 電子發燒友App
電子發燒友App


今天下午突然 出現 測試環境 cpu飆高,干到了 60%,其他項目 響應時間明顯變長。。。有點嚇人,不想背鍋
項目背景
出問題的項目是 需要連接各個不同nacos 和不同的 namespace 進行對應操作的 一個項目,對nacos的操作都是httpClient 調用的api接口,httpClient方法 沒有問題,不用質疑這個
定位問題
首先 這 cpu高了,直接top -Hp 看看
定位到 進程id,然后 執行 jstack 進程id -> 1.txt
看到堆棧信息 ,下面提示信息有很多
"com.alibaba.nacos.client.config.security.updater"?#2269?daemon?prio=5?os_prio=0?tid=0x00007fa3ec401800?nid=0x8d85?waiting?on?condition?[0x00007fa314396000]
???java.lang.Thread.State:?TIMED_WAITING?(parking) ????????at?sun.misc.Unsafe.park(Native?Method) ????????-?parking?to?wait?for??<0x00000000f7f3eae0>?(a?java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject) ????????at?java.util.concurrent.locks.LockSupport.parkNanos(LockSupport.java:215) ????????at?java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.awaitNanos(AbstractQueuedSynchronizer.java:2078) ????????at?java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:1093) ????????at?java.util.concurrent.ScheduledThreadPoolExecutor$DelayedWorkQueue.take(ScheduledThreadPoolExecutor.java:809) ????????at?java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1074) ????????at?java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1134) ????????at?java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ????????at?java.lang.Thread.run(Thread.java:748)
但是上面這個提示信息 顯示 是 線程內部的,而且是nacos client 內部的
你這么搞,讓我很難受啊,我都是http 調用的,當時就是為了 防止開啟無用的線程,這。。。。。怎么
那我去 根據你的關鍵字找找 是哪里打印的,關鍵字 com.alibaba.nacos.client.config.security.updater
ServerHttpAgent 類的方法
//?init?executorService this.executorService?=?new?ScheduledThreadPoolExecutor(1,?new?ThreadFactory()?{ ????@Override ????public?Thread?newThread(Runnable?r)?{ ????????Thread?t?=?new?Thread(r); ????????t.setName("com.alibaba.nacos.client.config.security.updater"); ????????t.setDaemon(true); ????????return?t; ????} });
這是構造方法啊,應該只初始化一次的啊,往上debug,我靠,NacosConfigService 類中調用了,debug 看什么時候調用了 不就行了嘛
項目初始化的時候 調用了一次,業務系統依賴nacos嘛,ok 可以理解
再就是漫長的等待,30s后 發現又是一次調用,我去,怎么可能。。。
往回debug,代碼如下
scheduler.schedule("定時校對灰度nacos?配置",?()?->?loadGrayConfig(grayFileName),
????1800,?1800,?TimeUnit.SECONDS);
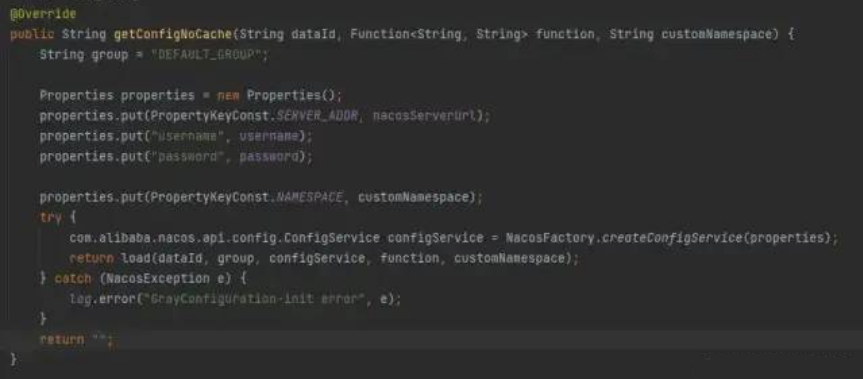
/** ?*?灰度配置更新?解決?網絡隔離的問題 ?* ?*?@param?grayFileName?灰度文件的名稱 ?*/ private?void?loadGrayConfig(String?grayFileName)?{ ????synchronized?(this)?{ ????????System.err.println("loadGrayConfig?datetime:?"?+?DateUtils.formatDate(new?Date())); ????????//刷一次?緩存?重新獲取nacos?內容?賦值 ????????grayConfigManager.loadNoCache(grayFileName); ????} }
?
?
等會,難道 小丑是我。。。。
這當時是為了灰度功能,定時數據校驗用的 用了一個線程池,當時以為用了線程池 妥妥的。。。還特意調用的 Nocache 方法,讓他創建新的nacos Config對象,做數據校對
但是每調用一次 NacosFactory.createConfigService(properties) ,nacos config 構造器就會開一個線程,就導致了這個問題
這里可能你要問了你說為了防止網絡隔離才加的這個調度任務,什么是網絡隔離啊?
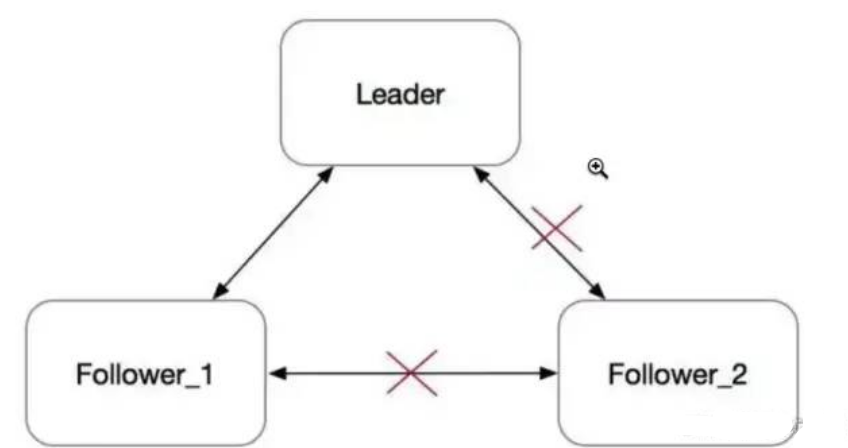
我剛開始聽說這個概念是 當時學習 Raft
假設一個Raft集群擁有三個節點,其中節點3的網絡被隔離,那么按照BasicRaft的實現,集群會有以下動作:
節點3由于網絡被隔離,收不到來自Leader的Heartbeat和AppendEntries,所以節點3會進入選舉過程,當然選舉過程也是收不到投票的,所以節點3會反復超時選舉;節點3的Term就會一直增大
節點1與節點2會正常工作,并停留在當時的Term
網絡恢復之后,Leader給節點3發送RPC的時候,節點3會拒絕這些RPC理由是發送方任期太小。
Leader收到節點3發送的拒絕后,會增大自己的Term,然后變成Follower。
隨后,集群開始新的選舉,大概率原本的Leader會成為新一輪的Leader。
那么網絡隔離 Raft是怎么解決的呢?
多輪投票的安全問題是棘手的,必須避免同一高度不同輪數分別提交兩個不同區塊的情形。在Tendermint中,這個問題可以通過鎖機制(locking mechanism)得到解決。
鎖定規則:預投票鎖(Prevote-the-Lock):
驗證者只能預投票(pre-vote) 他們被鎖定的區塊。這樣就阻止驗證者在上一輪中預提交(pre-commit)一個區塊,之后又預投票了下一輪的另一個區塊。
波爾卡解鎖(Unlock-on-Polka ):驗證者只有在看到更高一輪(相對于其當前被鎖定區塊的輪數)的波爾卡之后才能釋放該鎖。這樣就允許驗證者解鎖,如果他們預提交了某個區塊,但是這個區塊網絡的剩余節點不想提交,這樣就保護了整個網絡的運轉,并且這樣做并沒有損害網絡安全性。
解決方案是把term替換成(term, nodeid),并且按照字典序比較大小(a > b === a.term > b.term || a.term == b.term && a.nodeid > b. node_id). 這是paxos里的做法, 保證不會出現raft里的沖突.
原理是, raft對voting的階段有2個值來描述: term和當前投了哪個node_id, 即[term, nodeid], 由于raft不允許一個term vote2個不同的不同的node, 也就是說, vote_req.term > local.term && vote_req.nodeid == local.nodeid 才會grant這個vote請求.
把term替換成(term,nodeid)后, vote階段的大小比較變成了: vote_req.term > local.term || vote_req.term == local.term && vote_req.nodeid >= local.nodeid, 條件邊寬松了. 同一個term內, 較大nodeid的可以搶走較小nodeid 已經建立的leader.
而日志中原本記錄的term也需要將其替換成(term, node_id), 因為這兩項加起來才能唯一確定一個leader. 之前raft里只需一個term就可以唯一確定一個leader.
vote中比較最大log id相應的,從比較tuple (term, index) 改成比較tuple (term, node_id, index).
就這么點修改.
總結下來就是 按照字典排序 和 預投票鎖 保證 當多個 term 相同的 candidate 相遇后,肯定會有一個 獲得多數派投票
想法
我們如果出現 異常的網絡隔離情況再回來,可能導致 數據的不一致,但是上面的 解決辦法 因為 比較重,不適合我們,我們就單純 引入 定時校對的調度任務 進行比較(和 對賬一樣)
修復
我對nacos config 連接進行 遍歷查找 是否存活,不存活 我就shutdown,然后生成一個新的,而不是這種全部生成一邊,畢竟人家 構造器開了線程。。。。
說回來還是因為 我當時自信了,沒往這個調用下面看,在子類中 寫的開線程 哈哈,行吧,改改 ,跑到測試環境 看看效果(CPU)

嗯嗯 穩定了,明天再看看,應該沒問題了
編輯:黃飛
?













 工商網監
工商網監
評論