 電子發燒友App
電子發燒友App


今天給大家聊一聊Linux中文本操作的三劍客:awk、grep、sed,因其功能強大、使用頻繁,且是Linux下文本處理的得力利器,常被稱之為文本三劍客。 grep常用于查找,sed常用于取行和替換,而awk常用于運算。
有句玩笑話常說:做Linux技術不識三劍客,玩遍Linux也枉然,雖然是玩笑語,但也不得不說他們的重要性。
為什么聊起這個話題呢?
最近這幾天有點忙,可能是快到了畢業季了,最近來公司的面試的應屆生突然多了起來。 在對應屆生的面試過程中,往往會涉及一些基本的技術知識,主要看重的是對基礎知識的掌握和對新知識的學習能力。 而Linux下常用的基本命令awk、grep、sed也是常常被問及,來反映對Linux操作熟悉的程度。
問題:如何在Linux下查找包含某個函數的文件及所在的行?
熟悉Linux操作的肯定會說so easy! 此處先不給出具體答案,我們詳細介紹一下三劍客命令,如果不知道,看完后你肯定會知道答案!
1、grep命令
grep全稱是Global Regular Expression Print,表示全局正則表達式版本,它的使用權限是所有用戶。 它是Linux系統中一種強大的文本搜索工具,它能使用正則表達式搜索文本,并把匹配的行打印出來。
shell腳本中也經常使用grep,因為grep通過返回一個狀態值來說明搜索的結果。 如果搜索成功,則返回0,如果搜索不成功,則返回1,如果搜索的文件不存在,則返回2。 我們利用這些返回值就可進行一些自動化的文本處理工作。
grep家族包括grep、egrep和fgrep。 egrep和fgrep的命令跟grep區別不大。 egrep是grep的擴展,支持更多的re元字符,fgrep是fixed grep或fast grep,它們把所有的字母都看作單詞,也就是說,正則表達式中的元字符表示其自身的字面意義。 linux使用GNU版本的grep。 它功能更強,可以通過-G、-E、-F命令行選項來使用egrep和fgrep的功能。
- 參數
- -a 不要忽略二進制數據。
- -A <顯示行數> 除了顯示符合范本樣式的行之外,并顯示該行之后的指定幾行內容。
- -B<顯示行數> 除了顯示符合范本樣式的行之外,并顯示該行之前的指定幾行內容。
- -C<顯示行數> 除了顯示符合范本樣式的那一行之外,并顯示該行前后指定幾行的內容。
- -b 在顯示符合范本樣式的那一行之外,并顯示字節偏移量。 -c 只計算顯示符合范本樣式的行數,不顯示詳細內容
- -d<進行動作> 當指定要查找的是目錄而非文件時,必須使用這項參數,否則grep命令將回報信息并停止動作。
- -e<范本樣式> 指定字符串作為查找文件內容的范本樣式。
- -E 將范本樣式為延伸的普通表示法來使用,意味著能使用擴展正則表達式。
- -f <范本文件> 指定范本文件,其內容有一個或多個范本樣式,讓grep查找符合范本條件的文件內容,格式為每一列的范本樣式。
- -F 將范本樣式視為固定字符串的列表。
- -G 將范本樣式視為普通的表示法來使用。
- -h 在顯示符合范本樣式的那一列之前,不標示該列所屬的文件名稱。
- -H 在顯示符合范本樣式的那一列之前,標示該列的文件名稱。
- -i 忽略字符大小寫的差別。
- -l 列出文件內容符合指定的范本樣式的文件名稱。
- -L 列出文件內容不符合指定的范本樣式的文件名稱。
- -n 在顯示符合范本樣式的那一列,標示出該列的編號。
- -q 不顯示任何信息。
- -R/-r 此參數的效果和指定“-d recurse”參數相同,表明查找路徑為目錄
- -s 不顯示錯誤信息。
- -v 反轉查找,顯示不符合模式的所有信息
- -w 只顯示全字符合的列。
- -x 只顯示全列符合的列。
- -y 此參數效果跟“-i”相同。
- -o 只輸出文件中匹配到的部分。
- --color=auto 把匹配部分標記出來,要想當前終端后續使用都要標記匹配部分,可用alias命令重新封裝grep。
示例:
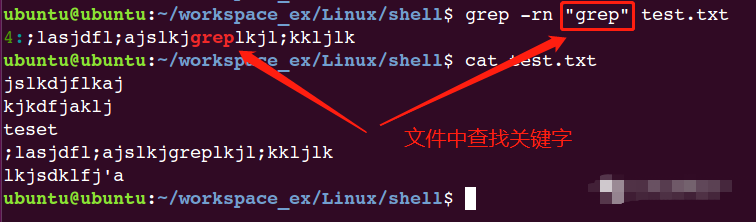
正則表達式
正則表達式應用廣泛,在絕大多數的編程語言都可以應用,在Linux中,也有著很大的用處。 使用正則表達式,可以有效的篩選出需要的文本,然后結合相應的支持的工具或語言,完成我們的需求。
格式
- .匹配任意單個字符,不能匹配空行
- [] 匹配指定范圍內的任意單個字符
- [^] 取反
- [:alnum:] 或 [0-9a-zA-Z]
- [:alpha:] 或 [a-zA-Z]
- [:上部:] 或 [A-Z]
- [:lower:] 或 [a-z]
- [:blank:] 空白字符(空格和制表符)
- [:space:] 水平和垂直的空白字符(比[:blank:]包含的范圍廣)
- [:cntrl:] 不可打印的控制字符(退格、刪除、警鈴... )
- [:digit:] 十進制數字 或[0-9]
- [:xdigit:]十六進制數字
- [:graph:] 可打印的非空白字符
- [:print:] 可打印字符
- [:punct:] 標點符號
- 匹配前面的字符任意次,包括0次,貪婪模式:盡可能長的匹配
- .* 任意長度的任意字符,不包括0次
- ? 匹配其前面的字符0 或 1次
- 匹配其前面的字符至少1次
- {n} 匹配前面的字符n次
- {m,n} 匹配前面的字符至少m 次,至多n次
- {,n} 匹配前面的字符至多n次
- {n,} 匹配前面的字符至少n次
我們可以根據grep命令任意組合正則表達式
2、sed命令
主要用來自動編輯一個或多個文件, 簡化對文件的反復操作
sed是一種流編輯器,一次處理一行內容。 處理時,把當前處理的行存儲在臨時緩沖區中,稱為“模式空間”,接著用sed命令處理緩沖區中的內容,處理完成后,把緩沖區的內容輸出。 然后讀入下行,執行下一個循環。 如果沒有使諸如‘D’的特殊命令,那會在兩個循環之間清空模式空間,但不會清空保留空間。 這樣不斷重復,直到文件末尾。 文件內容并沒有改變,除非你使用重定向存儲輸出或-i。
格式:sed [options] 'command' file(s) 常用參數:
- -n:不輸出內容到屏幕,即不自動打印,只打印匹配到的行
- -e:多點編輯,對每行處理時,可以有多個Script
- -f:把Script寫到文件當中,在執行sed時-f指定文件路徑,如果是多個Script,換行寫
- -r:支持擴展的正則表達式
- -i:直接將處理的結果寫入文件
- -i.bak:在將處理的結果寫入文件之前備份一份
示例:
sed '=' test.txt #顯示行號
sed '3=' test.txt #顯示第三行行號
sed "/./=" test.txt #只顯示非空白行的行號
sed -n "/./!=" test.txt #只顯示空白行行號
sed '$=' test.txt #顯示總共有多少行
sed -n '2p' test.txt #要加-n,否則會默認自動打印所有內容
sed -n '2 p' test.txt #要加-n,否則會默認自動打印所有內容
# 輸出指定行
sed -n '2,7 p' test.txt
sed -n '2,7p' test.txt
sed -n '2,7 {p}' test.txt
#替換文件中內容
sed -i 's/bck/sh/' test.txt test1.txt #替換test.txt、test1.txt內的bck為sh,每行只替換一個
sed -i 's/bck/sh/g' test.txt #替換test.txt內的bck為sh,每行都進行全面替換
sed -i 's/bck/sh/3g' test.txt #替換test.txt內的bck為sh,從第3個匹配位置開始替換
sed -i 's@bck@sh@g' test.txt #替換test.txt內的bck為sh,每行都進行全面替換
sed -i 's#bck#sh#g' test.txt #替換test.txt內的bck為sh,每行都進行全面替換
#顯示查找內容的行
sed -n '/sh/p' test.txt #顯示test.txt內的所有包含sh的所有行
sed -n '/sh/ ,$ p' test.txt #顯示test.txt里第一條包含sh的行及以下到末尾的所有行
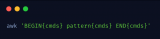
3、awk命令
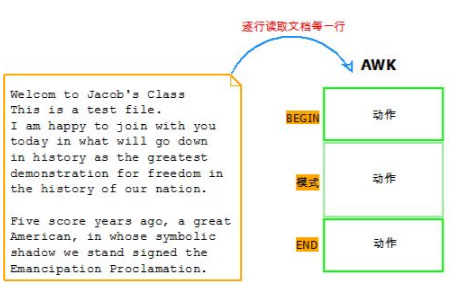
awk用于在linux/unix下對文本和數據進行處理。 數據可以來自標準輸入(stdin)、一個或多個文件,或其它命令的輸出。 它支持用戶自定義函數和動態正則表達式,是linux/unix下的一個強大編程工具。 它在命令行中使用,但更多是作為腳本來使用。 awk有很多內建的功能,比如數組、函數等,這是它和C語言的相同之處,靈活性是awk最大的優勢。 awk其實不僅僅是工具軟件,還是一種編程語言。
格式:awk [選項] 'program' var=value file...awk [選項] -f 程序文件 var=value file...awk [options] 'BEGIN{ action;... } pattern{ action;... }END{ action;... }' 文件 ...
常用命令選項
- -F fs:fs指定輸入分隔符,fs可以是字符串或正則表達式,如-F:
- -v var=value:賦值一個用戶定義變量,將外部變量傳遞給awk
- -f scripfile:從腳本文件中讀取awk命令
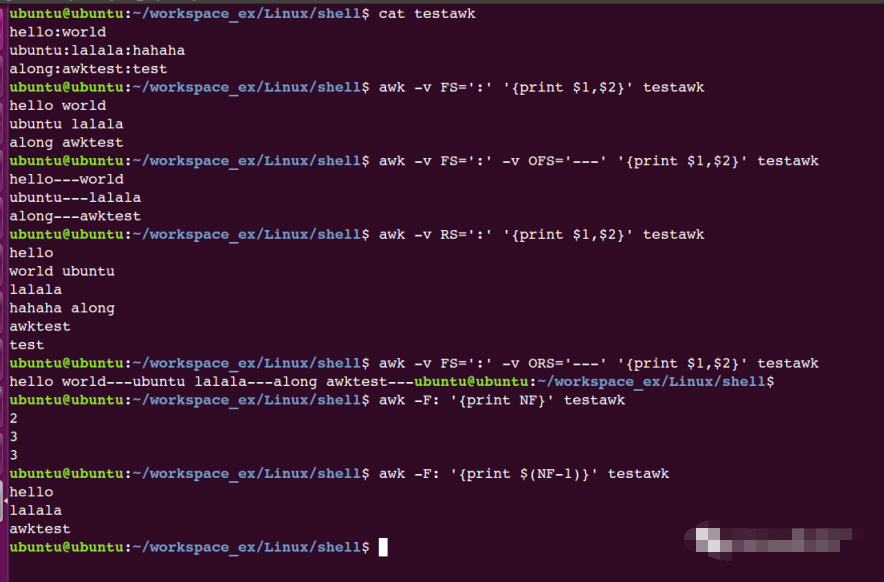
示例:
awk -v FS=':' '{print $1,$2}' testawk #FS指定輸入分隔符
awk -v FS=':' -v OFS='---' '{print $1,$2}' testawk #OFS指定輸出分隔符
awk -v RS=':' '{print $1,$2}' testawk
awk -v FS=':' -v ORS='---' '{print $1,$2}' testawk
awk -F: '{print NF}' testawk
awk -F: '{print $(NF-1)}' testawk #顯示倒數第2列
小結
上述三個命令的功能及參數遠遠不止本文提到的這些,在此只是羅列了一些常用的功能及參數。 這三個命令的功能非常強大,用法及參數和功能也非常的多,我們沒必要刻意去記憶,也不可能全部記住,記住一些常用的參數及用法即可。 只要當我們有需求時知道用哪個命令然后對應的去查找相關參數用法即可。

















 工商網監
工商網監
評論