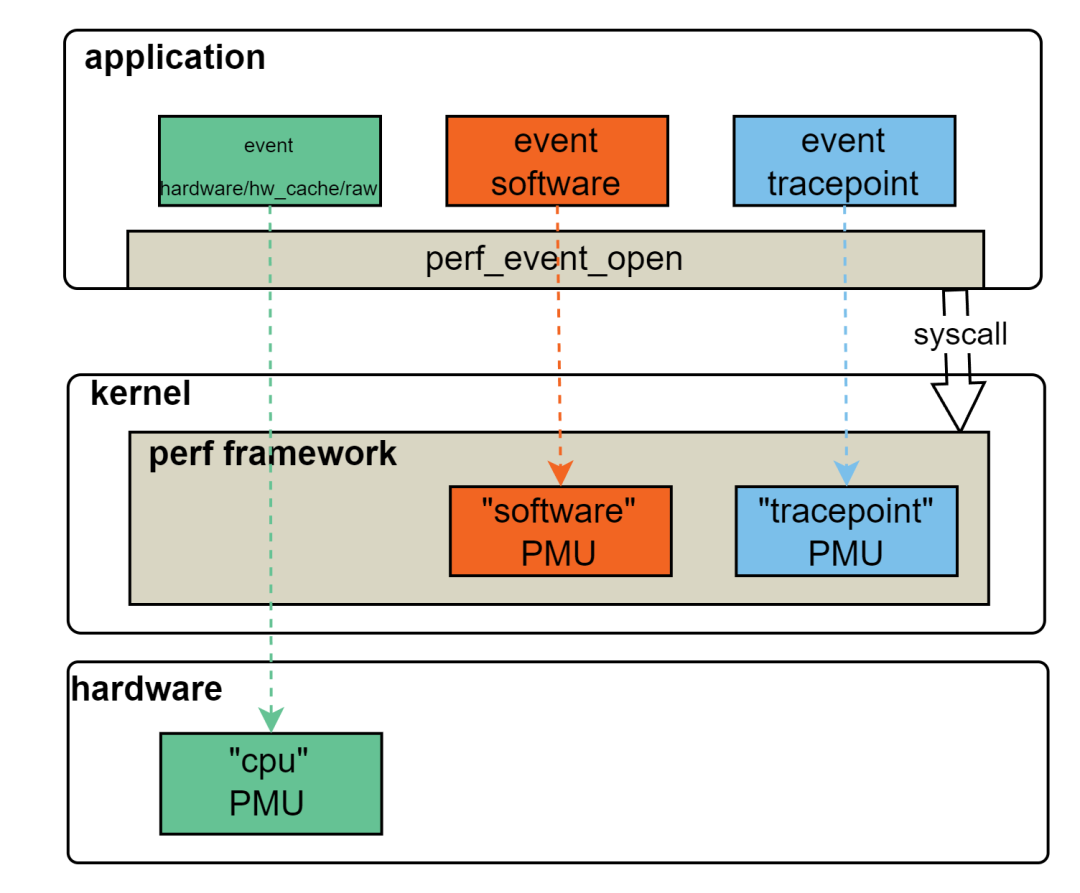
圖 3:事件類型與 PMU 的關(guān)系
3.3 事件監(jiān)控模式
事件的監(jiān)控有兩種模式,一曰 counting,一曰 sampling。
counting 模式很簡(jiǎn)單,就是簡(jiǎn)單的獲取事件的計(jì)數(shù),比如過去 5S 內(nèi) cpu 0 或 task 123 運(yùn)行期間產(chǎn)生的 instruction 數(shù)等。
sampling 模式比較復(fù)雜,其利用 PMU 定時(shí)去對(duì) CPU 當(dāng)前運(yùn)行的 ip 等信息進(jìn)行采樣,并通過一個(gè)環(huán)形 buffer 將采樣數(shù)據(jù)給到用戶態(tài)。
如綜述所言,本系列文章重點(diǎn)關(guān)注 counting 模式。
4. 前端編程基本范式
這里介紹前端的編程范式,不是為了介紹其本身而介紹,主要是為了介紹 perf 框架模型系統(tǒng)的前端呈現(xiàn)。 具體參數(shù)配置、接口形式等,請(qǐng)自行 man。
4.1 基本 counting 模式編程
注意 perf_event_attr 中對(duì)事件類型、事件編碼的指定。
/* 用戶自己對(duì) syscall 的封裝 */ long perf_event_open(struct perf_event_attr *hw_event, pid_t pid, int cpu, int group_fd, unsigned long flags) { int ret; ret = syscall(__NR_perf_event_open, hw_event, pid, cpu, group_fd, flags); return ret; } int main(void) { struct perf_event_attr pe; long long count; int fd; /* 這里初始化了一個(gè) attr * 此 attr 是向 perf_event_open 刻畫事件屬性的關(guān)鍵參數(shù) */ memset(&pe, 0, sizeof(struct perf_event_attr)); /* type:當(dāng)前要監(jiān)控的是一個(gè) hardware 類型事件 * 如前文所述,hardware 類型事件,其本質(zhì)就是 perf 框架提供了抽象事件編碼的硬件事件 */ pe.type = PERF_TYPE_HARDWARE; pe.size = sizeof(struct perf_event_attr); /* config:指定事件的編碼(instruction 事件) */ pe.config = PERF_COUNT_HW_INSTRUCTIONS; /* disable:該事件默認(rèn)初始是 disabled 模式 */ pe.disabled = 1; /* 不監(jiān)控 kernel(OS)模式下的事件 */ pe.exclude_kernel = 1; /* perf_event_open pid 入?yún)⑹?0 * 表明監(jiān)控當(dāng)前 task 的 instruction 事件 * 一個(gè)事件在用戶態(tài)的呈現(xiàn),就是一個(gè) fd */ fd = perf_event_open(&pe, 0, -1, -1, 0); /* RESET:復(fù)位計(jì)數(shù)值為 0 * ENABLE:enable 此事件(attr 參數(shù)中初始此事件是 disabled 的) * 故而需要顯式 enable */ ioctl(fd, PERF_EVENT_IOC_RESET, 0); ioctl(fd, PERF_EVENT_IOC_ENABLE, 0); /* 此 printf 的前后對(duì)事件進(jìn)行了 enable、disable * 所以,本程序的 instruction,本質(zhì)上就是此 printf 語(yǔ)句運(yùn)行期間的 instruction。 */ printf("Measuring instruction count for this printf "); ioctl(fd, PERF_EVENT_IOC_DISABLE, 0); /* 讀出事件的計(jì)數(shù)值 */ read(fd, &count, sizeof(long long)); printf("Used %lld instructions ", count); close(fd); }
4.2 事件組讀取
4.1 節(jié)中,對(duì) instruction 單一事件進(jìn)行監(jiān)控,并讀取 instruction 的計(jì)數(shù)。 perf 事件讀取還支持一種 PERF_FORMAT_GROUP 讀取方式,效果是將若干個(gè)事件放進(jìn)一個(gè)組內(nèi),每個(gè)組有一個(gè) group leader。對(duì) group leader 進(jìn)行讀取,可以一次讀出組內(nèi)所有事件的計(jì)數(shù)。 下面演示將一個(gè) hardware 類型事件和一個(gè) raw 類型事件作為一個(gè)組,一次讀取整組事件計(jì)數(shù)的基本范式:
struct read_format {
u64 nr; /* The number of events */
u64 values[2];
};
int main(void) {
struct perf_event_attr pe;
struct read_format count;
int group_leader_fd, group_member_fd;
/* 創(chuàng)建一個(gè) hardware 類型的事件,不贅述
*/
memset(&pe, 0, sizeof(struct perf_event_attr));
pe.type = PERF_TYPE_HARDWARE;
pe.size = sizeof(struct perf_event_attr);
pe.config = PERF_COUNT_HW_INSTRUCTIONS;
pe.disabled = 1;
pe.exclude_kernel = 1;
/* 這里指定采用 PERF_FORMAT_GROUP 讀取方式
* 注意,只在 group leader 時(shí)需要指定該參數(shù)
*/
pe.read_format = PERF_FORMAT_GROUP;
/* 創(chuàng)建 group leader
*/
group_leader_fd = perf_event_open(&pe, 0, -1, -1, 0);
/* 創(chuàng)建一個(gè) raw 類型的事件
* 假設(shè)要監(jiān)控的事件編碼:umask = 0x00, event_select = 0x3c
* 實(shí)際上此事件就是 UnHalted Core Cycles(也就是 hardware 類型的 PERF_COUNT_HW_CPU_CYCLES)
*/
memset(&pe, 0, sizeof(struct perf_event_attr));
pe.type = PERF_TYPE_RAW;
pe.size = sizeof(struct perf_event_attr);
/* 注意 raw 類型事件,config 的編碼方式
*/
pe.config = (0x00 << 4) | 0x3c;
pe.disabled = 1;
pe.exclude_kernel = 1;
/* 創(chuàng)建 group member,perf_event_open 的 group_fd 參數(shù)指定為 group_leader_fd
*/
group_member_fd = perf_event_open(&pe, 0, -1, group_leader_fd, 0);
/* 組模式下,只需要操作 group leader 即可
*/
ioctl(group_leader_fd, PERF_EVENT_IOC_RESET, 0);
ioctl(group_leader_fd, PERF_EVENT_IOC_ENABLE, 0);
printf("Measuring instruction count for this printf
");
ioctl(group_leader_fd, PERF_EVENT_IOC_DISABLE, 0);
/* 讀出事件組的計(jì)數(shù)值,注意這里入?yún)?count 是一個(gè) struct read_format
*/
read(group_leader_fd, &count, sizeof(count));
/* 只有 count.nr 與當(dāng)前組成員數(shù)(包括 leader、member)匹配,才是合法的數(shù)據(jù)
*/
if (count.nr == 2)
printf("Used %llu instructions, %llu cycles
", count.values[0], count.values[1]);
close(group_leader_fd);
close(group_member_fd);
}
4.3 模型總結(jié)
perf_event_open 支持 per-task 級(jí)別的事件監(jiān)控,pid 入?yún)魅肽繕?biāo) task 的 pid 即可。如綜述所言,per-cpu 級(jí)別的事件監(jiān)控本系列文章不做重點(diǎn)討論。
perf_event_open 支持對(duì)事件進(jìn)行分組,group leader 的 attr 需要帶上 PERF_FORMAT_GROUP 參數(shù),group member 的創(chuàng)建需要指定 group leader。
5. 總結(jié)
本文簡(jiǎn)要介紹 perf 前端的編程范式,意在為后續(xù) perf 框架中模型系統(tǒng)的抽象建立直觀感受。
編輯:黃飛













 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論